一、完全分布式部署介绍
学习目标
- 能够了解完全分布式部署场景
完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
二、NameNode HA+完全分布式部署
学习目标
- 能够了解HA+完成分布式部署场景
- 能够对HA+完全分布式部署架构规划
- 能够对HA+完全分布式部署进行配置
预备知识
1)什么是HA?
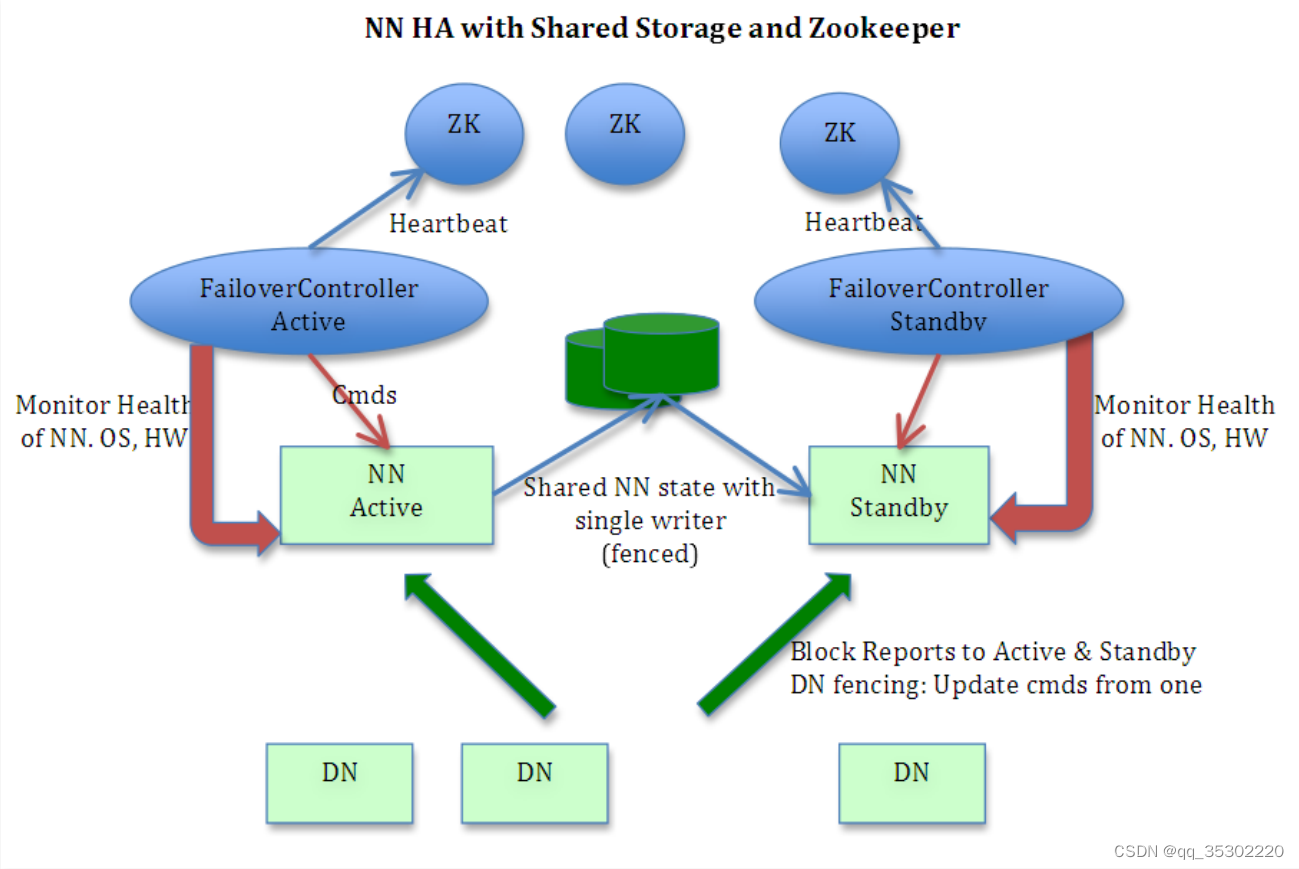
HA的意思是High Availability高可用,指当当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。
HA方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA是Hadoop 2.x中新添加的特性,包括NameNode HA 和 ResourceManager HA。因为DataNode和NodeManager本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
2)NameNode HA切换实现方法
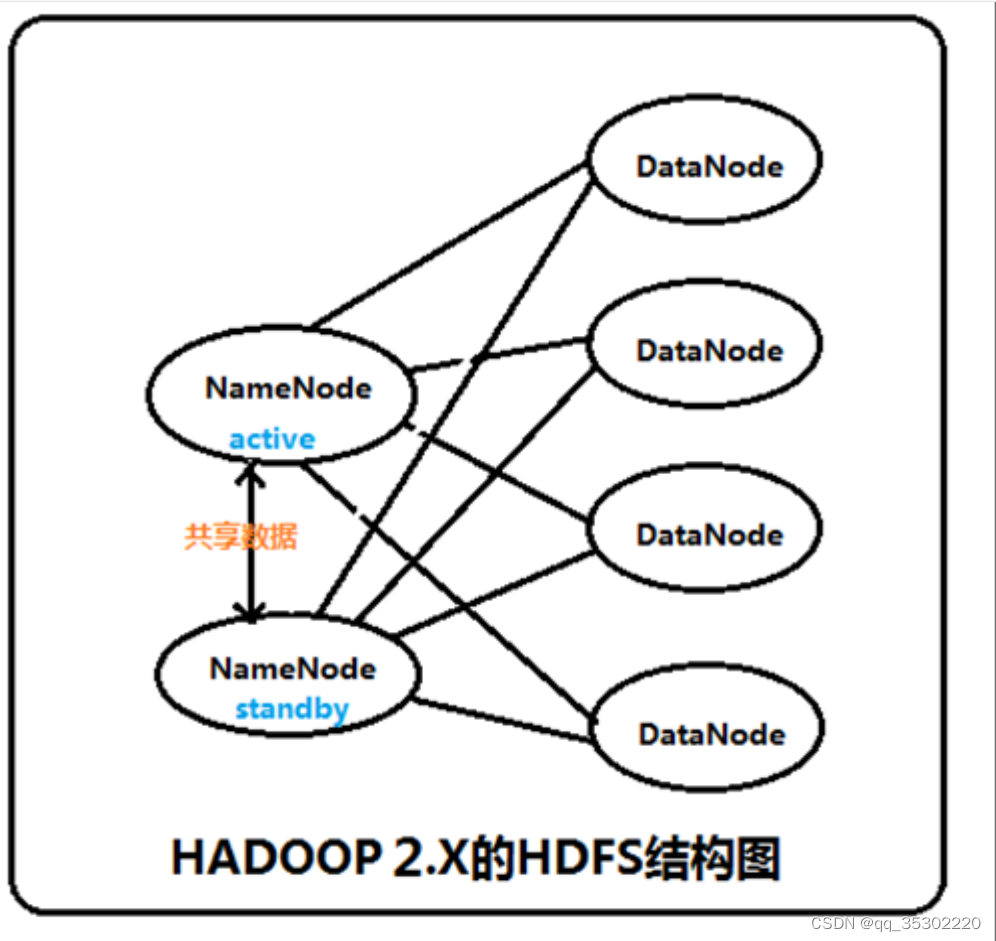
Hadoop2.X对NameNode进行一个抽象:NameService 一个NameService下面有两个NameNode,分别处于Active和Standby状态。
通过Zookeeper进行协调选举,确保只有一个活跃的NameNode。
一旦主(Active)宕掉,standby会切换成Active。

作为一个ZK集群的客户端,用来监控NN的状态信息。每个运行NN的节点必须要运行一个zkfc。
zkfc提供以下功能:
Health monitoring
zkfc定期对本地的NN发起health-check的命令,如果NN正确返回,那么这个NN被认为是OK的。否则被认为是失效节点。
ZooKeeper session management
当本地NN是健康的时候,zkfc将会在zk中持有一个session。如果本地NN又正好是active的,那么zkfc还有持有一个"ephemeral"的节点作为锁,一旦本地NN失效了,那么这个节点将会被自动删除。
ZooKeeper-based election
如果本地NN是健康的,并且zkfc发现没有其他的NN持有那个独占锁。那么他将试图去获取该锁,一旦成功,那么它就需要执行Failover,然后成为active的NN节点。Failover的过程是:第一步,对之前的NN执行fence,如果需要的话。第二步,将本地NN转换到active状态。

3)NameNode HA数据共享方法
Namenode主要维护两个文件,一个是fsimage,一个是editlog。
fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
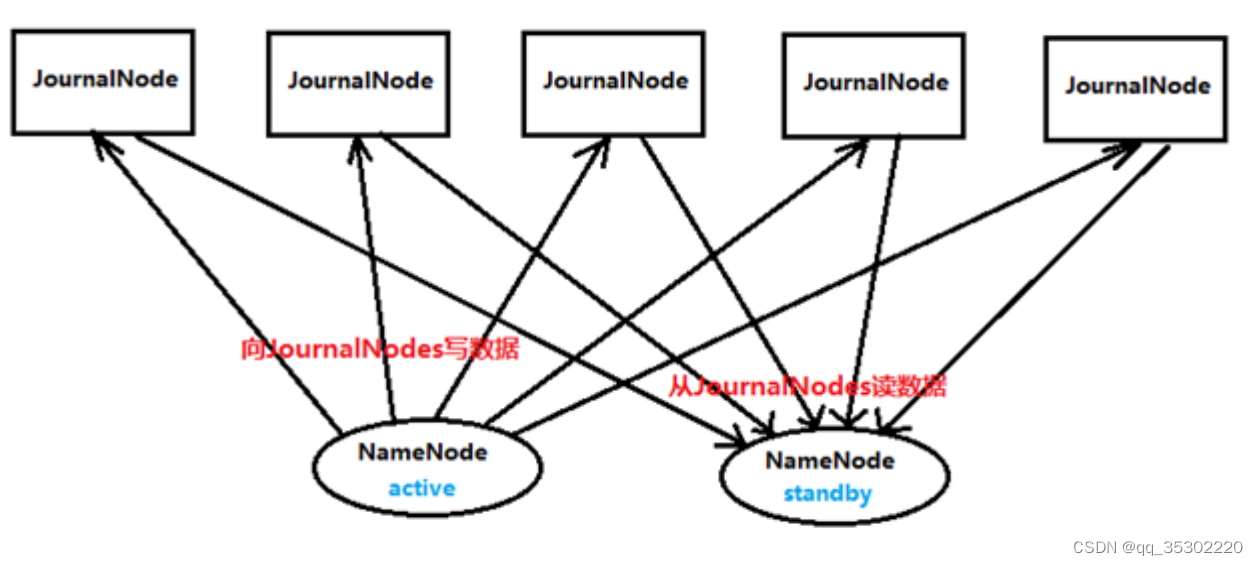
上面在Active Namenode与StandBy Namenode之间的绿色区域就是JournalNode,当然数量不一定只有1个,作用相当于NFS共享文件系统,Active Namenode往里写editlog数据,StandBy再从里面读取数据进行同步。
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态。active状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务
部署规划

实施
1)系统时间同步
[root@localhost ~]#ntpdate time1.aliyun.com
2)设置主机IP及名称解析
[root@localhost ~]#vim /etc/hosts
192.168.208.5 hd1
192.168.208.10 hd2
192.168.208.20 hd3
192.168.208.30 hd4
192.168.208.40 hd5
192.168.208.50 hd6
把/etc/hosts文件复制到所有集群主机
3)关闭防火墙及Selinux
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
[root@localhost ~]# sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
4)部署JDK
[root@localhost ~]#firefox http://download.oracle.com
[root@localhost ~]#tar xf jdk-8u191-linux-x64.tar.gz -C /usr/local
[root@localhost ~]#mv /usr/local/jdk1.8 /usr/local/jdk
5)SSH免密登录
[root@localhost ~]#ssh-keygen -t rsa -f /root/.ssh/id_rsa -P ''
[root@localhost ~]#cd /root/.ssh
[root@localhost ~]#cp id_rsa.pub authorized_keys
[root@localhost ~]#for i in hd2 hd3 hd4 hd5 hd6;do scp -r /root/.ssh $i:/root;done
把密钥复制到所有主机
6)zookeeper部署
6.0)zookeeper作用
ZooKeeper 是为分布式应用程序提供高性能协调服务的工具集合,译名为“动物园管理员”。
分布式应用程序可以基于它实现配置维护、命名服务、分布式同步、组服务等。
是 Hadoop集群管理的一个必不可少的模块,它主要用来解决分布式应用中经常遇到的数据管理问题,如集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等。
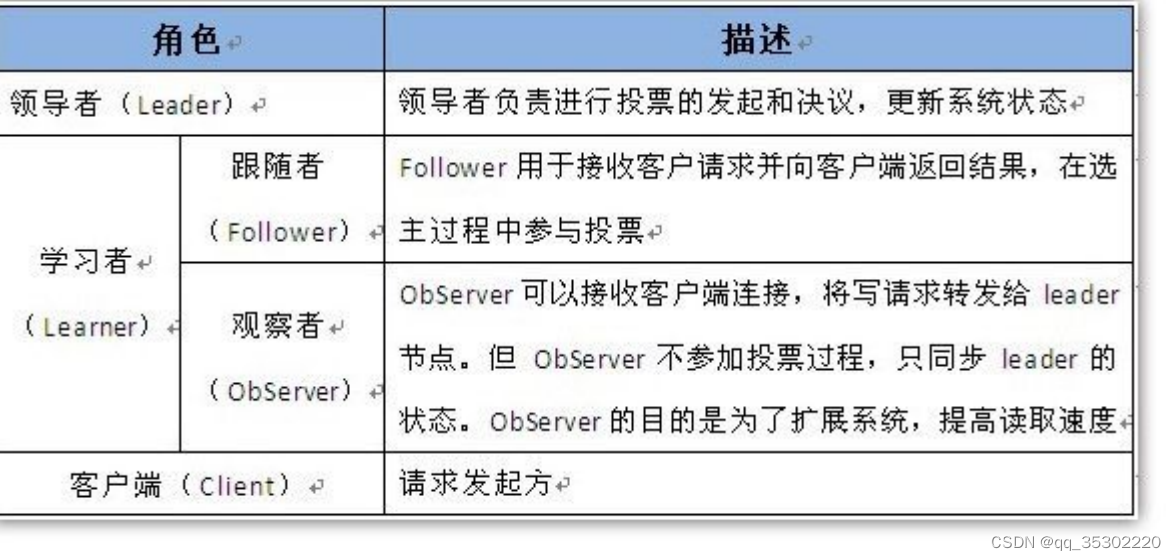
在ZooKeeper集群当中,集群中的服务器角色有两种Leader和Learner,Learner角色又分为Observer和Follower
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Follower完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Follower具有相同的系统状态。
如下图所示:
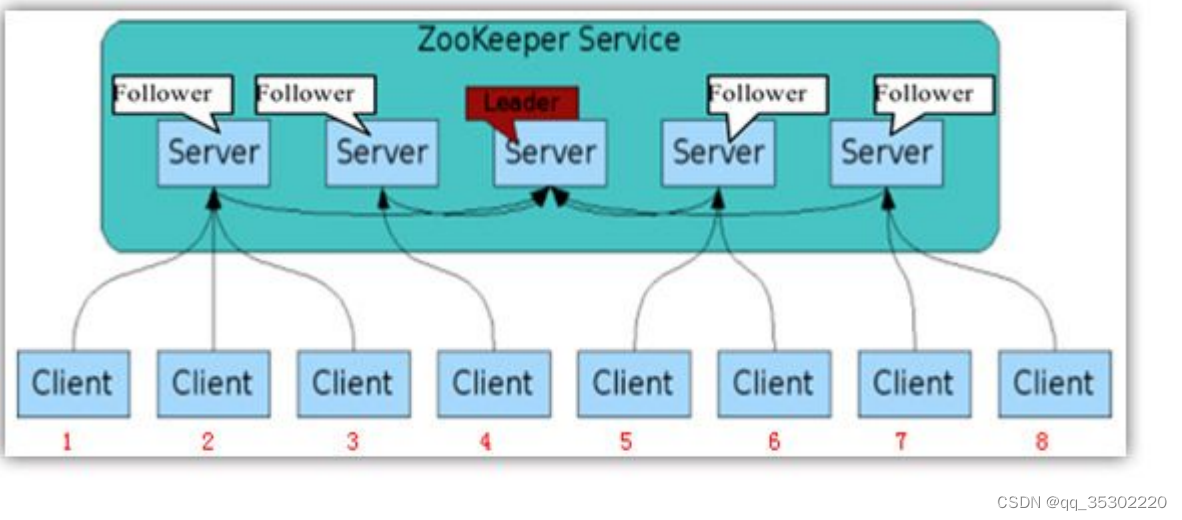
该ZooKeeper集群当中一共有5台服务器,有两种角色Leader和Follwer,5台服务器连通在一起,客户端又分别连在不同的ZK服务器上。
如果当数据通过客户端1,在左边第一台Follower服务器上做了一次数据变更,它会把这个数据的变化同步到其他所有的服务器,同步结束之后,那么其他的客户端都会获得这个数据的变化。
Zookeeper是一个由多个server组成的集群,一个leader,多个follower,每个server保存一份数据副本,全局数据一致、分布式读写,更新请求转发,由leader实施。
- Leader主要有三个功能
-
- 恢复数据;
-
- 维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
-
- Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
-
- Follower主要有四个功能
-
- 向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
-
- 接收Leader消息并进行处理;
-
- 接收Client的请求,如果为写请求,发送给Leader进行投票;
-
- 返回Client结果。
-
zookeeper部署至hdfs集群的datanode节点,此案例共3台。
6.1)获取软件包
[root@localhost ~]#wget https://www-eu.apache.org/dist/zookeeper/zookeeper3.4.13/zookeeper-3.4.13.tar.gz
6.2)部署软件包
[root@localhost ~]#tar xf zookeeper-3.4.13.tar.gz -C /usr/local
[root@localhost ~]#mv /usr/local/zookeeper-3.4.13 /usr/local/zookeeper
[root@localhost ~]#mv /usr/local/zookeeper/conf/zoo.sample.cfg
/usr/local/zookeeper/conf/zoo.cfg
[root@localhost ~]#vim /usr/local/zookeeper/conf/zoo.cfg
data=/opt/data
server.1=hd4:2888:3888
server.2=hd5:2888:3888
server.3=hd6:2888:3888
[root@localhost ~]#mkdir /opt/data
[root@localhost ~]#echo 1 > /opt/data/myid
每台服务器myid不同,需要分别修改,例如server.1对应的myid内容为1,server.2对应的myid内容为2,
server.3对应的myid为3。
2888端口:follower连接到leader机器的端口
3888端口:leader选举端口
6.3)添加环境变量
[root@localhost ~]#vim /etc/profile.d/hadoop.sh
export JAVA_HOME=/usr/local/jdk
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:$PATH
[root@localhost ~]# source /etc/profile
在3台datanode节点上全部添加
6.4)验证zookeeper
[root@localhost ~]#zkServer.sh start
[root@localhost ~]#zkServer.sh status
需要把以上文件拷贝至3台datanode,然后全部执行开启命令
[root@localhost ~]#zkServer.sh stop
7)hadoop软件包获取
[root@localhost ~]#wget
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop2.8.5.tar.gz
[root@localhost ~]#tar xf hadoop-2.8.5.tar.gz -C /opt
8)完全分布式(HA)配置文件修改
8.1)hadoop-env.sh
[root@localhost ~]#vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
修改hadoop-env.sh 25行,mapred-env.sh 16行,yarn-env.sh 23行,针对hadoop-2.8.5版本
8.2)core-site.xml
[root@localhost ~]#vim core-site.xml
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hd4:2181,hd5:2181,hd6:2181</value>
</property>
8.3)hdfs-site.xml
[root@localhost ~]#vim hdfs-site.xml
[root@localhost ~]#vim hdfs-site.xml
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hd1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hd1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hd2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hd2:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hd4:8485;hd5:8485;hd6:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</valu
e>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
8.4)配置datanode节点记录文件 slaves
[root@localhost ~]#vim slaves
hd4
hd5
hd6
8.5)mapred-site.xml
[root@localhost ~]#cp /opt/hadoop285/etc/hadoop/mapred-site.xml.template
/opt/hadoop285/etc/hadoop/mapred-site.xml
[root@localhost ~]#vim mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
8.6)yarn-site.xml
[root@localhost ~]#vim yarn-site.xml
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hd3</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
9)复制修改后的hadoop目录到所有集群节点
[root@localhost ~]#scp -r hadoop hdX:/opt
[root@localhost ~]#scp /etc/profile.d/hadoop.sh hdX:/etc/profile.d/
[root@localhost ~]#source /etc/profile
10)在datanode节点(3台)启动zookeeper
[root@localhost ~]#zkServer.sh start
11)启动journalnode(在namenode上操作,例如hd1)
[root@localhost ~]#hadoop-daemons.sh start journalnode
分别到hd4、hd5、hd6节点上进行验证
[root@localhost ~]#jps
12)格式化hdfs文件系统(在namenode上操作,例如hd1)
[root@localhost ~]#hdfs namenode -format
格式化完成后,请把/opt/data/tmp目录拷贝至hd2相应的位置,hd2将不再需要格式化,可以直接使用。
13)格式化zk(namenode上操作,例如hd1)
[root@localhost ~]#hdfs zkfc -formatZK
14)启动hdfs(namenode上操作,例如hd1)
[root@localhost ~]#start-dfs.sh
15)启动yarn(namenode上操作,例如想让hd2成为resourcemanager,需要在hd2上
启动。)
[root@localhost ~]#start-yarn.sh
16)访问
NameNode1:http://hd1:50070 查看NameNode状态
NameNode2:http://hd2:50070 查看NameNode状态
NameNode3:http://hd3:8088 查看yarn状态
三、Ambari自动部署Hadoop
学习目标
- 能够了解Ambari应用场景
- 能够了解Ambari功能
- 能够安装并配置Ambari Server
- 能够安装并配置Ambari Agent
- 能够通过Ambari实现Hadoop集群自动部署
- 能够掌握Ambari自动部署的Hadoop集群使用测试
1)Ambari介绍
Apache Ambari项目旨在通过开发用于配置,管理和监控Apache Hadoop集群的软件来简化Hadoop管理。Ambari提供了一个由RESTful API支持的直观,易用的Hadoop管理Web UI。
Ambari使系统管理员能够:
- 提供Hadoop集群
- Ambari提供了跨任意数量的主机安装Hadoop服务的分步向导。
- Ambari处理群集的Hadoop服务配置。
- 管理Hadoop集群
- Ambari提供集中管理,用于在整个集群中启动,停止和重新配置Hadoop服务。
- 监控Hadoop集群
- Ambari提供了一个仪表板,用于监控Hadoop集群的运行状况和状态。
- Ambari利用Ambari指标系统进行指标收集。
- Ambari利用Ambari Alert Framework进行系统警报,并在需要您注意时通知您(例如,节点出现故障,剩余磁盘空间不足等)。
Ambari使应用程序开发人员和系统集成商能够:
- 使用Ambari REST API轻松将Hadoop配置,管理和监控功能集成到自己的应用程序中
2)Ambari部署
Ambari本身也是一个分布式架构软件,主要由两部分组成:Ambari Server和Ambari Agent。用户通过AmbariServer通知Ambari Agent安装对应的软件,Agent会定时发送各个机器每个软件模块的状态给Server,最终这些状态信息会呈现给Ambari的GUI,方便用户了解到集群中各组件状态,做出相应的维护策略。
Ambari部署介绍:https://docs.hortonworks.com/HDPDocuments/Ambari-2.6.1.5/bk_ambari-installation/content/hdp_26_repositories.html
2.1)环境准备
1.Centos7.5 6台
1台做Ambari Server
5台做Ambari Agent[即可部署hadoop集群]
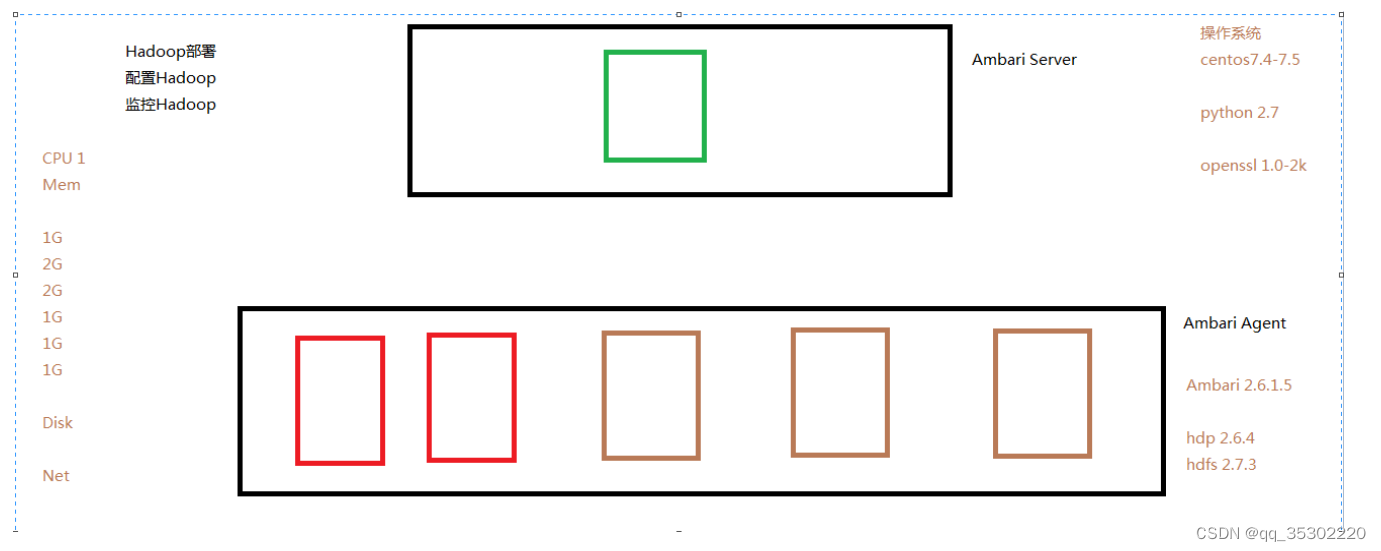
2.静态IP地址配置及集群主机之间多机互信
[root@ambariserver ~]# cat /etc/sysconfig/network-scripts/ifcfg-eth0
TYPE="Ethernet"
BOOTPROTO="static"
NAME="eth0"
DEVICE="eth0"
ONBOOT="yes"
IPADDR="192.168.122.X" #各主机IP地址自行规划
PREFIX="24"
GATEWAY="192.168.122.1"
DNS1="119.29.29.29"
[root@localhost ~]#ssh-keygen -t rsa -f /root/.ssh/id_rsa -P ''
[root@localhost ~]#cd /root/.ssh
[root@localhost ~]#cp id_rsa.pub authorized_keys
[root@localhost ~]#scp -r /root/.ssh 192.168.208.x:/root
3.集群主机名定义
[root@localhost ~]#vim /etc/hosts
192.168.122.10 ambariserver.a.com ambariserver
192.168.122.20 hd1.a.com hd1
192.168.122.30 hd2.a.com hd2
192.168.122.40 hd3.a.com hd3
192.168.122.50 hd4.a.com hd4
192.168.122.60 hd5.a.com hd5
完全合格域名格式
4.添加JDK
[root@localhost ~]#tar xf jdk-8u91-linux-x64.tar.gz -C /usr/local
[root@localhost ~]#mv /usr/local/jdk1.8_91 /usr/local/jdk
5.安装mariadb
[root@localhost ~]#yum -y install mariadb mariadb-server
[root@localhost ~]#systemctl start mariadb
[root@localhost ~]#systemctl enable mariadb
[root@localhost ~]#mysqladmin -uroot password "abc123"
[root@localhost ~]#mysql -uroot -pabc123
>create database ambari character set utf8;
> grant all on ambari.* to 'ambari'@'%' identified by 'abc123';
> grant all on ambari.* to 'ambari'@'ambariserver.a.com' identified by 'abc123';
> grant all on ambari.* to 'ambari'@'ambariserver' identified by 'abc123';
数据库访问授权要指定访问主机,例如ambariserver,不然可能会导致ambari-server start 失败。
grant all on . to ‘root’@‘ambari.a.com’ identified by “abc123”; create database ambari character set
utf8; create user ‘ambari’@‘%’ identified by “abc123456”; grant all on . to ‘ambari’@‘%’; update
mysql.user set password=password(‘abc123456’) where user=‘ambari’;
验证
[root@localhost ~]# mysql -h ambariserver.a.com -uambari -pabc123
6.安装数据库连接工具
[root@localhost ~]#yum -y install mysql-connector-java
7.安装httpd
[root@localhost ~]# yum -y install httpd
[root@localhost ~]# systemctl enable httpd
8.解决已获取软件资源至/var/www/html及/var/www/html
[root@localhost ~]#tar xf ambari-2.6.1.0-centos7.tar.gz -C /var/www/html/
[root@localhost ~]#tar xf HDP-2.6.4.0-centos7-rpm.tar.gz -C /var/www/html
[root@localhost ~]#tar xf HDP-UTILS-1.1.0.22-centos7.tar.gz -C /var/www/html
[root@localhost ~]#tar xf HDP-GPL-2.6.4.0-centos7-rpm.tar.gz -C /var/www/html
9.配置本地YUM源
- ambari源
[root@localhost ~]# vim /etc/yum.repos.d/ambari.repo
[ambari-2.6.1.5]
name=ambari Version - ambari-2.6.1.5
baseurl=http://<web-server-ip> or FQDN /ambari/centos7/2.6.1.5-3
gpgcheck=1
gpgkey=http://<web-server-ip> or FQDN /ambari/centos7/2.6.1.5-3/RPM-GPG-KEY/RPM-GPGKEY-Jenkins
enabled=1
priority=1
- hdp源
[root@localhost ~]# vim /etc/yum.repos.d/ambari.repo
#VERSION_NUMBER=2.6.4.0-91
[HDP-2.6.4.0]
name=HDP Version - HDP-2.6.4.0
baseurl=http://<web-server-ip> or FQDN /HDP/centos7/2.6.4.0-91
gpgcheck=1
gpgkey=http://<web-server-ip> or FQDN /HDP/centos7/2.6.4.0-91/RPM-GPG-KEY/RPM-GPG-KEYJenkins
enabled=1
priority=1
[HDP-UTILS-1.1.0.22]
name=HDP-UTILS Version - HDP-UTILS-1.1.0.22
baseurl=http://<web-server-ip> or FQDN /HDP-UTILS/centos7/1.1.0.22
gpgcheck=1
gpgkey=http://<web-server-ip> or FQDN /HDP/centos7/2.6.4.0-91/RPM-GPG-KEY/RPM-GPG-KEYJenkins
enabled=1
priority=1
[HDP-GPL-2.6.4.0]
name=HDP-GPL Version - HDP-GPL-2.6.4.0
baseurl=http://<web-server-ip> or FQDN /HDP-GPL/centos7/2.6.4.0-91
gpgcheck=1
gpgkey=http://<web-server-ip> or FQDN /HDP-GPL/centos7/2.6.4.0-91/RPM-GPG-KEY/RPM-GPGKEY-Jenkins
enabled=1
priority=1
10.Linux内核参数修改
[root@localhost ~]#ulimit -Sn 软限制
[root@localhost ~]#ulimit -Hn 硬限制
[root@localhost ~]#vim /etc/security/limits.conf
* soft nofile 10240
* hard nofile 20480
2.2)部署Ambari Server
[root@localhost ~]#yum -y intsall ambari-server
2.3)初始化Ambari Server
2.3.1)初始化前导入数据库
[root@localhost ~]#mysql -h ambariserver.a.com -uambari -pabc123
>use ambari;
>source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql;
>show tables;
2.3.2)Ambari Server初始化
[root@localhost ~]#ambari-server setup
Customize user account for ambari-server daemon [y/n] (n)?y
Enter user account for ambari-server daemon (root):root
Do you want to change Oracle JDK [y/n] (n)? y
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Oracle JDK 1.7 + Java Cryptography Extension (JCE) Policy Files 7
[3] Custom JDK
==============================================================================
Enter choice (1): 3
Path to JAVA_HOME: /usr/local/jdk
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? n
Enter advanced database configuration [y/n] (n)? y
Configuring database...
==============================================================================
Choose one of the following options:
[1] - PostgreSQL (Embedded)
[2] - Oracle
[3] - MySQL / MariaDB
[4] - PostgreSQL
[5] - Microsoft SQL Server (Tech Preview)
[6] - SQL Anywhere
[7] - BDB
==============================================================================
Enter choice (3): 3
Hostname (localhost): ambari.a.com
Port (3306):3306
Database name (ambari):ambari
Username (ambari): ambari
Enter Database Password :abc123456
WARNING: Before starting Ambari Server, you must run the following DDL against the
database to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQLCREATE.sql
Proceed with configuring remote database connection properties [y/n] (y)?y
2.4)启动Ambari Server
[root@localhost ~]#ambari-server start
[root@localhost ~]#/sbin/chkconfig ambari-server on
出现ERROR时,如果退出码状态为非0或0,并报告没有8080端口启动,请稍等待片刻。
2.5)访问Ambari Server服务器
http://ambari.a.com:8080 登录用户名和密码均为:admin
2.6)Ambari Agent部署
Agent主动汇报所在节点状态情况
2.6.1)部署JDK
[root@localhost ~]#for i in hd{1..5};do scp -r /usr/local/jdk $i:/usr/local;done
在Ambari Server上拷贝到各Agent主机
2.6.2)部署YUM源
[root@localhost ~]#for i in hd{1..5};do scp -r /etc/yum.repos.d/ambari.repo
/etc/yum.repos.d/hdp.repo $i:/etc/yum.repos.d;done
在Ambari Server上拷贝到各Agent主机
2.6.3)部署Ambari Agent
[root@localhost ~]#yum -y install ambari-agent
[root@localhost ~]#systemctl start ambari-agent
[root@localhost ~]#/sbin/chkconfig ambari-agent on
报错解决方法:提示Connecting to https://amabri_server_host:8440/ca ERROR
解决方法如下:
[root@localhost ~]#rpm -qa | grep openssl
openssl-1.0.2k-12.el7.x86_64 openssl-libs-1.0.2k-12.el7.x86_64
[root@localhost ~]# vi /etc/python/cert-verification.cfg
[https]
verify=disable #修改
[root@localhost ~]#vim /etc/ambari-agent/conf/ambari-agent.ini
[security]
force_https_protocol=PROTOCOL_TLSv1_2 #添加一行
[root@localhost ~]#ambari-agent restart
yum -y install libtirpc-devel #centos7.6中要安装
以上问题处理需要在所有Ambari-agent主机上操作。
2.7)Ambari Server Web端操作



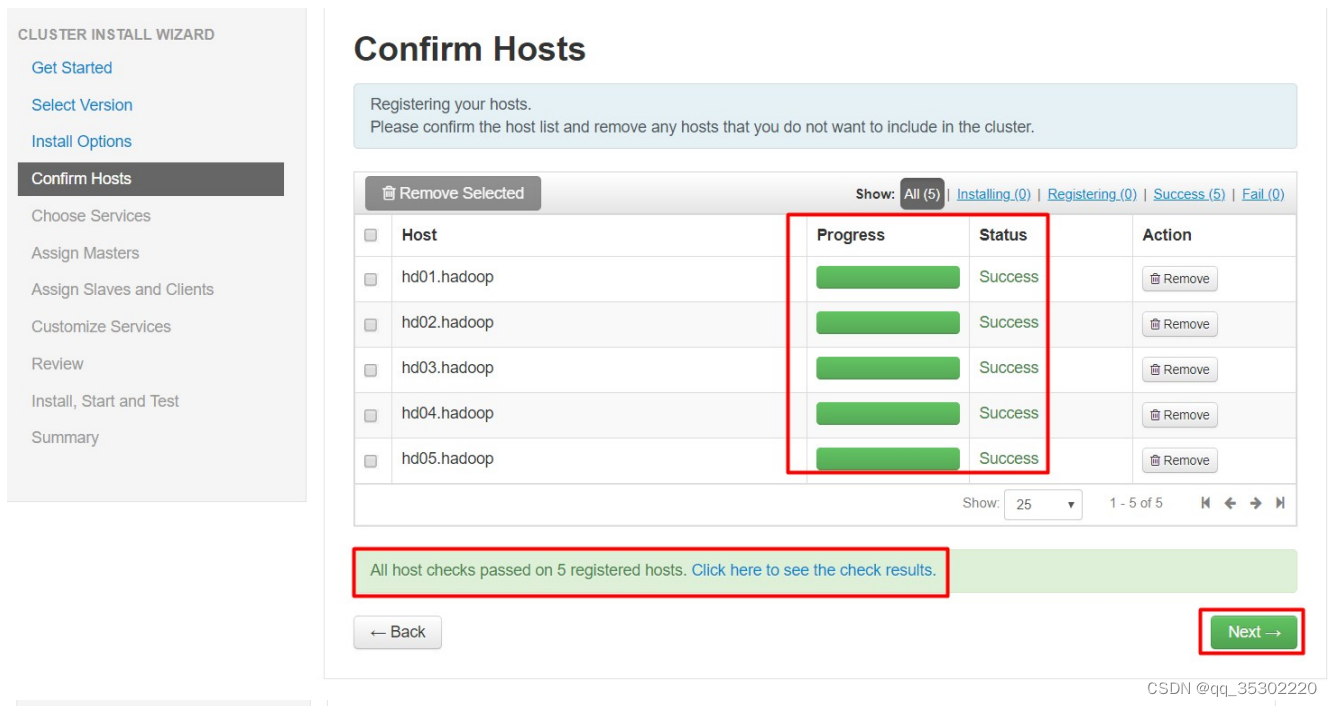
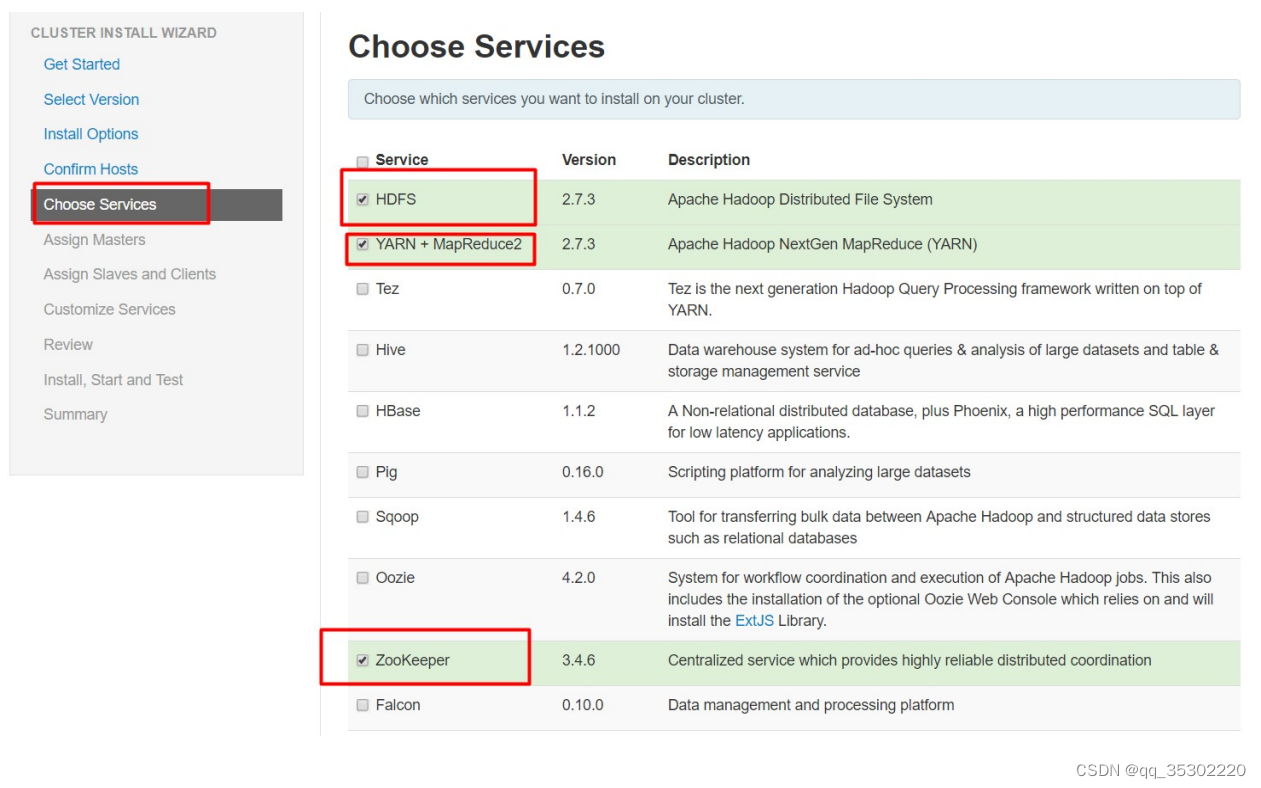
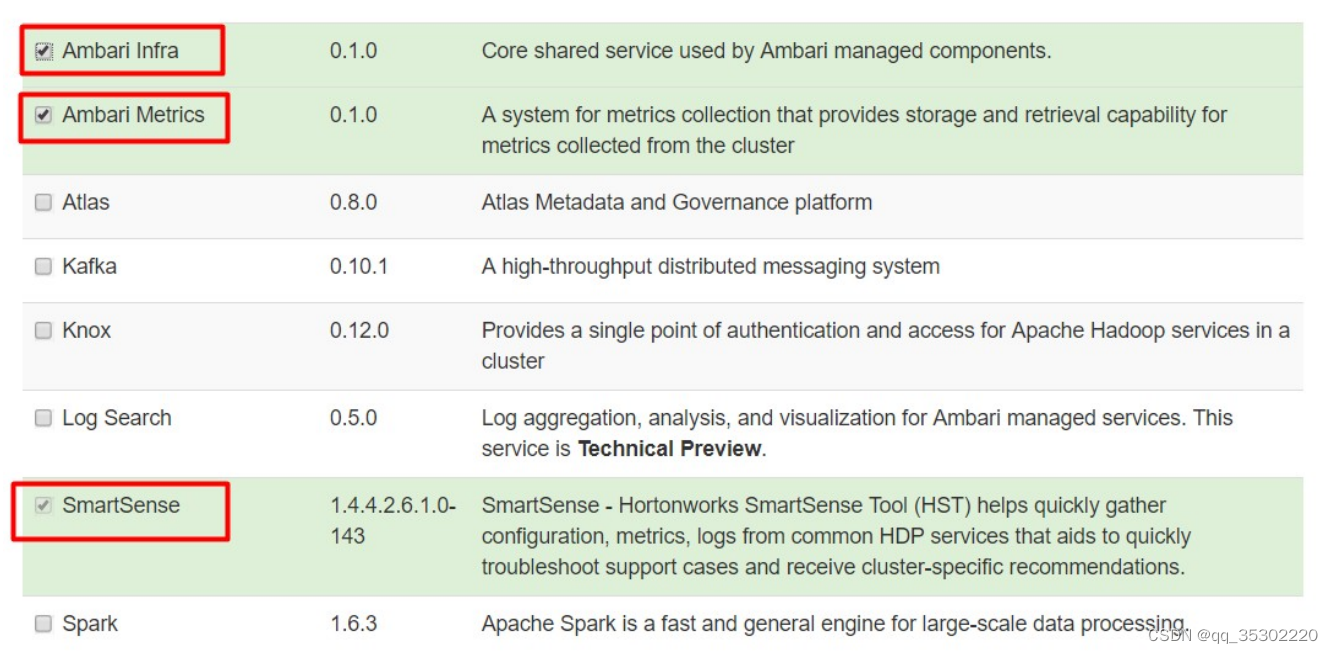

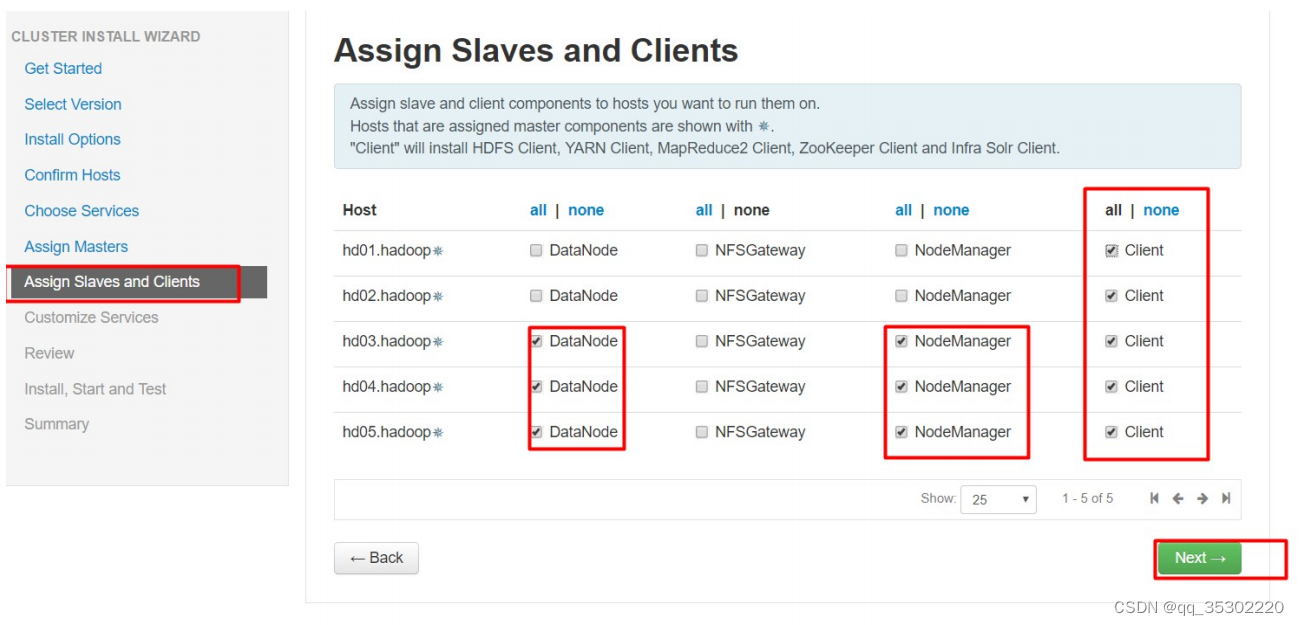
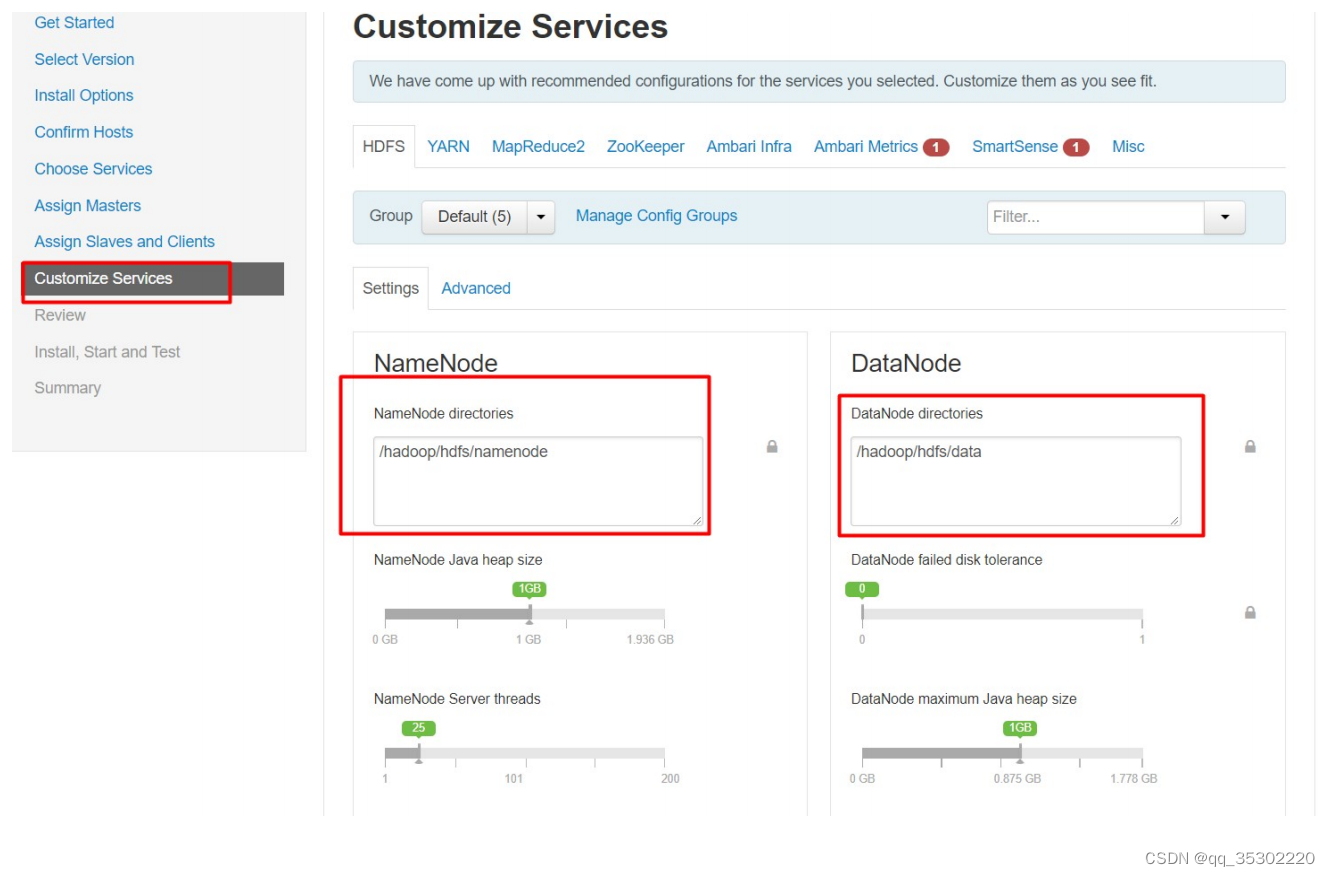

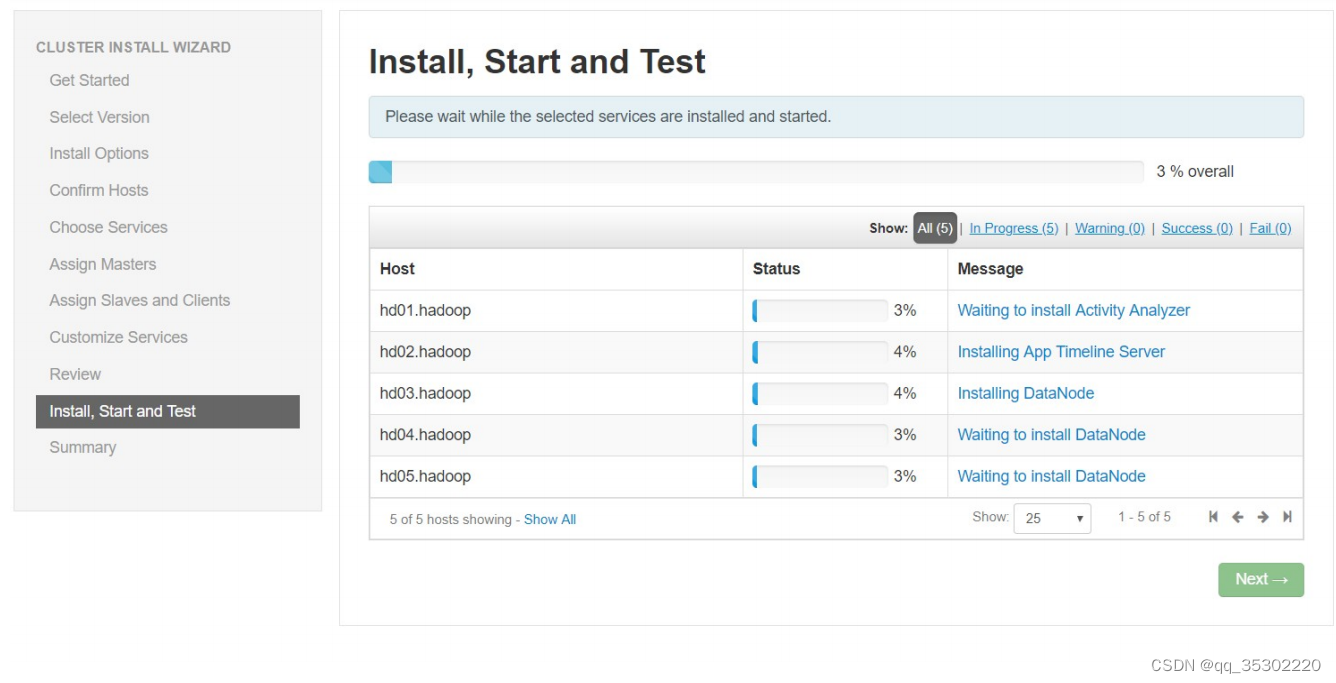

四、Hadoop监控
学习目标
- 能够通过Ambari实现Hadoop集群监控

五、验证Hadoop集群可用性
在任意一台已安装client服务器上均可做如下操作
[root@hd2 ~]# su - hdfs
[hdfs@hd2 ~]$ vim test.txt
tom
ken
192.168.1.1
[hdfs@hd2 ~]$ hdfs dfs -ls /
[hdfs@hd2 ~]$ hdfs dfs -mkdir /input
[hdfs@hd2 ~]$ hdfs dfs -put test.txt /input
[hdfs@hd2 ~]$ hadoop jar /usr/hdp/3.1.0.0-78/hadoop-mapreduce/hadoop-mapreduceexamples.jar wordcount /input /output
[root@hd2 ~]# hdfs dfs -cat /output/part-r-00000
192.168.1.1 1
ken 1
tom 1


![[附源码]Python计算机毕业设计SSM基于JAVA语言的宠物寄养管理(程序+LW)](https://img-blog.csdnimg.cn/b106f4b83f3141ec938f60d3336b7295.png)

![[附源码]Python计算机毕业设计SSM基于web的社团管理系统(程序+LW)](https://img-blog.csdnimg.cn/8ad3feb0d56b4a108c6490c7be94721b.png)

![[附源码]计算机毕业设计的小说阅读系统Springboot程序](https://img-blog.csdnimg.cn/73d5602892d74fe2828e44483b16f316.png)


![[附源码]Nodejs计算机毕业设计基于Web课堂签到管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/cb6e87ab6c944157a47ea5c78c6b1d4a.png)

