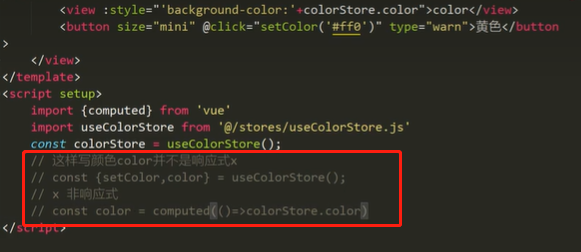
生成式AI技术无疑是当前最大的时代想象力之一。
资本、创业者、普通人都在涌入生成式AI里去一探究竟:“百模大战”连夜打响,融资规模连创新高,各种消费类产品概念不断涌现……根据Bloomberg Intelligence 的报告,2022年生成式AI 市场规模仅为400 亿美元,预计到2032年这一数字将突破1.3 万亿美元,未来10 年的年均复合增速高达42%。
然而,表面上看着热闹非凡,但生成式AI技术的普及和转化真的有我们想象的那么高吗?
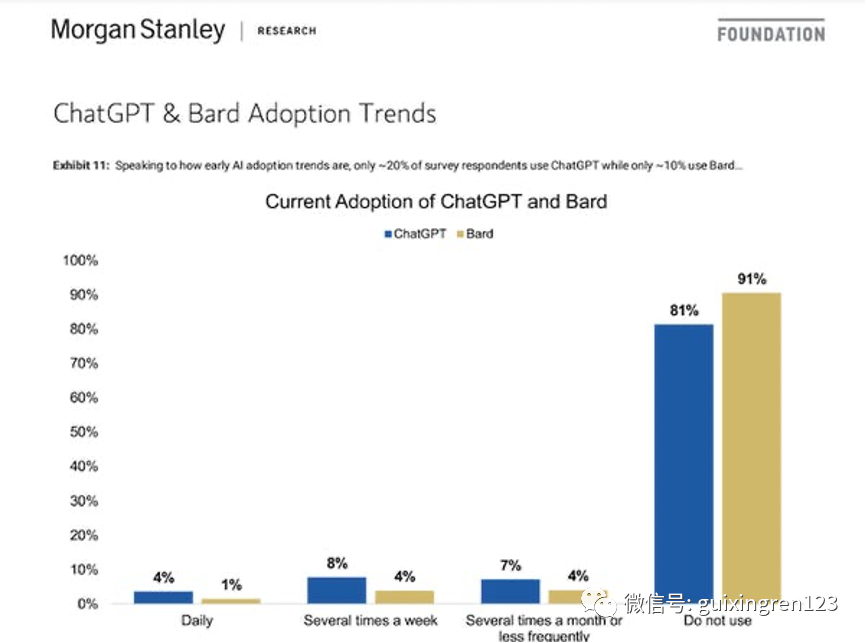
在经历了爆发式增长之后,6月以来,生成式AI聊天产品访问量几乎都出现了不同程度的下降。最新用户调查显示,有80%-90%以上的受访者表示未来六个月都完全不会使用ChatGPT、Bard等聊天工具。从消费端看,大家目前似乎更多地把生成式AI产品当成了一种追赶时尚潮流的玩具,而非持续使用的工具。
而在企业端,这样的现象就更为明显。一旦人们切换到工作模式时,生成式AI工具便很少出现在大家的工作流程中,甚至还被很多大型公司等明令禁止或限制性使用。
对于一个比较成熟技术的商业转化来说,6个多月的时间并不算短。但目前,关于生成式AI的狂想焦点似乎仍然还停留在大模型和产品概念上,人们预期所想看到的繁荣生态和对经济社会所产生的变革性影响还尚未到来。
那么,究竟是什么桎梏着它的发展?
生成式AI的落地之困:如何打破基础模型和开发者之间的“墙”?
所有人都不想错过生成式AI浪潮。但当前生成式AI的超高进入门槛,把大部分玩家挡在了门外。
过去这些年来,通过“深度学习+大算力”进行模型训练是实现人工智能最主流的技术途径。但大模型的商业化落地,必须得先回到成本核算上。
首先,大模型对算力的需求极大,是一个巨型“吞金兽”。GPT-3.5模型的训练一次的成本约在300万到460万美元之间,一些更大的语言模型训练成本甚至高达1200 万美元。自研大模型是一个“无底洞”,不具备雄厚资金实力的创业公司根本无法承担。
此外,通用模型并不能解决所有问题,能帮企业完成的事情非常有限。大模型的训练都是基于互联网上的公开数据完成,很多产品也相对孤立没有形成一个连贯的、整体的工作流,不具备定制化能力。意味着开发人员需要结合私有数据做大量个性化调试,开发训练门槛极高。
而由于前期的巨额投入,就算大模型开始商业化之后,要实现盈利也往往需要长时间的积累。因此,要想生成式AI技术真正落地到各行各业中发挥效力,当前急需一种可负担、高效率、低门槛的解决方案,让更多人参与到入生成式AI的开发中来。
那么,如何才能弥合从基础模型到终端应用之间的鸿沟?目前来看,提供一站式AI专业托管服务的云平台或许是当前的最佳解决路径。
云平台拥有充足、灵活的算力资源,中小型企业不必自行购买和维护昂贵的硬件设备,即可满足个性化的开发需求。用户可以通过 API和SDK,便捷地调用云平台上的第三方资源和大包服务,将他们的应用和服务与云平台无缝衔接,最大化简化开发流程。
此外,云平台还能够帮助解决数据的隐私安全问题。过去几个月来,包括苹果、三星、台积电、美国银行等很多大型企业都相继出台相关政策明令禁止员工使用ChatGP,纷纷开始自研大模型。而对于那些不具备自研实力的中小型企业来说,选择能够提供包括数据加密、身份验证、合规性工具等安全措施的云平台则是一个很好的低成本选项。

针对当前的生成式AI浪潮,云平台是否已经具备大模型开发的相当能力,能够提供生成式AI的全流程服务呢?
在刚刚落幕的亚马逊云科技纽约峰会上,我们看到了一份基于云的生成式AI完整解决方案。
亚马逊云科技,创建生成式AI普惠新范式
此次,亚马逊云科技延续了过去一贯的“务实”风格,瞄准当前生成式AI应用转化所面临的痛点问题,上新了一系列全新的功能和服务。从硬件到软件,从开发端到应用端,试图打造一个功能最全、能力最强的生成式AI服务平台。
-
Amazon Bedrock服务:搭建生成式AI开发的“快速通道”
针对开发层面基础模型训练成本昂贵、环境部署复杂的问题,今年4月,亚马逊云科技首次宣布推出Amazon Bedrock服务,允许用户通过可扩展、可靠且安全的亚马逊云科技托管服务,用API来便捷地访问来自不同供应商的基础模型,并利用它们来构建生成式AI应用程序。
当时,除了自家的Titan大模型之外,首发第三方合作商及基础模型还包括AI21 Labs的Jurassic-2,Anthropic的Claude,以及Stability AI的Stable Diffusion。在这次的纽约峰会上,亚马逊宣布再次增加前生成式AI领域的最大独角兽之一的Cohere作为供应商,也新增了包括Anthropic最新的语言模型 Claude 2,和Stability AI最新版文生图模型套件 Stable Diffusion XL 1.0等基础模型。
亚马逊云科技认为,未来一定不会是一个模型统管一切,Amazon Bedrock通过不断集成业界最领先的基础模型,用户将可以根据自身需求来便捷地调用最合适的模型。

但基础模型有了之后,还有一个棘手的问题没有解决——如何使用这些模型进行个性化的应用开发?云平台还要进一步解决私有数据学习、系统集成和调试以及任务自动执行的问题。
举一个我们在日常生活中经常会遇到的电商退换货的例子。你在电商平台买了双鞋子不太满意想要找客服换一个颜色,如果此时客服是ChatGPT等通用聊天机器人,他会怎么回答你?——“抱歉,我的训练数据截止日期是2021年9月,没有这双鞋的相关信息。”
要想让大模型真正发挥作用,首先要做的就是提前把公司内部跟这双鞋所有有关的信息都“喂”给模型,包括鞋的型号颜色、平台的退换货政策、库存信息等等,模型才能准确地给出反馈。在给出信息的同时,还需要AI一边聊天一边能在后台有序、安全地执行有关换货的所有操作。
在过去这对于开发者来说是一个庞大的工程,但现在,亚马逊新推出了一项名为Amazon Bedrock Agents服务,让这一切变得触手可及。
最新的Amazon Bedrock Agents服务能够在基础模型的基础上,把对话的定义、模型外部信息获取和解析、API调用、任务执行等打包成为一个全托管式的服务,从而能够及时、有针对性的输出结果。
如此一来,开发者不必重巨资从头开发自己的基础模型,也不要花费大量的时间和人力去进行模型的个性化部署和调试,从而能让开发者把更多的精力放在AI应用的构建和运营上,让不具备雄厚资金和技术实力的中小型开发者都可以加入到生成式AI浪潮中来。
-
“向量数据+硬件算力”双护航,铸造应用开发的最强大脑+最强底座
进行模型的定制开发,除了需要如Amazon Bedrock这样的专业托管服务,也需要计算、存储、安全等其他相关能力,来保证模型的持续可用、和迭代升级。
毋庸置疑,数据是人工智能出现和发展的基底。生成式AI为了学习和理解人类语言的复杂性,需要大量的训练数据,而这些训练数据通常是以“向量”的形式存在,也就是把自然语言转化为计算机可以理解和处理的数字。
那么,什么是向量数据,为什么它对生成式AI的发展至关重要呢?
假设你正在使用一个音乐推荐软件,我们可以把每首歌分别按照节奏、歌词、旋律等三个特征进行量化标记,比如第一首歌是(120,60,80),第二首歌是(100,80,70),当你告诉系统你喜欢第一首歌的节奏时,系统便会找到这首歌的节奏向量数据“120”,在数据库中查找与这个向量相似的其他向量,接着再把有相似特征的歌曲推荐给你。
当然,不止是三维,一个数据还可以被标注成更多纬度。在自然语言处理中,使用词嵌入技术表示的“词向量”通常是几百维的,而在图像处理中,使用像素值表示的图像向量可能有数千到数百万的维度。被“向量化”之后的数据将被存储在向量数据库之中,在高维空间中去高效地检索和生成最相关或最相似的数据。
然而,要将数据进行向量化处理和储存并不是一件容易的事,往往要耗费大量的人力和时间。针对这一问题,亚马逊云科技此次推出了适用于 Amazon OpenSearch Serverless 的向量引擎,该向量引擎能够支持简单的 API 调用,可用于存储和查询数十亿个 Embeddings(将高维度的数据映射到低维度空间的过程)。亚马逊云科技还表示,未来所有亚马逊云科技的数据库都将具有向量功能,在AI数据层面成为开发者的“最强大脑”。

除了向量引擎的支持,在算力层面,亚马逊云科技也一直致力于构建低成本、低延迟的云上基础设施。
亚马逊云科技和英伟达合作已超过12年,为人工智能、机器学习、图形、游戏和高性能计算等各种应用提供了大规模、低成本的 GPU 解决方案,在交付基于 GPU 的实例方面拥有无比丰富的经验。此次,亚马逊云科技展示了最新基于英伟达 H100 Tensor Core GPU 提供支持的P5实例,能够实现更低的延迟和高效的横向扩展性能。
P5 实例将是第一个利用亚马逊云科技第二代 Amazon Elastic Fabric Adapter(EFA)网络技术的 GPU 实例。与上一代相比,P5实例的训练时间最多可缩短6倍,从几天缩短到几小时,这一性能提升将帮助客户降低高达40%的训练成本。借助第二代 Amazon EFA,用户能够将其 P5 实例扩展到超过 2 万个英伟达 H100 GPU,为包括初创公司、大企业在内的所有规模客户提供所需的超级计算能力。
-
降低生成式AI门槛,用产品最大化赋能用户
除了面向生成式AI开发的工具和平台之外,在企业的日常运营之中需要一些能够拿来即用的生成式AI产品,来帮助提升工作和管理效率。关于这一点,亚马逊云科技也陆续推出了一些在工作场景中直接可以使用的产品,这些产品既覆盖底层开发人员也关注到了企业中大量的非技术人员。
比如在代码开发领域,自从亚马逊云科技在去年6月首次推出AI编程助手Amazon CodeWhisperer之后,现在该功能已经成为了很多开发者日常必备工具之一。
Amazon CodeWhisperer基于几十亿行开源代码训练,可以根据代码注释和现有代码实时生成代码建议,另外还能进行安全漏洞扫描。目前支持包括 Python、Java 和 JavaScript 15 种编程语言和包括 VS Code、IntelliJ IDEA、JupyterLab 和 Amazon SageMaker Studio等集成开发环境。
为了进一步提高开发效率,在纽约峰会上,亚马逊云科技正式宣布 Amazon Glue Studio Notebooks 也能支持 Amazon CodeWhisperer。通过 Amazon Glue Studio Notebooks,开发人员可以用自然语言编写特定任务,接着Amazon CodeWhisperer 可以直接在 Notebooks 中推荐一个或多个可完成此任务的代码片段,供开发人员直接使用和编辑。

Amazon CodeWhisperer支持语言和环境,图片来自亚马逊云科技官网
而对于非开发类工作场景,通过将 Amazon Bedrock的大语言模型能力与支持自然语言问答的 Amazon QuickSight Q 相结合,为用户提供了基于生成式AI的商业智能新服务。
比如你是一个财务分析师,你可以像跟ChatGPT聊天一样用自然语言下达命令,在几秒钟内Amazon QuickSight Q就能完成搜索关键财务信息或创建公司财务可视化图表的操作,同时还能帮你总结出趋势特点并提出建议。
类似拿来即用的产品还有帮助企业打破内部信息孤岛、加快数据驱动决策的Amazon Entity Resolution,以及能够帮助医疗软件供应商便捷地构建基于生成式AI的临床应用程序的Amazon HealthScribe等等,在各行各业扩大着生成式AI产品的使用场景。
释放AI时代的“云力量”
生成式AI的发展需要云,更需要大量基于云的工具和服务。
大模型之后,下一阶段生成式AI技术一定会朝着多样性和个性化方向发展,我们既可以看到比较通用的生产力工具,也会看到各种瞄准特定场景的AI产品。而在这个过程中,云平台会起到越来越关键的作用。
一方面,云平台会大大降低AI应用开发的门槛。在平台的算力和基础模型支持下,开发者们基本无需关心硬件和基础设施的问题,从而把更多的时间和精力放在业务和运营上。另一方面,云平台能够持续加快AI应用的开发和运营效率。用户可以通过直接调用API的方式进行应用的开发和管理,并安全、便捷地在团队或组织之间共享。
在云平台的助力之下,未来的生成式AI将不再只是一场巨头才能玩的“烧钱游戏”,更多普通人也将可以坐上牌桌。
作为云服务领域的行业领导者之一,亚马逊云科技提供了200多种服务,涵盖了计算、存储、数据库、网络、开发者工具、安全、分析、物联网、企业应用等广泛领域,云基础设施覆盖全球。同时,亚马逊云科技还是人工智能和机器学习领域的领先者,多年来持续提供和更新着一系列端到端的AI相关服务,让开发者可以灵活、便捷、低成本的开发和部署生成式AI应用。
此次,亚马逊云科技发布生成式AI工具“全家桶”,其核心目的就是要进一步降低生成式AI开发的门槛,让更多不懂大模型、不懂人工智能的普通人也能快速加入生成式AI的开发和应用之中。
生成式AI的重要性不在于模型有多大能力有多强,更重要的还是如何能够从基础模型演变成各个领域中的具体应用,从而赋能整个经济社会的发展。
现在,亚马逊云科技正在成为那个桥梁。
![[HDLBits] Exams/m2014 q4c](https://img-blog.csdnimg.cn/img_convert/5bccfb0c6b59e6a4ea6bc98f71998fe9.png)