前言:Hello,大家好😘,我是心跳sy,上一节我们主要学习了格式化输入输出的基本内容,这一节我们对格式化进行更加深入的了解,对文件概念进行介绍,并且对输入、输出与文件读写的基本概念进行学习,本节主要对printf,scanf深入了解,并介绍文件处理函数,如fprintf,fopen,fclose,freopen,tmpfile,tmpnam,fflush,setvbuf,setbuf以及其他文件操作函数进行理解,对字符的输入输出(putchar,getchar,fputc,fgetc)行的输入输出(puts,fputs,gets,fgets)块的输入输出(fread,fwrite)以及字符串的输入和输出(sprintf,snprintf,sscanf)会到下一节介绍,我们一起来看看吧💞💞💞!!!
c语言的输入/输出库非常庞大,并且是c语言的高级应用,我们前面已经学会使用printf,scanf函数的基本用法,这一节我们主要对文件操作进行介绍,并对格式化输入输出函数进行深入的了解,上一节还没太懂的友友们看完这一篇相信会有更加深入的了解~
我们知道文件读写是许多应用程序不可缺少的部分,在计算机编程中起着至关重要的部分,它允许程序通过读入和写入文件来持续化数据,以此来实现数据的长期保存和共享;而文件读写的基本概念是通过输入输出操作来与计算机上的文件进行交互,所以我们需要熟练掌握运用❗️❗️
本篇文章对各个示例均有详细的解释,对难理解的概念也进行了详细的诠释,耗时几天完成,内容较长,精心打造,无cv,概念均参考权威书籍。友友们耐心看完,放心食用,没学过文件和有关输入输出的友友们也能看懂哦~😘😘😘
1、⭐️流的概念⭐️
👉在c语言中,流表示任意输入的源或任意输出的目的地,可以想象成水流,只不过c语言的流更富有逻辑顺序概念,它提供和储存数据,产生数据的叫做输入流,消耗数据的叫做输出流,c程序与数据的交互都是以流的形式进行的,而我们下来介绍的文件读写就是先“打开文件”以打开数据流,然后“关闭文件”以关闭数据流;我们之前学习的printf,scanf就是格式化的输出函数、输入函数,所属的流是标准流,我们接下来会详细介绍~🌈🌈
1.1、💫文件指针
👉 一般形式:FILE *指针变量标识符;c程序中对流的访问是通过文件指针实现的,文件指针的类型是FILE *(FILE类型在头<stdio.h>中声明),其中文件指针表示的特定流具有标准的名字,比如stdin指针(标准输入流)等,如果用户需要,也可以自定义流:FILE *fp;(注意操作系统通常会限制可以同时打开的流,但程序可以声明任意数量的FILE *类型变量。)
1.2、💫标准流和重定向
👉c语言头<stdio.h>提供了3个标准流(同样c++中头<iostrream>也提供了标准输入输出流,我们以后介绍),c语言中这3个标准流可以直接使用,不需要对其进行声明,也不用打开或关闭它们。下图提供3个标准流:

👉这3个标准流的应用非常广泛,我们经常使用的printf,scanf,putchar,getchar,puts,gets函数都是通过stdin获得输入,通过stdout进行输出的。默认情况下,stdin表示键盘,stdout和stderr表示屏幕,然而许多操作系统允许通过重定向的机制来改变这些默认的含义。
👉通常我们可以强制程序从其他文件获得输入而不是从键盘那里,方法是在命令行中放上文件的名字,并在其前面加上字符小于号<,跟在程序名后面:(这里demo是指程序,意为demo程序代码里面的stdin,将指向文件in.dat,即从in.dat中获取数据)
demo<in.dat⭕️这种方法叫做输入重定向,它的本质是使stdin流表示文件(in.dat)而非键盘,其精妙之处在于demo程序不会意识到在从文件in.dat中读取数据,它会认为从stdin获得的任何数据都是从键盘输入的。
⭕️输出重定向与输入重定向类似,对stdout流的重定向是通过在命令行中放置文件名,并在其前加上字符大于号>实现:
demo>out.dat👉现在所有写入stdout流的数据都将进入out,dat文件中,而不是出现在屏幕上。值得一提的是😃,我们还可以把输入重定向和输出重定向结合起来使用,而且<,>字符不用与文件名相邻,重定向文件的顺序也无关紧要,下面两个例子是等效的:
demo < in.dat > out.dat
demo >out.dat <in.dat⚠️需要注意的是,输出重定向有一个问题,就是会把写入stdout的所有内容都放入文件中,如果程序运行失常或写出出错消息,那么我们在看文件的时候才能发现,而这些应该是出现在stderr中的,所以通过把出错消息写到stderr而不是stdout中,可以保证即使在对stdout重定向时,出错消息仍能显示到屏幕上。(比如linux c语言用perror()函数将错误消息写入标准错误stderr)
1.3、💫文本文件与二进制文件
👉<stdio.h>支持两种类型的文件:文本文件和二进制文件。我们知道,计算机的储存在物理上是二进制的,所以文本文件与二进制文件的区别不是物理上的,而是逻辑上的,两者只在编码层次上有差异,简单的来说,文本文件是基于字符编码的文件(人们可以检查和编辑文件),常见的编码有ASCII编码、UNICODE编码等等,例如c程序的源代码是储存在文本文件中;二进制文件是基于值编码的文件,其中字节除了可以表示字符,还可以表示其他类型的数据,比如浮点数和整数。
👉如果上面概念还未完全理解,我们再次深入理解: 文本文件基于字符编码,基本上是定长编码(也有非定长如UTF-8),每个字符在具体编码中是固定的,如ASCII码是8个比特的编码,UNICODE一般占16个比特。而二进制文件可看成是变长编码,因为是值编码,多少比特代表一个值,完全由自己决定,所以比较灵活,节约空间。
👉我们来看一个栗子🌸:当存储实型数字时,如3.1415927,文本文件需要9个字节,分别存储:3 . 1 4 1 5 9 2 7这9个字符的ASCII值;而二进制文件只需要4个字节:DB 0F 49 40
👉我们经常会遇到用记事本打开文件乱码的情况,原因如何❓
🌸文本工具打开一个文件,首先读取文件物理上所对应的二进制比特流,然后按照所选择的解码方式来解释这个流,然后将这个解释结果显示出来。一般来说,选取的解码方式会是ASCII码形式(一个字符8个比特),接下来它会8个比特8个比特地来解释文件流,记事本无论打开什么文件都按既定的字符编码工作(ASCII码),所以当打开一个二进制文件时,就会出现乱码,因为解码和译码不对应。
⚠️文本文件具有两种二进制文件没有的特性:
⭕️1、文本文件分为若干行。文本文件的每一行通常以一两个特殊字符结尾,特殊字符的选择与操作系统有关。在Windows中,行末的标记是回车符('\x0d')与一个紧跟其后的回行符('\x0a')。在UNIX和Macintosh操作系统(Mac OS)新版中,行末的标记是一个单独的回行符。
- \x0d代表回车字符,它的ASCII码值为13(十进制)。在文本文件中,回车字符通常用于表示光标返回到当前行的开头,但不换行。
- \x0a代表换行字符,它的ASCII码值为10(十进制)。换行字符用于在文本文件中表示将光标移动到下一行的开头。
在不同的操作系统和编程环境中,回车和换行字符的使用方式可能会有所不同:
- 在Windows操作系统中,通常使用回车和换行两个字符(\r\n)来表示换行,即先回车再换行。(\r的ASCII码就是13,是回车;\n的ASCII码为10,是换行,与\x0a,\x0d等价)
- 在Unix/Linux操作系统和类Unix环境(如macOS)中,通常只使用换行字符(\n)来表示换行。
- 在早期的Macintosh操作系统中,通常只使用回车字符(\r)来表示换行。
⭕️2、文本文件可以包含一个特殊的“文件末尾”标记。一些操作系统允许在文本文件的末尾使用一个特殊的字节作为标记。在Windows中,标记为'\xla'(Ctrl+Z)。Ctrl+Z不是必须的,但如果存在,它就标志着文件的结束,其后的所有字节都会被忽略。使用Ctrl+Z的这一习惯继承自DOS(磁盘操作系统),而DOS中的这一习惯又是从CP/M(早期用于个人计算机的一种操作系统)来的。大多数其他操作系统(包括UNIX)没有专门的文件末尾字符。
⭕️二进制文件不分行,也没有行末标记和文件末尾标记,所有字节都是平等对待的。
2、⭐️文件操作⭐️
👉输入输出重定向虽然简单易懂,但是在许多程序中受限制,当程序依赖重定向时,它无法控制自己的文件,甚至无法知道这些文件的名字,也无法同时写入或读入两个文件,所以这时我们将使用<stdio.h>提供的文件操作,我们下面一起来学习打开、关闭文件、改变缓冲文件的方式以及怎样删除文件和重命名文件!!😃😃
2.1、💫打开文件(fopen函数)


👉如果要把文件用作流,打开时就需要调用fopen函数,也叫作打开文件流。fopen的第一个参数是含有要打开文件名的字符串,其值应符合运行环境的文件名规范,可以包含路径位置信息(如果系统支持)。第二个参数是“模式字符串”,它用来指定打算对文件执行的操作,例如字符串“r”表示从文件读入数据,但不会向文件写入数据,我们下面会详细介绍。
⚠️注意,从C99开始,对fopen函数原型声明用restrict关键字进行修饰,这表明filename和mode所指向的字符串的内存单元不共享。
⚠️⚠️⚠️注意在Windows系统中,fopen函数调用用的文件名中含有字符 \ 时,一定要小心,c语言会把 \ 看作转义字符的开始标志。如下图:
fopen("c:\test_8_9\test1.dat", "r")以上调用会失败,因为编译器会把 \t 看作转义字符,所以有效的办法是用 \\ 来代替 \ 或者直接使用 / 代替 \ 。如下两种方法都可行:
fopen("c:\\test_8_9\\test1.dat", "r")fopen("c:/test_8_9/test1.dat", "r")👉 fopen函数返回一个文件指针,程序通常把此指针存储在一个变量中,然后后续使用时直接使用,fopen函数常见调用形式如下,其中fp是FILE*类型的变量,当程序调用输入函数从文件in.dat中读取数据时,会把fp作为实参。
👉当无法打开文件时,fopen函数会返回一个空指针,其原因可能是因为文件位置不对或者我们没有打开文件的权限。
fp = fopen("in.dat", "r");🔴我们看下面的一个例子:下面的例子fopen函数的一个参数是文件路径,第二个参数模式字符串中采用了“w”意为打开文件“写”:
#include<stdio.h>
int main()
{
FILE* fp = fopen("C:\\Users\\樊双艺\\Desktop\\c.txt.txt", "w");
if (fp != NULL)
{
fprintf(fp, "Hello, world!\n");
fclose(fp);
}
return 0;
}我们可以看到文本文件中写入了Hello,world!

⚠️⚠️⚠️这个例子有几点需要大家注意:
⭕️永远不要假设可以打开文件,每次都要测试 fopen函数的返回值以确保不是空指针,所以这里我们用 if语句来判断 fp是否为空,这里的 fprintf函数稍后介绍,我们现在只需要知道它的第一个参数是指向要写入文件的指针。
⭕️当成功写入文件后,我们需要关闭文件,一定要注意这是配套存在的❗️❗️❗️
2.2、💫模式
👉fopen函数的第二个参数要传递哪种模式字符串不仅依赖于稍后我们想对文件进行什么操作,还取决于文件中的数据是文本形式还是二进制形式。
👉下图为文本文件的模式字符串:

👉下图为二进制文件的模式字符串:当使用fopen打开二进制文件时,需要在模式字符串包含字母b(UNIX系统中文本文件与二进制文件具有完全相同的格式,所以不需要字母b,但是UNIX程序员仍应该包含字母b,便于代码移植)

⭕️从两个表格可以看出,头<stdio.h>对写数据和追加数据进行了区分:当给文件写数据时,通常会对先前的内容进行覆盖;然而,当为追加文件时,向文件写入的数据添加在文件末尾,因而可以保留文件的原始内容。
⭕️另外,带有字母“x”的打开模式是从C11才开始引入的,这个字母表示独占模式。在这种模式下,如果文件已经存在或者无法创建,fopen函数将执行失败;否则文件将以独占(非共享)模式打开。
⭕️图中带有“+”的字符串(也就是当打开文件用于读和写)时,需要先调用一个文件定位函数,不然就不能从读转为写,除非读遇到文件末尾;相应的如果既没调用fflush函数,也没有文件定位函数,那么就不能由写模式转为读模式。文件定位函数我们下节会介绍,fflush函数稍微会介绍。
2.3、💫关闭文件(fclose函数)

👉fclose函数允许程序关闭不再使用的文件,也叫作关闭文件流。fclose函数的参数必须是文件指针,此指针来自fopen函数或freopen函数(稍后介绍)的调用,如果成功关闭了文件,flcose函数会返回零,否则它会返回错误代码EOF。
✔️实例见fopen函数实例,程序员注意成对使用即可。
2.4、💫为已打开的流附加文件 (freopen函数)

👉freopen函数为已经打开的流附加一个不同的文件(简单地说用于重定向输入输出流)。最常见的用法是把文件和一个标准流(前文介绍的3只)相关联,可以在不改变代码原貌的情况下改变输入输出环境。其中三个参数,filename是需要重定向到的文件名或文件路径,mode代表模式字符串,stream是需要被重定向的文件流。
👉返回值:通常是它的第三个参数(文件指针),如果无法打开文件则返回NULL。
⭕️下面实例表示往foo文件写数据:其中假设freopen返回值为NULL,所以打不开foo文件。
if (freopen("foo", "w", stdout) == NULL)
{
//erro;foo can not be opened
}2.5、💫从命令行获取文件名
👉当正在编写的程序需要打开文件时,就会出现一个问题:如何把文件名提供给程序呢?最好的解决方案是让程序从命令行获取文件的名字,例如,当执行名为demo的程序时,可以通过把文件名放入命令行的方法为程序提供文件名:
demo names.dat dates.dat🌈这里我们要通过定义带有两个形式参数的main函数来访问命令行参数,我们下面介绍原理,会的友友们可以直接跳过~💞
2.5.1、💫命令行参数
👉运行程序时经常需要提供一些信息——文件名或者改变程序行为的开关,如果我们要访问这些命令行信息参数,必须通过把main函数定义为含有两个参数的函数来实现,这两个参数通常命名为argc和argv。形式如下:
int main(int argc, char* argv[])
{
...
}👉argc(“参数计数”)是命令行参数的数量(包括程序名本身),argv(“参数向量”)是指向命令行参数的指针数组,这些命令行参数以字符串的形式存储,argv[0]指向程序名,而从argv[1]到argv[argc-1]则指向余下的命令行参数。
👉argv有一个附加元素,即argv[argc],这个元素始终是一个空指针(NULL)。
⭕️我们来看一个例子:
👉如果用户输入命令行:ls -l remind.c (这里的 ls 是Linux的命令,ls 命令是“ list ”的缩写,用于列出或显示目录的内容。而 ls -l 是 ls 的命令参数,会以长列表格式显示文件,内含文件的详细信息,这里我们只介绍这一种参数,还有很多关于 ls 命令的功能,友友们下来可以了解了解🥳 )
👉那么argc将为3,argv[0]将指向含有程序名的字符串,argv[1]将指向字符串“-l ”,argv[2]将指向字符串“remind.c”,而argv[3]将为空指针。如下图:

👉图中没有详细的程序名,因为操作系统的不同,程序名可能会包括路径或其他信息,如果程序名不可用,那么argv[0]会指向空字符串。
👉因为argv是指针数组,所以访问命令行参数非常容易,常见的做法是,期望有命令行参数的程序会设置循环来按顺序检查每一个参数。设定循环的方法之一就是使用整型变量作为argv数组的下标。例如,下面的循环每行一条地显示命令行参数:
int i;
for (i = 1; i < argc; i++)
{
printf("%s\n", argv[i]);
}👉另一种方法是构造一个指向argv[1]的指针(argv[1]本就是指向字符的指针,所以必须构造二级指针指向字符指针),然后对指针重复进行自增操作来逐个访问数组余下的元素。因为argv数组的最后一个元素始终是空指针,所以循环可以在找到数组中一个空指针时停止。例如:
char** p;
for (p = &argv[1]; *p != NULL; p++)
{
printf("%s\n", *p);
}⚠️注意:这里我们设置了一个字符型二级指针,p是指向字符的指针的指针,p=&argv[1]是有意义的,因为argv[1]是一个字符指针,所以&argv[1]就是指向指针的指针,因为*p和NULL都是指针,所以测试*p!=NULL没有问题,p指向数组元素首元素地址,所以p自增可以指向下一个字符;printf中显示*p也是合理的,因为*p指向字符串的第一个字符,存放第一个字符地址,字符串常量的内存储存是连续的,所以可以直接打印出整个字符串。(如果还是不太理解的友友可以学习一下二级指针再理解一下代码解释~💞)
⭕️通过上面的介绍我们基本清楚了如何定义带有两个形式参数的main函数来访问命令行参数,我们回到从命令行获取文件名这一模块;一起来看看之前提到的例子:
demo names.dat dates.dat👉我们已经知道argc是命令行参数的数量,而argv是指向参数字符串的指针数组。argv[0]指向程序的名字,从argv[1]到argv[argc-1]都指向剩余的实际参数,而argv[argc]是空指针。在上述例子中,argc为3,argv[0]指向含有程序名的字符串,argv[1]指向字符串“names.dat”,argv[2]指向字符串“dates.dat”,argv[3]指向空。所以我们就可以通过匹配命令行参数数量来判断文件是否具有文件名,并且通过argv[]指针来找到文件名。
2.6、💫临时文件(tmpfile函数和tmpnam函数)
 👉现实生活中程序经常需要产生临时文件,即只在程序运行时存在的文件,例如C编译器就常常产生临时文件。编译器可能先把c程序翻译成一些储存在文件中的中间形式,稍后把程序翻译成目标代码时,编译器就会读取这些文件。一旦程序完全通过了编译,就不再需要保留那些含有程序中间形式的文件了。头<stdio.h>中提供了两个函数来处理临时文件,即tmpfile函数和tmpnam函数。
👉现实生活中程序经常需要产生临时文件,即只在程序运行时存在的文件,例如C编译器就常常产生临时文件。编译器可能先把c程序翻译成一些储存在文件中的中间形式,稍后把程序翻译成目标代码时,编译器就会读取这些文件。一旦程序完全通过了编译,就不再需要保留那些含有程序中间形式的文件了。头<stdio.h>中提供了两个函数来处理临时文件,即tmpfile函数和tmpnam函数。
👉tmpfile函数创建一个临时文件(用“wb+”模式打开),该临时文件将一直存在,除非关闭它或程序终止。tmpfile函数的调用会返回文件指针,如果临时文件创建失败,函数会返回空指针,此指针可以用于稍后访问该文件。
FILE* tempptr;
tmpptr = tmpfile();//创建一个临时文件,tmpptr是临时指针变量⚠️虽然tmpfile函数很易于使用,但是它有两个缺点:
⭕️无法知道tmpfile函数创建的文件名是什么;
⭕️无法在以后使文件变为永久的。
如果这些缺点导致了问题,那么备用方案就是用fopen函数产生临时文件,因为我们不想让此文件与前面已存在的文件拥有相同的名字,所以需要一个新函数产生新的文件名,就是tmpnam函数。
👉tmpnam函数为临时文件产生名字。如果它的实际参数是空指针,那么tmpnam函数会把文件名储存到一个静态变量中,并且返回指向此变量的指针。
char* filename;
...
filename = tmpnam(NULL);//创建一个临时文件名👉否则,tmpnam函数会把文件名复制到程序员提供的字符数组中:(在这种情况下,tmpnam函数一样会返回指向数组第一个字符的指针,L_tmpnam是在头文件中定义的宏,它指明了保存临时文件名的字符数组至少的长度)
char filename[L_tmpnam];
...
tmpnam(filename);2.7、💫文件缓冲(fflush函数、setvbuf函数、setbuf函数)

👉向磁盘驱动器传入数据或者从磁盘驱动器传出数据都是相对较慢的操作,因此在每次程序想读或写入字符时都直接访问磁盘文件是不可行的。这时一个效率高的方法就是缓冲,把写入流的数据存储在内存的缓冲区域内;当缓冲区满了(或者关闭流)时,对缓冲区进行“清洗”(写入输出设备)。比如printf函数在输出时,是先输出到缓冲区,然后才输出到屏幕上的,输入流可以用类似的方法进行缓冲:缓冲区包含来自输入设备的数据;我们可以从缓冲区读取数据而不是从设备本身直接读取数据。缓冲区的存在大大提高了读取效率,当然,把缓冲区的内容传给磁盘或从磁盘传递给缓冲区也是需要花时间的,但是大规模的“块”移动总比多次小字节速度快得多。✔️
头<stdio.h>中的函数会在缓冲有用时自动进行缓冲操作。缓冲是在后台发生的,但在极少的时候需要我们更主动的操作,这就需要用到上述3个函数。
👉当程序向文件写输出时,数据通常先放在缓冲区中。当缓冲区满了或者关闭文件时,缓冲区会自动清洗(向输出设备写入),有时我们期望通过一定频率来清洗文件的缓冲区,就需要调用fflush函数,fflush函数的参数是指向指定缓冲流的FILE对象的指针,如果函数调用成功,则返回0,否则返回EOF。下面调用的含义就是释放清洗指定流的缓冲区。
fflush(fp);👉而如果需要清洗和fp相关联的文件,那么就调用下面实例,清洗了全部输出流:
fflush(NULL);//flushes all buffers👉setvbuf函数允许改变缓冲流的方法,并且允许控制缓冲区的大小和位置。也可以理解为该函数可指定流的缓冲区,并且允许指定缓冲区的模式和大小(以字节为单位)。函数第一个参数是指向文件对象的指针,该对象标识打开的流。函数的第二个参数是用户分配的缓冲区的地址,长度至少为字节大小。如果设置为空指针,该函数将自动分配一个缓冲区,需指定缓冲区大小,若调用成功,函数返回0,否则返回非0;函数的第三个参数是期望的缓冲类型模式,有三种缓冲类型,分别定义为3个宏,我们等会列表展示;最后一个参数是缓冲区内字节的数量(缓冲区大小),较大的缓冲区可以提供较好的性能,而较小的缓冲区可以节约空间。
👉下图为函数第三个参数——3个宏定义缓冲类型模式 ,其中全缓冲又叫满缓冲:

👉⚠️上述3个宏均在头<stdio.h>中定义,对于没有与交互式设备相连的流来说,满缓冲是默认设置。
⭕️下面的例子调用setvbuf函数,把buffer数组的N个字节作为缓冲区,把stream的缓冲变成了满缓冲:
char buffer[N];
...
setvbuf(stream,buffer,_IOFBF,N);👉setbuf函数是一个较早期的函数,现在的新程序用得不多了,它设定了缓冲模式和缓冲区大小的默认值。
如果buffer是空指针(无缓冲),那么setbuf(stream,buffer)的调用就等价于:
(void)setbuf(stream,NULL,_IONBF,0);否则等价于(满缓冲),这里的BUFFERSIZ是在头文件中定义的宏:
(void)setbuf(stream,buffer,_IOFBF,BUFFERSIZ);⚠️注意:使用setvbuf函数和setbuf函数时,一定要确保在释放缓冲区之前已经关闭了流,特别是如果缓冲区是局部于函数的,并且有自动存储期,一定要确保在函数返回之前关闭流。
2.8、其他文件操作(remove函数和rename函数)

👉remove函数和rename函数允许程序执行基本的文件管理操作。不同于其他文件处理函数,这两个函数对文件名(而不是文件指针)进行处理,操作不涉及流,如果调用成功,那么这两个函数都返回0,否则都返回非0.
⭕️remove函数删除已经指定文件名的文件:
remove("foo"); //删除文件名为“foo”的文件👉如果程序使用fopen函数(而不是tmpfile函数,因为tmpfile函数无法知道创建的临时文件的文件名是什么)来创建临时文件,那么它可以使用remove函数在程序终止前删除此文件。一定要确保已经关闭了要移除的文件,因为对于当前打开的文件,移除文件的效果是由实现定义的。
⭕️rename函数改变文件的名字:
rename("foo","bar"); //改变文件名由“foo”变为“bar”👉对于用fopen函数创建的临时文件,如果程序需要使文件变为永久的,那么用rename函数改名就可以了。如果具有新名字的文件已经存在了,改名的效果会由实现定义。
⚠️注意:如果打开了要改名的文件,一定要记住在调用rename函数之前关闭此文件,对打开的文件执行改名操作会失败。
🌈这里的实现定义英文名称是implementation-defined,意为由编译器设计者来决定采取某种行动的,这个词语提醒我们,在实际编程时要考虑在多个运行环境下程序会产生不一样的结果的情况。
3、⭐️深入理解格式化输入输出⭐️(printf,fprintf,scanf,fscanf函数)
上节我们介绍了格式化输入输出的基本用法,上节介绍的基本概念已经够我们前期使用,这节我们继续对格式化输入输出函数进行深入介绍,并介绍格式化输入输出函数与流结合的用法,我们一起来看看吧~
3.1、💫...printf函数与fprintf函数

👉fprintf和printf函数向输出流中写入可变数量的数据项,并且利用格式串来控制输出的格式。这两个函数的定义原型都是以 ...(省略号)结尾的,表明后面还可能有可变数量的实际参数。这两个函数的返回值都是写入的字符数,若出错则返回一个负值。
👉fprintf函数与printf函数唯一不同的地方就是printf函数始终指向stdout(标准输出流)写入内容,而fprintf函数则向它自己的第一个实际参数指定的流中写入内容。
printf("number:%d\n",number); //写入标准输出流
fprintf(fp,"number:%d\n",number); //写入fp所指向的流⭕️下面实例展示了调用fprintf函数向fp指定文件流中写入内容:
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE* fp;
fp = fopen("C:\\Users\\樊双艺\\Desktop\\file.txt", "w+");
fprintf(fp, "%s %s %s %d", "We", "are", "in", 2023);
fclose(fp);
return(0);
}文件显示内容如下:

🌈可以看出:printf函数的调用等价于fprintf函数把stdout作为第一个实际参数而进行的调用。
⭕️和<stdio.h>中其他函数一样,fprintf函数不仅可以把数据写入磁盘文件,还可以用于任何输出流,事实上,fprintf函数最常见的应用之一是——向标准误差流(stderr)写入出错消息,和磁盘文件没有任何关系。下面调用类似实例:
fprintf(stderr,"Error:data file can not be opened.\n");👉向stderr写入出错消息可以保证消息输出在屏幕上,即使用户重定向stdout也没关系。
🌈【在<stdio.h>中还有另外两个函数也可以向流写入格式化的输出,分别是vfprintf函数和vprintf函数,这两个函数都不太常见,我们下节介绍。】
3.2、💫...printf函数转换说明
👉fprintf函数和printf函数都要求格式串包含普通字符或转换说明。普通字符会原样输出,而转换说明则描述了如何把剩余的实参转换为字符格式显现出来。现在我们对上节课的转换说明内容进行回顾,并补充深入内容。
👉...printf函数的转换说明由字符%和跟随其后的最多5个不同的选项构成:

下面进行解释,选项的顺序必须与上面一致:
🌈标志(可选项,允许多于一个)。标志 - 会导致数在栏内左对齐,而其他标志会影响数的显示形式,如下表:

⭕️示例:标志作用于%d转换(其他类似),第一行显示了不带任何标志的效果,接下来四行分别显示带有标志-、+、空格、0的效果(标志#从不用于%d,关于#的示例会在介绍完转换指定符后展示)。剩下几行为组合标志的效果:
int main()
{
int i = 123;
printf( "%8d\n", i);
printf( "%-8d\n", i);
printf( "%+8d\n", i);
printf( "% 8d\n", i);
printf( "%08d\n", i);
printf("%-+8d\n", i);
printf("%- 8d\n", i);
printf("%+08d\n", i);
printf("% 08d\n", i);
return 0;
}运行结果如下:
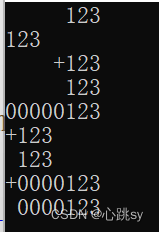
分析如下:

🌈最小栏宽(可选项),要输出的字符的最小数目。如果数据太小以至于无法达到这一宽度,那么会进行填充(默认情况下会在数据的左侧添加空格,从而使其在栏内右对齐。)如果数据项过大以至于超过了这个宽度,那么会完整的显示数据项。栏宽既可以是整数也可以是字符 * 。如果栏宽是字符 * ,那么栏宽由下一个参数决定,如果这个参数为负,它会被视为前面带 - 标志的正数。
🌈精度(可选项),精度的含义依赖于转换指定符:如果转换指定符是d,i,o,u,x,X,那么精度表示最少位数(如果位数不够,则添加前导0);如果转换指定符是a,A,e,E,f,F,那么精度表示小数点后的位数;如果转换指定符是g,G,那么精度表示有效数字的个数;如果转换指定符是s,那么精度表示最大字节数。精度是由小数点( . )后跟一个整数或字符 * 构成的。如果出现字符 * ,那么精度由下一个参数决定,如果只有小数点,则精度为0。
⭕️示例:最小栏宽和精度结合作用于转换说明%s的效果
int main()
{
char arr[10] = "bogus";
printf( "%6s\n", arr);
printf( "%-6s\n", arr);
printf( "%.4s\n", arr);
printf( "%6.4s\n", arr);
printf("%-6.4s\n", arr);
return 0;
}
分析如下:

🌈长度指定符(可选项)。长度指定符配合转换指定符,共同指定转入的实际参数的类型(例如:%d通常表示一个int值,而%hd用于显示short int值;%ld用于显示long int值)。

👉另外C99中还定义了长度转换符hh(字符型或无符号字符型) 例如:signed char/unsigned char;以及长度指定符 j 和 t ,这两个不常见,我们以后遇到后介绍。
👉转换指定符n(表中未指出),适配于任何整型长度指定符,长度类型符与转换说明结合时的类型均为指针类型。
🌈转换指定符(必有)。 转换指定符必须是下表中列出的某一种字符。注意f、F、e、E、g、G、a和A全部设计用来输出double类型的值。但把它们用于float类型的值也可以:由于有默认实参提升,float类型实参在传递给带有可变数量实参的函数时会型自动转换为double类。类似的,传递给...printf函数的字符也会自动转换为int类型,所以可以正常使用转换指定符c。

注意:
👉C99时新定义了a、A两个转换说明,使用格式[-]0xh.hhhhp±d的格式把double类型转换为十六进制科学计数法形式。其中[-]是可选的负号,h代表十六进制数位,±是正号或负号,d是指数,d为十进制数,表示2的幂。a表示用小写形式显示a-f,A表示用大写形式显示A-F。
👉支持宽字符:从C99开始就可以使用fprintf来输出宽字符。%le转换说明用于输出一个宽字符,%ls用于输出一个由宽字符组成的字符串。
⭕️示例:说明了标志#作用于o、x、X、g、G转换效果
int main()
{
int i = 123;
printf( "%8o\n", i);
printf("%#8o\n", i);
printf( "%8x\n", i);
printf("%#8x\n", i);
printf( "%8X\n", i);
printf("%#8X\n", i);
return 0;
} 
分析如下:

⭕️示例:说明了%g转换如何以%e和%f的格式显示数
int main()
{
printf("%.4g\n", 123456.);
printf("%.4g\n", 12345.6);
printf("%.4g\n", 1234.56);
printf("%.4g\n", 123.456);
printf("%.4g\n", 12.3456);
printf("%.4g\n", 1.23456);
printf("%.4g\n", 0.123456);
printf("%.4g\n", 0.0123456);
printf("%.4g\n", 0.00123456);
printf("%.4g\n", 0.000123456);
printf("%.4g\n", 0.0000123456);
printf("%.4g\n", 0.00000123456);
return 0;
}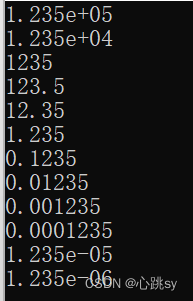
分析如下:

🌈值得说说的是,用字符 * 填充格式串往往会带来奇妙的结果,我们来看一个例子:
int main()
{
int i = 123;
printf("%6.4d\n", i);
printf("%*.4d\n", 6, i);
printf("%6.*d\n", 4, i);
printf("%*.*d\n", 6, 4, i);
return 0;
}
👉可以看出:这四次输出都完全相同,用字符 * 取代最小栏宽度或者精度,为字符 * 填充的值刚好出现在待显示的值之前。这就可以体现出字符 * 的优势,就是在于它允许使用宏来指定栏宽或精度:
printf("%*d",WIDTH);3.3、💫...scanf函数与fscanf函数

👉fscanf函数和scanf函数从输入流读入数据,并且使用格式串来指明输入的格式。格式串后面可以有任意数量的指针(每个指针指向一个对象)作为额外的实际参数。输入的数据项根据格式串中的转换说明进行转换并且存储在指针指向的对象中。
👉scanf函数始终从标准输入流stdin中读入内容,而fscanf函数则从它的第一个参数所指定的流中读入内容:
scanf("%d%d",&i,&j); //从标准输入流读入
fscanf(fp,"%d%d",&i,&j); //从指定流读入👉可以看出scanf函数的调用等同于以stdin作为第一个实际参数的fscanf函数的调用。
⚠️需要注意的是:如果发生输入失败(即没有输入字符可以读)或者匹配失败(即输入字符和格式串不匹配),那么...scanf函数会提前返回。scanf和fscanf函数都返回读入并且赋值给对象的数据项的数量。如果在读取任何数据项之前发生输入失败,那么会返回EOF。
3.4、💫...scanf函数格式串
👉scanf函数的调用类似于printf函数的调用,但它们的工作原理完全不同,我们常把scanf函数和fscanf函数看作“模式匹配函数”,这个概念我们上节提过,这里的匹配就是指scanf函数在读取输入时的输入的内容与格式串的匹配,scanf函数是一个要求极其苛刻的函数,它只要发现不匹配,函数就会返回不再进行读取,而不匹配的字符及其以后的字符将会被“放入原处”,等待下一次读取。
scanf函数的格式串可能含有三种信息:
🌈转换说明:scanf函数格式串中的转换说明类似于printf函数格式串中的转换说明。大多数的转换说明(除了%[ 、%c、%n例外)会跳过输入项开始处的空白字符。但是,转换说明不会跳过尾部的空白字符。如果输入含有(空格123回车),那么转换说明%d会读取空格、1、2、3,但是会留下回车不读取。又例如:%d%d%d 是按十进值格式输入三个数值。输入时,在两个数据之间可以用一个或多个空格、tab 键、回车键分隔。
🌈空白字符:scanf格式串中的一个或多个空白字符与输入流空白字符相匹配。
🌈非空白字符:包括一些普通字符,除%外用户必须保证输入的内容与格式串字符相匹配。
3.5、💫...scanf函数转换说明
scanf函数的转换说明由字符%和跟随其后的下列选项(按照出现的顺序)构成:
🌈字符 * (可选项)。字符 * 的出现意味着赋值屏蔽;这是一个可选的星号,表示数据是从流 stream 中读取的,可以被忽视,表示读入此数据但是不会把它赋值给对象。用 * 匹配的数据项不包含在scanf函数返回的计数中。(注意区别于printf函数)
🌈最大栏宽(可选项)。最大栏宽限制了输入项字符的数量。注意printf函数中是最小栏宽,如果达到了这个最大限度,那么此数据项的转换将结束。转换开始处跳过的空白字符不进行统计。
🌈长度指定符(可选项)。长度指定符表明用于存储输入数据项的对象的类型与特定转换说明中常见的类型长度不一致。(与printf函数长度指定符只有 [ 字符不一样)

🌈转换指定符(必有):转换指定符必定是下表列出的某一种字符:
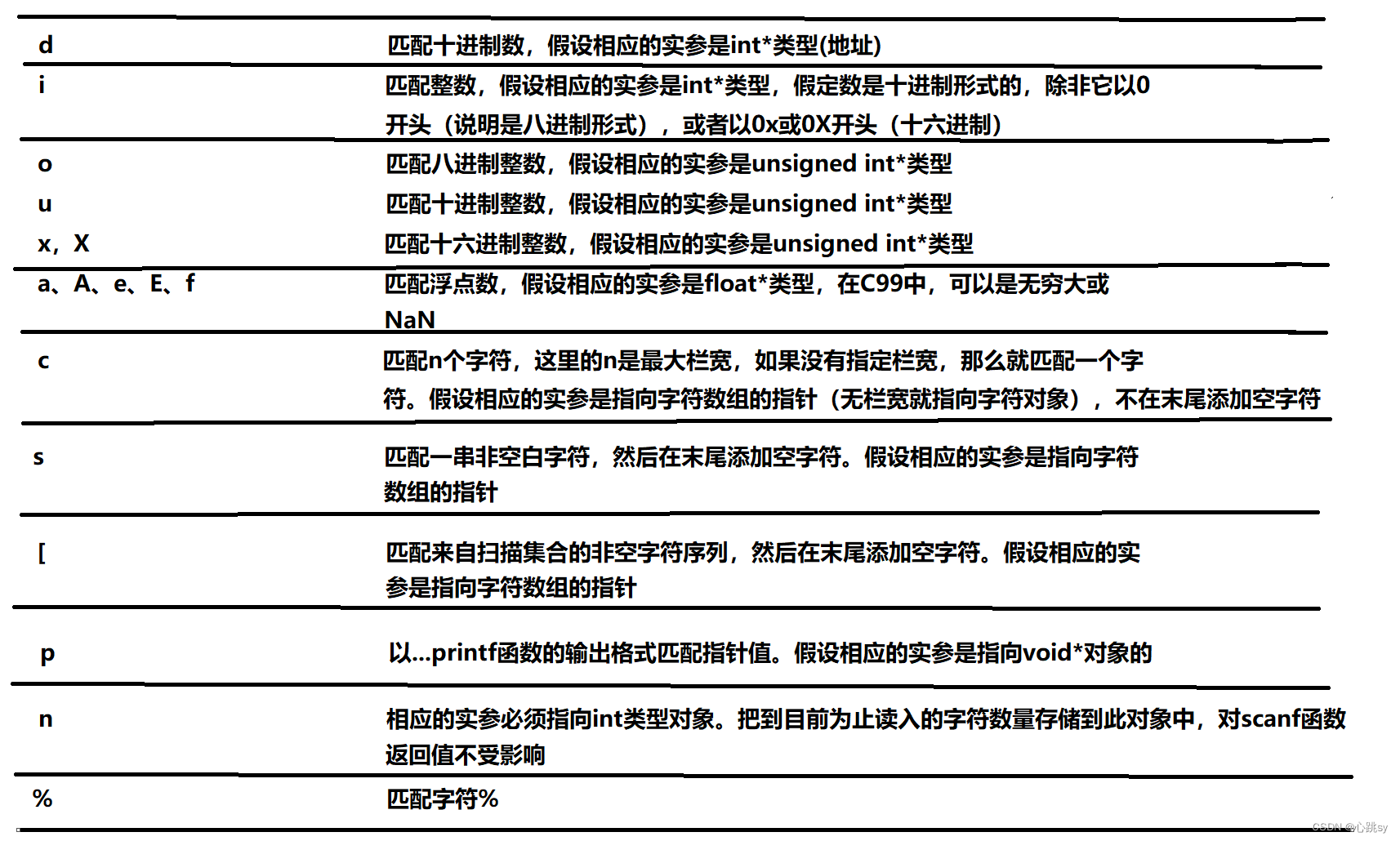
解释如下:
👉数值型数据项可以始终用符号(+或 -)作为开头。然而,说明符o,u,x,X把数据项转换成无符号的形式,所以通常不用这些说明符来读取负数。
👉说明符 [ 是说明符s更加复杂(更加灵活)的版本,使用 [ 的完整转换说明格式是%[集合]或者%[^集合] ,这里的集合可以是任意字符集。(但是如果 ] 是集合中的一个字符,那么它必须首先出现。)%[集合]匹配集合(即扫描集合)中的任意字符序列。%[^集合]匹配不在集合中的任意字符序列(我们可以理解为数学上的补集,我们匹配的就是补集的内容)。例如:%[abc]匹配的是只含有字母a,b,c的任何字符串,而%[^abc]匹配的是不含有字母a,b,c的任何字符串。
⭕️示例:
#include<stdio.h>
int main()
{
int a, b, c;
printf("请输入三个数字:");
scanf("%d, %d, %d", &a, &b, &c);
printf("%d, %d, %d\n", a, b, c);
return 0;
}
⚠️使用scanf时一定要注意格式串的对应,像上面的例子1,2,3之间必须输入逗号,否则会造成匹配错误,如下图:

123会被当成第一个输入对象,并存入a中,接下来2与逗号不匹配,scanf提前返回,b和c的内容为无效值。
⭕️示例 转换指定符 [ 的效果:
#include<stdio.h>
int main()
{
char str[20] = { 0 };
int n = 0;
n = scanf("%[0123456789]", str);
printf("%d %s", n, str);
return 0;
}
可以看出对于转换说明%[0123456789],我们输入 123abc,它只匹配含有0123456789的字符,所以只输出123,返回值为赋值给对象的数据项的数量。
3.6、💫检测文件末尾和错误条件(clearerr函数、feof函数、ferror函数)

我们知道,...scanf函数读入并存储n个数据项,那么我们就希望它的返回值就是n,如果返回值小于n,那么一定是出错了,一共有三种情况:
✔️文件末尾。函数在完全匹配格式串之前遇到了文件末尾。
✔️读取错误。函数不能从流中读取字符。
✔️匹配失败。数据项的格式是错误的,例如,函数可能在搜索整数的第一个数字时遇到了一个字母。
但是如何知道遇到的情况是哪种呢❓
👉每个流都有与之相关的两个指示器:错误指示器和文件末尾指示器,当打开流时会清除这些指示器。遇到文件末尾就设置文件末尾指示器,遇到读错误就设置错误指示器。(输出流上发生写错误时也会设置错误指示器。)匹配失败不会改变任何一个指示器。
👉一旦设置了错误指示器或者文件末尾指示器,他就会保持这种状态直到被显示的清除(可能通过clearerr函数的调用)。C 库函数 void clearerr(FILE *stream) 清除给定流 stream 的文件结束和错误标识符:
clearerr(fp); //同时清除指定流的文件末尾指示器和错误指示器👉因为其他库函数因为副作用可以清除某种指示器或两种都可以清除,所以不需要经常使用clearerr函数。
👉我们可以调用feof函数和ferror函数来测试流的指示器,从而确定出先前在流上的操作失败的原因。C 库函数 int feof(FILE *stream)会测试给定流 stream 的文件结束标识符,如果为与fp相关的流设置了文件末尾指示器,那么feof(fp)函数调用就会返回非零值。C 库函数 int ferror(FILE *stream) 会测试给定流 stream 的错误标识符。如果设置了错误指示器,那么ferror(fp)函数的调用也会返回非零值,而其他情况下,这两个函数都会返回零。
👉如果我们想知道当scanf函数返回小于预期的值是什么情况,可以使用feof函数和ferror函数来确定原因。如果feof函数返回了非零的值,那么就说明已经到达了输入文件的末尾。如果ferror函数返回了非零的值,那么就表示在输入过程中产生了读错误。如果两个函数都没有返回非零值,那么一定是发生了匹配错误。不管问题是什么,scanf函数的返回值都会告诉我们在问题产生前所读入的数据项的数量。
⭕️我们来看一个示例:应用feof和ferror函数,自定义一个搜索文件中以整数起始的行,下面是自定义函数的调用,其返回值赋值给n。
n=find_int("foo");其中“foo”是要搜索文件的名字,函数返回找到的整数的值并将其赋值给n,如果出现问题(文件无法打开或者发生读错误,再或者没有以整数起始的行),find_int函数将返回一个错误的值(-1,-2,-3)
int find_int(const char* filname)
{
FILE* fp = fopen(filename, "r");
int n;
if (fp == NULL)
{
return -1; //不能打开文件
}
while (fscanf(fp, "%d", &n) != 1)
{
if (ferror(fp))
{
fclose(fp);
return -2; //输入错误
}
if (feof(fp))
{
fclose(fp);
return -3; //找不到整数
}
scanf(fp, "%*[^\n]");
}
fclose(fp);
return n;
}分析:

🌈至此我们有关文件的基本操作以及对格式化输入输出的详细理解就结束了~~本节主要对文件的基本操作进行介绍,下一节会对如何把单独的字符、一行数据和块数据怎么输入输出文件流进行介绍,涉及函数(putchar,getchar,fputc,fgetc)行的输入输出(puts,fputs,gets,fgets)块的输入输出(fread,fwrite)以及字符串的输入和输出(sprintf,snprintf,sscanf),我们到时再进行详细介绍。
🌈感谢各位友友们花费了宝贵的时间来阅读本篇文章,创作不易,希望大家多多支持呀😘😘😘,如在阅读中发现任何问题,欢迎各位友友大佬们在评论区指正支持❗️ ❗️ ❗️