我们先看一下默认的 HashMap的设置

什么是 加载因子?
HashMap的底层是哈希表,是存储键值对的结构类型,它需要通过一定的计算才可以确定数据在哈希表中的存储位置:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//AbstractMap
public int hashCode() {
int h = 0;
Iterator<Entry<K,V>> i = entrySet().iterator();
while (i.hasNext())
h += i.next().hashCode();
return h;
}
一般的数据结构,不是查询快就是插入快,HashMap就是一个插入慢、查询快的数据结构。但这种数据结构容易产生两种问题:① 如果空间利用率高,那么经过的哈希算法计算存储位置的时候,会发现很多存储位置已经有数据了(哈希冲突);② 如果为了避免发生哈希冲突,增大数组容量,就会导致空间利用率不高。
而加载因子就是表示Hash表中元素的填满程度。
加载因子 = 填入表中的元素个数 / 散列表的长度
加载因子越大,说明填满程度越高,发生哈希冲突的频率越大,有可能会加大计算存储时间的耗时。
加载因子越小,说明空间利用率低,等于说以空间换时间了属于是。
影响查找效率的因素主要分为3部分?
1、散列函数存入hash的时候 是否均匀
2、加载因子的大小
3、怎么样处理的冲突
解决冲突有什么方法?
1. 开放定址法
Hi = (H(key) + di) MOD m,其中i=1,2,…,k(k<=m-1)
H(key)为哈希函数,m为哈希表表长,di为增量序列,i为已发生冲突的次数。其中,开放定址法根据步长不同可以分为3种:
1.1 线性探查法(Linear Probing):di = 1,2,3,…,m-1
简单地说,就是以当前冲突位置为起点,步长为1循环查找,直到找到一个空的位置,如果循环完了都占不到位置,就说明容器已经满了。举个栗子,就像你在饭点去街上吃饭,挨家去看是否有位置一样。
1.2 平方探测法(Quadratic Probing):di = ±12, ±22,±32,…,±k2(k≤m/2)
相对于线性探查法,这就相当于的步长为di = i2来循环查找,直到找到空的位置。以上面那个例子来看,现在你不是挨家去看有没有位置了,而是拿手机算去第i2家店,然后去问这家店有没有位置。
1.3 伪随机探测法:di = 伪随机数序列
这个就是取随机数来作为步长。还是用上面的例子,这次就是完全按心情去选一家店问有没有位置了。
但开放定址法有这些缺点:
这种方法建立起来的哈希表,当冲突多的时候数据容易堆集在一起,这时候对查找不友好;
删除结点的时候不能简单将结点的空间置空,否则将截断在它填入散列表之后的同义词结点查找路径。因此如果要删除结点,只能在被删结点上添加删除标记,而不能真正删除结点;
如果哈希表的空间已经满了,还需要建立一个溢出表,来存入多出来的元素。
2. 再哈希法
Hi = RHi(key), 其中i=1,2,…,k
RHi()函数是不同于H()的哈希函数,用于同义词发生地址冲突时,计算出另一个哈希函数地址,直到不发生冲突位置。这种方法不容易产生堆集,但是会增加计算时间。
所以再哈希法的缺点是:
增加了计算时间。
3. 建立一个公共溢出区
假设哈希函数的值域为[0, m-1],设向量HashTable[0,…,m-1]为基本表,每个分量存放一个记录,另外还设置了向量OverTable[0,…,v]为溢出表。基本表中存储的是关键字的记录,一旦发生冲突,不管他们哈希函数得到的哈希地址是什么,都填入溢出表。
但这个方法的缺点在于:
查找冲突数据的时候,需要遍历溢出表才能得到数据。
4. 链地址法(拉链法)
将冲突位置的元素构造成链表。在添加数据的时候,如果哈希地址与哈希表上的元素冲突,就放在这个位置的链表上。
拉链法的优点:
处理冲突的方式简单,且无堆集现象,非同义词绝不会发生冲突,因此平均查找长度较短;
由于拉链法中各链表上的结点空间是动态申请的,所以它更适合造表前无法确定表长的情况;
删除结点操作易于实现,只要简单地删除链表上的相应的结点即可。
拉链法的缺点:
需要额外的存储空间。
从HashMap的底层结构中我们可以看到,HashMap采用是数组+链表/红黑树的组合来作为底层结构,也就是开放地址法+链地址法的方式来实现HashMap。
图片
至于为什么在JDK1.8的时候要运用到红黑树,下篇文章会介绍。
为什么HashMap加载因子一定是0.75?而不是0.8,0.6?
从上文我们知道,HashMap的底层其实也是哈希表(散列表),而解决冲突的方式是链地址法。HashMap的初始容量大小默认是16,为了减少冲突发生的概率,当HashMap的数组长度到达一个临界值的时候,就会触发扩容,把所有元素rehash之后再放在扩容后的容器中,这是一个相当耗时的操作。
而这个临界值就是由加载因子和当前容器的容量大小来确定的:
临界值 = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR
即默认情况下是16x0.75=12时,就会触发扩容操作。
那么为什么选择了0.75作为HashMap的加载因子呢?笔者不才,通过看源码解释和大佬的文章,才知道这个跟一个统计学里很重要的原理——泊松分布有关。
泊松分布是统计学和概率学常见的离散概率分布,适用于描述单位时间内随机事件发生的次数的概率分布。有兴趣的读者可以看看维基百科或者阮一峰老师的这篇文章:[泊松分布和指数分布:10分钟教程][10]
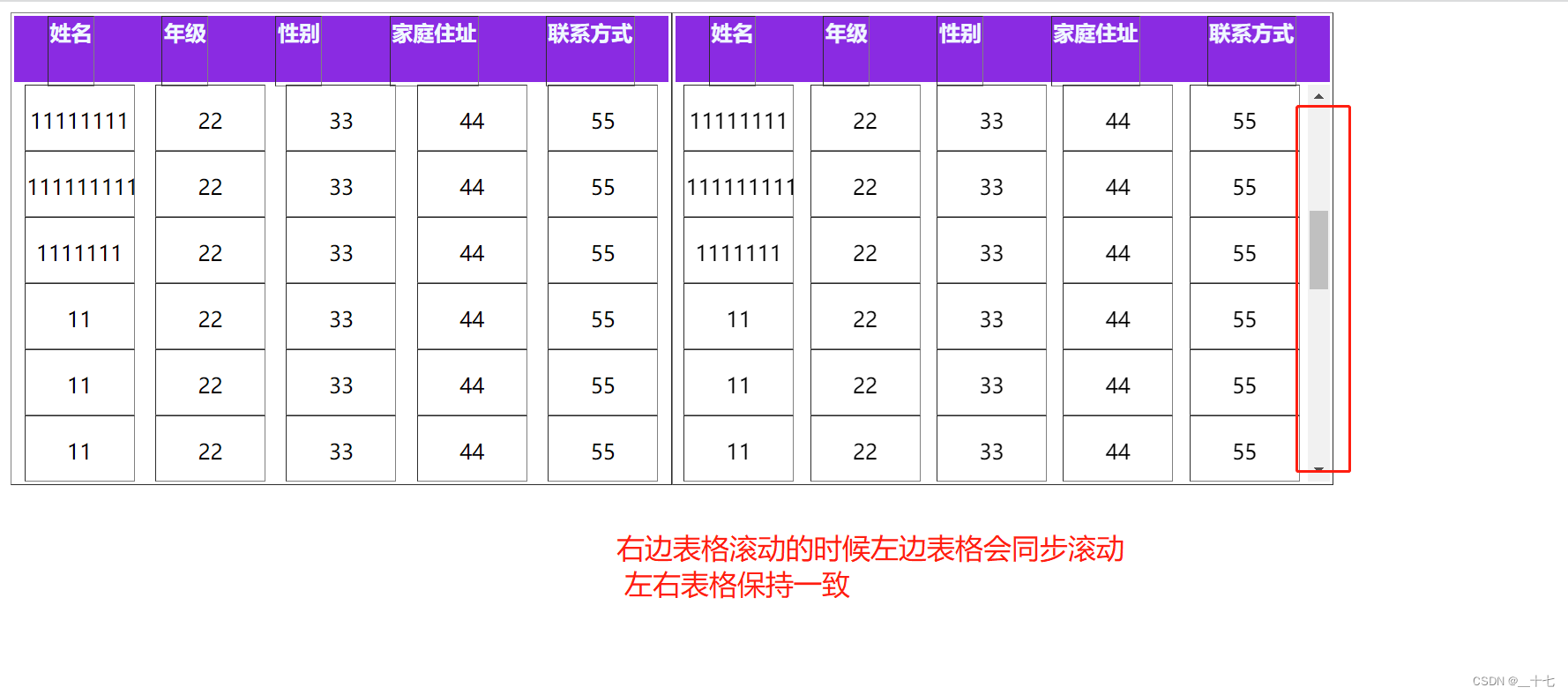
图片
等号的左边,P 表示概率,N表示某种函数关系,t 表示时间,n 表示数量。等号的右边,λ 表示事件的频率。
在HashMap的源码中有这么一段注释:
/* Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
笔者拙译:在理想情况下,使用随机哈希码,在扩容阈值(加载因子)为0.75的情况下,节点出现在频率在Hash桶(表)中遵循参数平均为0.5的泊松分布。忽略方差,即X = λt,P(λt = k),其中λt = 0.5的情况,按公式:
图片
计算结果如上述的列表所示,当一个bin中的链表长度达到8个元素的时候,概率为0.00000006,几乎是一个不可能事件。
所以我们可以知道,其实常数0.5是作为参数代入泊松分布来计算的,而加载因子0.75是作为一个条件,当HashMap长度为length/size ≥ 0.75时就扩容,在这个条件下,冲突后的拉链长度和概率结果为:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
那么为什么不可以是0.8或者0.6呢?
HashMap中除了哈希算法之外,有两个参数影响了性能:初始容量和加载因子。初始容量是哈希表在创建时的容量,加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量。
在维基百科来描述加载因子:
对于开放定址法,加载因子是特别重要因素,应严格限制在0.7-0.8以下。超过0.8,查表时的CPU缓存不命中(cache missing)按照指数曲线上升。因此,一些采用开放定址法的hash库,如Java的系统库限制了加载因子为0.75,超过此值将resize散列表。
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少扩容rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,以便减少扩容操作。
选择0、75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择。
初始化调用resize方法
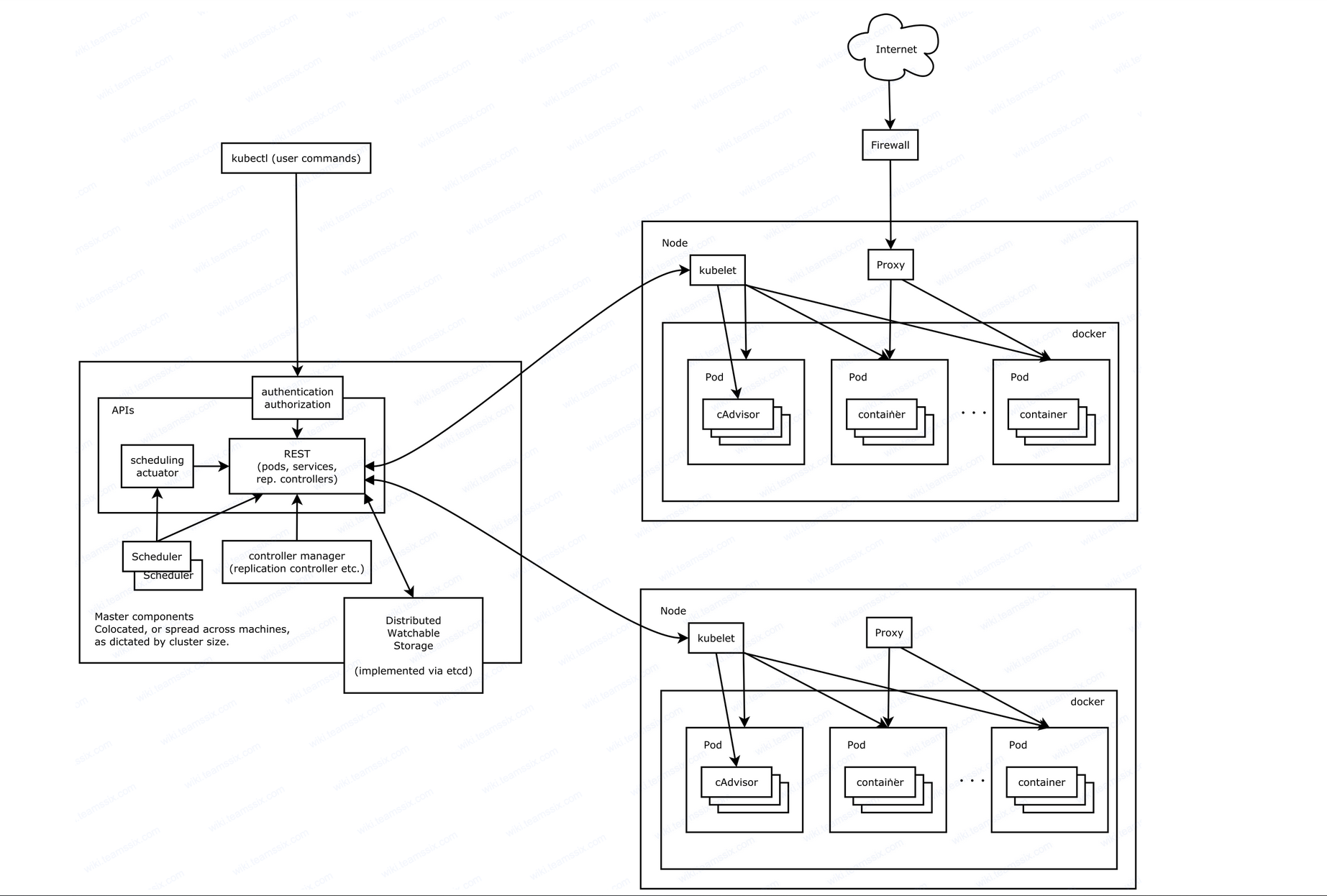
HashMap的工作原理
当我们去定义一个正常的HashMap的时候,我们可以选择不指定参数,也可以选择指定参数。可以选择的指定参数有
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
* 初始化容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
* 加载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
* 从数组链表的形式转为红黑数的一个阈值
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
* 从红黑书转为数组 + 链表的一个阈值
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
* 数组能承受的最大长度,超过这个长度,就转为红黑树
*/
static final int MIN_TREEIFY_CAPACITY = 64;
首先,我们在学习之前,先提一些经典的问题
1、hashMap在什么时候创建数组,什么时候创建链表
2、hashMap如果 put(null,null) 行不行
3、hashMap的工作原理是什么
4、Hahsmap 在1.7 和 1.8 两个版本的 区别是什么
5、HashMap是如何确立键值对的位置
6、扩容为什么每次都是2的幂次方
7、HashMap底层为什么要使用异或运算符
8、hashMap的线程安全问题发生在哪里
首先,当我们建立了一个HashMap的时候,是不会创建一个新数组的,因为如果我们创建了新数组的话又不往里面放值,是非常浪费内存的一件事情。
所以,什么时候创建数组?
当我们第一次往hashMap中添加元素的时候,创建数组。
在hashmap中,创建数组和数组扩容的方法是resize方法
扩容的话是扩容成原来的两倍,初始化的话是初始化成threshold大小。
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 也就是这次resize()是扩容操作而不是初始化操作
if (oldCap >= MAXIMUM_CAPACITY) { // 如果超过了最大容量
threshold = Integer.MAX_VALUE; // threshold设为int的上界,是为了避免以后再扩容
// 因为数组大小已经到上界了,已经不能再扩容了
return oldTab; // 因为已经不能扩容了,所以直接返回旧的table数组
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && // 将新的容量赋值为旧容量的两倍,并且新容量不超过最大容量
oldCap >= DEFAULT_INITIAL_CAPACITY) // 旧容量必须不小于默认初始大小16
newThr = oldThr << 1; // 新阈值是原来的两倍
}
else if (oldThr > 0) // 这种情况就是要初始化了,并且初始化的大小是前面指定了的,这一定是因为调用了有参构造
newCap = oldThr; // 这里的oldThr就是之前构造方法里调用了tableSizeFor()生成的那个threshold
else { // 这种情况就是调用的无参构造,全部使用默认值
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) { // 之前后面两个初始化的分支都没有对newThr进行赋值,这里会赋值
float ft = (float)newCap * loadFactor; // 扩容阈值的计算当然就是容量乘以负载因子啦
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
得到新容量和新阈值以后,先初始化新的table数组newTab,并将table指向newTab
如果oldTab为空的话,说明这次resize()是初始化操作,不需要迁移数据,直接返回newTab就可以了;是扩容操作的话就要开始迁移了。
迁移数据的代码如下
for (int j = 0; j < oldCap; ++j) { // 要迁移数据当然要遍历旧的table数组
Node<K,V> e;
if ((e = oldTab[j]) != null) { // 旧数组对应桶位非空
oldTab[j] = null; // 清除旧数组的引用
if (e.next == null) // 如果头节点后面没有其他节点
newTab[e.hash & (newCap - 1)] = e; // 将该节点放到newTab里
else if (e instanceof TreeNode) // 如果头节点是树节点
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 调用 split() 方法对树进行拆分
else {
// 链表迁移
}
}
}
再看链表迁移代码之前,先讲一个结论,就是一个节点在新数组中的位置,要么是原来的那个位置,要么是新的位置,并且新位置比旧位置正好大了oldCap。下面举例说明:
假设旧数组长度为16,那么新数组长度应该为32。在旧数组中,假设同一桶位的hash值一个为5,一个21。下面分别计算下他们在新旧数组的位置。
0000 0000 0000 0000 0000 0000 0000 1111 (16-1)
& 0000 0000 0000 0000 0000 0000 0000 0101 (5)
= 0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0001 1111 (32-1)
& 0000 0000 0000 0000 0000 0000 0000 0101 (5)
= 0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0000 1111 (16-1)
& 0000 0000 0000 0000 0000 0000 0001 0101 (21)
= 0000 0000 0000 0000 0000 0000 0000 0101
0000 0000 0000 0000 0000 0000 0001 1111 (32-1)
& 0000 0000 0000 0000 0000 0000 0001 0101 (21)
= 0000 0000 0000 0000 0000 0000 0001 0101
这里有一个非常重要的概念哈,我们是怎么根据key找到它在hashMap中的最终位置的呢?
首先,我们对key取它的hash值,拿到hash值之后,这个hash值并不是最终在数组上的索引哈,因为我们需要将它和数组的最大索引的二进制进行一把与的运算,最终得到的才是数组中的索引,这就是你在上面看到的那个二进制的操作。
这里的话,我们结合一些实战进行理解。
HashMap的工作原理是近年来常见的Java面试题。几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间的区别,那么为何这道面试题如此特殊呢?是因为这道题考察的深度很深。这题经常出现在高级或中高级面试中。投资银行更喜欢问这个问题,甚至会要求你实现HashMap来考察你的编程能力。ConcurrentHashMap和其它同步集合的引入让这道题变得更加复杂。让我们开始探索的旅程吧!
“你用过HashMap吗?” “什么是HashMap?你为什么用到它?”
几乎每个人都会回答“是的”,然后回答HashMap的一些特性,譬如HashMap可以接受null键值和值,而HashTable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对等等。这显示出你已经用过HashMap,而且对它相当的熟悉。但是面试官来个急转直下,从此刻开始问出一些刁钻的问题,关于HashMap的更多基础的细节。面试官可能会问出下面的问题:
“你知道HashMap的工作原理吗?” “你知道HashMap的get()方法的工作原理吗?”
你也许会回答“我没有详查标准的Java API,你可以看看Java源代码或者Open JDK。”“我可以用Google找到答案。”
但一些面试者可能可以给出答案,“HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,返回的hashCode用于找到bucket位置来储存Entry对象。”这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Entry。这一点有助于理解获取对象的逻辑。如果你没有意识到这一点,或者错误的认为仅仅只在bucket中存储值的话,你将不会回答如何从HashMap中获取对象的逻辑。这个答案相当的正确,也显示出面试者确实知道hashing以及HashMap的工作原理。但是这仅仅是故事的开始,当面试官加入一些Java程序员每天要碰到的实际场景的时候,错误的答案频现。下个问题可能是关于HashMap中的碰撞探测(collision detection)以及碰撞的解决方法:
“当两个对象的hashcode相同会发生什么?”
从这里开始,真正的困惑开始了,一些面试者会回答因为hashcode相同,所以两个对象是相等的,HashMap将会抛出异常,或者不会存储它们。然后面试官可能会提醒他们有equals()和hashCode()两个方法,并告诉他们两个对象就算hashcode相同,但是它们可能并不相等。一些面试者可能就此放弃,而另外一些还能继续挺进,他们回答“因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用LinkedList存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在LinkedList中。”这个答案非常的合理,虽然有很多种处理碰撞的方法,这种方法是最简单的,也正是HashMap的处理方法。但故事还没有完结,面试官会继续问:
“如果两个键的hashcode相同,你如何获取值对象?”
面试者会回答:当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。面试官提醒他如果有两个值对象储存在同一个bucket,他给出答案:将会遍历LinkedList直到找到值对象。面试官会问因为你并没有值对象去比较,你是如何确定确定找到值对象的?除非面试者直到HashMap在LinkedList中存储的是键值对,否则他们不可能回答出这一题。
其中一些记得这个重要知识点的面试者会说,找到bucket位置之后,会调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象。完美的答案!
许多情况下,面试者会在这个环节中出错,因为他们混淆了hashCode()和equals()方法。因为在此之前hashCode()屡屡出现,而equals()方法仅仅在获取值对象的时候才出现。一些优秀的开发者会指出使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
如果你认为到这里已经完结了,那么听到下面这个问题的时候,你会大吃一惊。
“如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?”
除非你真正知道HashMap的工作原理,否则你将回答不出这道题。默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
如果你能够回答这道问题,下面的问题来了:“你了解重新调整HashMap大小存在什么问题吗?”你可能回答不上来,这时面试官会提醒你当多线程的情况下,可能产生条件竞争(race condition)。
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在LinkedList中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。这个时候,你可以质问面试官,为什么这么奇怪,要在多线程的环境下使用HashMap呢?:)
热心的读者贡献了更多的关于HashMap的问题:
为什么String, Interger这样的wrapper类适合作为键?
String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
我们可以使用自定义的对象作为键吗?
这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了。
我们可以使用CocurrentHashMap来代替HashTable吗?
这是另外一个很热门的面试题,因为ConcurrentHashMap越来越多人用了。我们知道HashTable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。看看这篇博客查看Hashtable和ConcurrentHashMap的区别。
我个人很喜欢这个问题,因为这个问题的深度和广度,也不直接的涉及到不同的概念。让我们再来看看这些问题设计哪些知识点:
hashing的概念
HashMap中解决碰撞的方法
equals()和hashCode()的应用,以及它们在HashMap中的重要性
不可变对象的好处
HashMap多线程的条件竞争
重新调整HashMap的大小
总结
HashMap的工作原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用LinkedList来解决碰撞问题,当发生碰撞了,对象将会储存在LinkedList的下一个节点中。 HashMap在每个LinkedList节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的LinkedList中。键对象的equals()方法用来找到键值对。
因为HashMap的好处非常多,我曾经在电子商务的应用中使用HashMap作为缓存。因为金融领域非常多的运用Java,也出于性能的考虑,我们会经常用到HashMap和ConcurrentHashMap。你可以查看更多的关于HashMap和HashTable的文章。
一、HashMap的原理
众所周知,HashMap是用来存储Key-Value键值对的一种集合,这个键值对也叫做Entry,而每个Entry都是存储在数组当中,因此这个数组就是HashMap的主干。
HashMap数组中的每一个元素的初始值都是NULL
1.Put方法的实现原理
HaspMap的一种重要的方法是put()方法,当我们调用put()方法时,比如hashMap.put(“Java”,0),此时要插入一个Key值为“Java”的元素,这时首先需要一个Hash函数来确定这个Entry的插入位置,设为index,即 index = hash(“Java”),假设求出的index值为2,那么这个Entry就会插入到数组索引为2的位置。
但是HaspMap的长度肯定是有限的,当插入的Entry越来越多时,不同的Key值通过哈希函数算出来的index值肯定会有冲突,此时就可以利用链表来解决。
其实HaspMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点,每一个Entry对象通过Next指针指向下一个Entry对象,这样,当新的Entry的hash值与之前的存在冲突时,只需要插入到对应点链表即可。
需要注意的是,新来的Entry节点采用的是“头插法”,而不是直接插入在链表的尾部,这是因为HashMap的发明者认为,新插入的节点被查找的可能性更大。
2.Get方法的实现原理
get()方法用来根据Key值来查找对应点Value,当调用get()方法时,比如hashMap.get(“apple”),这时同样要对Key值做一次Hash映射,算出其对应的index值,即index = hash(“apple”)。
前面说到的可能存在Hash冲突,同一个位置可能存在多个Entry,这时就要从对应链表的头节点开始,一个个向下查找,直到找到对应的
Key值,这样就获得到了所要查找的键值对。
例如假设我们要找的Key值是"apple":
第一步,算出Key值“apple”的hash值,假设为2。
第二步,在数组中查找索引为2的位置,此时找到头节点为Entry6,Entry6的Key值是banana,不是我们要找的值。
第三步,查找Entry6的Next节点,这里为Entry1,它的Key值为apple,是我们要查找的值,这样就找到了对应的键值对,结束。
二、HashMap的深入思考
上面所说的就是HashMap的基本原理,可以总结出HashMap的3个要素为:hash函数、数组、链表,如下图:
接下来对于HaspMap还有很多深入的问题,比如:
1.HashMap默认的初始长度是多少?为什么这么规定?
2.高并发情况下,HashMap会出现死锁吗?
3.Java8中,HashMap有怎样的优化?
下面开始说明这几个问题:
1.HashMap的长度
1.HaspMap的默认初始长度是16,并且每次扩展长度或者手动初始化时,长度必须是2的次幂。之所以是16,是为了服务于从Key值映射到index的hash算法。前面说到了,从Key值映射到数组中所对应的位置需要用到一个hash函数:index = hash(“Java”);
那么为了实现一个尽量分布均匀的hash函数,利用的是Key值的HashCode来做某种运算。因此问题来了,如何进行计算,才能让这个hash函数尽量分布均匀呢?
一种简单的方法是将Key值的HashCode值与HashMap的长度进行取模运算,即 index = HashCode(Key) % hashMap.length,但是,但是!这种取模方式运算固然简单,然而它的效率是很低的, 而且,如果使用了取模%, 那么HashMap在容量变为2倍时, 需要再次rehash确定每个链表元素的位置,浪费了性能。
因此为了实现高效的hash函数算法,HashMap的发明者采用了位运算的方式。那么如何进行位运算呢?可以按照下面的公式:
接下来我们以Key值为“apple”的例子来演示这个过程:
计算“apple”的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001。
HashMap默认初始长度是16,计算hashMap.Length-1的结果为十进制的15,二进制的1111。
把以上两个结果做 与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以看出来,hash算法得到的index值完全取决与Key的HashCode的最后几位。这样做不但效果上等同于取模运算,而且大大提高了效率。
那么回到最初的问题,初始长度为什么是16或者2的次幂?如果不是会怎么样?
我们假设HaspMap的初始长度为10,重复前面的运算步骤:
单独看这个结果,表面上并没有问题。我们再来尝试一个新的HashCode 101110001110101110 1011 :
然后我们再换一个HashCode 101110001110101110 1111 试试 :
这样我们可以看到,虽然HashCode的倒数第二第三位从0变成了1,但是运算的结果都是1001。也就是说,当HashMap长度为10的时候,有些index结果的出现几率会更大,而有些index结果永远不会出现(比如0111)!
所以这样显然不符合Hash算法均匀分布的原则。
而长度是16或者其他2的次幂,Length - 1的值的所有二进制位全为1(如15的二进制是1111,31的二进制为11111),这种情况下,index的结果就等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。这也是HashMap设计的玄妙之处。
2.HashMap的死锁
我们知道HashMap是非线程安全的,那么原因是什么呢?
由于HashMap的容量是有限的,如果HashMap中的数组的容量很小,假如只有2个,那么如果要放进10个keys的话,碰撞就会非常频繁,此时一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷。
为了解决这个问题,HashMap设计了一个阈值,其值为容量的0.75,当HashMap所用容量超过了阈值后,就会自动扩充其容量。
在多线程的情况下,当重新调整HashMap大小的时候,就会存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历。如果条件竞争发生了,那么就会产生死循环了。
扩容为什么都是2的n次幂
因为我们在求数组下标的时候,16的最大索引15(二进制位1111),那么在进行与运算的时候,每个不一样的值都会得到他们本身相似的2进制,换个角度思考,如果扩容的时候扩的是10,这个时候,本来是不一样的原二进制会变成一样的二进制,导致产生hash冲突,增加我们的存值的成本。所以二进制扩容能帮助我们更好的均匀的存值。
(小知识:数组在内存当中的存值是连续的,链表当中存的是键值对)
hashMap的线程安全问题发生在什么阶段
取得索引的阶段。当多个线程同时使用hashMap的时候。假设现在有两个值的hash值都是一样的,他们同时要做与运算拿到数组索引,假设他们都拿到数组索引的时候,二者同时进行了写操作,其中一个写覆盖了另一个写, 于是就发生了线程安全问题