摘要
大语言模型能够通过上下文学习-只需要在推理阶段加入一些输入-标签的示例对,就能完成对新输入文本的预测。但是,对模型是如何学习,示例的哪些方面会影响最终的任务效果,我们知之甚少。在这篇纹章中,我们揭示了 正确的输入-标签示例对不是必须的,随机替换示例中的标签几乎不会影响效果,这个结论在12个不同的模型上是一致的,包括gpt3。相反,我们发现示例的其他方面是最终任务效果的核心驱动,包括:标签的空间,输入文本的分布,整体序列的格式。总之,我们的分析提供了一个新的方式去理解上下文学习是怎么工作的以及背后的机理,同时抛砖引玉:在推理阶段,大语言模型有多少能力可以被激发。
1. 引言
大型语言模型(LMs)通过简单地对几个输入标签对(演示)进行条件反射,在下游任务中表现出了令人印象深刻的性能;这种类型的推理被称为上下文学习(Brown et al., 2020)。尽管上下文学习在广泛的任务上始终优于 zeroshot 推理(Zhao et al., 2021; Liu et al., 2021),但对它的工作原理和演示的哪些方面如何有助于最终任务性能知之甚少。
在本文中,我们表明,事实上,有效的语境学习并不需要基础事实演示(第4节)。具体而言,用随机标签替换演示中的标签几乎不会影响分类和多项选择任务的性能(图1)。结果在 12 个不同的模型上是一致的,包括 GPT-3 家族。这强烈表明,与直觉相反,该模型不依赖于演示中的输入标签映射来执行任务。
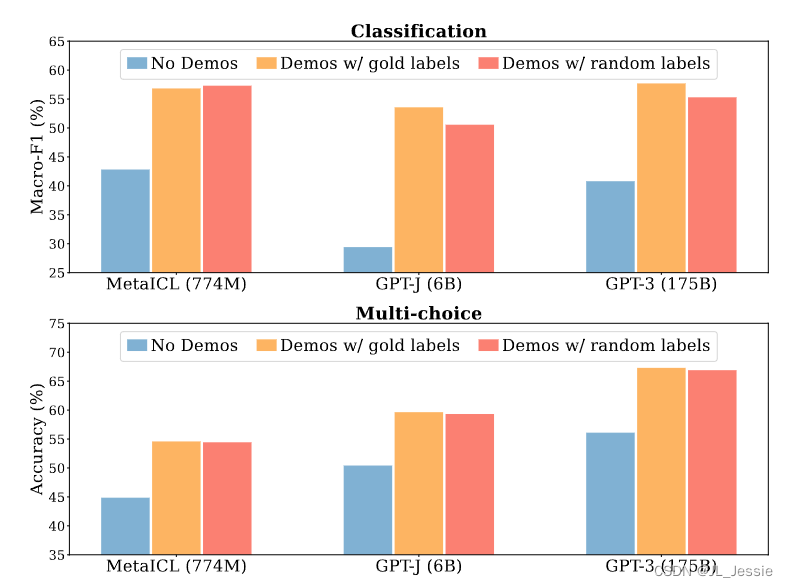
上图为实验结果,在分类任务和多选任务上,分别使用三个不同大小的lms,评估了GPT-3的六个数据集, 并且使用了通道方法。完整结果见第4节。当演示中的标签被随机标签取代时,上下文学习性能只会略有下降。
进一步的分析调查了演示的哪些部分确实对性能有贡献。我们确定了演示的可能方面(例如,标签空间和输入文本的分布),并评估了演示的一系列变体,以量化每个变体的影响(第5节)。我们发现:(1)标签空间和演示所指定的输入文本的分布都是上下文学习的关键(无论标签对个人输入是否正确);(2) 指定整体格式也是至关重要的,例如,当标签空间未知时,使用随机英语单词作为标签比不使用标签要好得多;(3) 具有上下文学习目标的元训练(Min et al.,2021b)放大了这些效果——模型几乎完全利用了演示的更简单方面,如格式,而不是输入标签映射。
总之,我们的分析为理解样例在上下文学习中的作用提供了一种新的方法。我们的经验表明,(1)与直觉相反,模型并不像我们想象的那样依赖于演示样例中提供的基本事实与输入标签映射(第4节),(2)尽管如此,仍然受益于了解演示指定的标签空间和输入分布(第5节)。我们还讨论了更广泛的含义,例如,我们可以对测试时的模型学习说些什么,以及未来工作的途径(第6节)。
2. 相关工作
大型语言模型在广泛的下游任务中对强大的性能至关重要(Devlin 等人,2019;Radford 等人,2019;Liu 等人,2019;Raffel 等人,2020;Lewis 等人,2020)。虽然微调是一种流行的转移到新任务的方法(Devlin等人,2019年),但微调非常大的模型(例如≥10B参数)通常是不切实际的。Brown等人(2020)提出了上下文学习作为学习新任务的替代方法。如图 2 所示,LM 仅通过推理来学习新任务,方法是将训练数据的串联作为演示,而无需任何梯度更新。

自引入以来,上下文学习一直是大量研究的焦点。先前的工作提出了更好地制定问题的方法(Zhao et al., 2021; Holtzman et al., 2021; Min et al., 2021a),更好的方法为演示选择标记示例(Liu et al., 2021; Lu et al., 2021; Rubin et al., 2021),使用显式上下文学习目标进行元训练(Chen et al., 2021; Min et al., 2021b),并学习遵循指令作为上下文学习的变体(Mishra et al., 2021b; Efrat and Levy, 2020; Wei et al., 2022a; Sanh et al., 2022)。同时,一些工作报告了上下文学习的脆弱性和过度敏感性(Lu et al., 2021; Zhao et al., 2021; Mishra et al., 2021a)。
了解为什么上下文学习有效的工作相对较少。Xie等人(2022)提供了理论分析,即上下文学习可以形式化为贝叶斯推理 即 使用演示样例来恢复潜在概念concept。(Raazeghi 等人2022) 表明上下文内学习性能与预训练数据中的词频高度相关。据我们所知,本文是第一个提供实证分析的论文,该分析调查了为什么上下文内学习比零样本推理实现了性能提升。我们发现演示中的真实输入标签映射只有边际效应,并衡量演示的细粒度方面的影响。
3. 实验建立
我们描述了分析中使用的实验设置(第 4 节和第 5 节)。
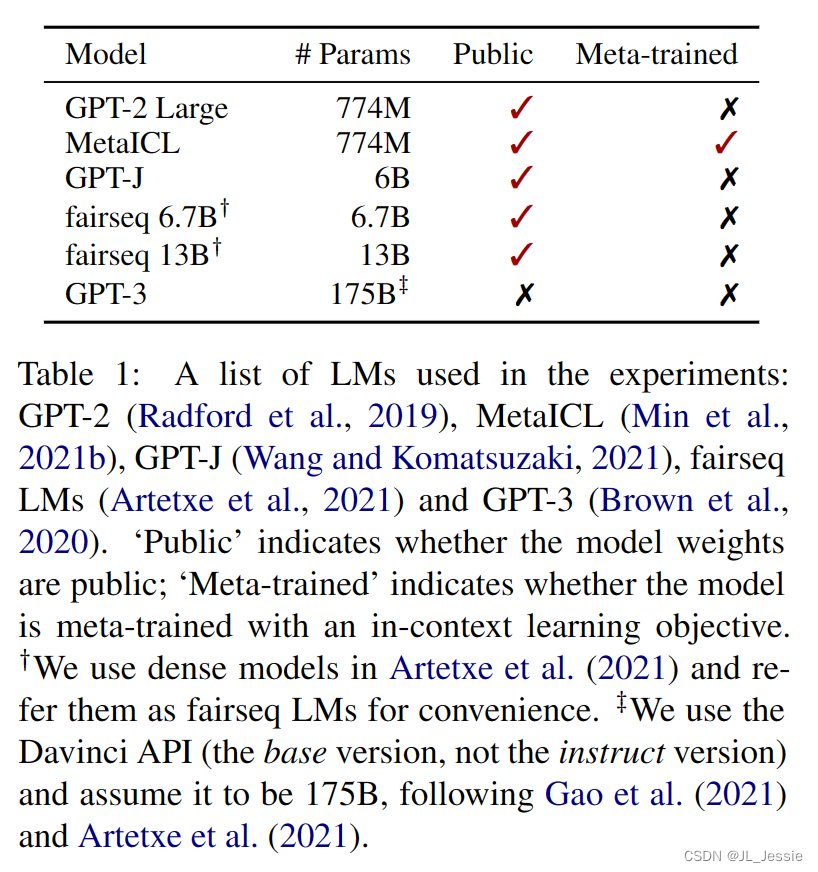
**模型:**我们总共试验了12个模型。我们包括6种语言模型(表1),它们都是仅解码器的、dens - lm。按照Min等人(2021a),我们使用每个LM和两种推理方法,直接通道和通道。LM 的大小从 774M 到 175B 不等。包括了GPT-3 和公开发布的最大的密集LM (fairseq 13B)。我们还包括MetaICL,它由GPT-2大型初始化,然后在具有上下文学习目标的监督数据集集合上进行元训练,并确保我们的评估数据集不会与在元训练时使用的数据集重叠。
评估数据: 我们对26个数据集进行了评估,包括情感分析、意译检测、自然语言推断、仇恨言论检测、问答和句子补全(完整列表和参考文献见附录A)所有数据集都是分类和多项选择任务。我们使用这些数据集是因为它们(1)是真正的低资源数据集,少于10K训练例,(2)包括来自GLUE (Wang等人,2018)和SuperGLUE (Wang等人,2019a)的经过充分研究的基准,以及(3)涵盖科学,社交媒体,金融等多个领域。
其他详细信息: 除非另有说明,否则我们默认使用k=16个示例作为论文中所有实验的演示。示例是从训练数据中均匀采样的。我们使用5个不同的随机种子选择一组k个训练示例,并进行5次实验。对于fairseq13B和GPT-3,由于资源有限,我们用6个数据集2和3个随机种子的子集进行了实验。我们报告了分类任务的MacroF13和多选任务的准确性。我们计算种子上的每个数据集的平均值,然后报告数据集上的宏平均值。我们使用最小模板从一个例子中形成一个输入序列。我们参考附录B了解更多详细信息。所有实验都可以参考github 复现:github.com/Alrope123/ rethinking-demonstrations.
4 真实标签并不重要
4.1 正确标签 和 随机标注(gold label VS random label)
为了在演示中看到正确配对的输入和标签的影响——我们称之为基础真值输入-标签映射——我们比较了以下三种方法。
- 无演示 No demonstrations是一种典型的零射击方法,它不使用任何标记数据。通过argmax∈C P (y|x)进行预测,其中x是测试输入,C是一个小的离散的可能标签集。
- 带有正确标签的演示 Demonstrations w/ gold label 其中有k个标记示例(x1, y1)…(yk xk)。k input-label对的串联用于预测viaargmax∈cp (y|x1, y1…)Xk, yk, x)
- 带有随便标签的演示 Demonstrations w/ random labels标签是用随机标签形成的,而不是用标记数据形成的正确标签。每个xi(1≤i≤k)与从c中均匀随机抽样的i i配对。(x1, i i)…然后使用(xk, yk)通过argmax∈cp (y|x1, y1…)进行预测。(x, y, x)
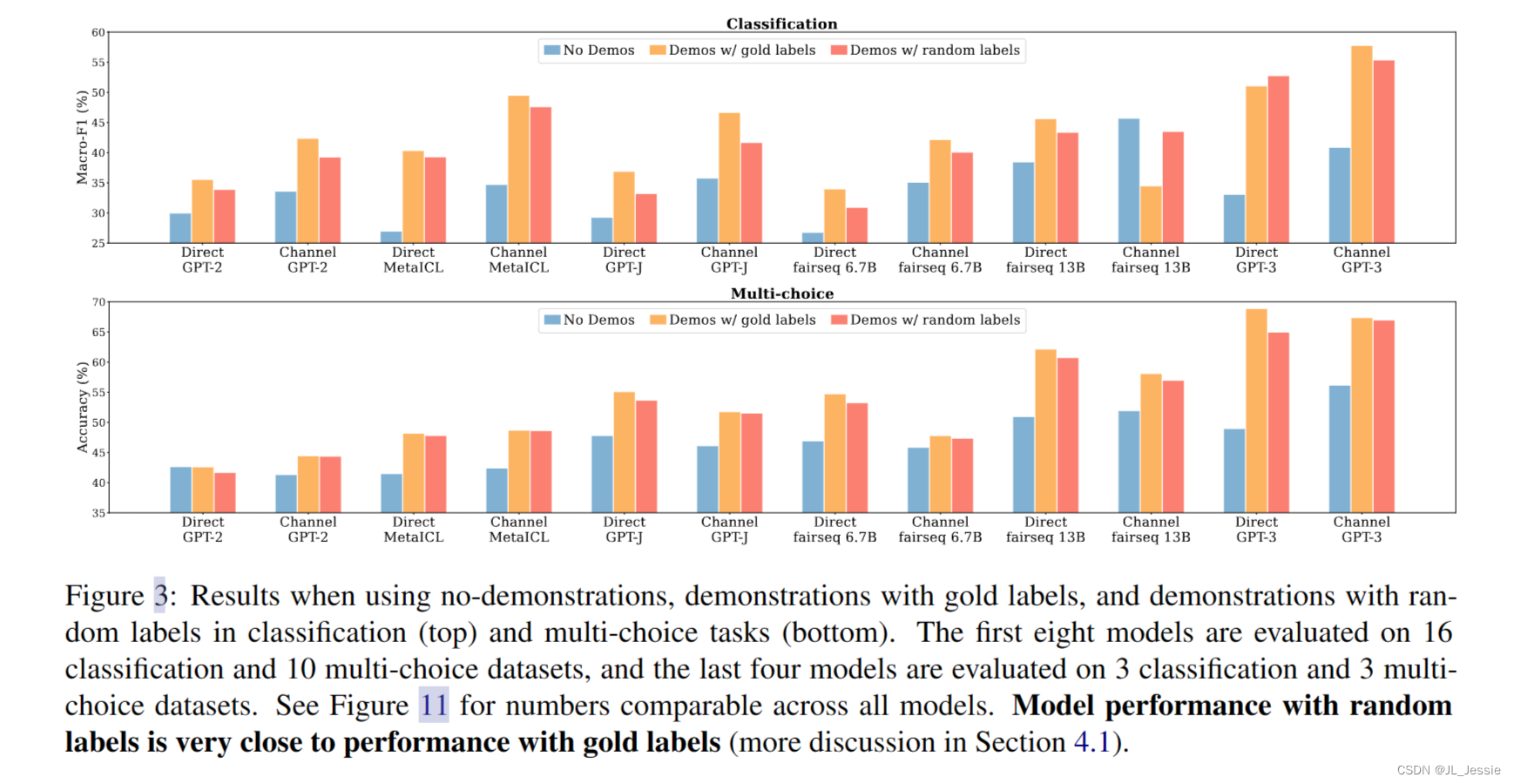
结果如图3所示。首先,与没有演示相比,使用带有正确标签的演示显着提高了性能,因为在之前的许多工作中都发现了这一点(Brown等人,2020;赵等,2021;刘等人,2021)。然后我们发现,用随机标签替换正确标签只会略微损害性能。几乎所有模型的趋势都是一致的:模型的性能绝对下降幅度在0-5%之间。在多选择任务中替换标签的影响(平均为1.7%)比在分类任务中(绝对为2.6%)要小。
这一结果表明,带有真实/正确标签的输入对 并不是实现性能提升所必需的。这是违反直觉的,因为在典型的监督训练中,正确配对的训练数据是至关重要的——它告知模型执行下游任务所需的预期输入标签对应关系。尽管如此,这些模型确实在下游任务上实现了重要的性能。这强烈表明模型能够恢复任务的预期输入标签对应;然而,它并不是直接来自于演示中的配对。
同样值得注意的是,MetaICL的性能下降特别小:绝对值为0.1-0.9%。这表明,具有明确上下文学习目标的元训练实际上鼓励模型从本质上忽略输入标签映射,并利用演示的其他组件(更多讨论见5.4节)。在附录C.2中,我们提供了额外的结果,表明(1)从标签的真实分布中选择随机标签(而不是均匀分布)进一步减少了差距,(2)趋势可能依赖于数据集,尽管在大多数数据集总体趋势是一致的。
4.2 消融实验
对于额外的消融,我们使用5个分类和4个多选择数据集进行实验(Classification includes: MRPC, RTE, Tweet_eval-hate, SICK, poem-sentiment; Multi-choice includes OpenbookQA, CommonsenseQA, COPA and ARC.)
-
正确标签的数量重要吗? 为了进一步检查演示中标签正确性的影响,我们通过改变演示中正确标签的数量来进行消融研究。我们评估“ 包含a%正确标签的演示(0≤a≤100),由k × a%正确对和k ×(1−a%)对错误对组成(见附录B中的算法1)。这里,a = 100与典型的上下文学习相同,即w/ gold标签的演示。
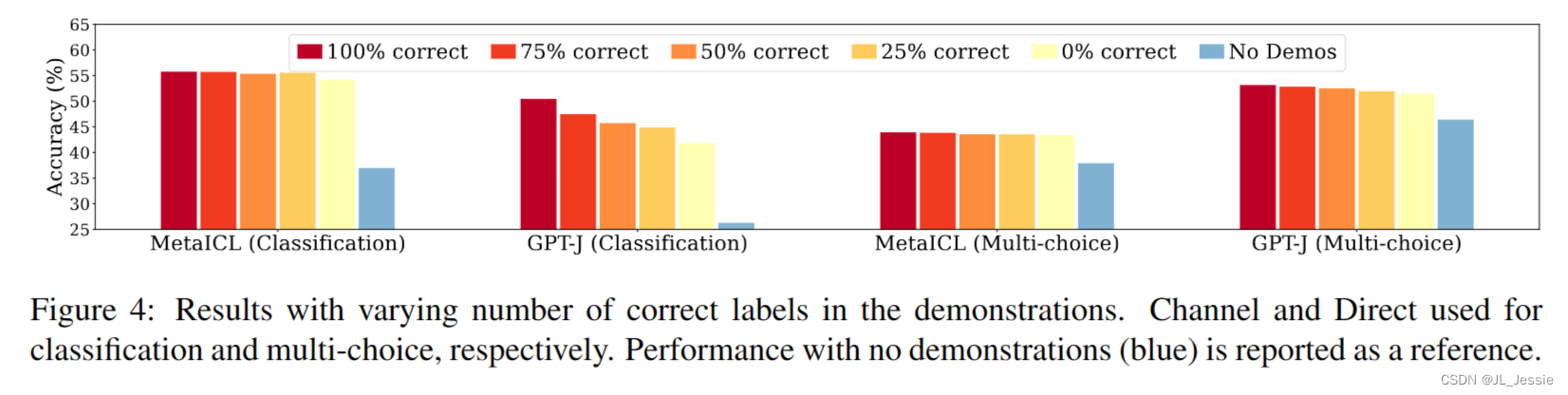
结果如图4所示。模型性能对演示中正确标签的数量相当不敏感。事实上,总是使用不正确的标签比不使用演示效果要好得多,例如,在分类中使用MetaICL演示,在多选择中使用MetaICL演示,在多选择中使用GPT-J分别保留92%、100%和97%的改进。相比之下,分类中的GPT-J在标签错误越多的情况下,性能下降相对明显,例如在总是使用错误标签的情况下,性能下降近10%。尽管如此,总是使用不正确的标签比没有演示要好得多。
-
结果与k的变化一致吗? 我们在演示中研究了输入标签对(k)的数量的影响。结果如图5所示。首先,即使k很小(k = 4),使用演示也明显优于不演示方法,并且从使用金标签到使用随机标签的性能下降在不同k的范围内始终很小,在0.8 - 1.6%的范围内有趣的是,当k≥8时,无论是金标签还是随机标签,模型性能都不会随着k的增加而增加。这与典型的监督训练相反,在监督训练中,模型的性能随着k的增加而迅速提高,尤其是当k很小的时候。我们假设,较大的标记数据主要有利于监督输入-标签的对应关系,而数据的其他组成部分,如示例输入、示例标签和数据格式更容易从小数据中恢复,这可能是从较大的数据中获得最小性能增益的原因(在第5节中有更多讨论)
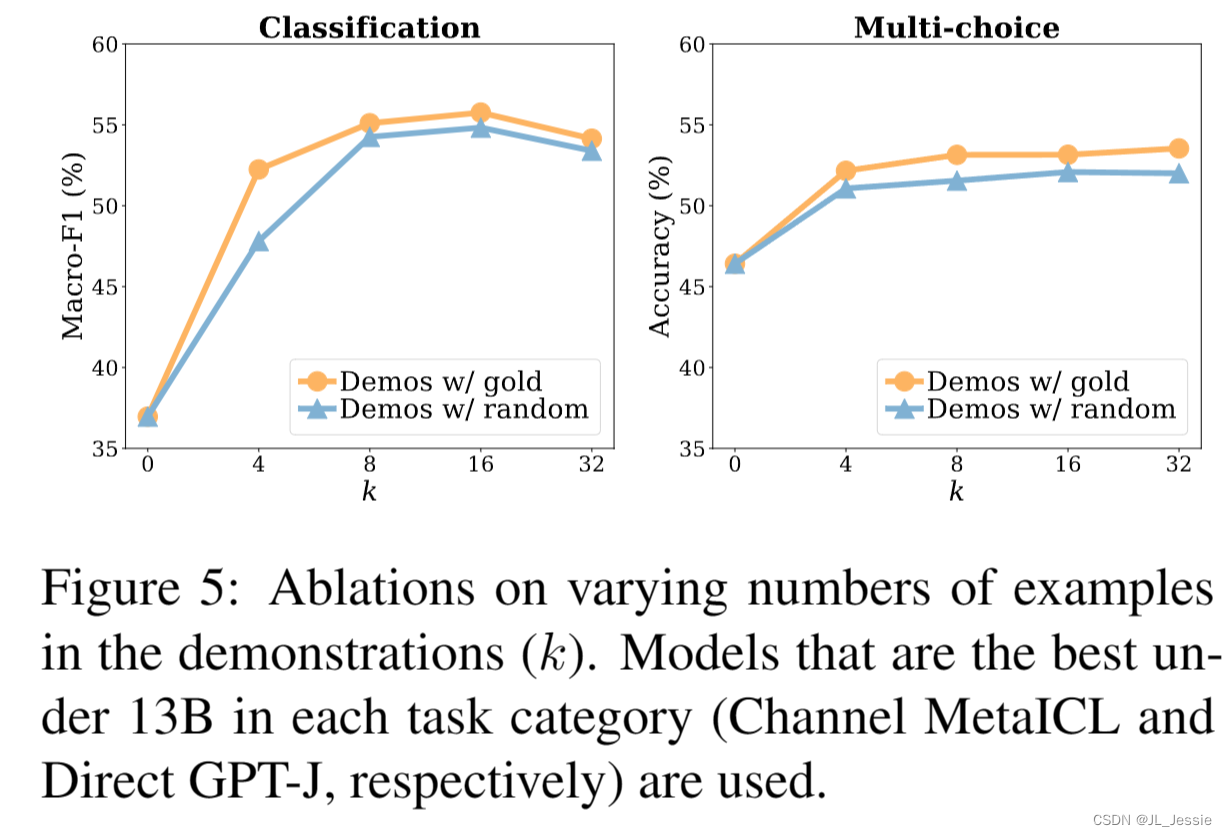
-
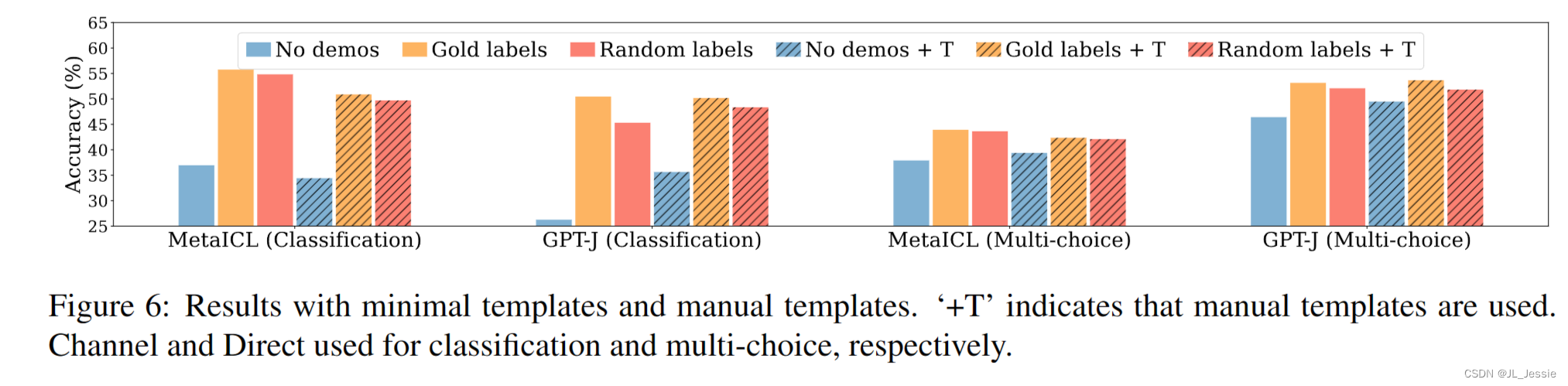
结果与更好的模板一致吗? 虽然我们默认使用最小的模板,但我们也探索了手动模板,即,以特定于数据集的方式手工编写的模板,取自以前的工作(详见附录B)。图6显示了趋势——用随机标签替换黄金标签几乎不会损害性能——使用手动模板。值得注意的是,使用手动模板并不总是优于使用最小模板。
-
5 为什么 上下文学习会有用?
第4节展示了演示中的ground truth输入-标签映射对上下文内学习的性能收益几乎没有影响。本节将进一步讨论演示的哪些其他方面会导致上下文学习的良好表现。
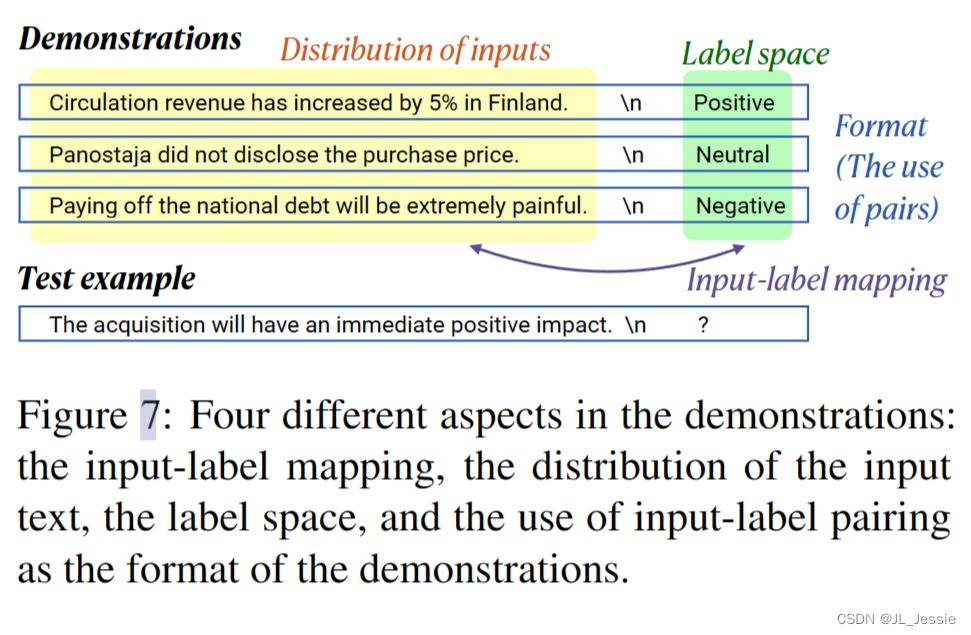
我们确定了演示的四个方面(x1, y1)…(xk, yk),可能提供学习信号(如图7所示)。
- 输入-标签映射,即每个输入xi是否与正确的标签yi配对。
- 输入文本的分布,即x1…Xk来自。
- 标签空间,即y1…yk所覆盖的空间。
- 格式,特别是使用输入标签配对作为格式。
正如第4节对输入-标签映射所做的那样,我们设计了一系列演示的变体,以单独量化每个方面的影响(第5.1-5.3节)。然后,我们还讨论了具有上下文学习目标的模型元训练的趋势(第5.4节)。对于所有的实验,模型在5个分类和4个选择数据集上进行评估,如4.2节所示。有关实现细节和示例演示,分别参见附录B和表4。
5.1 输入文本分布的影响
我们对OOD演示进行了实验,其中包括分布外(OOD)文本,而不是来自未标记训练数据的输入。具体来说,从外部语料库中随机抽取k个句子{xi,rand}k i=1,替换x1…Xk在演示中。该变体评估输入文本分布的影响,同时保留标签空间和演示的格式。
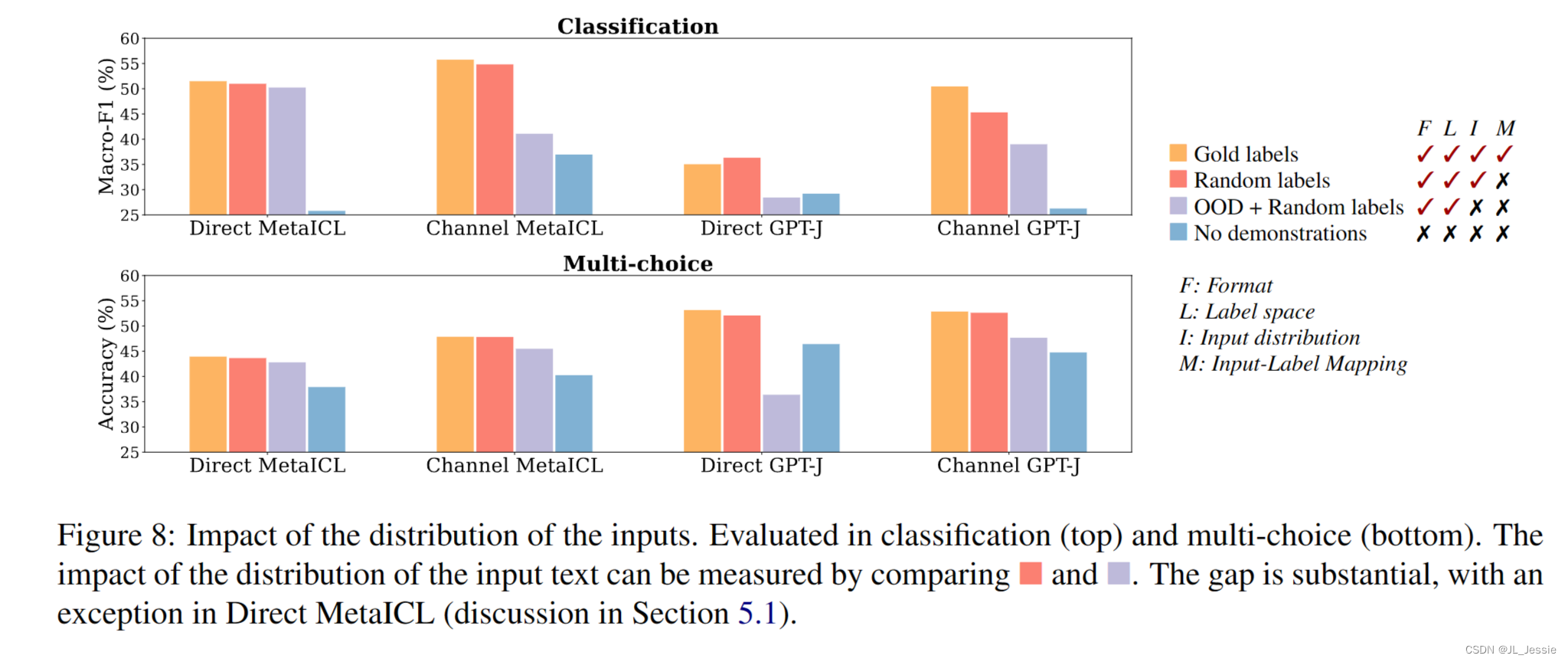
结果图8显示,当在分类和选择中使用Channel MetaICL、Direct GPT-J或Channel GPT-J时,使用分布外输入而不是来自训练数据的输入会显著降低性能,绝对下降3-16%。在选择题中,Direct GPT-J甚至比没有演示更糟糕。Direct MetaICL是一个例外,我们认为这是元训练的影响(在第5.4节讨论)。
这表明演示中的分布输入对性能提升有很大贡献 *这可能是因为 以符合训练分布的 文本输入 使任务更接近于语言建模,因为LM在训练期间总是以分布文本为条件。
5.2 标签空间的影响
我们还进行了随机英语单词的演示实验,使用随机英语单词作为所有k对的标签。具体来说,我们对英语单词Crand的一个随机子集进行采样,其中|Crand| = |C|,并将i∈Crand与xi随机配对。该变体评估标签空间的影响,同时保持输入文本的分布和演示的格式。

结果 根据图9,直接模型和通道模型表现出不同的模式。使用直接模型,在标签空间内使用随机标签和使用随机英语单词之间的性能差距是显著的,绝对值在5-16%之间。**这表明对标签空间的调节对性能的提高有很大的帮助。**即使对于没有固定标签集的多选择任务也是如此——我们假设多选择任务仍然具有模型使用的特定选择分布(例如,OpenBookQA数据集中的“螺栓”或“螺钉”等对象)。
另一方面,去除输出空间不会导致通道模型的显著下降:绝对值下降0–2%,有时甚至会增加。我们假设这是因为通道模型只以标签为条件,因此不受益于了解标签空间。这与必须生成正确标签的直接模型形成对比
5.3 输入-标签的映射的影响
第5.1节和第5.2节侧重于尽可能保持演示格式的变体。本节探讨了更改格式的变体。虽然格式有很多方面,但我们会进行最小的修改,以删除输入与标签的配对。具体来说,我们评估了没有标签的演示,其中LM以x1…xk的连接为条件,而只有标签的演示是以y1…yk的连接为前提。这些消融分别提供了“随机英语单词演示”和“OOD输入演示”的无格式对应物。
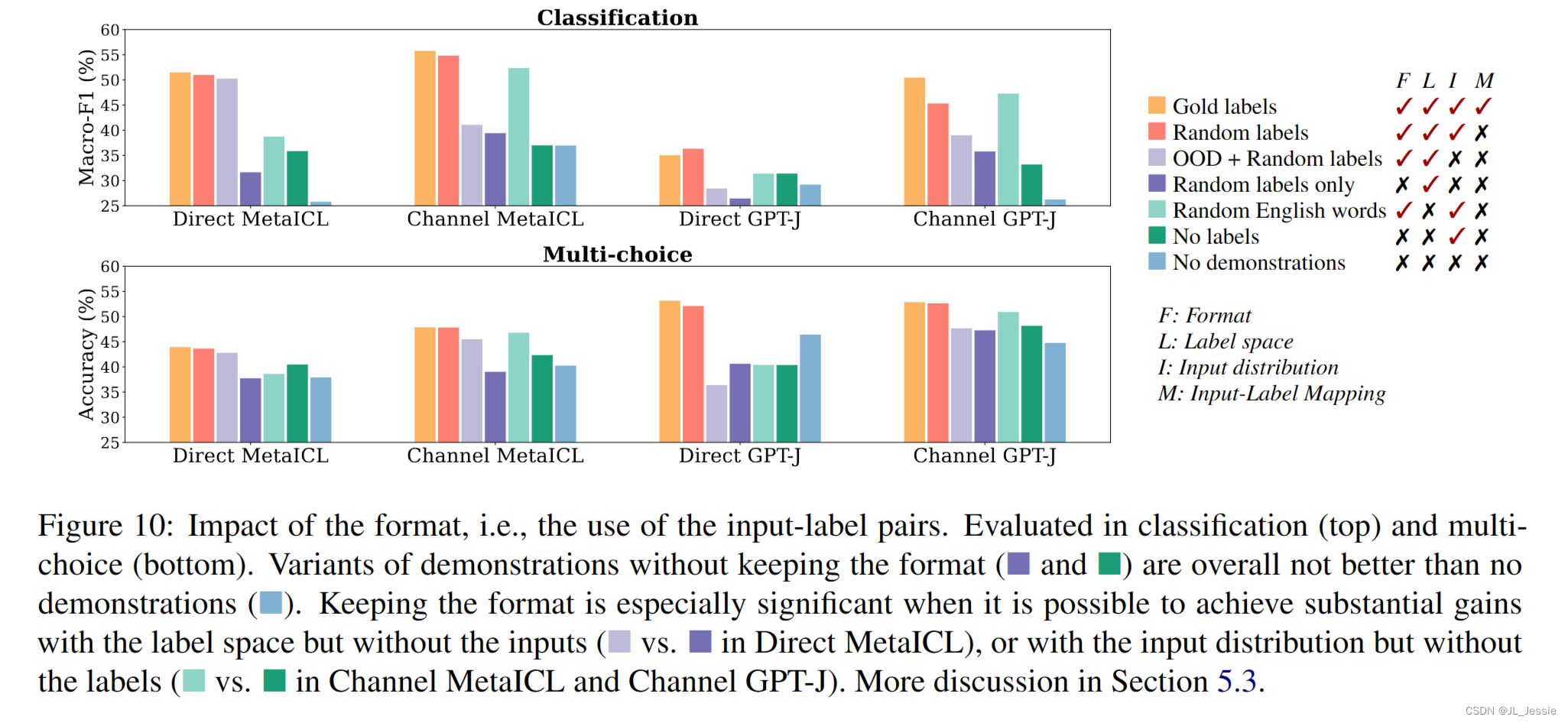
结果 基于图 10,删除格式接近或低于没有演示,表明格式的重要性。这可能是因为对一系列输入标签对的条件会触发模型模仿整体格式并完成给定测试输入时的预期新示例
更有趣的是,通过仅使用输入或仅使用标签,保持格式在保留大部分性能增益方面起着重要作用。
例如,使用Direct MetaICL,通过简单地从语料库中随机抽取句子,并分别在分类和多选择中将它们与标签集随机配对(如图10所示),可以保留95%和82%的上下文学习(带有金标的演示)改进。
同样,对于通道模型,通过简单地将MetaICL分类、GPTJ分类、MetaICL多选择和GPT-J多选择中的未标记训练数据的每个输入分别与随机英语单词配对(如图10所示),可以保留82%、87%、86%和75%的上下文学习改进。对于所有这些情况,删除输入而不是使用OOD输入,或者删除标签而不是使用随机英语单词的情况要糟糕得多,这表明保持输入-标签对的格式是关键。
5.4 元训练的影响
与其他模型不同的是,MetaICL是根据上下文学习目标进行训练的,这与最近在大量监督数据集(称为元训练)上使用多任务训练以泛化到新任务的工作一致(Aghajanyan等人,2021;Khashabi et al., 2020;魏等人,2022a;Sanh et al., 2022)。我们的目标是通过仔细检查MetaICL的结果,更好地理解与我们的发现相关的元训练的作用。特别是,我们观察到,到目前为止,我们看到的模式在MetaICL中比在其他模型中更为明显。例如,基本事实输入标签映射的重要性更小,而保持演示的格式则更重要。在Direct MetaICL中,输入标签映射和输入分布的影响几乎为零,在Channel MetaICL中,输入标签映射和输出空间的影响几乎为零。
基于这一观察,我们假设元训练鼓励模型只利用演示的简单方面,而忽略其他方面。这是基于我们的直觉,即(1)输入标签映射可能更难利用,(2)格式可能更容易利用,以及(3)模型训练生成的文本空间可能比模型设定的文本空间更容易利用。(也就是说,直接模型 利用标签空间 比利用输入空间更好,通道模型利用输入分布 比 利用标签空间更好。)
6 讨论和结论
在本文中,我们研究了示范对上下文学习成功的作用。我们发现,演示中的基本事实输入标签映射比人们想象的要重要得多——在演示中用随机标签替换黄金标签只会略微降低性能。然后,我们确定演示中的一系列方面,并检查哪一方面真正有助于提高性能。结果表明:
(1)增益主要来自输入空间和标签空间的独立规范,
(2)如果使用正确的格式,则通过仅使用输入或仅使用标签集,模型仍然可以保留高达95%的性能增益,
(3)具有上下文学习目标的元训练放大了这些趋势。
总之,我们的发现为上下文学习提供了一系列更广泛的指示,以及未来工作的途径。
**模型在测试时学习吗?**如果我们对学习进行严格的定义:捕捉训练数据中给出的输入标签对应关系,那么我们的研究结果表明,LMs在测试时不会学习新任务。我们的分析表明,该模型可能会忽略演示定义的任务,而使用预训练中的先验知识。然而,学习一项新任务可以被更广泛地解释:它可能包括适应特定的输入和标签分布以及演示所建议的格式,并最终做出更准确的预测。有了这个学习的定义,模型确实可以从演示中学习任务。我们的实验表明,该模型确实利用了演示的各个方面,并实现了性能提升。
LMs的能力。该模型执行下游任务,而不依赖于来自演示的输入标签对应关系。这表明,该模型仅从语言建模目标中学到了输入标签对应关系(隐含的概念),例如,将积极评价与“积极”一词联系起来。这与Reynolds和McDonnell(2021)一致,他们声称演示是针对任务定位的,执行任务的内在能力是在预训练时获得的。
一方面,这表明语言建模目标已经带来了巨大的零样本能力,即使从天真的零样本准确性中并不总是很明显。另一方面,这表明上下文学习可能不适用于尚未在LM中捕获输入标签对应关系的任务。这就引出了如何在上下文学习无法解决的NLP问题上取得进展的研究问题:我们是否需要一种更好的方法来提取已经存储在LM中的输入标签映射,一种学习更广泛任务语义的LM目标的更好变体,或者通过对标记数据进行微调来进行显式监督。
与指令遵循模型的联系。先前的工作发现,训练能够读取任务的自然语言描述(称为指令)并在推理时执行新任务的模型是有希望的(Mishra等人,2021b;Efrat和Levy,2020;Wei等人,2020;Sanh等人,2022)。我们认为演示和指令在很大程度上与LM具有相同的作用,并假设我们的发现适用于以下指令模型:指令提示模型恢复其已有的能力,但不监督模型学习新的任务语义。Webson和Pavlick(2022)已经部分验证了这一点,他们表明,在不相关或误导性的指令下,模型性能不会降低太多。我们将更多的分析留给后续的教学模式。
显著提高零射击性能。我们的主要发现之一是,可以在不使用任何标记数据的情况下实现接近k-shot的性能,只需将每个未标记的输入与随机标签配对并将其用作演示。这意味着我们的零射击基线水平比之前想象的要高得多。未来的工作可以进一步提高零射击性能,在访问未标记的训练数据时使用宽松的假设。
Limation 受限因素
任务和数据集类型的影响。本文的重点是来自具有真实自然语言输入的已建立的NLP基准的任务。正如Rong(2021)所观察到的那样,输入更有限的合成任务实际上可能更多地使用基础真值标签。我们通过检查多个NLP数据集的平均性能来报告宏观层面的分析,但不同的数据集可能表现不同。附录C.2讨论了这方面,包括在一些数据集模型对中使用基础真实标签和使用随机标签之间存在较大差距的发现(例如,在最极端的情况下,在使用GPT-J的financial_phrasebank数据集上,绝对误差接近14%)。自我们论文的第一个版本以来,Kim等人(2022)表明,使用否定标签大大降低了分类的性能我们认为重要的是要理解模型需要多大程度的基础真值标签才能成功地执行上下文学习。
扩展到生成。我们的实验仅限于分类和多项选择任务。我们假设,在开放集任务(如生成)中,背景真值输出可能不是上下文学习所必需的,但将其留给未来的工作。将我们的实验扩展到这样的任务并非无关重要,因为它需要在保持正确输出分布的同时对具有不正确输入-输出对应的输出进行变化(根据我们在第5节的分析,这是重要的)。自我们论文的第一个版本以来,Madaan和Yazdanbakhsh(2022)使用思维提示链进行了类似的分析(Wei et al., 2022b),这产生了执行复杂任务(如数学问题)的基本原理。Madaan和Yazdanbakhsh(2022)表明,虽然在演示中简单地使用随机基本原理(例如,与来自不同示例的基本原理配对)会显著降低性能,但其他类型的反事实基本原理(例如,错误的方程)不会像我们想象的那样降低性能。我们参考Madaan和Yazdanbakhsh(2022)关于理论基础的哪些方面重要或不重要的更多讨论。