这集我们来讲一个requests的封装函数。
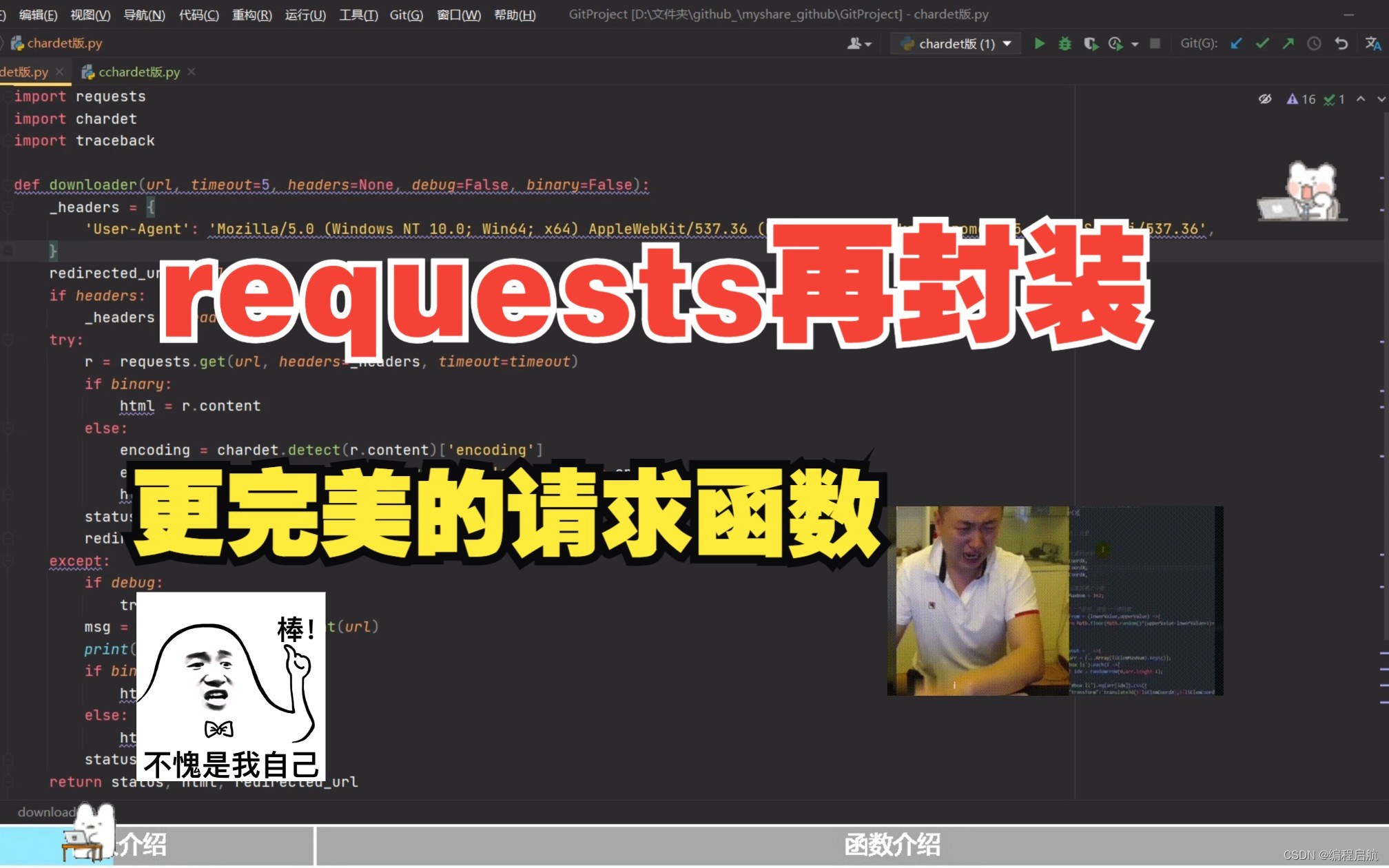
作为一个程序员,我们经常会追求代码的复用性,所以就很多三方库,让我们不重复造轮子。但三方库也不是一步到位的,真正要完成目标还是要动动手的,把工具组装起来。相信每个人都封装过一些工具类。
作为一个爬虫小子,那肯定天天少不了爬取网页。那一般流程是什么呢?首先去分析下网页,然后开始写程序。先import requests,再去网页复制一个User-Agent,还要做异常处理,再判断一下状态码,若网页编码有问题还得再import 一个cchardet,然后再获取encoding,等等等等一堆。一次还好,但这种简单的流程我们每写一个程序就需要经历,很明显是重复性的劳动,非常地消耗耐心,可能本来跃跃欲试呢,做完这些基础操作就没多大兴趣了。
那么下面我就分享一下我封装的爬虫工具函数。
在代码写注释还难免会有讲不清晰的地方,视频讲解在此:https://www.bilibili.com/video/BV1PX4y1x7sV/
import requests
import cchardet
import traceback
def downloader(url, timeout=5, headers=None, debug=False, binary=False):
_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
redirected_url = url
if headers:
_headers = headers
try:
r = requests.get(url, headers=_headers, timeout=timeout)
if binary:
html = r.content
else:
encoding = cchardet.detect(r.content)['encoding']
html = r.content.decode(encoding)
status = r.status_code
redirected_url = r.url
except:
if debug:
traceback.print_exc()
msg = 'failed download: {}'.format(url)
print(msg)
if binary:
html = b''
else:
html = ''
status = 0
return status, html, redirected_url
if __name__ == '__main__':
url = 'http://news.baidu.com/'
s, html,real_url = downloader(url,debug=True)
print(s, len(html),real_url)
import requests
import chardet
import traceback
def downloader(url, timeout=5, headers=None, debug=False, binary=False):
_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}
redirected_url = url
if headers:
_headers = headers
try:
r = requests.get(url, headers=_headers, timeout=timeout)
if binary:
html = r.content
else:
encoding = chardet.detect(r.content)['encoding']
encoding='gb18030' if encoding.lower() == 'gb2312' else encoding
html = r.content.decode(encoding)
status = r.status_code
redirected_url = r.url
except:
if debug:
traceback.print_exc()
msg = '链接{}下载失败了'.format(url)
print(msg)
if binary:
html = b''
else:
html = ''
status = 0
return status, html, redirected_url
if __name__ == '__main__':
url = 'http://news.baidu.com/'
s, html,real_url = downloader(url,debug=True)
print(s, len(html),real_url)