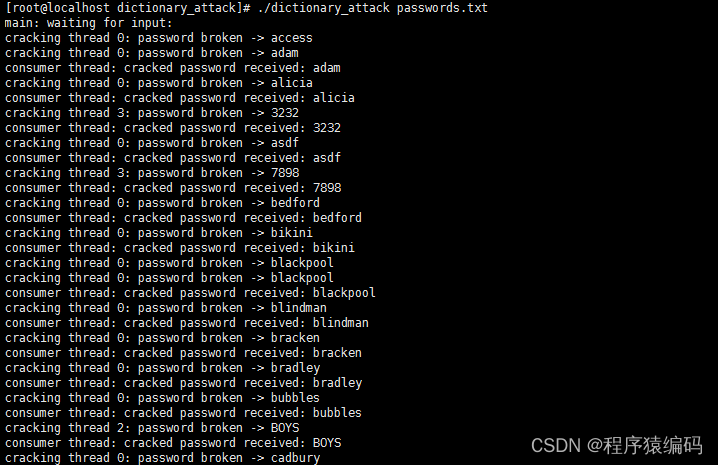
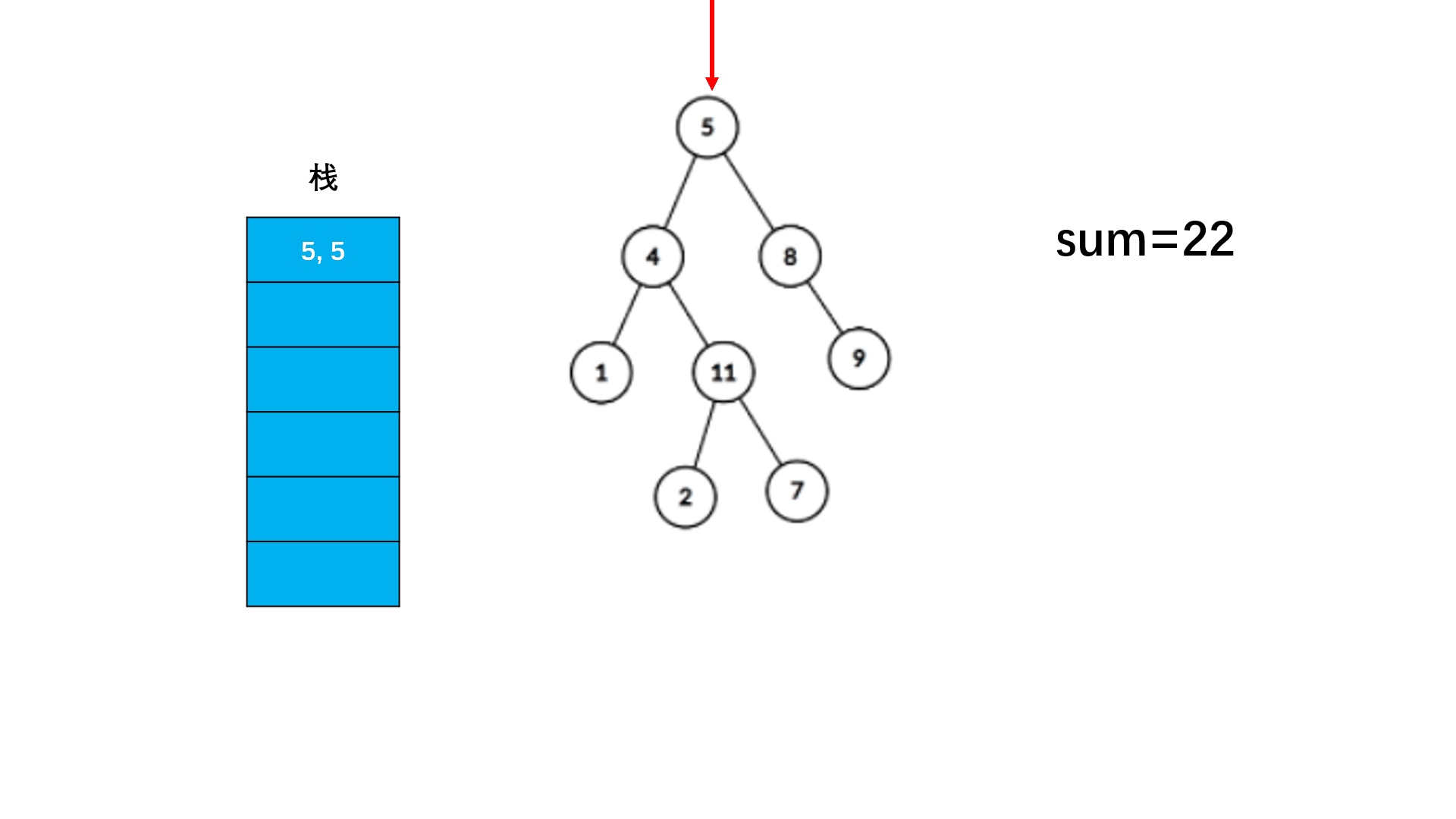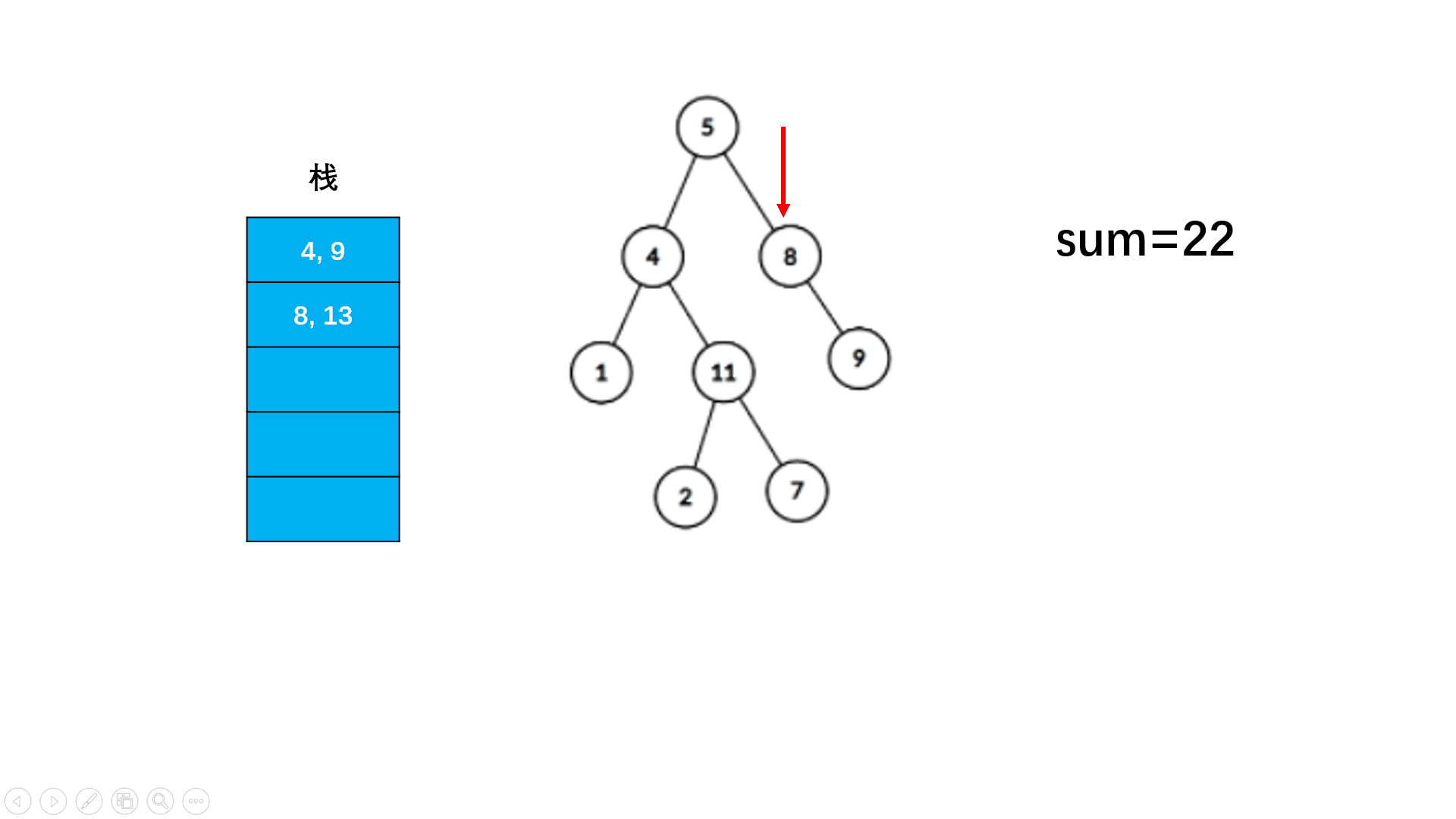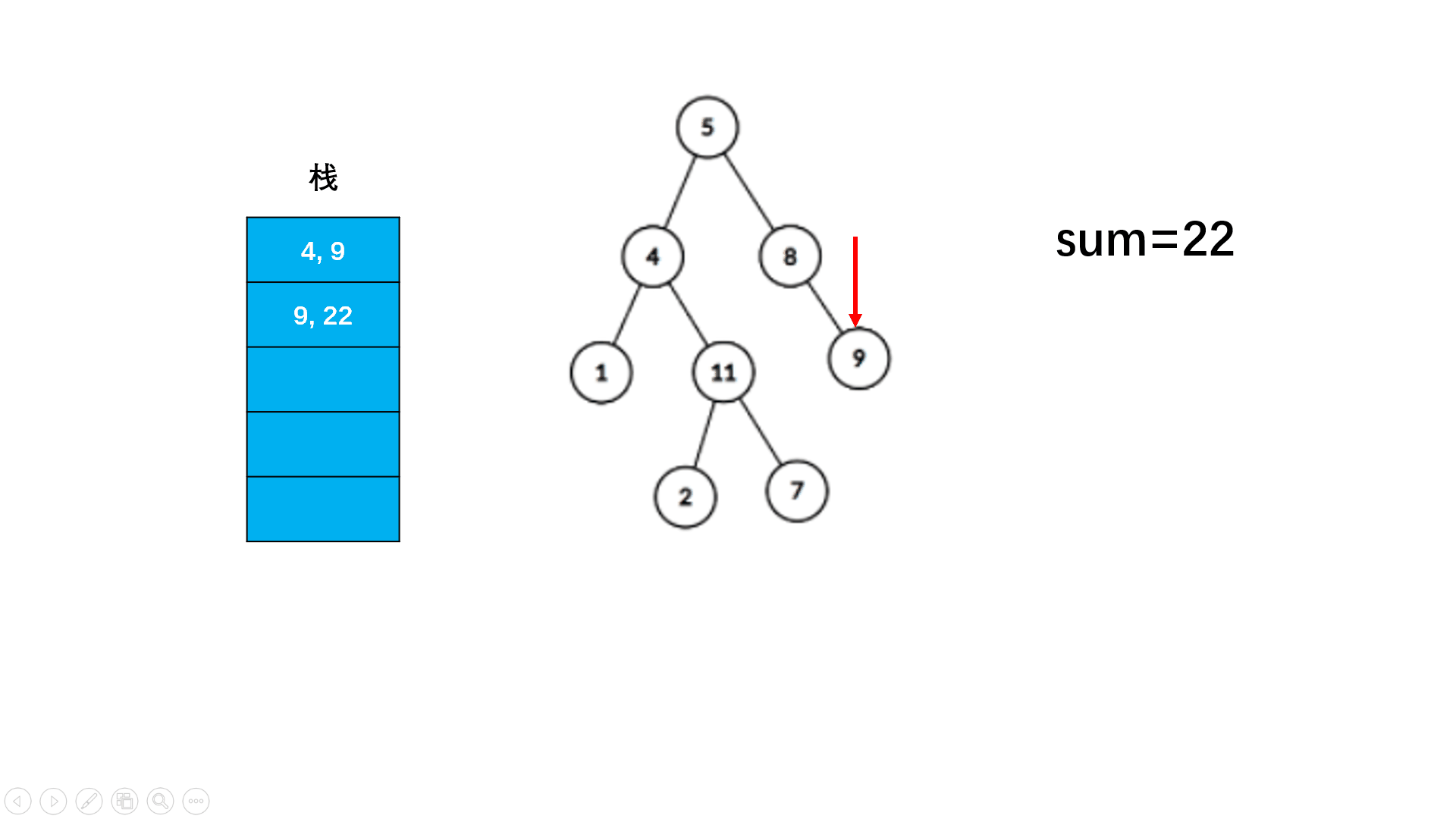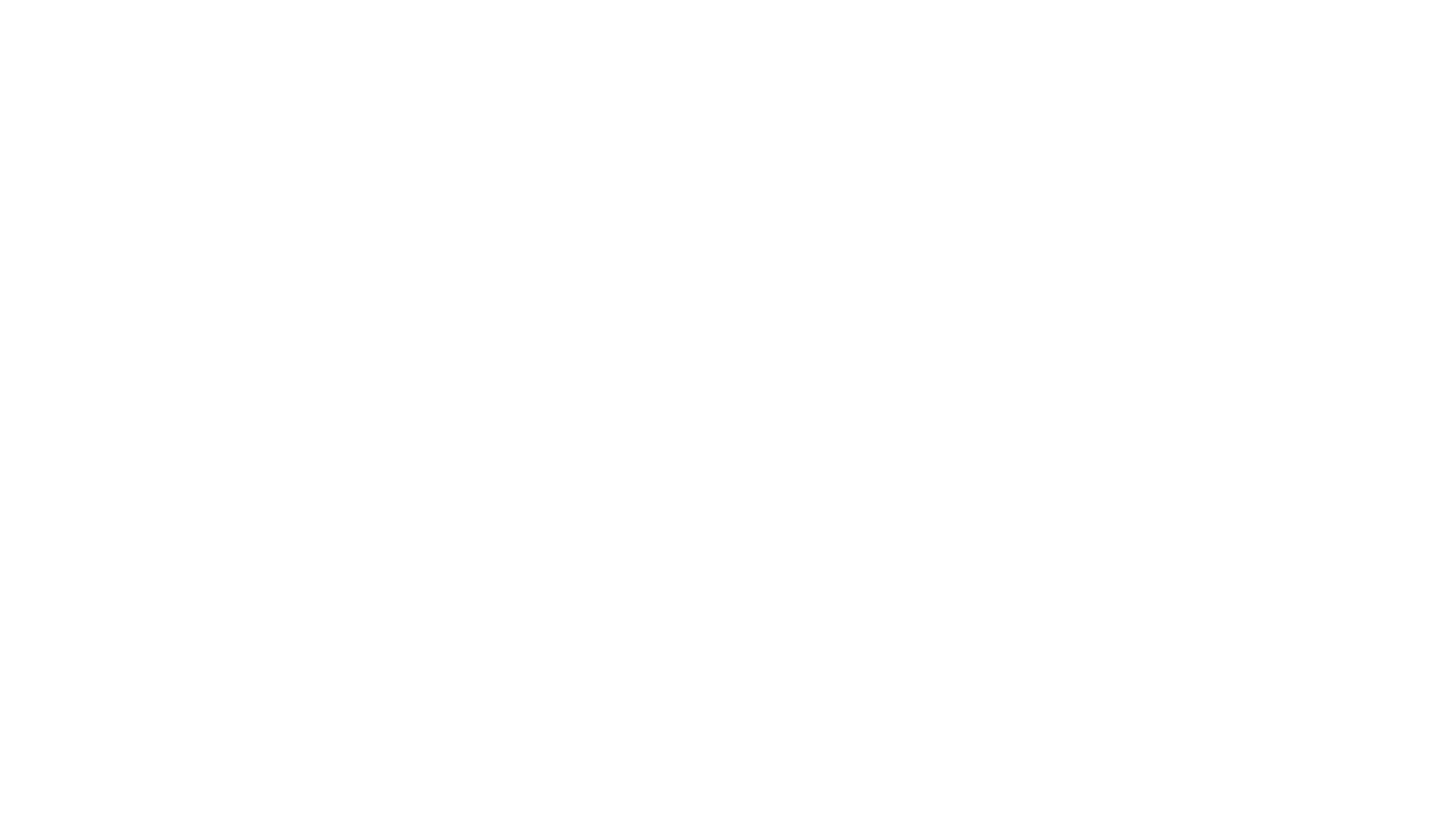
Redis的核心处理逻辑一直都是单线程 有一些分支模块是多线程(某些异步流程从4.0开始用的多线程,例如UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC等非阻塞的删除操作。网络I/O解包从6.0开始用的是多线程;)
为什么是单线程
多线程多好啊可以利用多核优势
官方给的解释
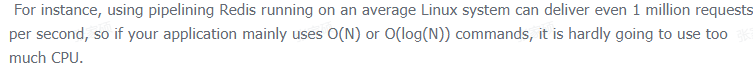
意思就是Redis的定位,是内存k-v存储, 是做短平快的热点数据处理,一般来说执行会很快,执行本身不是瓶颈,而瓶颈通常在网络I/O,处理逻辑多线程并不会有太大收益。
同时,Redis本身 秉持简洁高效的理念,代码的简单性、可维护性 是Redis以来一直以来的追求,引入多线程带来的复杂性远比想象的要大,而且多线程本身也会引入额外成本,细说
1.多线程的引入的复杂度很大
1.首先,多线程引入之后,Redis原来的顺序执行特性就不复存在,为了支持事务的原子性、隔离性,Redis就不得不引入一些很复杂的实现; .
2.Redis的数据结构极其高效,在单线程模式下做了很多特性的优化,如果引入多线程,那么所有
底层数据结构都要改造为线程安全,这会是极其复杂的工作;
3.而且,多线程模式也使得程序调试更加复杂和麻烦,会带来额外的开发成本及运营成本,也更容易犯错(回想一下MYSQL并发....)
2.多线程带来额外的成本
1.上下文切换成本,多线程调度需要切换线程上下文,这个操作先存储当前线程的本地数据、程序指针等,然后载入另一个线程数据,这种内核操作的成本不可忽视。
2.同步机制的开销,-些公共资源,在单线程模式下直接访问就行了,多线程需要通过加锁等方式去进行同步,这也是不可忽视的CPU开销;
3.一个线程本身也占据内存大小,对Redis这种内存数据库而言,内存非常珍贵,多线程本身带来的内存使用的成本也需要谨慎决策。
单线程为什么这么快
第一,Redis的大部分操作在内存上完成,内存操作本身就特别快;
第二,Redis追求极致,选择了很多高效的数据结构,并做了非常多的优化,比如ziplist, hash,跳表,有时候一种对象底层有几种实现以应对不同场景。
第三,Redis 采用了多路复用机制,使其在网络I0操作中能并发处理大量的客户端请求,实现高吞吐量。
第一第二点挺好理解的 第三点怎么说
什么叫I/0多路复用,简单理解来说,就是有I/0操作触发的时候,就会产生通知,收到通知,再去处理通知对应的事件,针对I/0多路复用,Redis做了一层包装,叫Reactor模型。
本质就是监听各种事件,当事件发生时,将事件分发给不同的处理器。
这样就不会阻塞在某一个操作上,充分发挥性能,可以说I/O多路复用让Redis单线程也有了较大的并发度,注意这里是并发,而不是并行,在这种模式下,Redis单 核的性能可以说是被充分的利用了。
但是呢
现在业务量实在是太大了
前面也有说过,Redis选择 单线程的核心原因是Redis是都是内存操作,CPU处理都非常快,瓶颈更容易出现在I/O而不是CPU,所以选择了单线程模型。
随着时代的发展,很多业务的请求量都达到了一个曾经难以想象的高度,I/O操作确实成为了瓶颈,而之前Redis处理流程中读取请求、发送回包都属于I/O操作,所以Redis引入了多线程,这里的多线程也不是说将整个处理逻辑都多线程化,如果这么做,需要对所有数据结构进行线程安全重构,这是巨大的成本,并且,也不见得能有多大提升,甚至可能因为损耗而降低,毕竟瓶颈大多时候都不在处理,瓶颈实际一般都在 于网络I/O。
因为上述情况,Redis选择了引入多线程来处理网络I/O,仍然使用单线程框架来执行Redis命令,这样既保持了Redis核心的单线程处理架构,完全兼容以前的实现,又引入了多线程解决提升网络I/O的性能。
关于多线程不需要了解太多
首先 多线程是6.0之后引入的 为了解决日益变多的数据量 默认是关闭了 可以在.conf里面修改 多线程负责的是处理网络I/O 具体来说
读取并解析指令以及回包。
单线程模式下是一个线程完成读取、解析、执行、将回包放入客户端缓冲区;
但在多线程模式下,会将不同的client放 入clients_ pending_ read任务队列中, 后续会通Round-Robin轮询负载均衡策略把这些client分给其他IO线程和主线程进行读取和解析;在回包的时候,也是利用Round-Robin轮询负 载均衡策略把等待回包队列中的任务连续均匀地分配给IO线程各自的
本地FIFO任务队列和主线程自己,主线程轮询等待所有IO线程完成回包任务