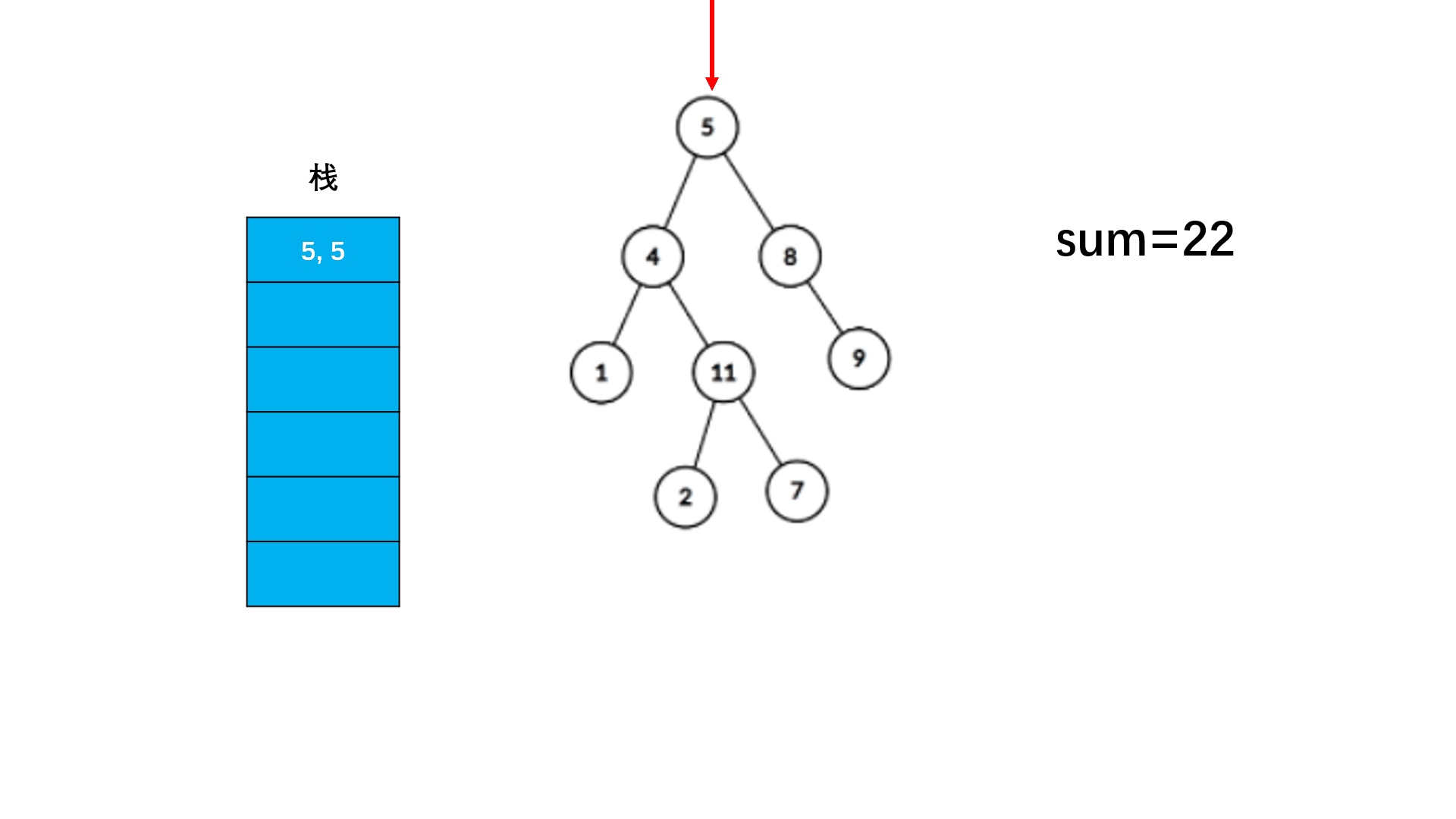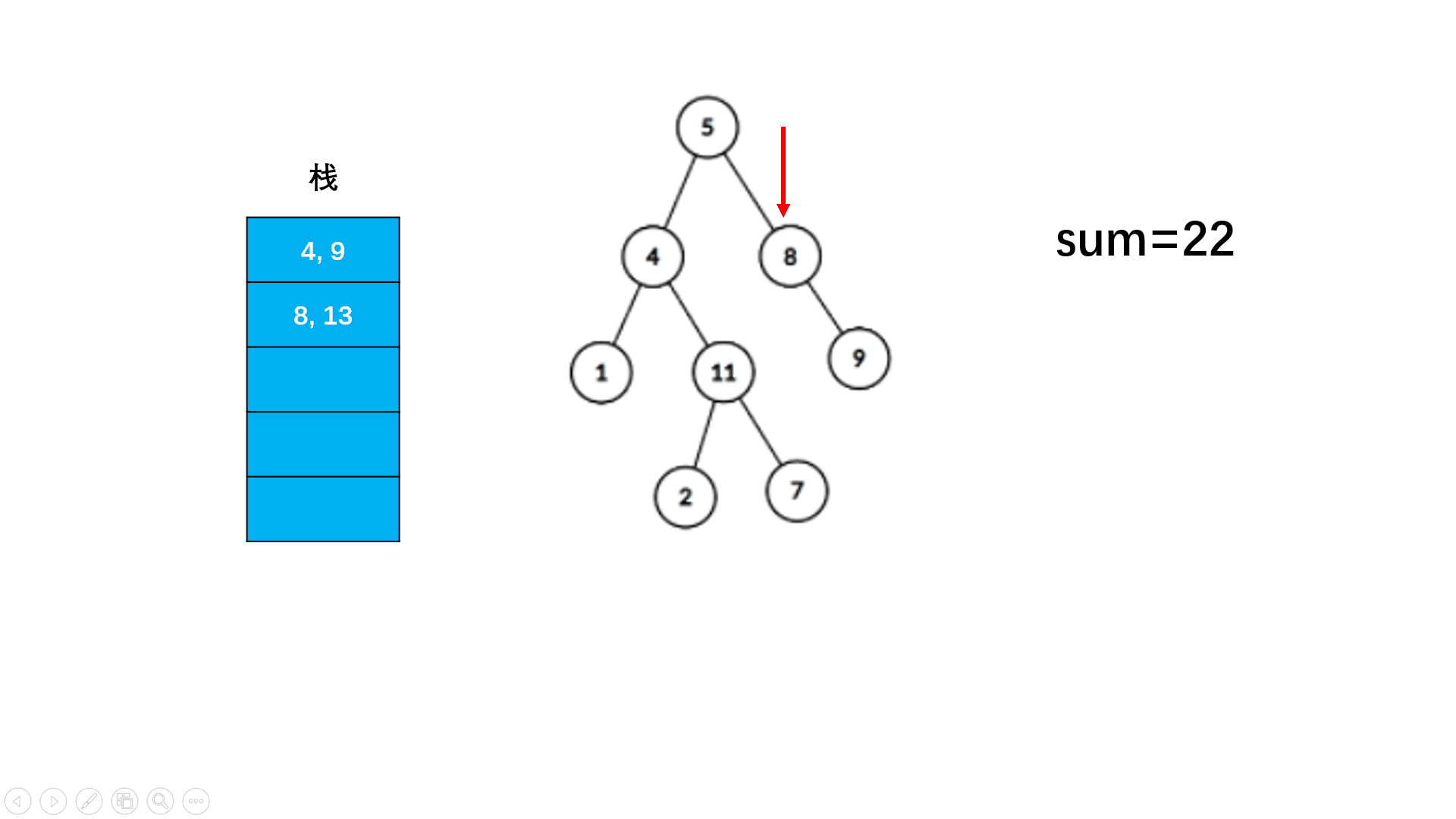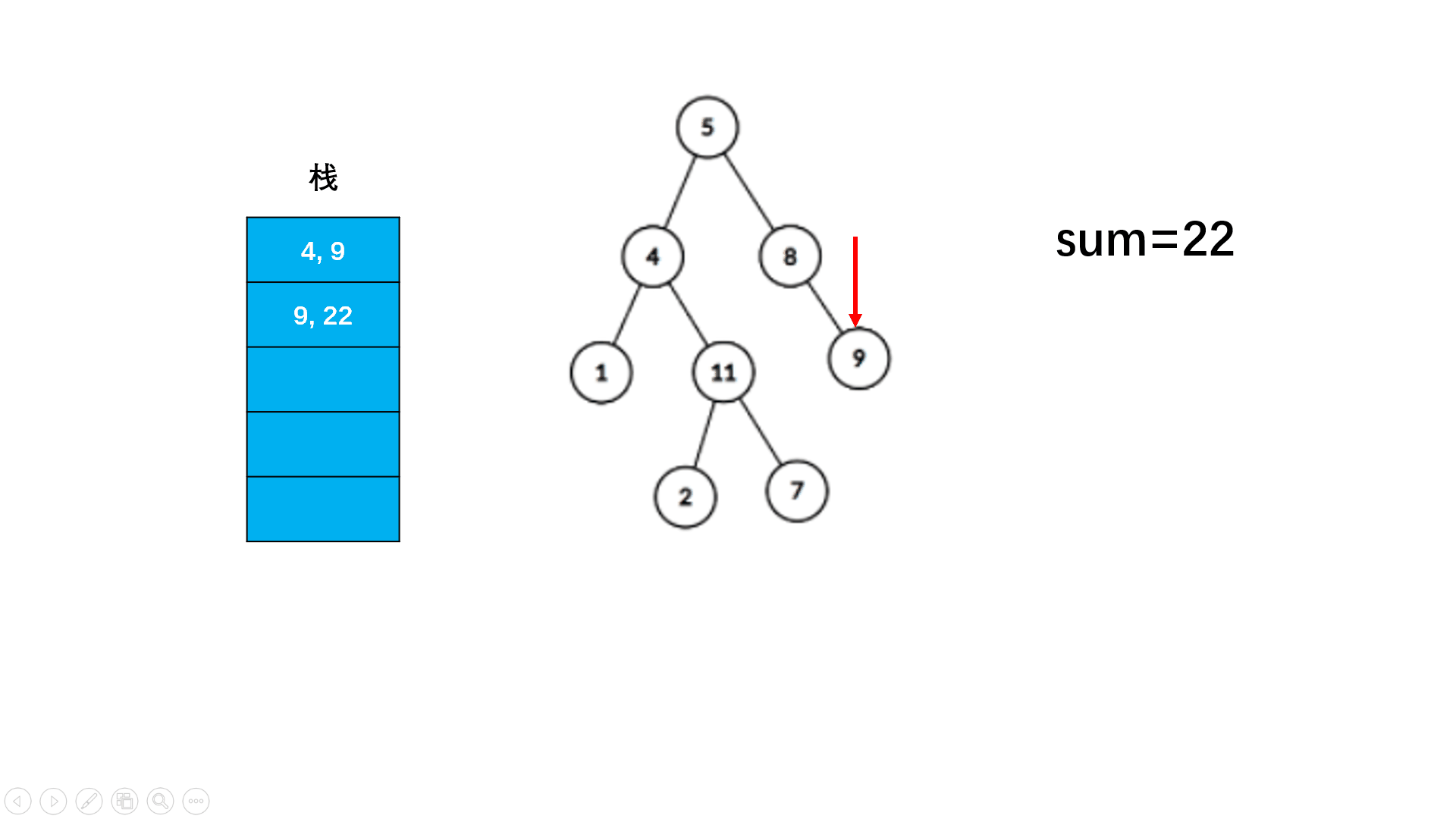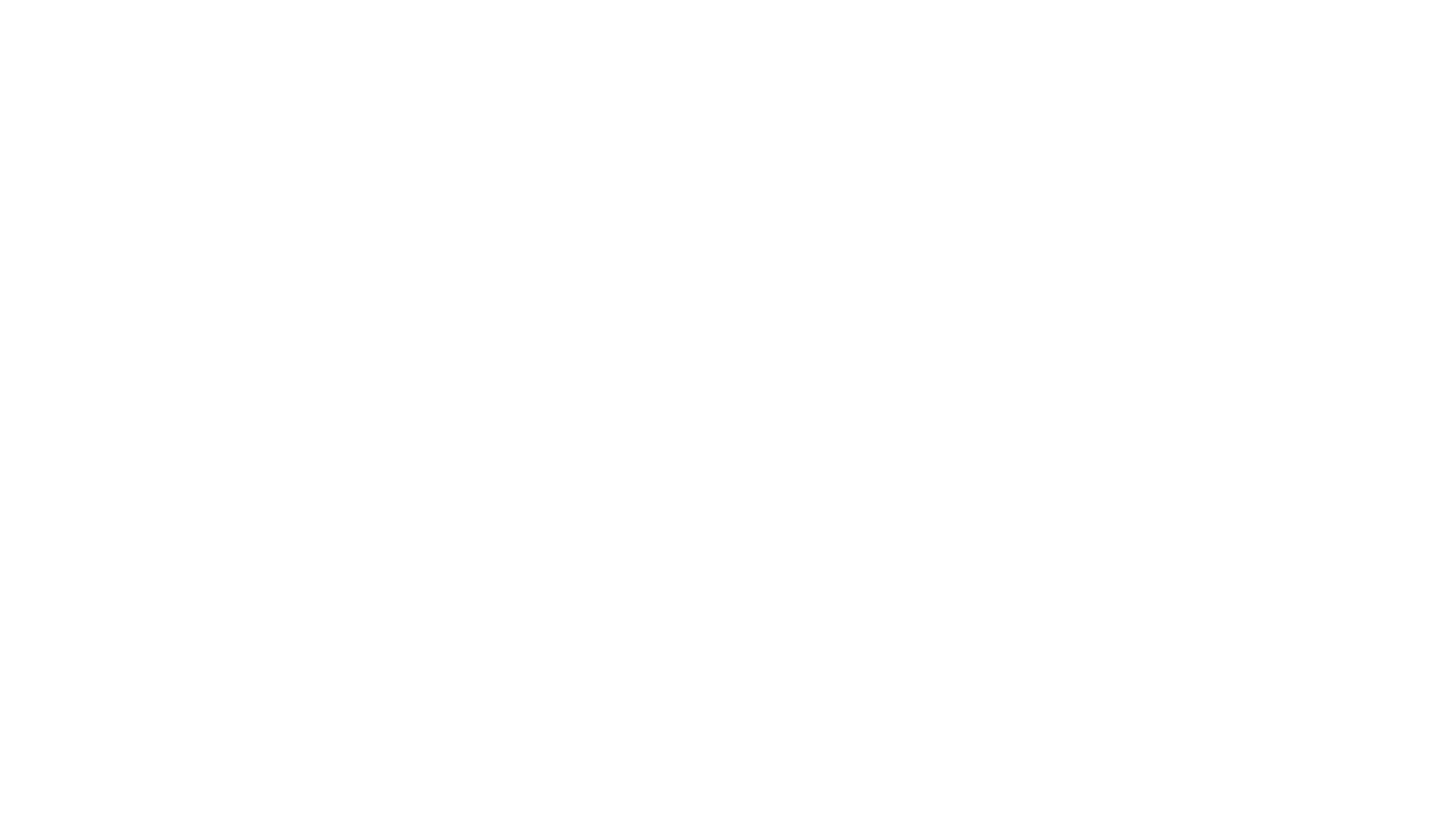
文章目录
- Abstract
- 1.Introduction
- 2. Related Work
- 3. Our Method
- 3.1 Long- and Short-range Branches
- 3.2 SNR-based Spatially-varying Feature Fusion
- 3.3 SNR-guided Attention in Transformer
- 3.4 Loss Function
- 4. Experiments
- 4.1. Datasets and Implementation Details
- 4.2 Comparison with Current Methods
- 4.3 Ablation Study
- 4.4. Influence of SNR Prior
- 5. Conclusion
论文链接(CVPR2022):《SNR-Aware Low-light Image Enhancement》
源码链接:https://github.com/dvlab-research/SNR-Aware-Low-Light-Enhance
Abstract
本文提出了一种新的弱光图像增强解决方案,通过综合利用Signal-to-Noise-Ratio-aware transformers和Convolution models,利用空间变化操作动态增强像素。
它们是对极低信噪比(SNR)图像区域的long-range操作和对其他区域的short-range操作。
我们提出在引导特征融合之前先考虑信噪比,并利用一种新的自注意模型构建SNR-aware Transformer,以避免来自极低信噪比的噪声图像区域的token。
大量的实验表明,在7个具有代表性的基准测试中,我们的框架始终比SOTA方法获得更好的性能。此外,我们进行了一项大规模的用户研究,有100名参与者来验证我们的结果优越的感知质量。
1.Introduction
微光成像对于许多任务都是至关重要的,比如夜间的物体和动作识别[18,27]。弱光图像通常可视性较差,不适合人类感知。同样,当直接以弱光图像作为输入时,下游视觉任务也会受到影响。
目前已经提出了几种增强弱光图像的方法。如今,事实上的方法是学习操纵颜色、色调和对比度的神经网络,以增强弱光图像[12,15,41,56],而最近的一些作品考虑了图像中的噪声[29,48]。
本文的核心思想是:
在微光图像中,不同的区域可以具有不同的亮度、噪声、可见性等特征。亮度极低的区域会受到噪声的严重破坏,而同一图像中的其他区域仍然可以有合理的能见度和对比度。
为了更好的整体图像增强,我们应该自适应地考虑弱光图像中的不同区域。
因此,我们通过探索信噪比(signal-To-noise- ratio, SNR)[3, 54]来研究图像空间中信噪比的关系,以实现空间变化增强。
1. 低信噪比的区域通常是不清楚的。因此,我们在更长的空间范围内利用非局部图像信息进行图像增强。 (Long-range)
2. 信噪比较高的区域通常具有较高的能见度和较少的噪声。因此,本地图像信息通常就足够了。(Short-Range)
下图所示为弱光图像举例说明。

本文提出了对于在RGB空间下的弱光图像增强解决方案 是同时利用long-range 和short-range的operation。
1. 具有Transfomer结构的long-range[38]捕获非局部信息
2. 具有convolutional residual blocks[17]的short-range捕获局部信息.
在增强每个像素时,我们根据像素的信噪比动态地确定局部(short-range)和非局部(long-range)信息的贡献。
因此,在高信噪比区域,局部信息在增强过程中起着至关重要的作用,而在非常低信噪比区域,非局部信息是有效的。
为了实现这种空间变化的操作,我们构造了一个SNR prior,并利用它来指导特征融合。同时,我们修改了Transformer结构中的注意机制,提出了SNR-aware Transformer。
与现有的Transformer结构不同,并不是所有的token都有助于注意力计算。我们只考虑具有足够信噪比的Token,以避免极低信噪比区域的噪声影响。
我们的框架有效地增强了动态噪声水平的微光图像。在7个具有代表性的数据集上进行了广泛的实验:LOL (v1 [45], v2real [53], & v2-synthetic[53])、SID[5]、SMID[4]和SDSD(室内和室外)[39]。
如图1所示,我们的框架在所有具有相同结构的数据集上都优于10种SOTA方法。此外,我们进行了大规模的用户研究,有100名参与者来验证我们的方法的有效性。定性比较如图3所示。

总的来说,我们的贡献有如下三点:
- 我们提出了一种新的信噪比感知框架,该框架利用SNR prior,并同时采用transformer structure和convolutional model来实现空间变化的弱光图像增强。
- 我们设计了一种具有自注意模块的SNR-aware transformer,用于弱光图像增强。
- 我们在七个有代表性的数据集上进行了广泛的实验,表明我们的框架始终优于一组丰富的SOTA方法。
2. Related Work
- No-learning-based Low-light Image Enhancement
为了增强微光图像,直方图均衡化和伽玛校正是扩展动态范围和提高图像对比度的基本工具。这些主要方法往往会在增强的真实图像中产生不希望看到的伪影。基于retexx的方法,将反射分量视为图像增强的似是而非的近似,能够产生更真实和自然的结果[28,35]。然而,当增强复杂的真实图像时,这一行方法经常会局部扭曲颜色[40]。 - Learning-based Low-light Image Enhancement
近年来提出了许多基于学习的微光图像增强方法[2,14,20,22,29,31,42,48-50,52,53,59,60,62,63]。Wang et al.[40]提出了预测光照图来增强曝光不足的照片。Sean等人设计了一种策略来学习三种不同类型的空间局部滤波器来增强。Yang等人提出了一种半监督方法来恢复微光图像的线性带表示。此外,还有非监督方法[7,14,19]。例如Guo等人[14]构建了一个轻量级网络来估计像素级和高阶曲线,用于动态范围调整。
与之前的工作不同,我们的新方法基于一个信噪比感知框架,包括一个新的SNR-aware Transformer设计和一个卷积模型,以空间变化的方式自适应增强弱光图像。如图1所示,我们的框架在7个相同结构的不同基准上都取得了更好的性能。
3. Our Method
图4显示了我们框架的概述。输入是一个弱光图像,我们首先使用一个简单而有效的策略获得一个SNR map(详细信息见第3.2节)。我们提出以SNR为指导,对不同signal-to-noise ratios的图像区域自适应地学习不同的增强操作。

在我们框架的最深层隐藏层中,我们为long-range和short-range设计了两个不同的分支。它们是专门为实现高效操作而制定的,分别由transformer[38]和卷积结构实现。为了实现长时间的工作,同时避免在极暗区域噪声的影响,我们用一个SNR map来指导transformer的注意机制。为了采用不同的操作,我们提出了一种基于信噪比的融合策略,从long-range、short-range特征中获得组合表示。此外,我们使用从编码器到解码器的skip connections来增强图像细节。
3.1 Long- and Short-range Branches
- Necessity of spatial-varying operations
传统的微光图像增强网络在最深的隐藏层采用卷积结构。这些操作大多是在short-range 获取本地信息。局部信息可能足以恢复不是非常暗的图像区域,因为这些像素仍然包含大量可见的图像内容(或信号)。但是对于非常暗的区域,局部信息不足以增强像素,因为相邻的局部区域的可见度也很弱,且大多是噪声。
为了解决这一关键问题,我们利用不同的局部和非局部通信动态增强不同区域的像素。本地和非本地信息是互补的。这种效果可以根据图像上的SNR分布来确定。一方面,对于高SNR的图像区域,局部信息应该起主要作用,因为局部信息已经足够增强了。它通常比long-range 非本地信息更准确。
另一方面,对于非常低信噪比的图像区域,我们更多地关注非局部信息,因为局部区域在噪声的主导下可能具有很少的图像信息。与以往方法不同的是,在我们的框架中,我们明确地为非常低信噪比的图像区域制定了一个long-range分支,为其他区域制定了一个short-range分支(见图4)。
- Implementation of two branches
由于transformer 善于通过全局自注意机制捕获long-range依赖关系,因此,基于transformer[38]结构实现了远程分支。这在许多高水平任务[10,16,21,30,46,57,58]和低水平任务[6,44]中得到了证实。
在long-range 分支中,我们首先将feature map F F F (编码器从输入图像 I ∈ R H × W × 3 I∈R^{H×W×3} I∈RH×W×3中提取)划分为m个特征块,即 F i ∈ R p × p × C F_i∈R^{p×p×C} Fi∈Rp×p×C, I = 1 , … , m I ={1,…,m} I=1,…,m。假设feature map F F F 的大小为 h × w × C h × w × C h×w×C, patch的大小为 p × p p × p p×p,覆盖整个feature map的feature patches有 m = h p × w p m = \frac{h}{p} × \frac{w}{p} m=ph×pw.
如图4所示,我们的SNR-aware transformer是基于patch的。它由多头自注意(MSA)模块[38]和前馈网络(FFN)[38]组成,两者都由两个全连接层组成。从transformer的output feature F 1 , . . . , F m F_1,...,F_m F1,...,Fm 具有相同大小的input feature。我们把 F 1 , . . . , F m F_1,...,F_m F1,...,Fm flatten 到1D的特征,并进行计算
y 0 = [ F 1 , F 2 , … , F m ] , q i = k i = v i = L N ( y i − 1 ) , y ^ i = M S A ( q i , k i , v i ) + y i − 1 , y i = F F N ( L N ( y ^ i ) ) + y ^ i , and [ F 1 , F 2 , … , F m ] = y l , i = { 1 , … , l } , \begin{aligned}& y_0=\left[F_1, F_2, \ldots, F_m\right] \text {, } \\& q_i=k_i=v_i=L N\left(y_{i-1}\right) \text {, } \\& \widehat{y}_i=M S A\left(q_i, k_i, v_i\right)+y_{i-1} \text {, } \\& y_i=F F N\left(L N\left(\widehat{y}_i\right)\right)+\widehat{y}_i, \\& \text { and }\left[\mathcal{F}_1, \mathcal{F}_2, \ldots, \mathcal{F}_m\right]=y_l, i=\{1, \ldots, l\} \text {, } \\&\end{aligned} y0=[F1,F2,…,Fm], qi=ki=vi=LN(yi−1), y i=MSA(qi,ki,vi)+yi−1, yi=FFN(LN(y i))+y i, and [F1,F2,…,Fm]=yl,i={1,…,l},
式中, L N LN LN为 Layer normalization; y i y_i yi表示第 i i i 个transformer block的输出; M S A MSA MSA 表示 SNR-aware multi-head self-attention module (见图5),将在第3.3节详细介绍; Q i 、 k i 、 v i Q_i、k_i、v_i Qi、ki、vi分别表示第 i i i 个多头自我注意模块中的查询向量、键向量和值向量; l l l 表示transformer 的层数。Transformed feature F 1 , … , F m \mathcal{F}_1, \ldots, \mathcal{F}_m F1,…,Fm 可以合并形成2D feature map F l \mathcal{F}_l Fl(见图4)。
3.2 SNR-based Spatially-varying Feature Fusion
如图4所示,我们利用编码器 E \mathcal{E} E从输入图像 I I I中提取特征 F F F,然后将该特征分别由long-range 和short-range 分支进行处理,产生long-range特征 F l ∈ R h × w × C \mathcal{F}_l∈R^{h×w×C} Fl∈Rh×w×C和short-range 特征 F s ∈ R h × w × C \mathcal{F}_s∈R^{h×w×C} Fs∈Rh×w×C。为了自适应地结合这两个特征,我们将信噪比映射的大小调整为 h × w h × w h×w,将其归一化到 [0,1] 范围内,并将归一化后的信噪比映射 S ’ S’ S’作为插值权值,将 F l F_l Fl和 F s Fs Fs融合为 :
F = F s × S ′ + F l × ( 1 − S ′ ) \mathcal{F}=\mathcal{F}_s \times S^{\prime}+\mathcal{F}_l \times\left(1-S^{\prime}\right) F=Fs×S′+Fl×(1−S′)
其中 F ∈ R h × w × C F∈R^{h×w×C} F∈Rh×w×C是传递给解码器以产生最终输出图像的输出特征。由于SNR map 中的值动态地显示了输入图像不同区域的噪声水平,因此融合可以自适应地结合局部(近程)和非局部(长程)图像信息产生 F \mathcal{F} F。
3.3 SNR-guided Attention in Transformer
- Limitation of traditional transformer structures
虽然传统的transformer可以捕获非局部信息来增强图像,但它们也存在一些关键问题。在原始结构中,对所有的patch进行注意计算。为了增强一个像素,long-range 的注意力可能来自任何图像区域,而不考虑信号和噪声水平。事实上,非常低信噪比的区域是由噪声主导的。因此,它们的信息是不准确的,严重干扰了图像增强。在此,我们提出了SNR 引导下的transformer改进的注意事项。
- SNR-aware transformer

图5显示了我们的具有新的自注意模块的SNR-aware Transformer。给定输入图像 I ∈ R H × W × 3 I∈R^{H×W×3} I∈RH×W×3,对应的SNR map S ∈ R H × W S∈R^{H×W} S∈RH×W,我们先调整S的大小为 S ’ ∈ R h × w S’∈R^{h×w} S’∈Rh×w来匹配 feature map F F F 的大小,然后按照 F F F划分patch的方法将 S ’ S’ S’ 划分为 m m m 个patch,并计算每个patch的平均值,即 S i ∈ R 1 , I = { 1 , … , m } S_i∈R^1, I =\{1,…,m\} Si∈R1,I={1,…,m}。我们把这些值打包成向量 S ∈ R m S∈R^m S∈Rm。它在transformer的注意力计算中起到了掩模的作用,可以避免transformer中极低信噪比的图像区域(见图5)的信息传播。S的第 i i i个元素的掩码值表示为 :
S i = { 0 , S i < s 1 , S i ≥ s , i = { 1 , … , m } , \mathcal{S}_i=\left\{\begin{array}{ll}0, & S_i<s \\1, & S_i \geq s\end{array}, i=\{1, \ldots, m\},\right. Si={0,1,Si<sSi≥s,i={1,…,m},
其中 s s s为阈值。接下来,我们将 S \mathcal{S} S的m个副本堆叠,形成矩阵 S ’ ∈ R m × m S’∈R^{m×m} S’∈Rm×m。设multi-head self-attention (MSA)模块(式(1))的head数为 B B B,则Transformer第 i i i 层第b个head 的self-attention A t t e n t i o n i , b Attention_{i,b} Attentioni,b为 :
Q i , b = q i W b q , K i , b = k i W b k , V i , b = v i W b v , and Attention i , b ( Q i , b , K i , b , V i , b ) = Softmax ( Q i , b K i , b T d b + ( 1 − S ′ ) σ ) V i , b \begin{gathered}\mathbf{Q}_{i, b}=q_i W_b^q, \mathbf{K}_{i, b}=k_i W_b^k, \mathbf{V}_{i, b}=v_i W_b^v, \quad \text { and } \\\text { Attention }_{i, b}\left(\mathbf{Q}_{i, b}, \mathbf{K}_{i, b}, \mathbf{V}_{i, b}\right)=\operatorname{Softmax}\left(\frac{\mathbf{Q}_{i, b} \mathbf{K}_{i, b}^T}{\sqrt{d_b}}+\left(1-\mathcal{S}^{\prime}\right) \sigma\right) \mathbf{V}_{i, b}\end{gathered} Qi,b=qiWbq,Ki,b=kiWbk,Vi,b=viWbv, and Attention i,b(Qi,b,Ki,b,Vi,b)=Softmax(dbQi,bKi,bT+(1−S′)σ)Vi,b
其中 q i , k i , v i ∈ R m × ( p × p × C ) q_i, k_i, v_i \in \mathbb{R}^{m \times(p \times p \times C)} qi,ki,vi∈Rm×(p×p×C) 是式(1)中输入的2D feature, W k q , W k k , W k v ∈ R ( p × p × C ) × C k W_k^q, W_k^k, W_k^v \in \mathbb{R}^{(p \times p \times C) \times C_k} Wkq,Wkk,Wkv∈R(p×p×C)×Ck 表示的是第k个head的投影矩阵。 Q i , b , K i , b , V i , b ∈ R m × C k Q_{i,b}, K_{i,b}, V_{i,b} \in \mathbb{R}^{m\times C_k} Qi,b,Ki,b,Vi,b∈Rm×Ck 分别是在attention 计算中的query, key, value features。
S o f t m a x ( ) Softmax() Softmax() 和 A t t e n t i o n i , b ( ) Attention_{i,b}() Attentioni,b() 的输出形状分别是 m × m m\times m m×m 和 m × C k m \times C_k m×Ck, 其中 C k C_k Ck 是self-attention 计算中的通道数量。 d k \sqrt {d_k} dk 是为了归一化,σ是一个小的负标量−1e9。 B个head的输出都被连接到了一起,所有的值都被线性地投影在transformer的第 i i i层产生MSA的最终输出。因此,我们保证了long-range的attention来自于具有充足SNR 的图像区域。
3.4 Loss Function
- Data FLow
给定输入图像 I I I,我们首先应用一个具有卷积层的Encoder来提取特征 F F F。编码器的每个阶段包含一个卷积层和LeakyReLU[47]的堆栈。剩余卷积块在编码器之后使用。然后将 F F F转发到long-range 和short-range 分支中,生成特征 F l F_l Fl和 F s F_s Fs。最后,我们将 F l F_l Fl和 F S F_S FS融合为 F F F,并使用译码器(与编码器对称)将 F F F转换为残差 R R R。最终输出图像 I ′ = I + R I ' = I +R I′=I+R
- Loss Terms
有两个重构损失术语来训练我们的框架,即Charbonnier loss[25]和Percepture loss。Charbonnier loss写成 :
L r = ∥ I ′ − I ^ ∥ 2 + ϵ 2 L_r=\sqrt{\left\|I^{\prime}-\widehat{I}\right\|_2+\epsilon^2} Lr= I′−I 2+ϵ2
其中, I ^ \hat I I^为ground truth, ϵ \epsilon ϵ 在所有实验中均取 1 0 − 3 10^{−3} 10−3。Percepture loss使用L1损失来比较 I ^ \hat I I^ 和 I ‘ I‘ I‘之间的VGG特征距离。
L v g g = ∥ Φ ( I ′ ) − Φ ( I ^ ) ∥ 1 L_{v g g}=\left\|\Phi\left(I^{\prime}\right)-\Phi(\widehat{I})\right\|_1 Lvgg= Φ(I′)−Φ(I ) 1
其中 Φ ( ) Φ() Φ() 是从VGG网络[37]中提取特征的操作。总的损失函数为 :
L = L r + λ L v g g L=L_r+\lambda L_{v g g} L=Lr+λLvgg
λ是一个超参数。
4. Experiments
4.1. Datasets and Implementation Details
我们在几个数据集(具有可观测噪音的微光区域)评估了我们的框架。它们是LOL (v1 & v2) [45, 53], SID [5], SMID[4]和SDSD[39]。
- LOL
LOL在v1和v2版本中都有明显的噪音。
LOL-v1[45]包含485对low/normal-light 图像用于训练,15对用于测试。每一对包括一个弱光输入图像和一个相关的适定参考图像。
LOL -v2[53]分为LOLv2-real和LOLv2 -synthetic。
LOLv2- v2-real包含689对低/正常光图像对用于训练,100对用于测试。在固定其他相机参数的情况下,通过改变曝光时间和ISO来收集大多数弱光图像。
LOL -v2-synthetic是通过分析RAW格式中的光照分布而生成的。
- SID/SMID
对于SID和SMID,每个输入样本都是一对短曝光和长曝光图像。SID和SMID都有较大的噪声,这是因为它们是在极端黑暗的环境下拍摄的弱光图像。
对于SID,我们使用Sony摄像机捕获的子集,并遵循SID提供的脚本,使用rawpy的默认ISP将弱光图像从RAW转换为RGB。
对于SMID,我们使用它的完整图像,也将RAWdata传输到RGB,因为我们的工作是在RGB域探索微光图像增强。我们按照[4]的训练和测试划分。 - SDSD
最后,我们采用SDSD数据集39进行评估。它包含一个室内子集和一个室外子集,都提供低光和正常光对。
我们在PyTorch[34]中实现了我们的框架,并在带有2080Ti GPU的PC上对其进行训练和测试。
我们用高斯分布随机初始化的网络参数从头开始训练我们的方法,并采用标准的增广方法,例如垂直和水平翻转。
我们框架的编码器有三个卷积层(即strides 1,2,2),编码器后有一个残差块。解码器与编码器对称,使用ChannelShuffle[36]实现上采样机制。为了最小化损失,我们采用了Adam[23]优化器,动量设置为0.9。
4.2 Comparison with Current Methods
我们将我们的方法与SOTA方法中丰富的微光图像增强方法进行了比较,包括Dong[9]、LIME[15]、MF[11]、SRIE[12]、BIMEF[55]、DRD[45]、RRM[28]、SID[5]、DeepUPE[40]、KIND[61]、DeepLPF[33]、FIDE[48]、LPNet[26]、MIR-Net[59]、RF[24]、3DLUT[60]、A3DLUT[42]、Band[52]、EG[20]、Retinex[29]和Sparse[53]。此外,我们还将我们的框架与两种最新的用于低级任务的Transformer结构(IPT[6]和Uformer[44])进行了比较。
-
Quantitative analysis
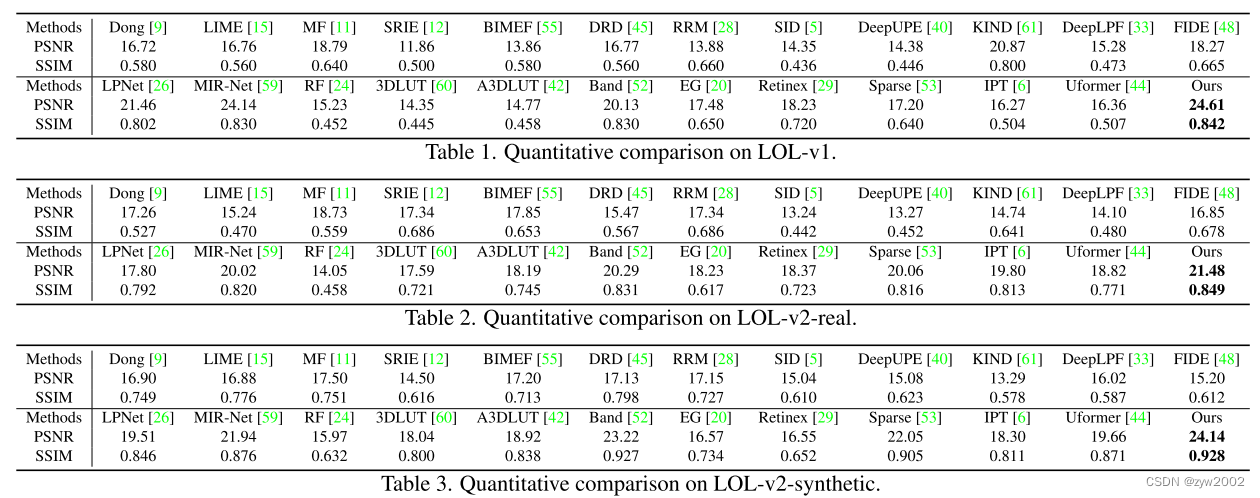
我们采用峰值信噪比(PSNR)和结构相似度指数(SSIM)[43]进行评价。一般来说,更高的SSIM意味着结果中更高频的细节和结构。表1-3显示了LOL -v1、LOL -v2-real和LOL -v2synthetic的比较。我们的方法超越了所有的基线。
请注意,我们从各自的论文或运行各自的公共代码中获得这些数字。我们的方法(24.61/0.842)在LOL-v1上也优于22和62。表4对SID、SMID、SDSD-indoor和SDSD-outdoor的方法进行了比较。我们的算法性能最好。
-
Qualitative analysis
首先,我们在图6(最上面一行)中展示了视觉样本,将我们的方法与在LOL-v1上获得最佳性能(在PSNR方面)的基线进行比较。我们的方法可以得到更好的视觉质量与更高的对比度,更精确的细节,颜色一致性和更好的亮度。
图6也显示了LOLv2-real和lolv2 -synthetic的视觉对比。虽然这些数据集中的原始图像存在明显的噪声和弱光照,但我们的方法仍然可以得到更真实的结果。此外,在具有复杂纹理的区域,我们的输出显示出更少的视觉伪影。

图7(上一行)显示了对SID的视觉比较,表明我们的方法可以有效地处理非常嘈杂的弱光图像。图7还显示了SMID、sdsd -indoor和sdsd -outdoor的可视化结果。这些结果也表明,该方法在抑制噪声的同时,能有效地增强图像亮度,揭示图像细节。

-
User study
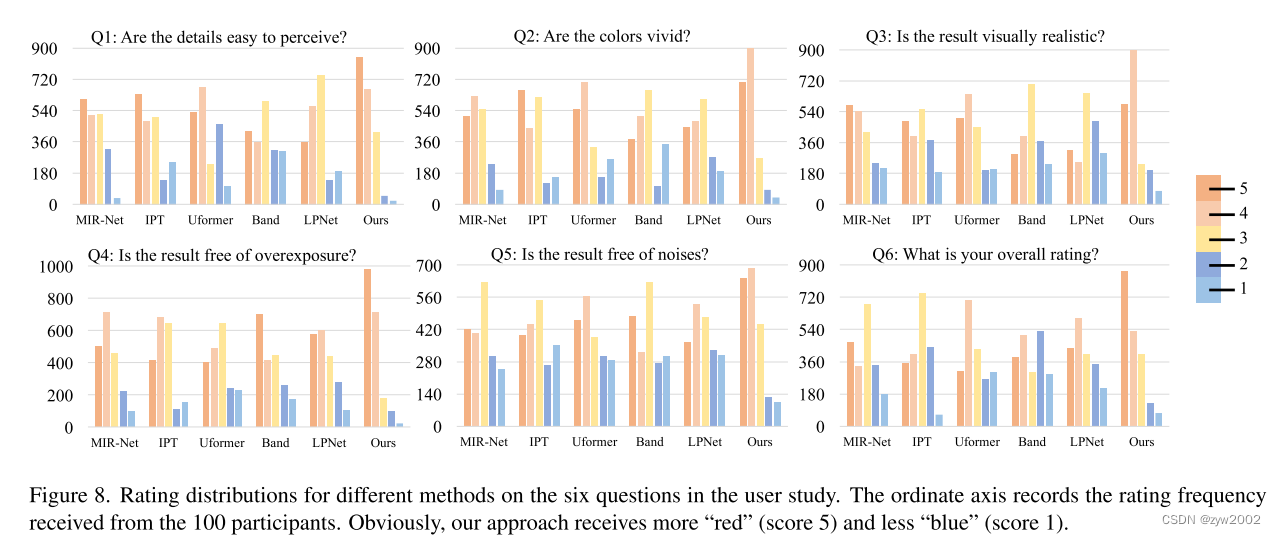
我们进一步对100名参与者进行了大规模的用户研究,以评估我们的方法和5个最强基线(通过SID、SMID和SDSD上的平均PSNR选择)对增强iPhone X或华为P30拍摄的弱光照片的人类感知。共在道路、公园、图书馆、学校、肖像等不同环境下拍摄了30张弱光照片,50%图像像素的强度低于30%。
在[40]中设置之后,我们使用Likert表(1(最差)到5(最好)),通过图8中所示的6个问题的用户评分来评估结果。所有方法都是在SDSD-outdoor上进行训练,因为[39]表明训练后的模型可以有效增强手机拍摄的弱光图像。图8显示了不同方法的评级分布,其中我们的方法得到的“红色”评级更多,“蓝色”评级更少。此外,我们使用配对t检验(使用MS Excel中的t检验函数)对我们的方法和其他方法之间的评级进行了统计分析。在0.001的显著水平下,所有的t检验结果都具有统计学意义,因为所有的pvalue都小于0.001。
4.3 Ablation Study
我们通过分别移除整体架构上的不同组件来考虑四种消融设置。
- “Our w/o L”删除了远程分支,所以框架只有卷积操作。
- “Our w/o S”删除了短程分支,保持了完整的远程分支和信噪比引导的注意力。
- “Ours w/o SA”进一步从“Ours w/o S”中删除了信噪比引导的注意,只保留了最深层的基本Transformer结构。
- “Ours w/o A”消除了信噪比引导的注意。
我们对所有7个数据集进行了消融研究。表5总结了结果。与所有消融设置相比,我们的全消融设置产生了最高的PSNR和SSIM。“Our w/o L”、“Our w/o S”和“Our w/o SA”显示了单独使用卷积运算或Transformer结构的缺点,从而显示了共同利用短程(卷积模型)和长程(Transformer结构)操作的有效性。结果还显示了“信噪比引导的注意力”(“Ours w/o A”vs.“Ours”)和“信噪比引导的融合”(“Ours w/o S”vs.“Ours”)的影响。

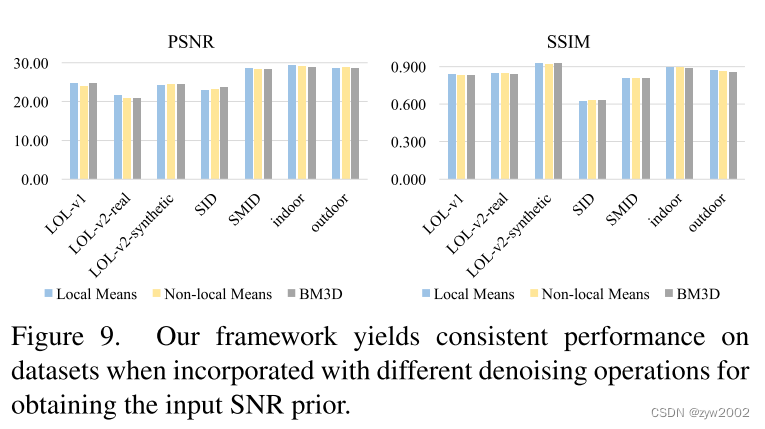
4.4. Influence of SNR Prior
我们框架的信噪比输入是通过对输入帧进行不基于学习的去噪操作获得的(式(2))。在所有的实验中,考虑到local means去噪速度快,我们都采用local means去噪。在本节中,我们将分析引入其他操作时的影响,包括non-local means[1]和BM3D[8]。结果如图9所示,表明我们的框架对获取信噪比输入的策略并不敏感。这些结果都优于基线的结果。
5. Conclusion
我们提出了一种新颖的信噪比感知框架,该框架共同利用short-range和long-range操作,以空间变化的方式动态增强像素。采用SNR prior对特征融合进行引导。SNR-aware Transformer采用了一个新的自注意模块。大量的实验,包括用户研究,表明我们的框架在使用相同的网络结构时,在有代表性的基准测试中始终保持最佳的性能。
我们未来的工作是探索其他semantics来增强空间变化机制。此外,我们计划通过同时考虑时间和空间变化的操作,将我们的方法扩展到处理弱光视频。另一个方向是探索微光图像中接近黑色区域的生成方法。