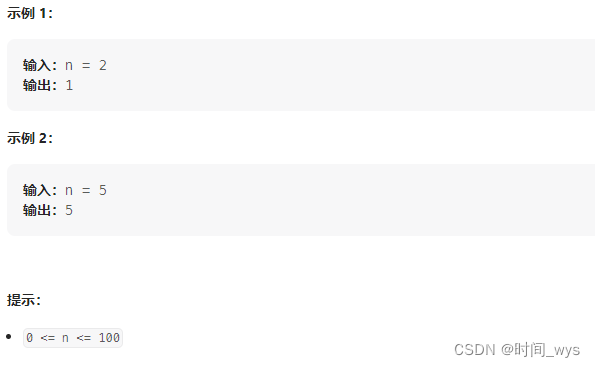
方向一:分享一道你收藏的好题
小雅兰刚学数据结构与算法的时候,学的真的是很吃力,感觉链表真的特别的难,在学习了后面的知识之后,发现链表慢慢变得简单了,若是放在现在,小雅兰仍然觉得链表的知识点以及OJ题是非常有意义的。
这是小雅兰写的和链表知识点有关的博客:单链表——“数据结构与算法”_认真学习的小雅兰.的博客-CSDN博客
双链表——“数据结构与算法”_认真学习的小雅兰.的博客-CSDN博客
顺序表(更新版)——“数据结构与算法”_认真学习的小雅兰.的博客-CSDN博客

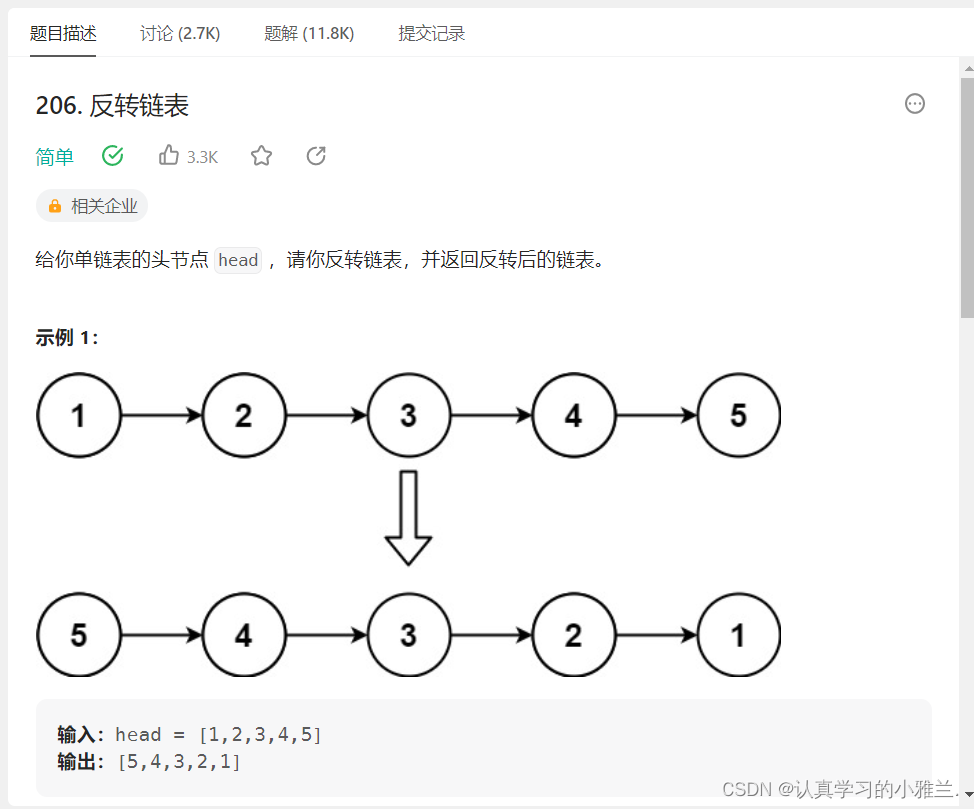
struct ListNode* reverseList(struct ListNode* head){ if(head==NULL) { return NULL; } struct ListNode*n1=NULL; struct ListNode*n2=head; struct ListNode*n3=n2->next; while(n2!=NULL) { n2->next=n1; //迭代 n1=n2; n2=n3; if(n3!=NULL) { n3=n3->next; } } return n1; }


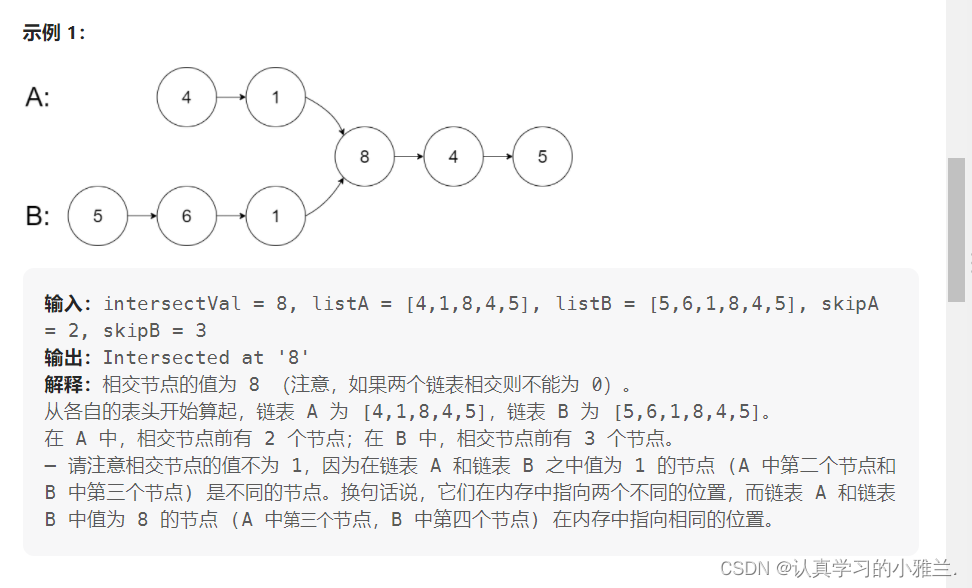




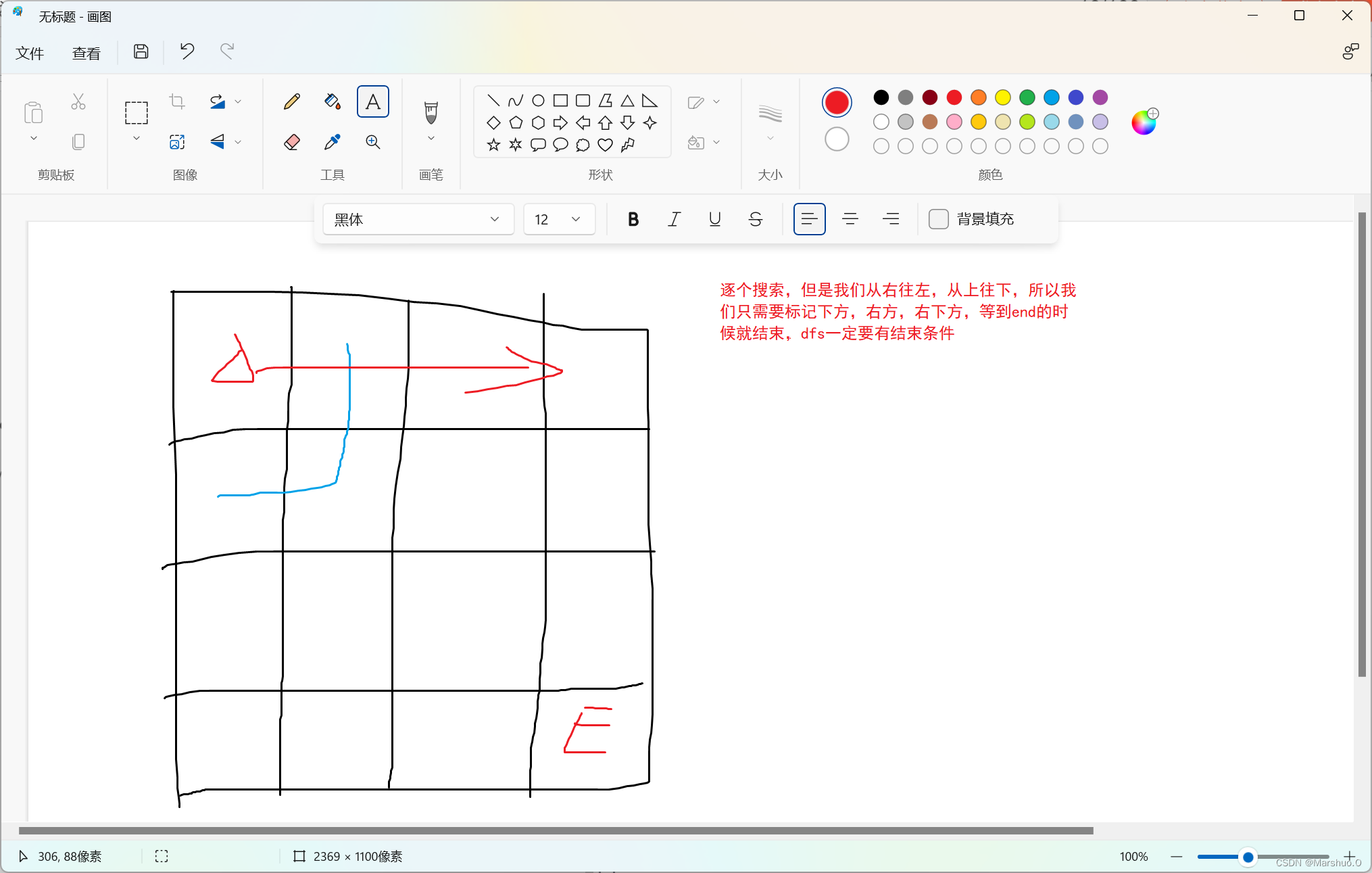
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { if (headA == NULL || headB == NULL) { return NULL; } struct ListNode *pA = headA, *pB = headB; while (pA != pB) { pA = pA == NULL ? headB : pA->next; pB = pB == NULL ? headA : pB->next; } return pA; }





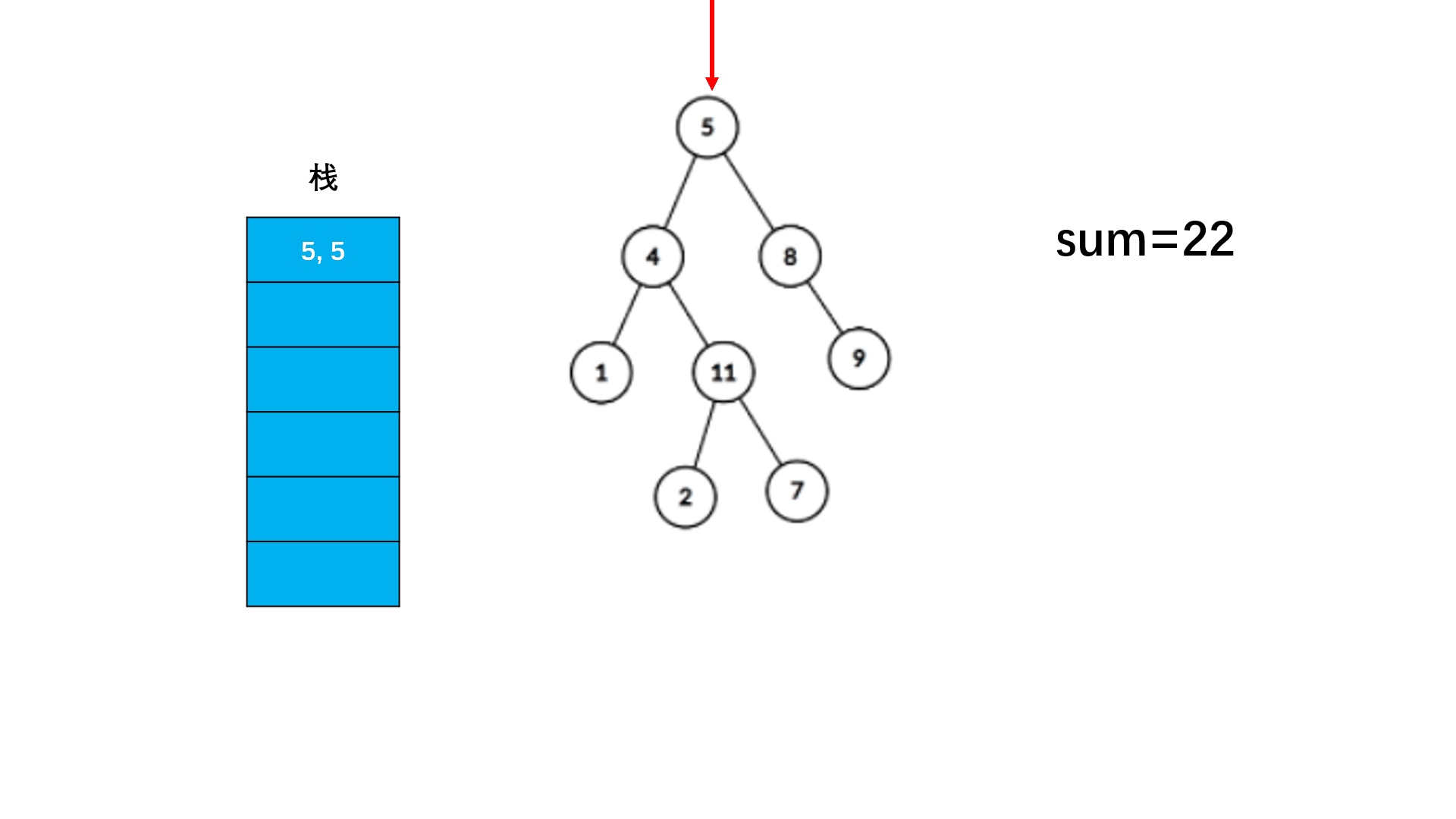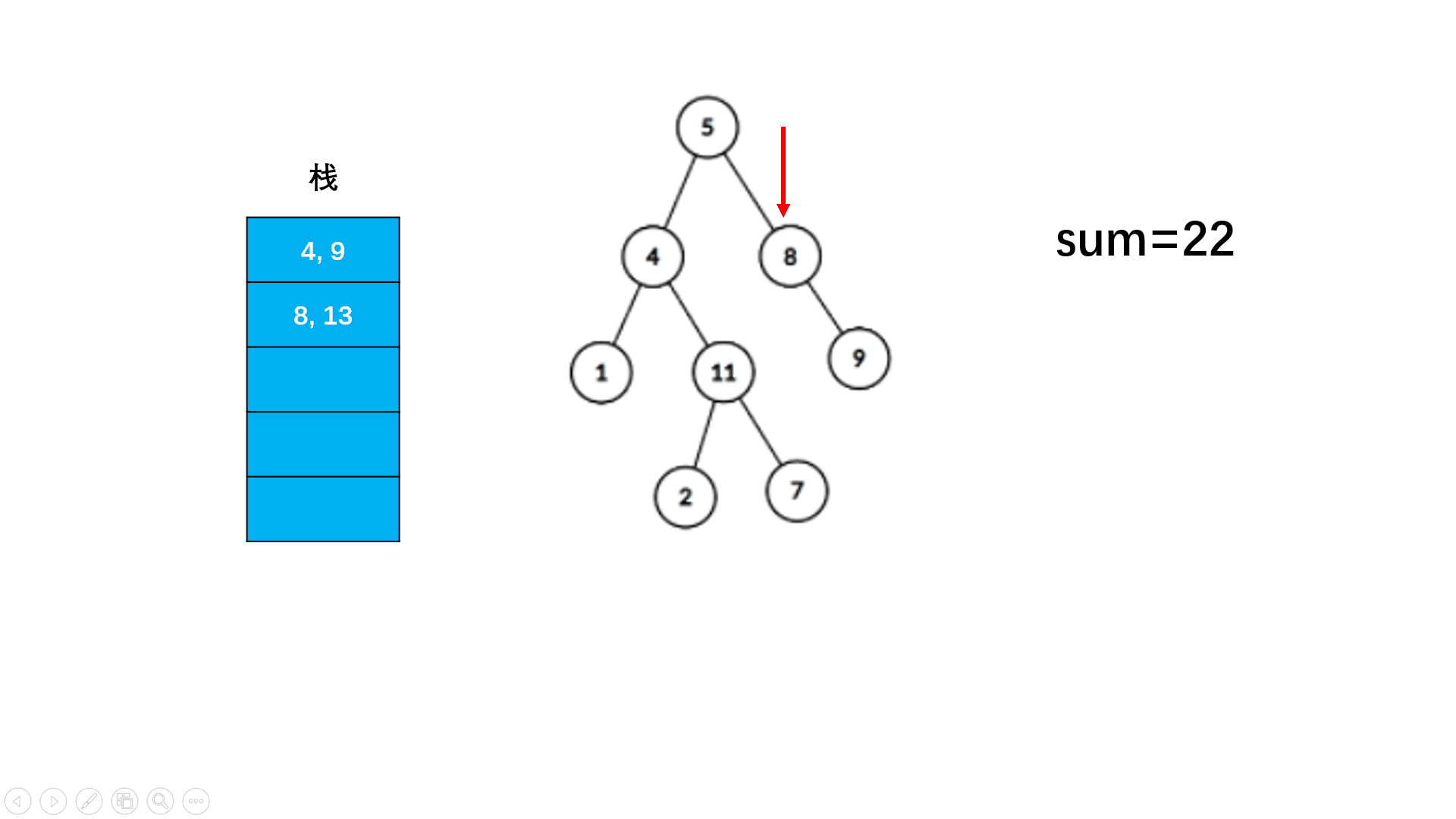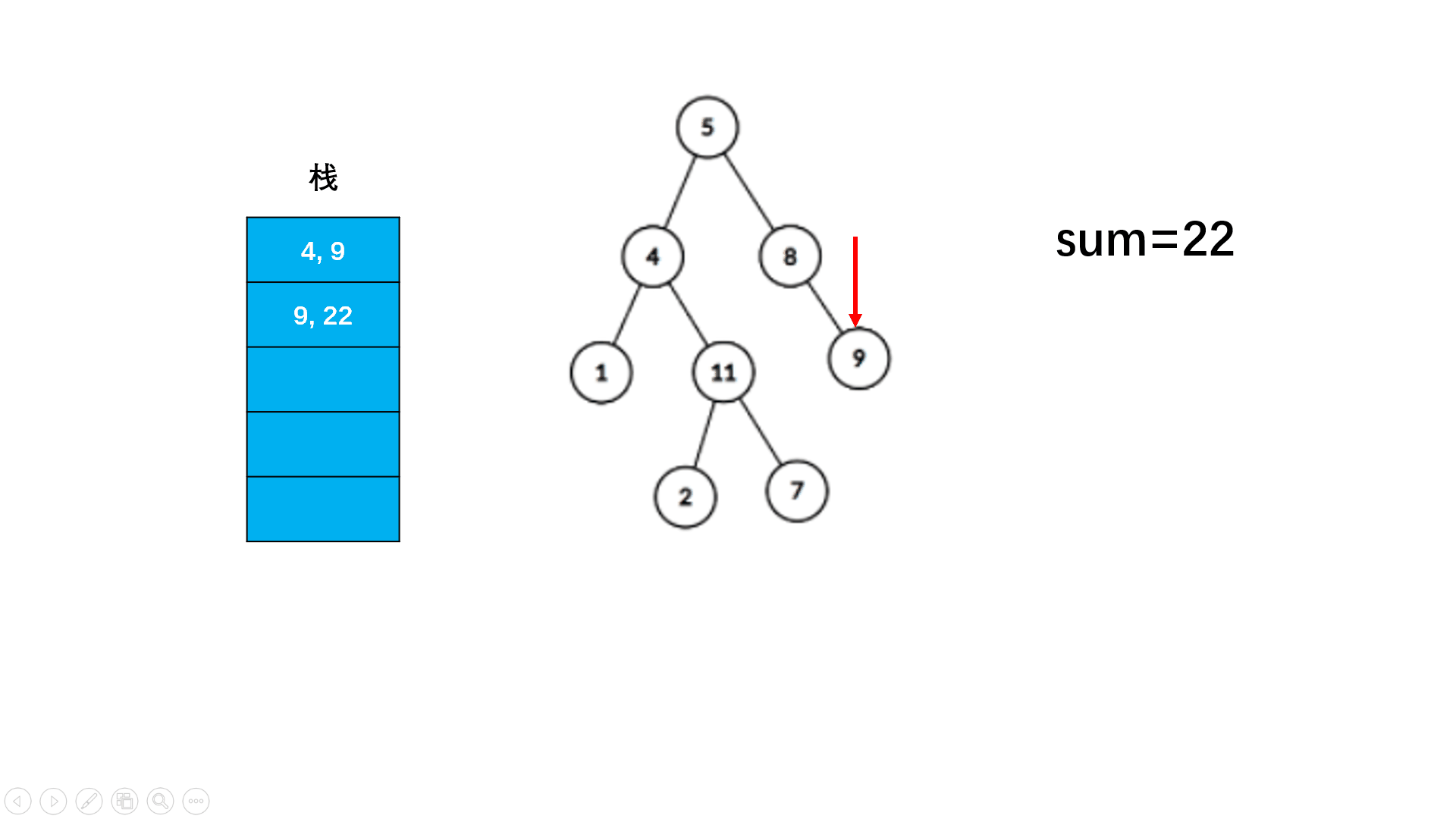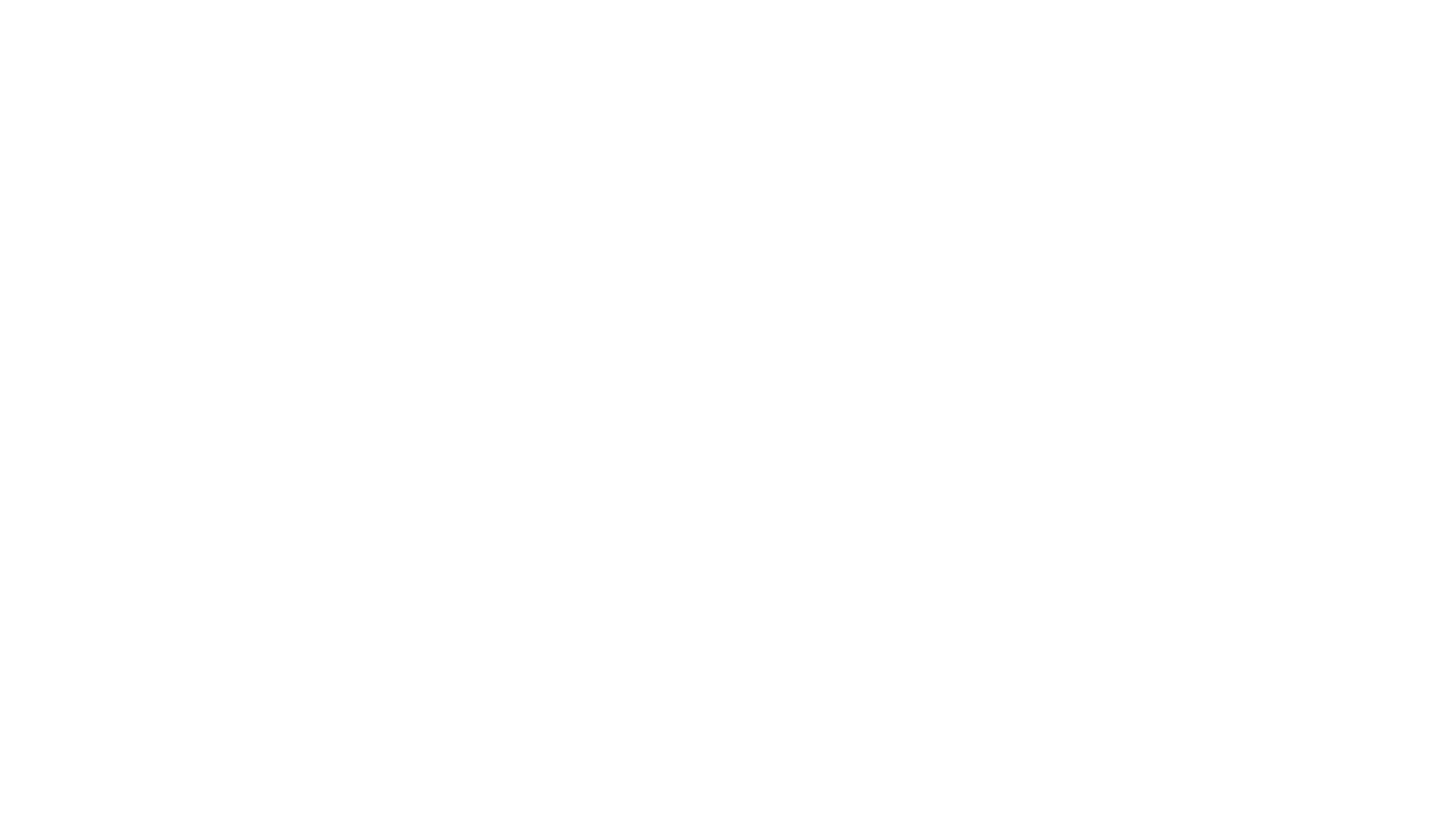
这个题目用到的主要思想就是快慢指针的思想!!!

bool hasCycle(struct ListNode* head) { if (head == NULL || head->next == NULL) { return false; } struct ListNode* slow = head; struct ListNode* fast = head->next; while (slow != fast) { if (fast == NULL || fast->next == NULL) { return false; } slow = slow->next; fast = fast->next->next; } return true; }

方向二:分享一个你收藏的便捷技巧
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。链表可以在多种编程语言中实现。像Lisp和Scheme这样的语言的内建数据类型中就包含了链表的存取和操作。程序语言或面向对象语言,如C,C++和Java依靠易变工具来生成链表。
线性表的链式存储表示的特点是用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。因此,为了表示每个数据元素 与其直接后继数据元素之间的逻辑关系,对数据元素来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。由这两部分信息组成一个"结点",表示线性表中一个数据元素。线性表的链式存储表示,有一个缺点就是要找一个数,必须要从头开始找起,十分麻烦。
根据情况,也可以自己设计链表的其它扩展。但是一般不会在边上附加数据,因为链表的点和边基本上是一一对应的(除了第一个或者最后一个节点,但是也不会产生特殊情况)。不过有一个特例是如果链表支持在链表的一段中把前和后指针反向,反向标记加在边上可能会更方便。
对于非线性的链表,可以参见相关的其他数据结构,例如树、图。另外有一种基于多个线性链表的数据结构:跳表,插入、删除和查找等基本操作的速度可以达到O(nlogn),和平衡二叉树一样。
其中存储数据元素信息的域称作数据域(设域名为data),存储直接后继存储位置的域称为指针域(设域名为next)。指针域中存储的信息又称做指针或链。
由分别表示,,…,的N 个结点依次相链构成的链表,称为线性表的链式存储表示,由于此类链表的每个结点中只包含一个指针域,故又称单链表或线性链表。
从结构上进行区分,链表可以分为:单向链表(Singly Linked)、双向链表(Doubly Linked List)和循环链表(Circular List),在一些资料里还会有块状链表或者多重链表(Multiply Linked List),绝大对数情况下,我们只会用到下面三种链表。
单向链表(Singly Linked)
单向链表的存储结构比较简单,在存储上,它能够用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。每个元素包含两个域,其中存储数据元素信息的域称为数据域;存储直接后继存储位置的域称为指针域。指针域中存储的信息称作指针或链。如下图,链接指向列表中下一个节点,而最后一个节点则指向一个空值。
双向链表(Doubly Linked List)
双向链表的存储结构相对于单向链表更加复杂。在双向链表中,每个节点中有两个指针域,一个指向直接后继,另一个指向直接前驱,当连接为最后一个连接时,指向空值或者空列表。如下图:
循环链表(Circular List)
循环链表是另一种形式的链式存储结构。其特点是表中最后一个节点的指针域指向头节点,整个链表形成一个环。由此,从表中任意节点出发均可找到表中其他节点,如下图:
类似的,双向链表也可以构建循环链表。循环链表有两个特点,第一,链表中没有 NULL 指针;第二,链表无须增加存储量。



- 存储单元可以是连续的,也可以是不连续的
- 每个节点包含两部分,分别为数据元素域和指针域
- 节点和节点之间通过指针域进行连接
方向三:积灰这么久,这个当时被你收藏的东西对现在的你还有用吗?
链表的用途
- 实现文件系统:链表可以被用来实现文件系统中的文件目录结构,每个节点可以表示一个文件或者一个目录,而整个文件系统可以看做一个包含多个节点的链表结构。
- 排序:链表可以用于实现排序算法,例如归并排序和快速排序。这些算法通常需要在运行时动态创建和删除节点,这正是链表的长处。
- 管理动态数据:链表是一种动态数据结构,可以自由添加和删除节点,因此它经常用于管理动态大小的数据集合,例如文件系统、操作系统内存管理和网络协议。
- 存储稀疏数据:链表也可用于存储稀疏数据结构,例如稀疏矩阵。由于链表可以有效地管理和存储无序的数据集合,因此它是一种有效的方法来存储稀疏数据。
- 实现各种数据结构:表通常用于实现其他高效的数据结构,例如队列、栈和哈希表。链表提供了高效的插入和删除操作,可以在 O(1) 的时间内执行,而数组等其他数据结构需要进行大量的数据搬迁。
可用链表实现的数据结构:
- 线性数据结构:链表可以用来实现栈、队列、链式队列等线性数据结构,而且基于链表实现的栈和队列可以动态增长,比基于数组的实现更灵活。
- 哈希表:哈希表使用链表可以解决哈希碰撞(Hash Collision)的问题,链表可以用来构成哈希桶,当出现哈希碰撞时将冲突的数据添加到链表的末尾。
- 图和树:链表可以用来描述和实现复杂的图和树数据结构,每个节点可以使用链表来存储子节点或相邻的节点。
- 实现高效的内存分配器:链表可以被用来实现文件系统中的文件目录结构,每个节点可以表示一个文件或者一个目录,而整个文件系统可以看做一个包含多个节点的链表结构。
链表主要是便于管理长度或数量不确定的数据,相对于数组,链表处理这种数据时比较节省内存。动态语言通常不大需要链表,因为动态语言的解释器帮你管理内存,但当你对空间效率或插入动作的效率有特殊要求时也可在动态语言中使用链表。
链表常用于在程序中临时存储一组不定长的线性数据。
具有这样的特点的数据可以用链表来保存:
1,数据是逐渐增加的
2,数据是不定长的,在存储第一个数据之前难以确定一个将来一共需要存储多少数据的上限,或者虽然可以确定上限,但这个上限又比通常大部分情况下数据可能达到的长度要大得多,因而一次性按照上限把空间分配好是不划算的。而链表则可以在每次需要增加新数据时才为之申请内存,不会造成浪费,也不会因一次申请不足而使数据的数量受到限制。
3,不需要按照序号对数据进行随机访问。
C++ STL 中提供了list容器,就是链表。同时STL还提供了vector容器,也可以用于处理具有上述特点的数据,而且vector还支持随机访问(即可以不考虑上述第3点要求)。但vector在增加数据时,如果原先分配的连续内存已经用完则需要重新分配内存并把原有数据复制过去,这时它的插入数据的动作时间复杂度就不是O(1)了(不是常量时间了)。因而,链表适于处理的数据除了具有上述特点外,如果还有如下第4点特征,则以链表为最佳选择了:
4,希望每次添加数据、删除数据的动作的时间复杂度都是O(1)的(常量时间)。
好啦,小雅兰今天的分享就到这里啦,还要继续加油噢!!!