排序01-多目标模型
这节课的内容是推荐系统排序的多目标模型。这节课的内容分两部分。
- 第一部分是模型结构。模型把用户特征、物品特征、统计特征、场景特征作为输入,输出对多个指标的预估。
- 第二部分内容是降采样和校准。在实际的推荐系统中,正负样本的比例严重不平衡,负样本数量远多于正样本,因此需要对负样本做降采样。以点击率为例,对负样本做降采样会导致模型高估点击率,因此需要用公式做校准。
排序01:多目标模型_哔哩哔哩_bilibili
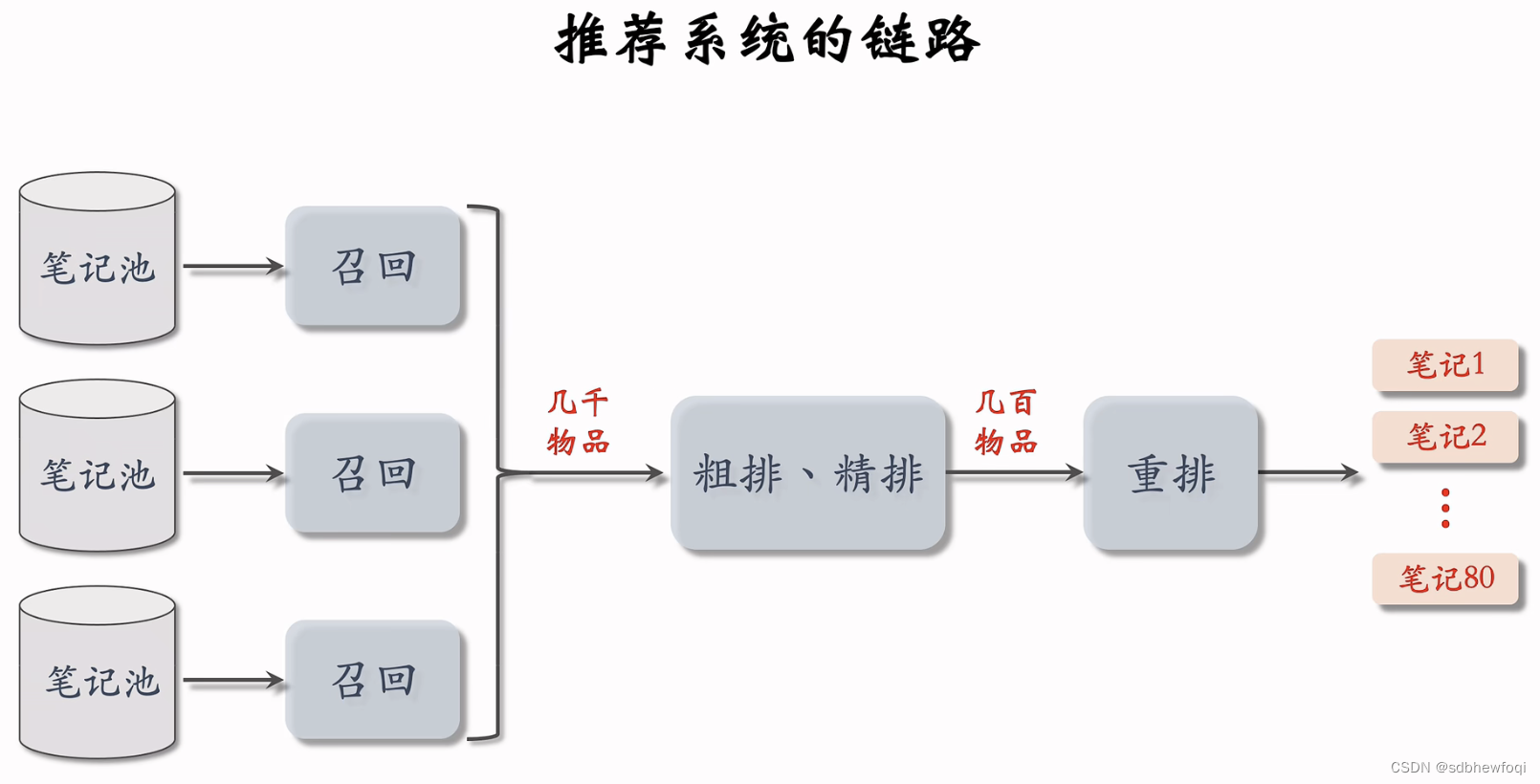
多条召回通道从几亿篇选出几千篇,粗排给召回的笔记逐一打分,保留几百篇。精排再打分,不做截断,带着分数进入重排。重拍做多样性抽样,并将相似内容打散,最终有几十篇笔记被选中展示给用户。

排序的主要依据是用户对笔记的兴趣,兴趣反应在交互上。
曝光次数:一篇笔记被展示给多少用户。曝光之后才会有点击等行为。

可以用点击率等消费指标衡量一篇笔记受欢迎的程度。点击率差不多有百分之一二十。
转发远远少于点赞和收藏,但是转发很重要,转发到 wx 等平台可以给xhs 吸引到外部的流量。

在把笔记展示给用户之前,需要提前预估用户对笔记的兴趣,可以预估多项,然后再融合。
最简单的公式是加权和。比如点击率的权重是1,点赞率收藏率转发率等的权重都是2。权重是做 ABTEST 调出来的。

现在工业界基本都用多目标模型。排序模型的输入是各种特征。
- 用户特征:主要用户 id 和用户画像;
- 物品特征:物品 id、物品画像、作者信息、
- 统计特征:用户统计特征、物品统计特征、比如用户在过去30天中一共曝光、点击、点赞、转发了多少篇笔记;再比如候选物品,在过去30天内一共获得了多少次曝光机会,获得了多少次点击、点赞。
- 场景特征:是随着用户请求传过来的,包含当前时间、用户所在地点。 比方说,候选物品和用户在同一个城市,那么用户对物品有更高的兴趣。是否是周末、节假日也会影响用户的兴趣。
NN 输出一个向量,这个向量再输入4个神经网络,每个神经网络有2-3个 FC,最后一个激活函数是 sigmoid。4个NN 分别输出点击率、点赞率、收藏率、转发率的预估值。4个预估值介于0-1之间。反映出用户对物品的兴趣。
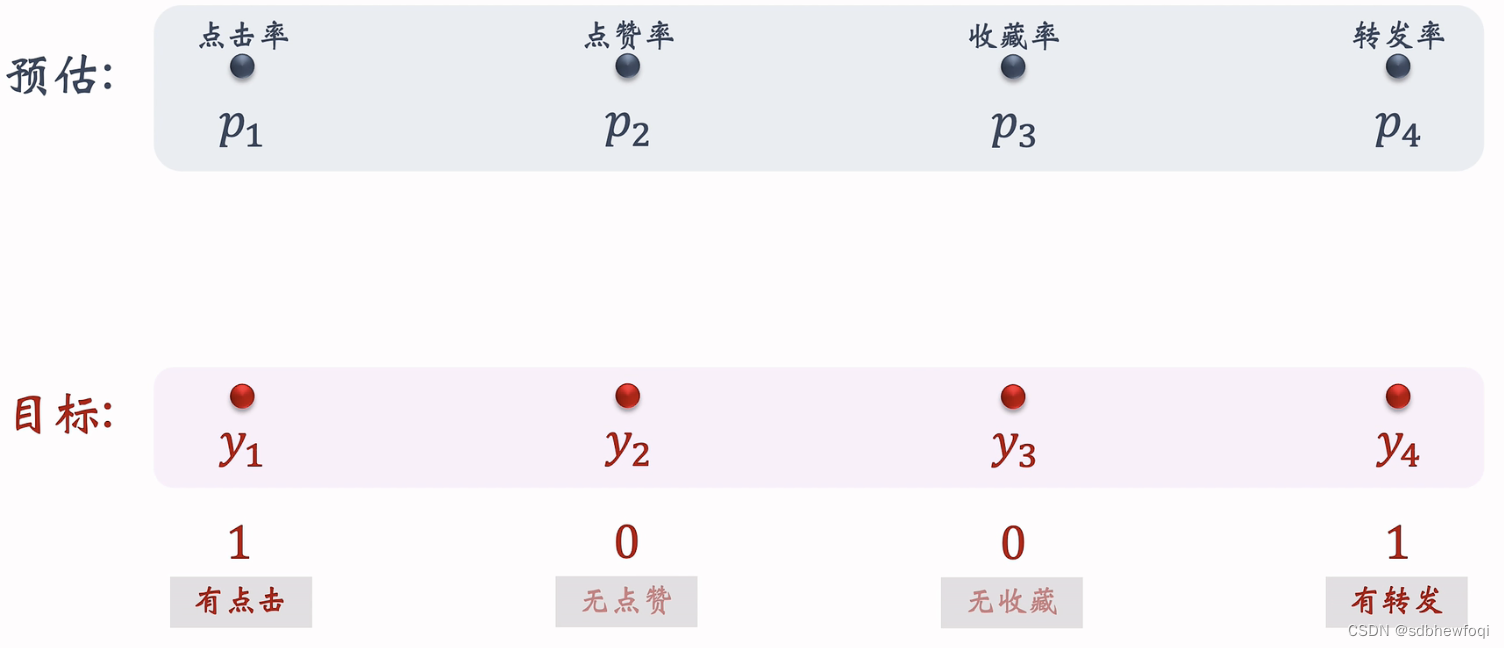

模型的训练:预估值 p1p2p3p4去拟合真实的目标y1y2y3y4,y要么是0,要么是1。
训练是要鼓励模型的预测接近目标,是二元分类,判定用户是否会点击物品。有4个任务,每个任务都是一个二元分类,用交叉熵loss。
p1越接近y1,loss越小。4个损失函数的加权和作为总的损失函数。权重 a是根据经验设置的。在收集的历史数据上训练nn的参数,最小化损失函数。
损失函数越小说明模型的预测越接近真实目标,训练的时候把损失函数关于神经网络的参数求梯度,做梯度下降更新神经网络的参数。

训练的时候实际有很多困难,重点讲其中一个。
类别不平衡:正样本少(有点击),负样本多(没有点击)。
要太多负样本用处不大,白浪费计算资源。
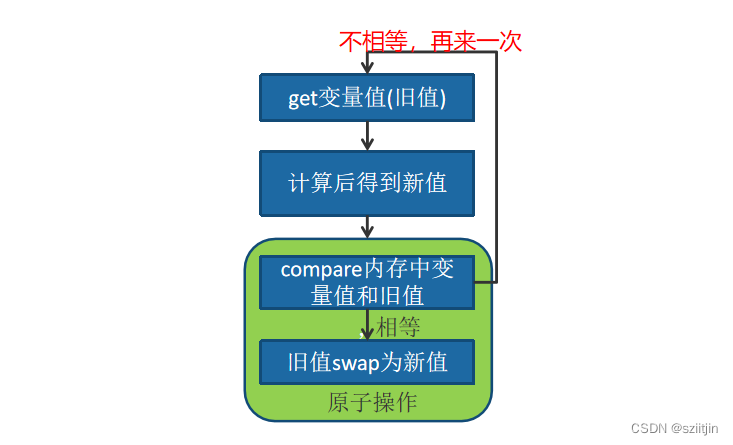
解决方法:负样本的随机降采样。负样本过多,不用全部的负样本,只用一小部分负样本。
减少样本数量,降低训练的计算代价。例如原本一天积累的数据需要在集群上训练10h,降采样之后负样本的数量减少了很多,训练只需3h。
预估值校准

预估值校准
给定用户特征、物品特征。用 nn 预估出分数,分数需要做校准才能把预估值用于排序。
为什么要校准??
以点击为例,负样本(曝光之后没有点击)的样本远远大于正样本,降采样让正负样本差距不悬殊,采样率为 a。
a越小,负样本越少,模型对点击率的高估就会越严重。

推导校准公式,对预估的点击率做校准。
样本总数 n_+ n_-,上面两个公式消掉 n+和 n_。
用校准后的分数作为排序的依据。
说说为什么要做校准吧。如果纯优化点击的话,降采样后的各个物品ctr相对顺序是不变的,不做校准也可以。校准一般是针对广告系统,ctr需要参与广告计费的计算,所以需要精确值。而校准有两部分,一是模型端降采样后的校准,如视频里说明。二是后链路根据实际CTR校准,如插值保序回归等。

如果是单一目标,确实不用校准。如果是多个目标,而且需要相乘,那么就应该校准。
弹幕:比较准有什么关系吗?反正排序衡量的是相对排名,不校准的顺序也是对的
弹幕:只关注排序也需要校准?对于批训练来说,每次训练的正负样本分布不一样,就会导致排序结果不能对齐?
排序02-MMOE
Multi-gate Mixture-of-Experts (MMoE) 是一种多目标排序模型。MMoE 用多个独立的塔提取特征,并对多塔提取的特征向量做加权平均,然后送入多头。
MMoE 的训练容易出现极化现象(polarize),可以用 dropout 解决。
排序02:Multi-gate Mixture-of-Experts (MMoE)_哔哩哔哩_bilibili
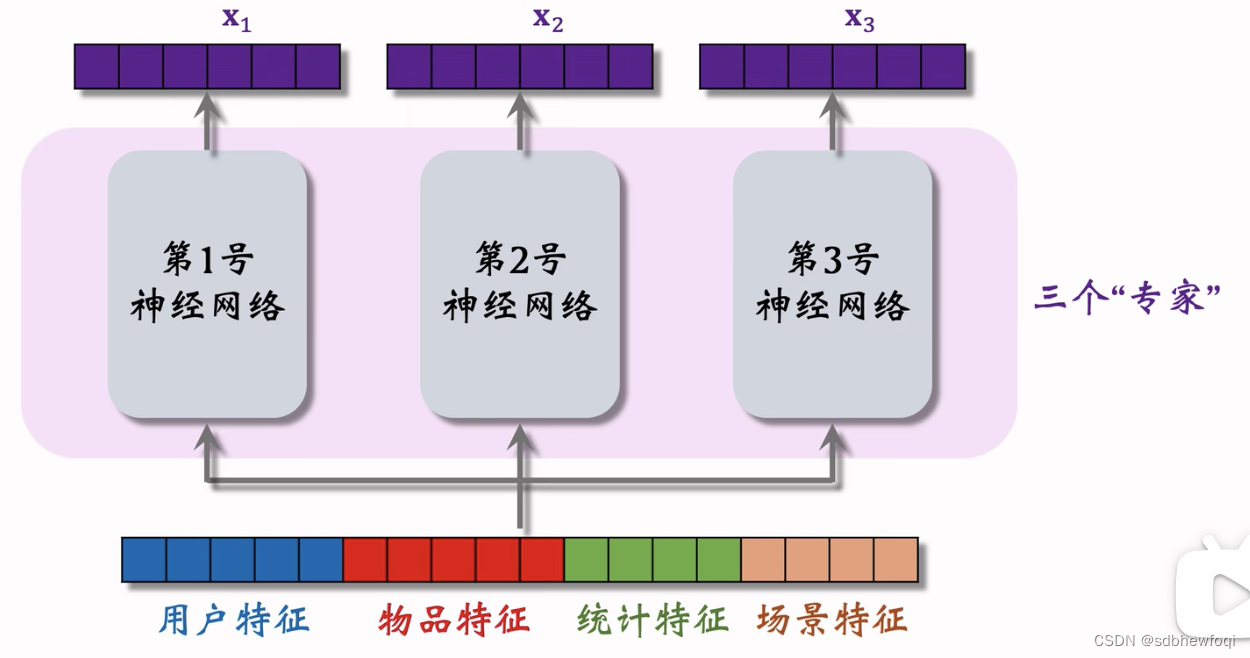

模型输入是向量,向量输入3个 nn,3个nn(专家)的结构相同但不共享参数。3个 nn 各输出一个向量x1,x2,x3。3个 nn 被叫做专家。
把下面的特征向量输入另一个神经网络,最后接一个 softmax,输出3个概率值 p1p2p3,对应3个 nn,作为3个专家的权重,对 x1x2x3做加权平均。
q1q2q3也是加权平均的权重。(预估几个任务就有几组权重)该例子里假设只预估点击率、点赞率两个指标,只有 p\q 两组权重。如果有10个目标就要有10组权重。
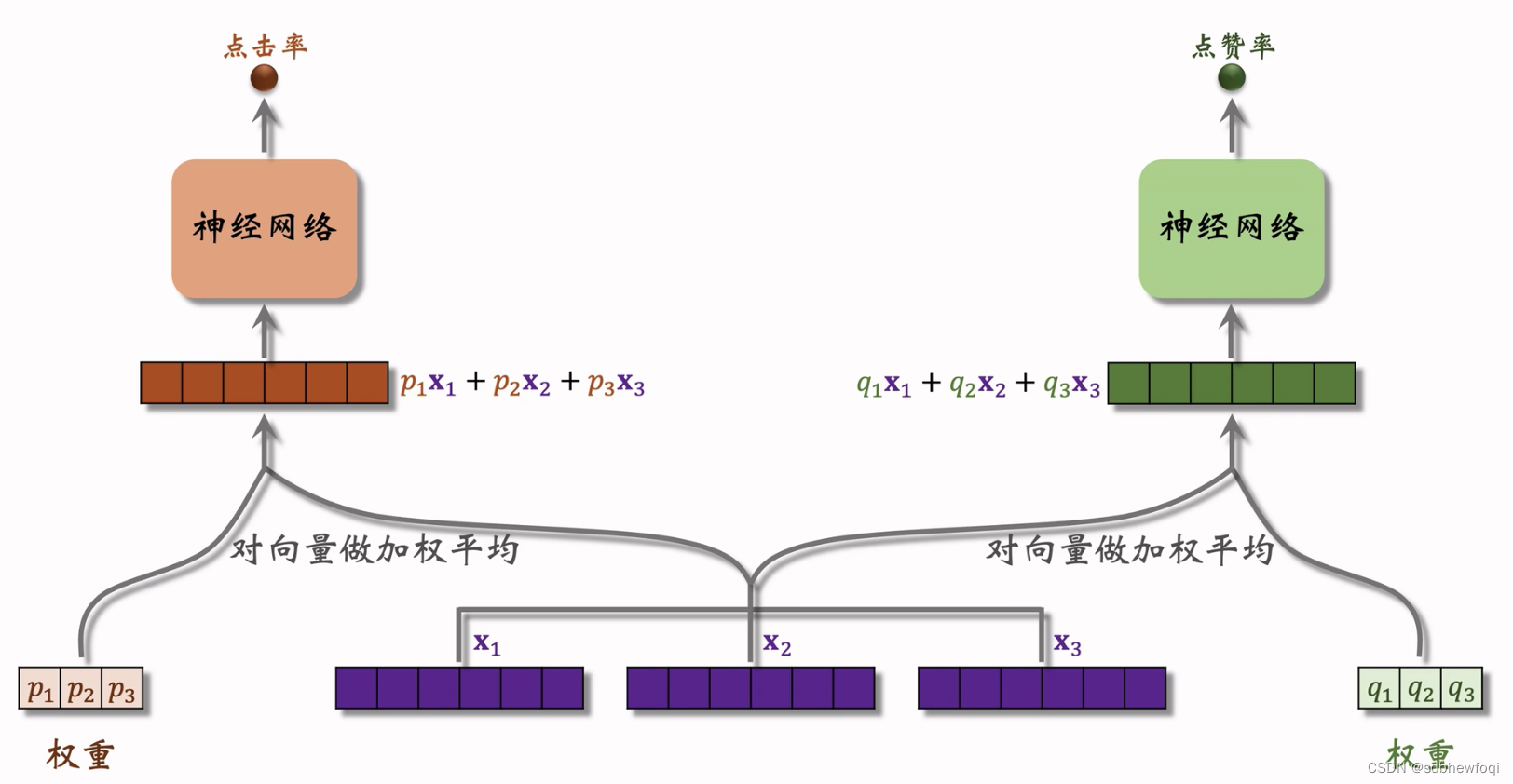
总结:对 nn 输出的向量x1,x2,x3做加权平均,使用加权平均得到的向量去预估某个业务指标。专家网络的数量是参数,需要手动调,例如4or8个。
极化
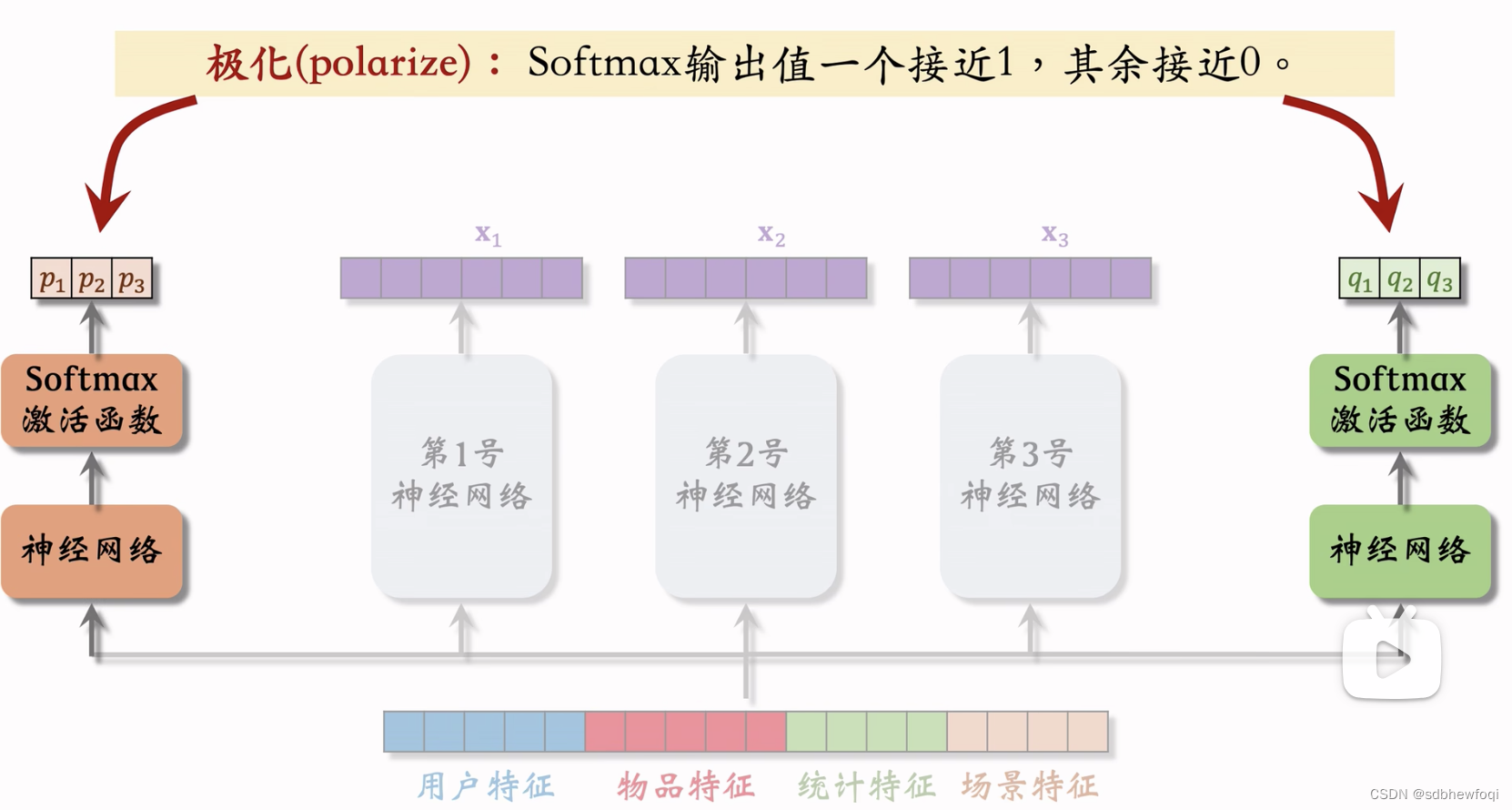
mmoe 在实践中有个问题,softmax 会发生极化。
极化现象:softmax 输出值一个接近1,其余接近0。例如只有 p1接近1,p2p3都接近0。
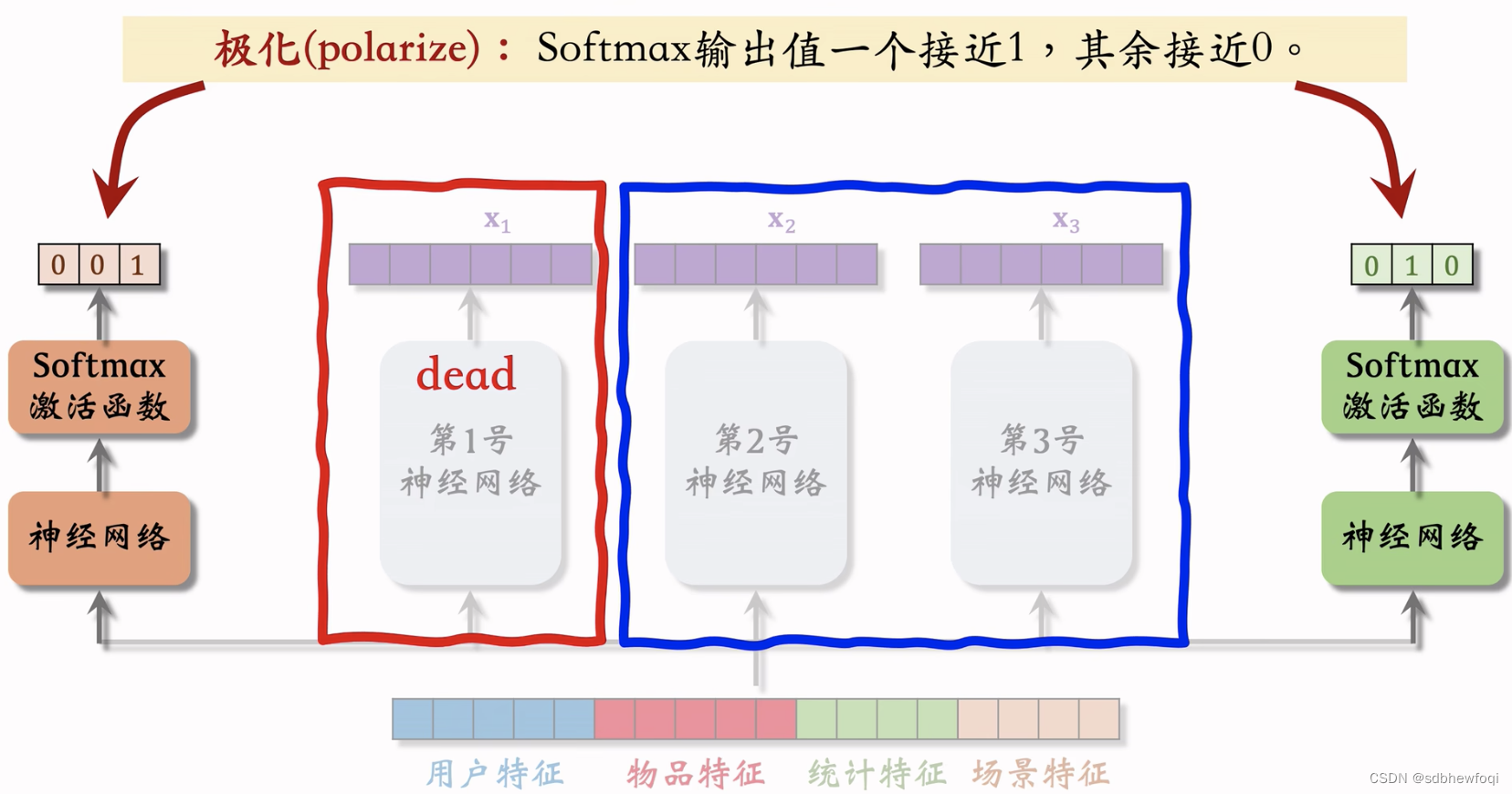
假如p1p2p3为001,那么预估点击率任务只使用了第3号神经网络。另外两个没用,等于没用 MMOE,不会对专家做融合。

dropout 强迫每个任务根据部分专家做预测,如果用 dropout 不太可能会发生极化,否则预测结果会非常差。
假如发生极化,softmax 输出的某项接近1,万一这个元素被 mask预测的结果肯定会非常离谱。为了让预测尽量精准,神经网络会尽量避免极化的发生,softmax 输出的某项接近1。
使用 dropout 基本能避免极化。

用了 MMOE 也不一定有效果。
排序03-预估分数融合
排序的多目标模型会预估点击率、点赞率等指标。得到这些指标之后,需要将它们融合成一个分数。这节课介绍工业界常用的几种融分公式。
排序03:预估分数融合_哔哩哔哩_bilibili

plike点赞率,pcollect 收藏率。
下面的公式有实际意义,pclick*plike=曝光之后用户点赞的概率

ptime:预估短视频的观看时长,比如预测用户会观看10s
w1,a1都是超参数需要线上 ab手动调整。
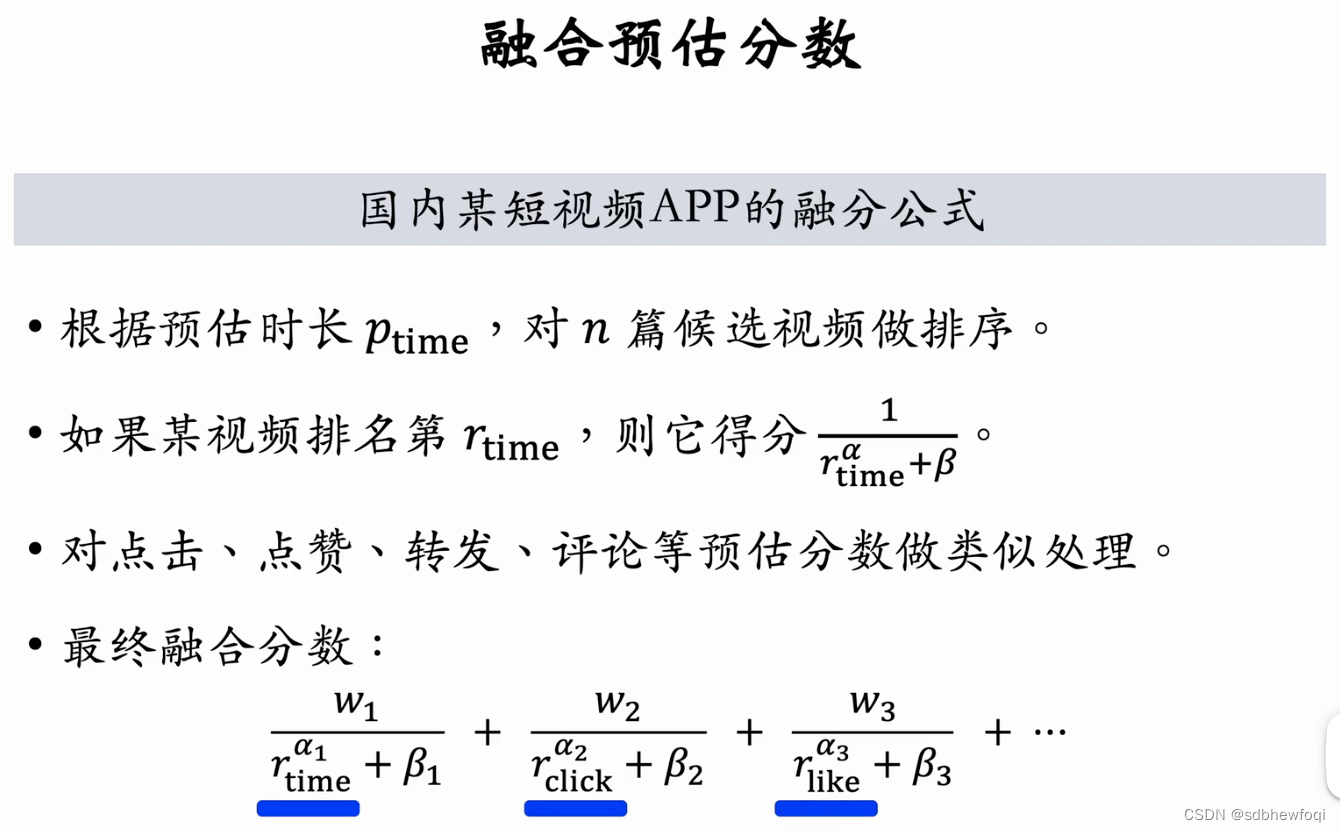
快手融合公式。预估的播放时长越长,r_time 越小,得分越高。则短视频越靠前。
不是直接用预估的分数,而是使用每个分数的排名。
计算维度是某一篇笔记的播放排名、点击排名、点赞排名。
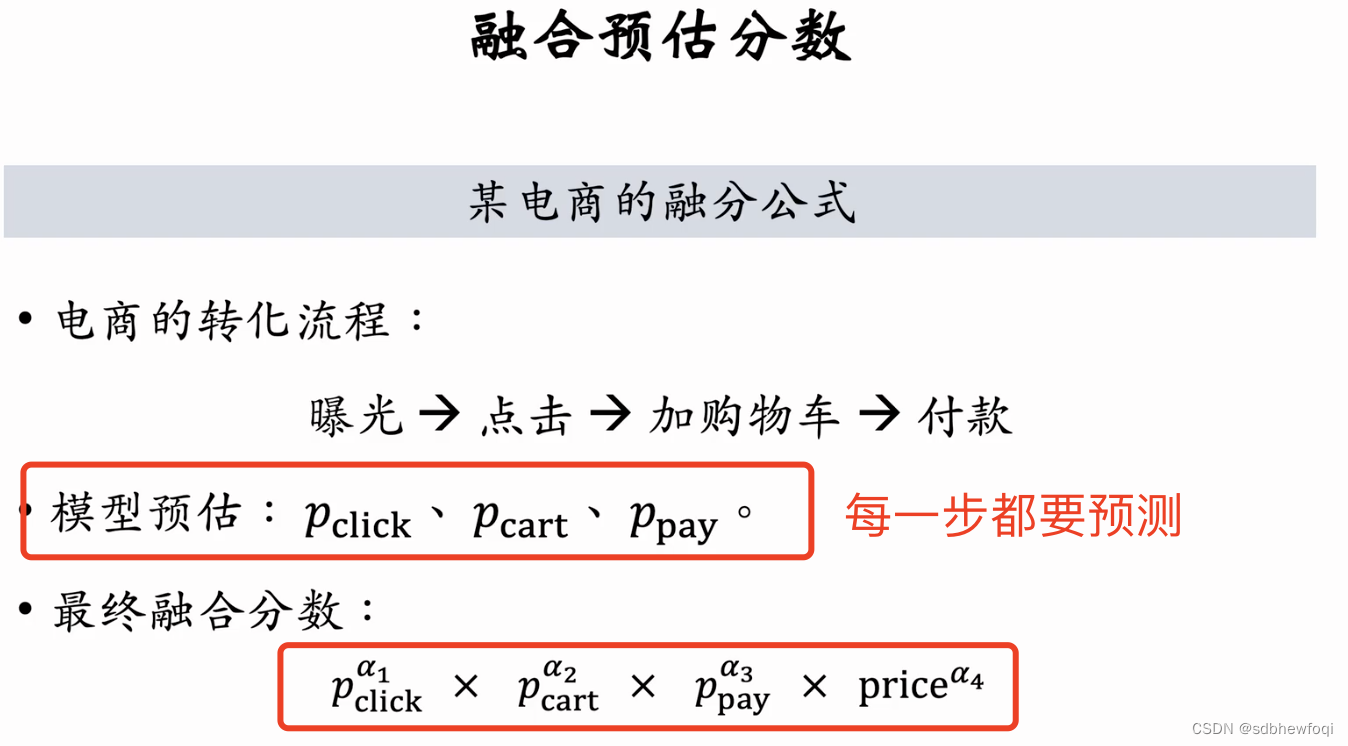
假如a1,a2,a3,a4都是1,公式有实际意义就是电商的营收。

排序04-视频播放建模
视频播放的建模主要有两个目标:视频播放时长、视频完播率。这节课讨论如何在多目标排序模型添加与播放时长、完播率相关的预估任务。
排序04:视频播放建模_哔哩哔哩_bilibili(评论也能学到很多)
视频播放时长建模

对于视频网站时长和完播才是最主要的指标,其次才是点击和交互。 如果一个用户把视频看完即使没有收藏转发也能说明用户对视频感兴趣。
播放时长是连续变量,自然想到用回归来拟合播放时长。但用回归的话效果不好。 对视频播放时长建模效果最好的是这篇 youtube 论文。
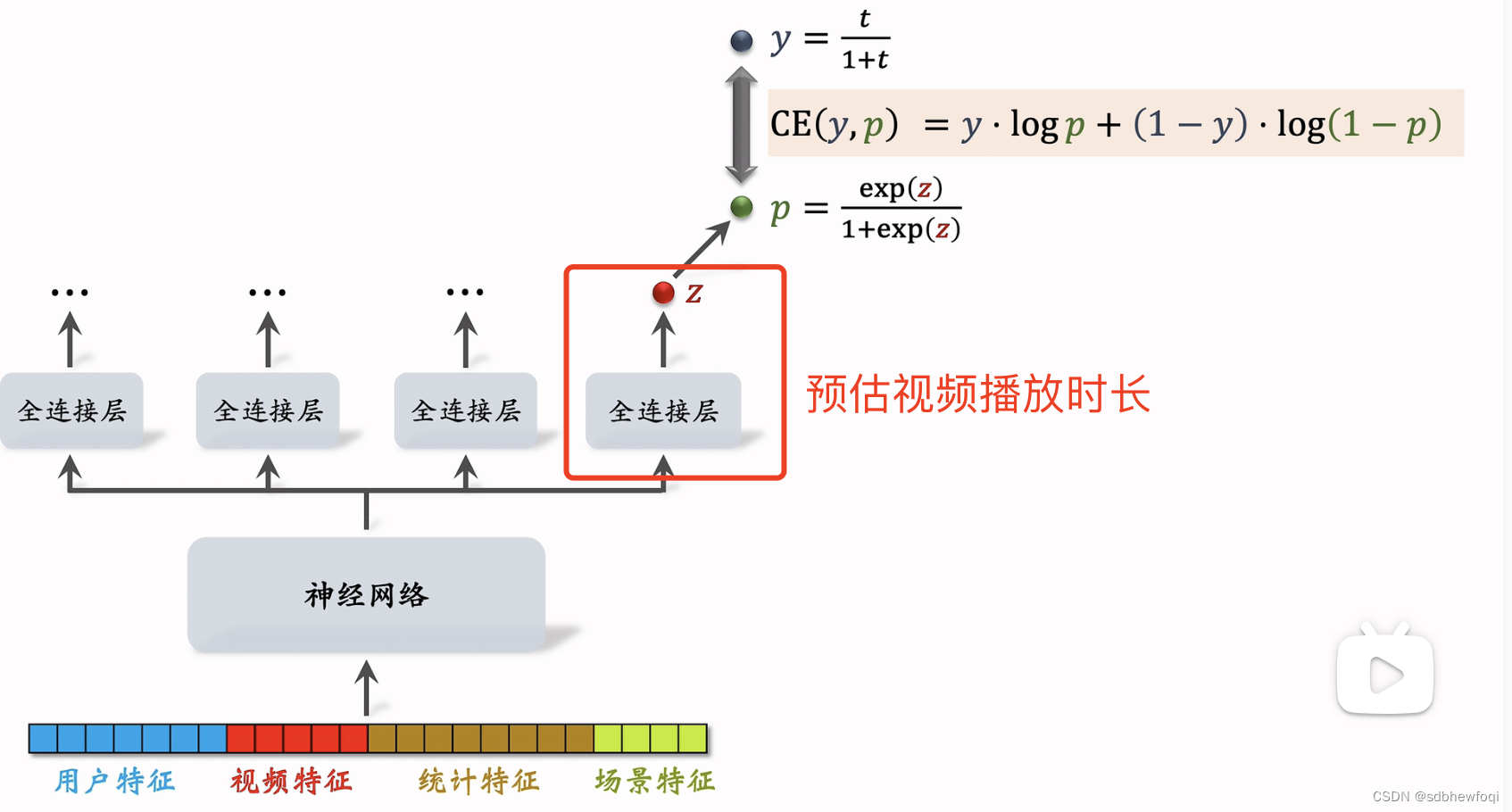
神经网络是 share bottom的,被所有任务共享。
z 是被预估的实数,z 做sigmoid变换得到 p, 让 p 拟合 y,y 是我们自己定义的,等于 t/(1+t),t 是用户实际观看视频的时长,t 越大则 y 越大。
使用 y 和 p 的交叉熵作为损失函数,最小化交叉熵让p 接近 y。
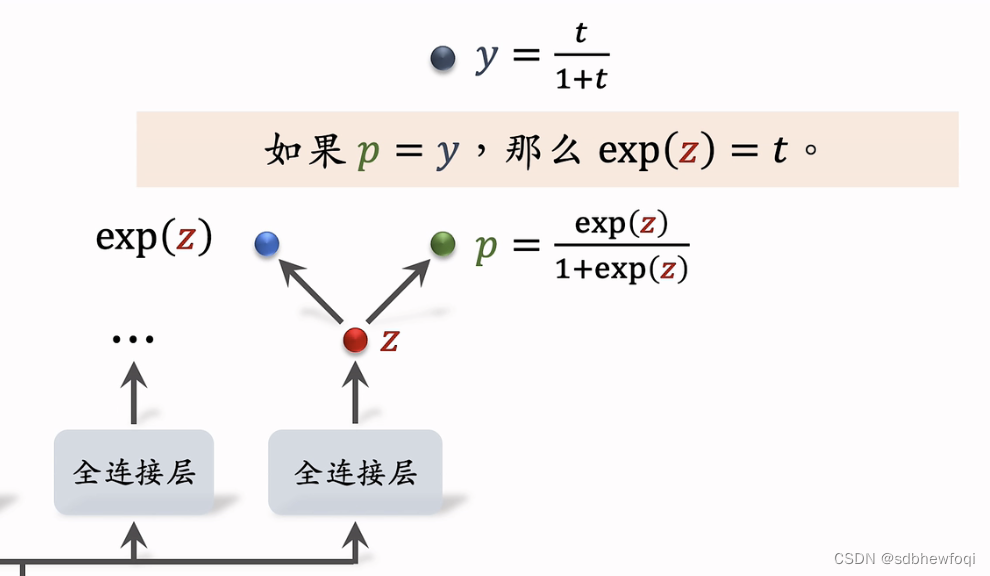
在线推理可以使用 exp(z) 作为播放时长的预估。
在训练中要用 p,做完训练后 p 就没有用了。
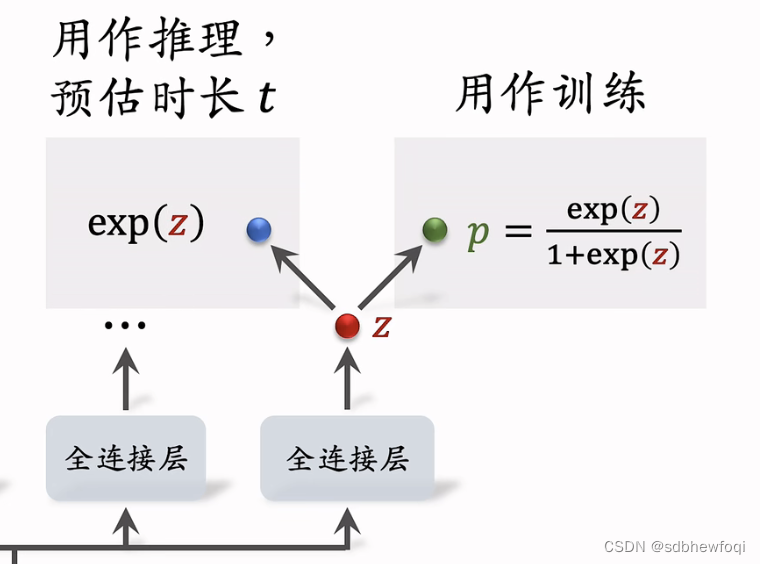

总结:
- z是实数可正可负
- t被记录在训练数据中。
- 分母1+t被去掉也没关系,相当于给损失函数做加权,权重是播放时长。

视频完播率建模
视频完播可以用回归建模,也可以使用二元分类建模。

y属于0-1之间
预估出的完播率作为融分公式的一项,影响视频的排序。
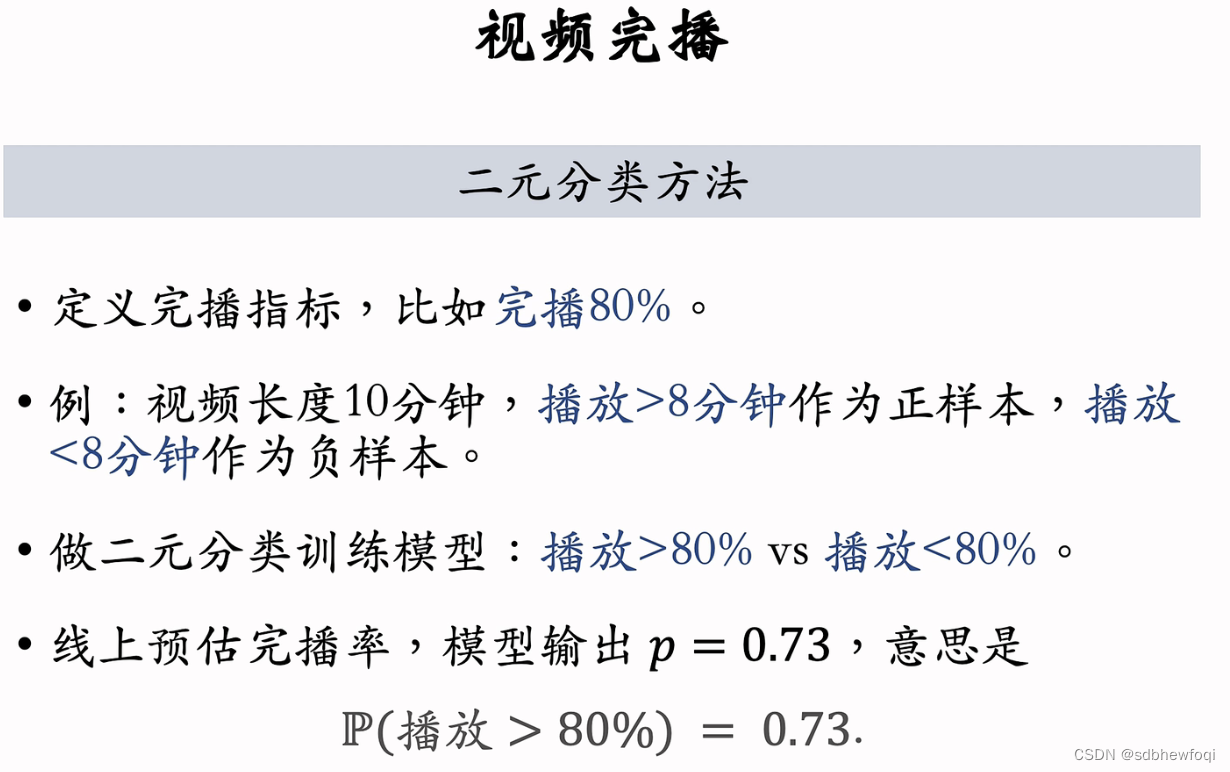
二元分类需要算法工程师自己定义完播指标,比如完播80%。
播放>80%是正样本,播放<80%是负样本。
线上预估时,模型输出 p=0.73,意思是视频播放超过80%的概率是0.73。


不能直接将完播率融合到分数里。视频越长完播率越低。直接用对长视频不公平。
需要拟合一个 f(),用于调整完播率。f是视频长度的函数,视频越长函数值 f 越小。pfinish才是对长短视频公平的,pfinish 作为融分公式的一项。
排序05-排序模型的特征
推荐系统中的排序模型需要用户画像、物品画像、统计特征、场景特征。这节课详细讲解这几类特征,以及系统的工程架构。
排序05:排序模型的特征_哔哩哔哩_bilibili

用户属性记录在用户画像中,用户 id 本身不携带任何信息,但是模型学到的 id emb 向量对召回和排序有很重要的影响。通常32d,64d
新用户、老用户和高活低活用户的行为区别很大。模型需要专门针对新用户和低活用户做优化。

- 物品 id emb在召回和排序中重要性很高。
- 在 xhs 中,一篇笔记发布的时间越久,价值就越低。电商打折等强时效话题热度只有几天。
- 笔记定位 geohash、城市对召回和排序有用。geohash是对经纬度的编码,表示地图上一个长方形的区域。
- 笔记的内容。离散内容特征做 emb变成向量。
- 笔记自带属性,反应出笔记的质量,笔记的点击和交互指标和这些数学相关。
- 算法打的分数

用各种时间粒度可以反应出用户的实时、短期、中长期兴趣;
对图文和视频分别做统计可以反映出用户对哪类笔记的偏好。

- 统计量反映出笔记的受欢迎程度。如果指标都很高,说明笔记质量高,算法应该给这种笔记更高的流量。使用不同的时间粒度也有道理,有些笔记的时效性强,30天指标很高,但最近1天的指标很差,说明这种笔记已经过时了,不应该给更多流量。
- 按照笔记的受众做分桶。把受众分成男女两个桶,分别计算男性的点击率,女性的点击率。这样的统计量可以反映出笔记是更受男还是女欢迎。比如一篇笔记是对粉色键盘的测评,笔记总体的点击点赞都很高,但是来自男性用户 的点击率很低,说明不应该吧这款粉色键盘推荐给男性用户。年龄、地域分桶也是类似的。
- 反应作者受欢迎程度和作品的平均品质。

随着推荐请求传来的,不需要从用户画像,笔记画像等数据库中获取。
- 用户可能对自己附近发生的事情感兴趣。
- 一个人在同一天不同时刻的兴趣有所区别。
- 周末 or 节假日用户可能会对特定的话题感兴趣。
- 苹果和安卓用户点击率点赞率指标差异非常显著。
特征处理

- 用户 id、笔记 id、作者 id 的数量都非常巨大,几千万几亿级别,消耗内存很大。
- 类目(几百个)、关键词(几百万个)这类处理起来很容易,做 emb 消耗内存不多。
- 把连续的年龄变成10个年龄段,做 onehot 编码或者做 emb。
- 曝光数、点击数都是长尾分布,以曝光数为例,大多数笔记只有几百次曝光而已,很少能上百万次曝光。假如直接吧曝光数作为特征输入模型,一旦出现几十万,几百万这种特别大的数值,计算会出现异常,训练时梯度很离谱,做推理时预估值很奇怪。log(1+x)可以解决异常值的问题。
- 可以把曝光数、点击数转为点击率,做平滑,去掉偶然性的波动。
- 实际中,两种变换后的连续特征都作为模型的输入,比如 log(1+曝光数)、 log(1+点击数),平滑之后的点击率也会用到。


在做特征工程时,需要关注特征覆盖率。理想情况下特征能覆盖100%的样本,不存在特征缺失的问题。需要分析特征的覆盖率,想办法提高特征覆盖率,如果一个特征很重要,提高它的覆盖率肯定可以显著提升模型表现。
除了特征覆盖率,还需要考虑当特征缺失时,需要用什么作为默认值。
数据服务

推荐系统用到三个数据源,三个数据源都存储在内存数据库中。
在线上服务时, 排序服务器会从三个数据源取回所需的数据。然后吧读取的数据做处理,作为特征喂给模型,模型就能预估出点击率点赞率等指标。
简化版:当用户刷 xhs时,用户请求会被发送到推荐系统的主服务器上,主服务器会把请求发送到召回服务器上,做完召回后,召回服务器会把几十路召回的结果做归并,把几千篇笔记的 id返回给主服务器。
召回需要调用用户画像,不展开了。
主服务器吧笔记 id、用户id、场景特征发送给排序服务器。这里有一个用户 id 和几千个笔记 id,笔记 id 是召回的结果。 用户id 和场景特征都是从用户请求中获取的,场景特征包括当前时刻、用户所在地点,以及手机型号和操作系统。
接下来,排序服务器要从多个数据源中取回排序所需特征,主要是这三个。取回的特征分别是用户特征、物品特征、统计特征。
用户画像数据库线上压力比较小,因为每次只读一个用户的特征。
物品画像数据库线上压力非常大,
粗排要给几千篇笔记做排序,读取几千篇笔记的特征
同样,存用户统计值的数据库压力小,存物品统计值的数据库压力大。
在工程实现时,用户画像里面存什么都可以,特征可以很多很大。
但尽量不要往物品画像里塞很大的向量,否则物品画像会承受过大的压力。
用户画像较为静态,像性别年龄这样的属性几乎不会发生变化。用户活跃度、兴趣标签这些属性通常也就是天级别的刷新,变化很慢。
物品画像的变化更少,可以认为是完全静态。物品自身属性和算法给物品打的标签在很长一段时间内不会发生任何变化。
对于用户画像和物品画像,最重要的是读取速度要快,而不太需要考虑时效性。因为他们都是静态的。有时候甚至可以吧用户画像,物品画像缓存到排序服务器本地,让读取变得更快。
但不能吧统计数据在本地缓存,统计数据是动态变化的时效性很强,比如用户刷新 xhs往下刷了30篇,点击了5篇,点赞了1篇。那么这个用户的曝光、点击、点赞等统计量都发生了变化,要尽快刷新数据库。
再收集到排序所需的特征后,排序服务器把特征打包传递给 tf serving,tensorflow 会给笔记打分,吧分数返回给排序服务器。
排序服务器会用融合的分数,多样性分数和业务规则给笔记做排序。把排名最高的几十篇笔记返回给主服务器,就是最后给用户曝光的笔记,