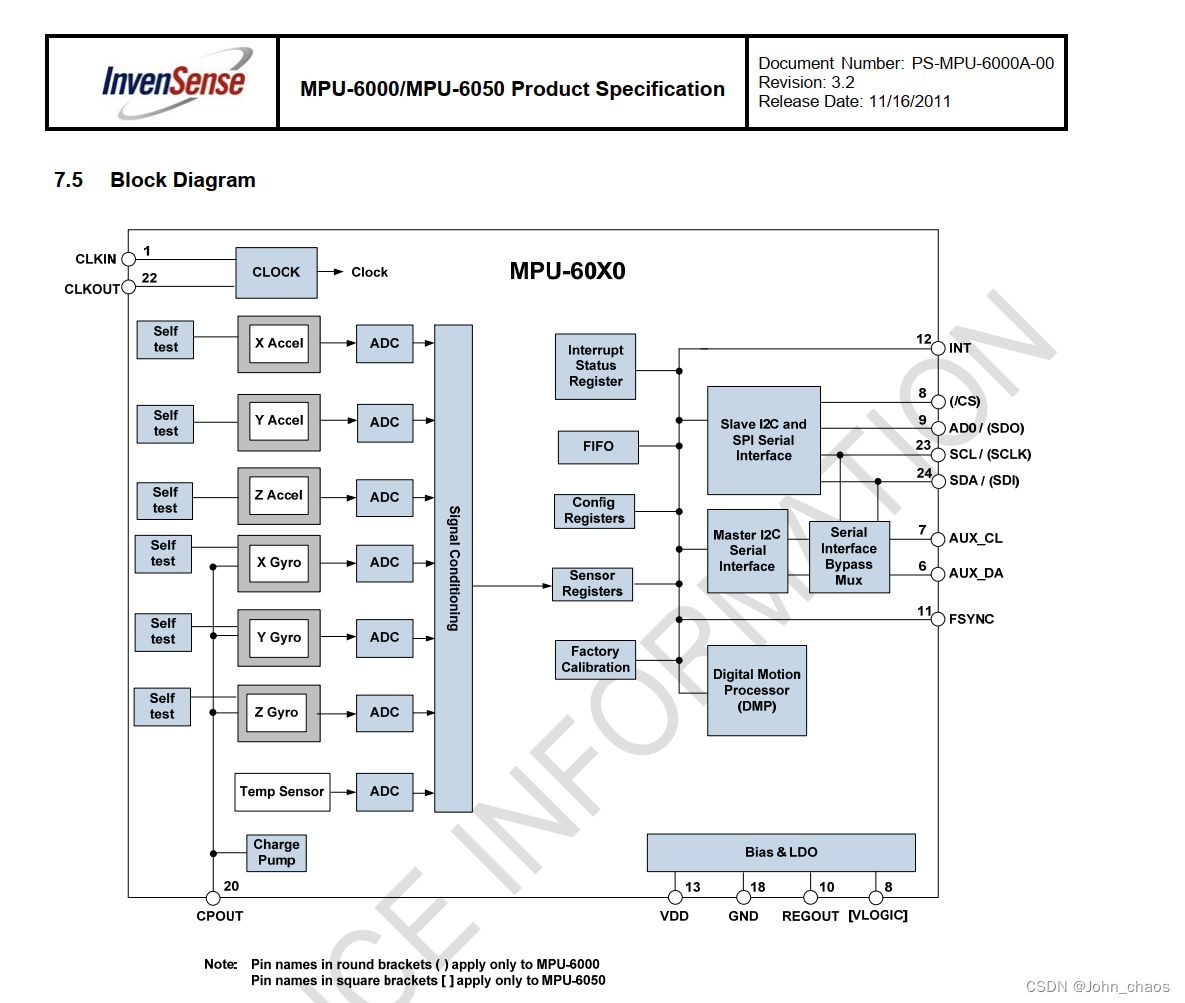
目录
- 0.准备
- 1.问题分析
- 挑战
- 流程
- 数据集介绍
- 结果提交
- 2.代码实现
- 2.1 加载数据
- 2.1.1 加载训练数据
- 2.1.2 加载测试数据
- 2.2 数据分析
- 2.3 模型建立与预测
- 3.结果提交
0.准备
注册kaggle账号后,进入titanic竞赛界面
https://www.kaggle.com/competitions/titanic
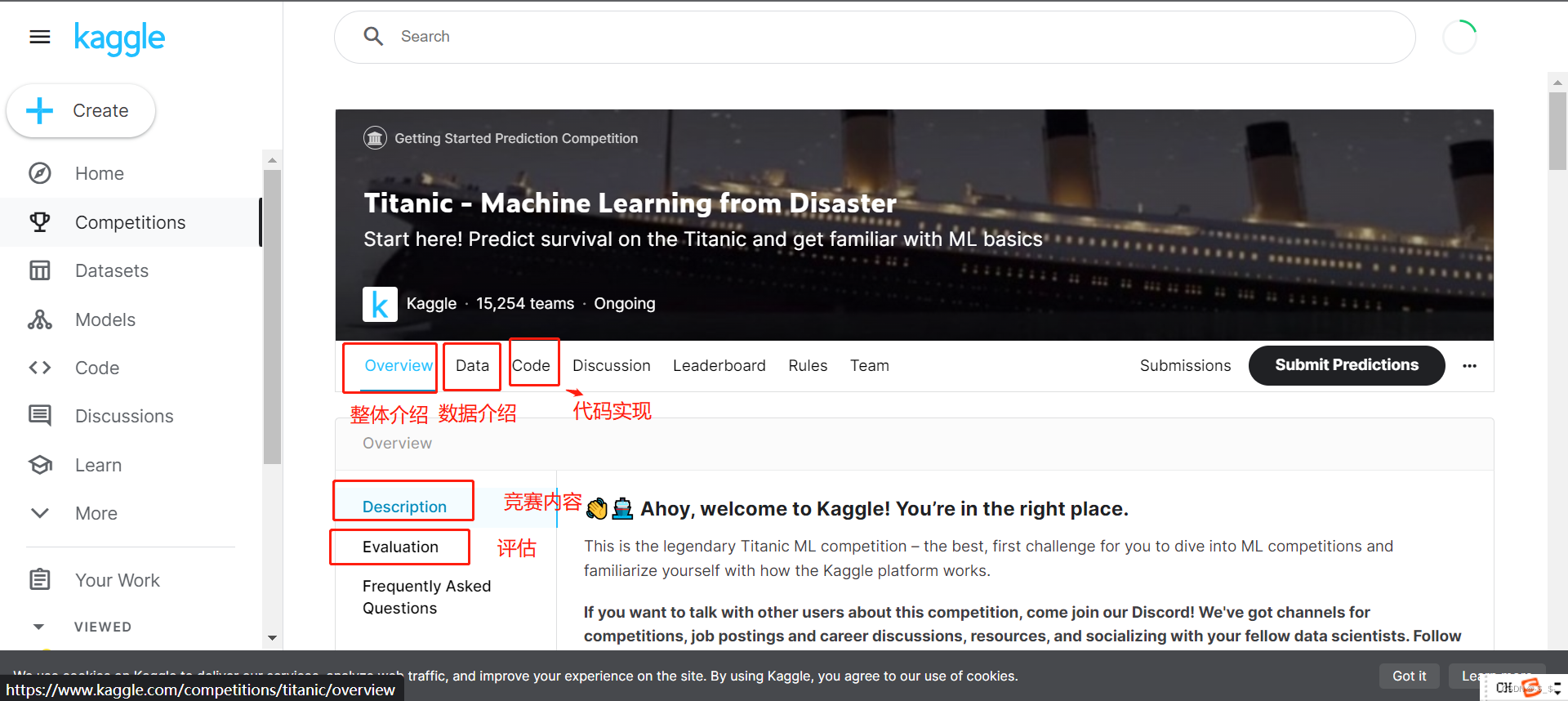
进入后界面如下
Overview部分为竞赛整体介绍,包括竞赛介绍以及结果评估。
Data部分为数据集介绍,介绍使用的数据集。
Code部分为提交的代码
1.问题分析
挑战
泰坦尼克号的沉没是历史上最臭名昭著的沉船事故之一。
1912 年 4 月 15 日,被公认为 "永不沉没 "的皇家邮轮泰坦尼克号在首航时撞上冰山沉没。不幸的是,由于没有足够的救生艇供船上所有人使用,2224 名乘客和船员中有 1502 人丧生。
虽然生还有一定的运气成分,但似乎有些群体比其他群体更有可能生还。
在这项挑战中,我们要求您建立一个预测模型来回答这个问题:"使用乘客数据(即姓名、年龄、性别、社会经济阶层等)来回答 "什么样的人更有可能幸存?
流程
- 参加竞赛
阅读挑战说明,接受竞赛规则并访问竞赛数据集。 - 开始工作
下载数据,在本地或 Kaggle Notebooks(我们的免设置、可定制的 Jupyter Notebooks 环境,配备免费 GPU)上构建模型,并生成预测文件。 - 提交
在 Kaggle 上以提交的形式上传您的预测,并获得准确率分数。 - 查看排行榜
在我们的排行榜上查看您的模型在其他 Kaggler 中的排名。 - 提高分数
查看讨论区,查找大量教程和其他竞争对手的见解。
数据集介绍
在本次竞赛中,您将获得两个类似的数据集,其中包括乘客信息,如姓名、年龄、性别、社会经济阶层等。一个数据集名为 train.csv,另一个名为 test.csv。
Train.csv将包含一个乘客子集(确切地说是891人)的详细信息,重要的是,它将揭示乘客是否幸存,也就是所谓的 “基本事实”。
test.csv 数据集包含类似的信息,但不会披露每位乘客的 “基本事实”。您的任务就是预测这些结果。
利用您在 train.csv 数据中发现的模式,预测机上其他 418 名乘客(在 test.csv 中找到)是否幸存。
结果提交
-
目标
您的任务是预测泰坦尼克号沉没时是否有乘客幸存。
对于测试集中的每个变量,您必须预测其值为 0 或 1。 -
指标
您的分数是您正确预测乘客的百分比。这就是所谓的准确率。 -
提交文件格式
您应提交一个 csv 文件,其中包含 418 个条目和一行标题。如果您提交的文件中有额外的列(除乘客编号和存活人数外)或行,则会显示错误。
2.代码实现
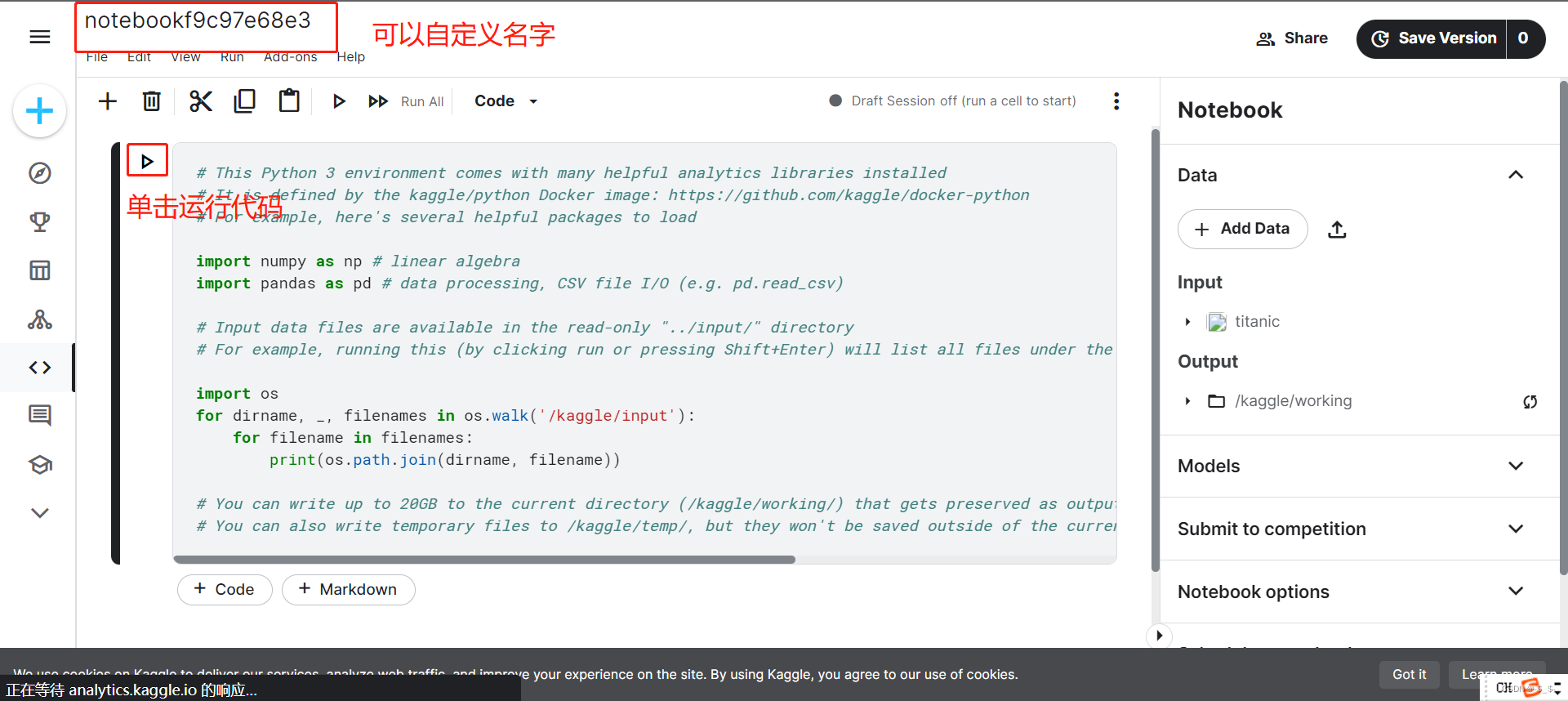
首先选择Code,之后点击New Notebook
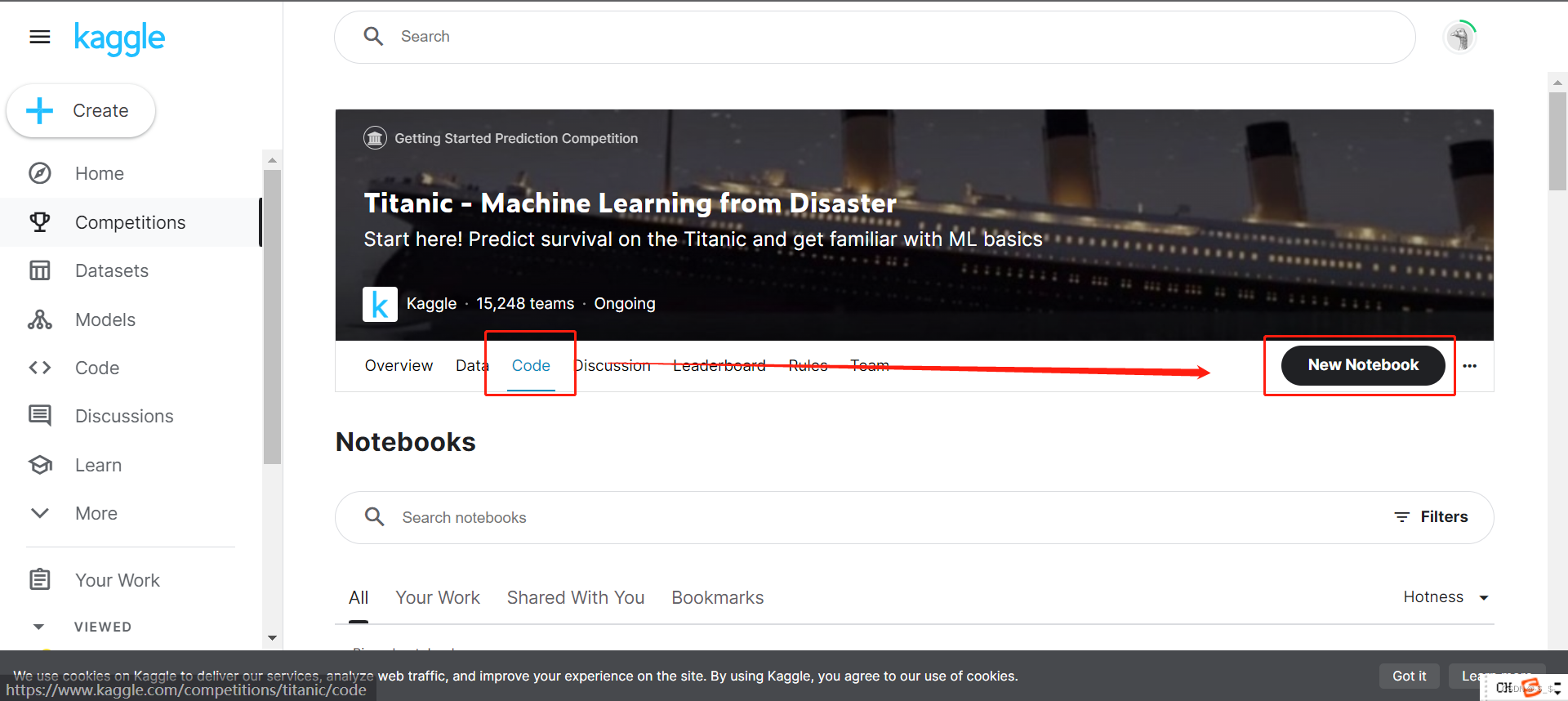
新建Notebook后,会出现如下界面
单击运行Notebook中的代码
查看运行结果
代码为
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
结果应为
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csv
2.1 加载数据
主要使用
pd.read_csv(filepath_or_buffer. sep=‘;’)
filepath_or_buffer 输入需要读取的csv文件路径
sep指定数据中列之间的分隔符,默认为逗号。
data.head():返回data的前几行数据,默认为前五行,需要前十行则data.head(10)
data.tail():返回data的后几行数据,默认为后五行,需要后十行则data.tail(10)
2.1.1 加载训练数据
代码
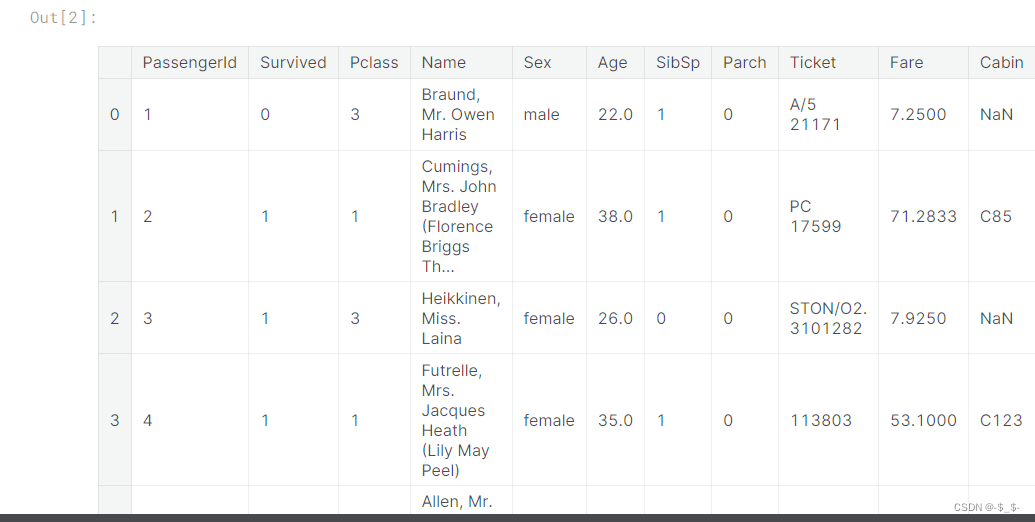
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
输出结果
2.1.2 加载测试数据
代码
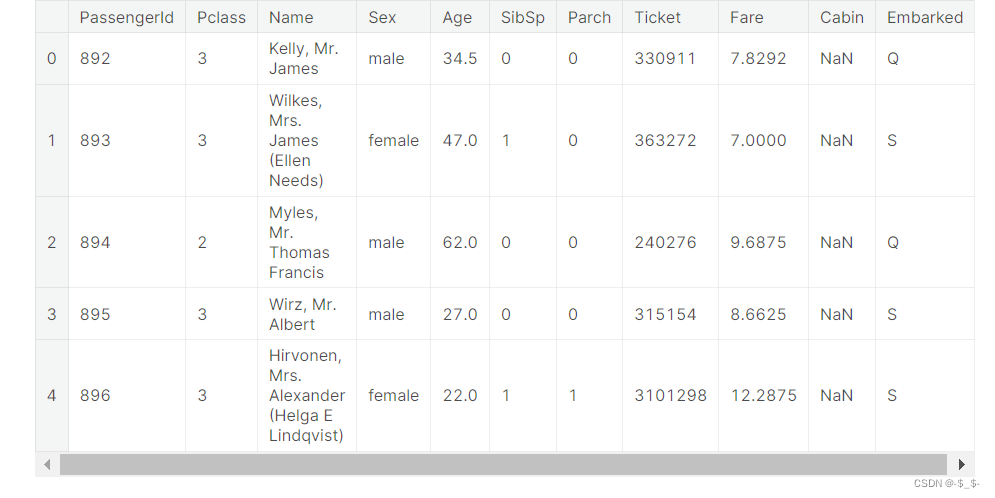
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
结果
2.2 数据分析
记住我们的目标:我们希望在train.csv中找到规律,帮助我们预测test.csv中的乘客是否幸存。
当有这么多数据需要排序时,最初寻找规律可能会让人感到不知所措。所以,我们从简单开始。
请记住,gender_submission.csv中的样本提交文件假设所有女性乘客幸存(所有男性乘客死亡)。
这是一个合理的初步猜测吗?我们将检查这个猜测在数据中是否成立(在train.csv中)。
将下面的代码复制到新的代码单元格中。然后,运行单元格。
代码
(计算女性幸存率)
women = train_data.loc[train_data.Sex == 'female']["Survived"]
rate_women = sum(women)/len(women)
print("% of women who survived:", rate_women)
结果
% of women who survived: 0.7420382165605095
(计算男性幸存率)
men = train_data.loc[train_data.Sex == 'male']["Survived"]
rate_men = sum(men)/len(men)
print("% of men who survived:", rate_men)
结果
% of men who survived: 0.18890814558058924
上面的代码计算了幸存的男性乘客(在火车.csv中)的百分比。
从中可以看出,船上几乎75%的女性幸存下来,而只有19%的男性活了下来。由于性别似乎是生存的有力指标,gender_submission.csv中的提交文件并不是一个糟糕的第一猜测!
但归根结底,这份基于性别的报告的预测只基于一个专栏。正如你所能想象的,通过考虑多列,我们可以发现更复杂的模式,这些模式可能会产生更明智的预测。由于同时考虑几个列是非常困难的(或者,同时考虑许多不同列中的所有可能模式需要很长时间),我们将使用机器学习来实现自动化。
2.3 模型建立与预测
我们将建立一个所谓的随机森林模型。该模型由几棵“树”组成(下图中有三棵树,但我们将构建100棵!),它们将单独考虑每位乘客的数据,并投票决定乘客是否幸存。然后,随机森林模型做出一个民主的决定:得票最多的结果获胜!
下面的代码单元在数据的四个不同列(“Pclass”、“Sex”、“SibSp”和“Parch”)中查找模式。它根据train.csv文件中的模式在随机森林模型中构建树,然后在test.csv中为乘客生成预测。该代码还将这些新预测保存在csv文件submission.csv中。
将此代码复制到您的笔记本中,并在新的代码格中运行。
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
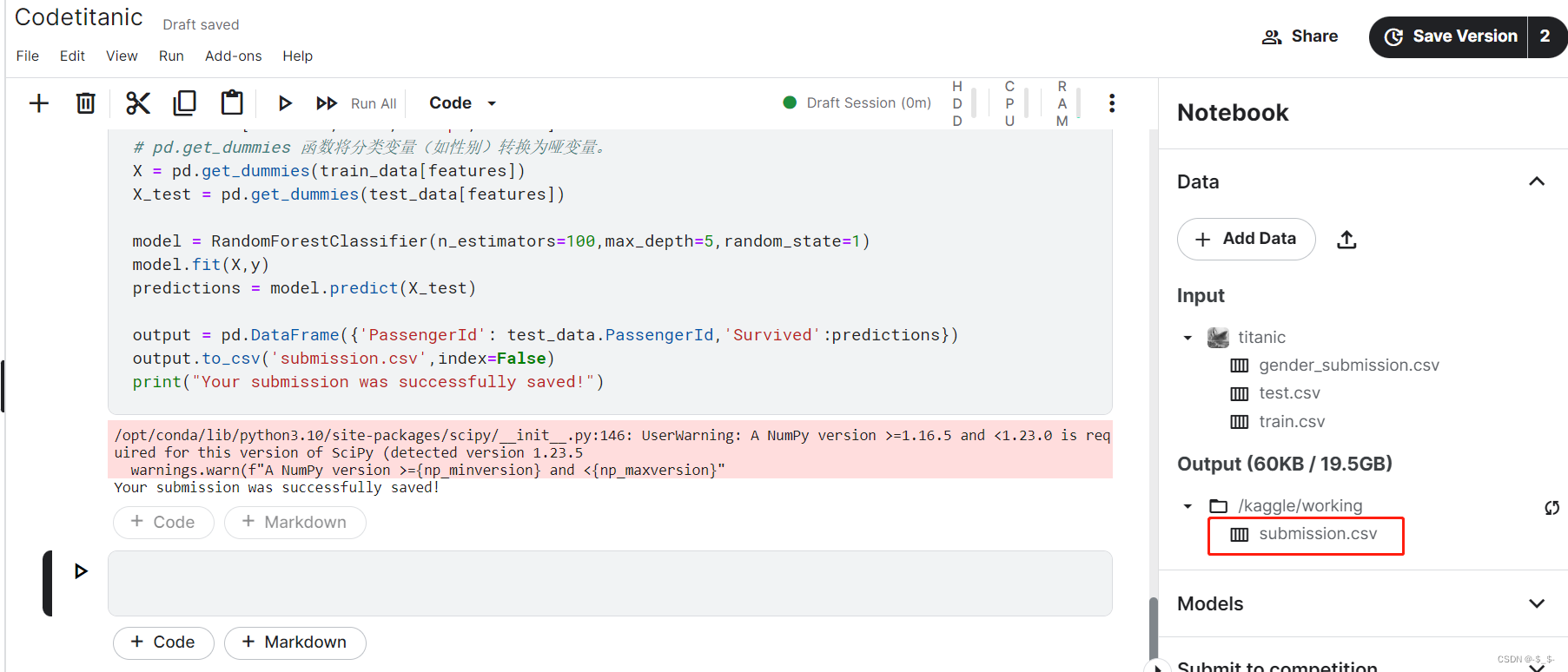
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
运行结果
Your submission was successfully saved!
可以看到,在Outpu文件夹下生成了submission.csv
3.结果提交
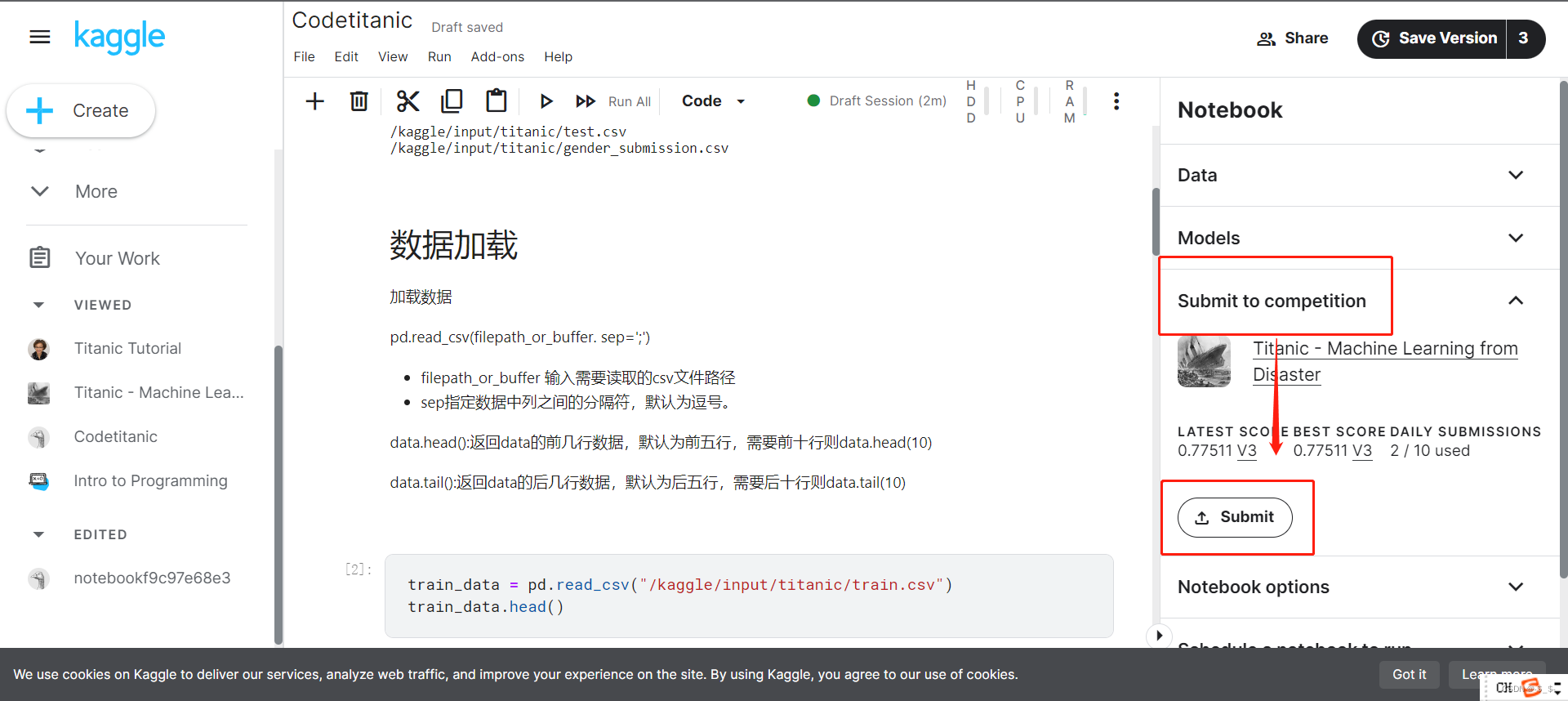
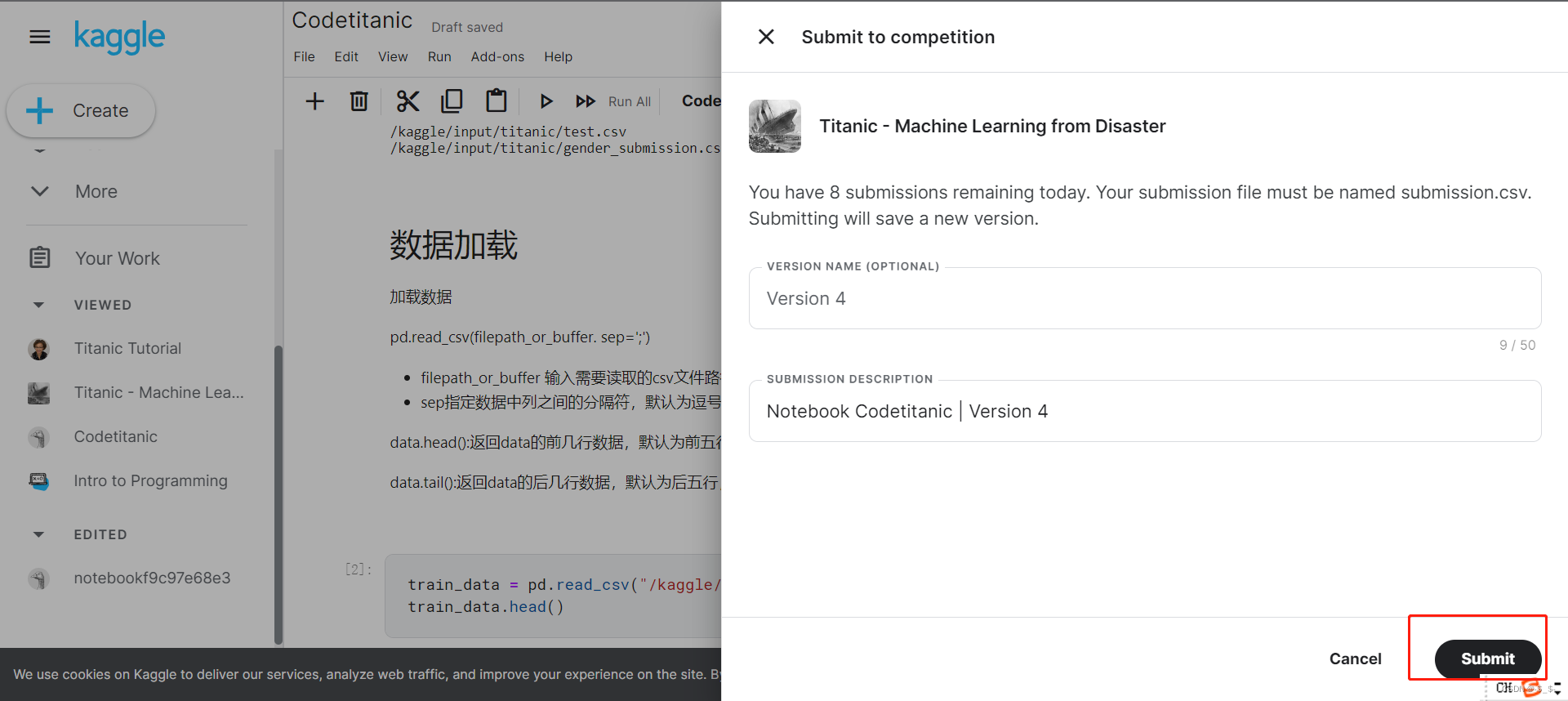
提交后在右边可看到最新提交的结果