文章目录
- 基本概念:文档和索引
- JSON文档
- 元数据
- 索引
- REST API
- 节点和集群
- 节点
- Master eligible节点和Master节点
- Data Node 和 Coordinating Node
- 其它节点
- 分片(Primary Shard & Replica Shard)
- 分片的设定
- 操作命令
基本概念:文档和索引
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位。
- 文档会被序列化成JSON格式,保存在Elasticsearch中。
- JSON对象由字段组成,每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)。
- 每个文档都有一个UniqueID,你可以自己指定ID,或者通过Elasticsearch自动生成。
JSON文档
一篇文档包含了一系列的字段,类似数据库表中一条记录,字段的类型可以指定或者通过Elasticsearch自动推算,支持数组,支持嵌套。

元数据
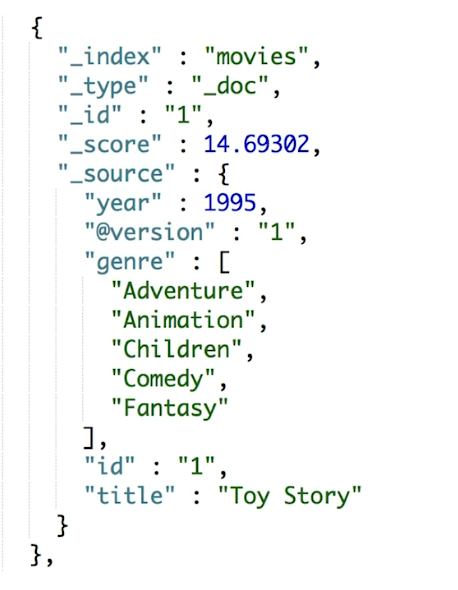
每一个文档都有一个元数据,元数据是用于标注文档的相关信息的。
- _index: 文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯一ld
- _source:文档的原始Json数据
- _all:整合所有字段内容到该字段,7.0版本已被废除
- _version:文档的版本信息
- _score:相关性打分
索引
索引(Index)是文档的容器,是一类文档的结合。
- Index体现了逻辑空间的概念:每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型;
- Shard体现了物理空间的概念:索引中的数据分散在Shard上
- 索引的 Mapping定义文档字段的类型,Setting定义不同的数据分布

{
"settings": {
"index": {
"creation_date": "1690724511450",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "fl-Kf7M9TiiEpFPfAT6Iew",
"version": {
"created": "7010099"
},
"provided_name": "movies"
}
}
REST API
补充:kibana显示中文界面,打开 kibana/config/kibana.yml,最后一行写入 i18n.locale: “zh-CN”,然后重新启动kibana
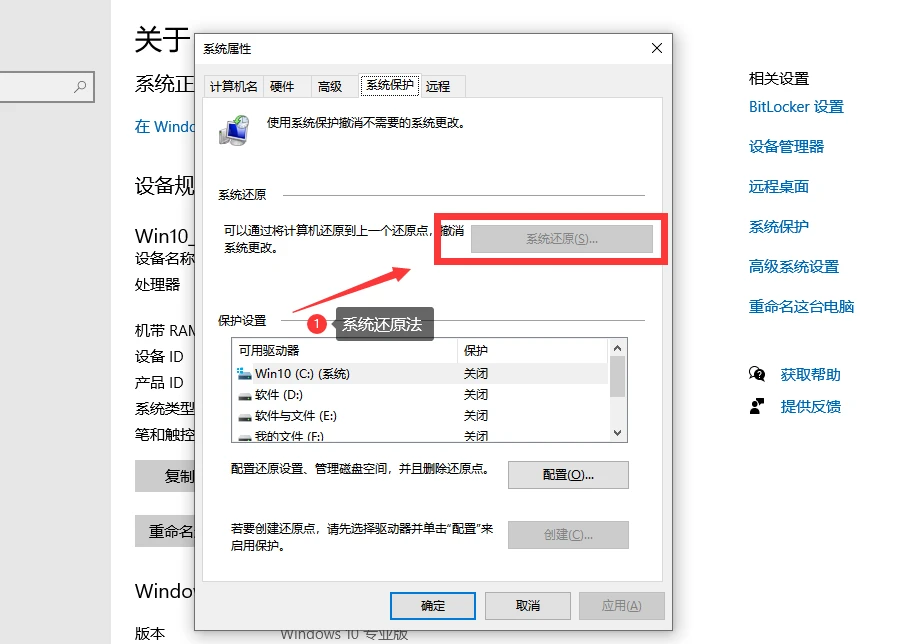
进入Kibana页面–>开发工具–>console:
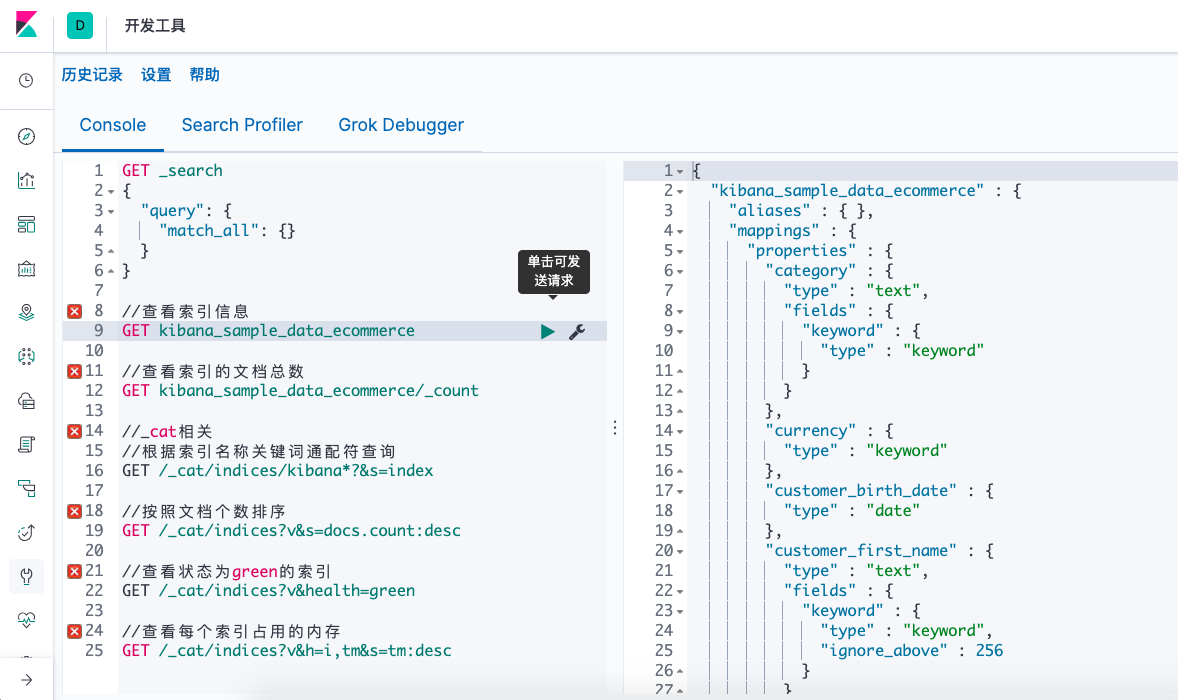
//查看索引信息
GET kibana_sample_data_ecommerce
//查看索引的文档总数
GET kibana_sample_data_ecommerce/_count
//_cat相关
//根据索引名称关键词通配符查询
GET /_cat/indices/kibana*?&s=index
//按照文档个数排序
GET /_cat/indices?v&s=docs.count:desc
//查看状态为green的索引
GET /_cat/indices?v&health=green
//查看每个索引占用的内存
GET /_cat/indices?v&h=i,tm&s=tm:desc
节点和集群
Elasticsearch分布式系统的高可用性和可扩展性:
- 服务可用性-允许有节点停止服务
- 数据可用性-部分节点丢失,不会丢失数据
- 请求量提升/数据的不断增长(将数据分布到所有节点上)
Elasticsearch分布式架构的特点
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
- 不同的集群通过不同的名字来区分,默认名字“elasticsearch”,也可以通过配置文件修改,或者在命令行中-E cluster.name=geektime进行设定
- 一个集群可以有一个或者多个节点
节点
- 节点是一个 Elasticsearch的实例,其本质上就是一个 JAVA进程,一台机器 上可以运行多个Elasticsearch进程,但是生产环境一般建议一台机器上只运行一个Elasticsearch实例;
- 每一个节点都有名字, 通过配置文件配置,或者启动时候 -E node.name=node1 指定。每一个节点在启动之后,会分配一个UID,保存在data目录下。
Master eligible节点和Master节点
- 每个节点启动后,默认就是一个Master eligible节点(可以通过设置node.master: false 禁止)
- Master-eligible节点可以参加选主流程,成为Master 节点;当第一个节点启动时候,它会将自己选举成Master节点。
- 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息。
- 集群状态(Cluster State) 维护了一个集群中必要的信息,包括:所有的节点信息、所有的索引和其相关的Mapping与Setting 信息、分片的路由信息。任意节点都能修改信息会导致数据的不一致性。
Data Node 和 Coordinating Node
- 可以保存数据的节点,叫做Data Node,负责保存分片数据,在数据扩展上起到了至关重要的作用。
- Coordinating Node:负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起;每个节点默认都起到了Coordinating Node的职责。
其它节点
- Hot & Warm Node:不同硬件配置的Data Node, 用来实现Hot & Warm架构,降低集群部署的成本
- Machine L earning Node:负责跑机器学习的Job,用来做异常检测
*Tribe Node:(5.3开始使用Cross Cluster Serarch) Tribe Node连接到不同的Elasticsearch集群,并且支持将这些集群当成一个单独的集群处理
分片(Primary Shard & Replica Shard)
- 主分片,用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上。一个分片是一个运行的Lucene的实例。主分片数在索引|创建时指定,后续不允许修改,除非Reindex。
- 副本用以解决数据高可用的问题。分片是主分片的拷贝副本分片数,可以动态地调整。增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
分片的设定
- 对于生产环境中分片的设定,需要提前做好容量规划。如果分片数设置过小,导致后续无法增加节点实现水品扩展;如果单个分片的数据量太大,导致数据重新分配耗时。
- 分片数设置过大,7.0开始,默认主分片设置成1, 解决了over-sharding的问题,影响搜索结果的相关性打分,影响统计结果的准确性;单个节点上过多的分片,会导致资源浪费,同时也会影响性能。
操作命令
通过 GET _cluster/health 可以查看集群的健康度
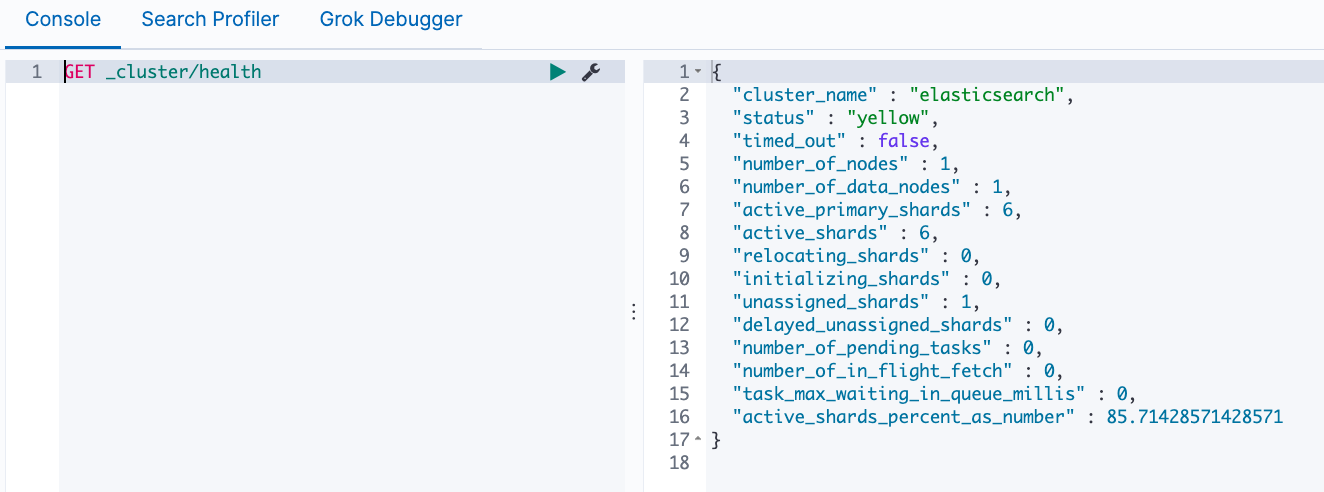
其中 status的含义如下:
- Green- 主分片与副本都正常分配
- Yellow -主分片全部正常分配,有副本分片未能正常分配
- Red -有主分片未能分配例如,当服务器的磁盘容量超过85%时,去创建了一个新的索引
#查看健康度(按下Command+/可以跳转到官网查看详细用法)
GET _cluster/health
#查看node信息
GET _cat/nodes
#查看shards信息
GET _cat/shards