文章目录
- 介绍
- 相关工作
- text-based QA
- 多跳QA推理
- 模型
- 段落选择器
- 构建实体图
- 编码 Query 和 Context
- Fusion Block 推理
- Doc2Graph
- Dynamic Graph Attention
- Update Query
- Graph2Doc
- 预测
介绍
将 DFGN 模型用于HotpotQA (TBQA类型的公开数据集)
QA任务注重从单一的篇章中找到证据和答案,但是有一些不需要推理,只要抽取就可以了。针对这个问题,有了一些需要多跳理解任务的数据集,如 WikiHop, Complex Web Question, HotpotQA
多跳理解任务面临的两大挑战:
- 需要从多个篇章中过滤噪声,抽取出有用的信息。
- 有文章提出从输入的篇章中建立实体图,通过实体图,用GNN来聚合信息
- 问题:静态的全局实体图,是隐式的推理
- 本文:根据query去构建动态的局部实体图,进行显式的推理
- 问题的答案可能并不存在于抽取得到的实体图的实体中
- 本文:两个方向的信息集成
- doc2graph:把文档信息集成到实体图中
- graph2doc:把实体图的信息集成回文档表示
- 本文:两个方向的信息集成
本文的贡献:
- 提出 DFGN,解决基于文本(text-based)的多跳问答问题
- 提出了一种方法来解释与评估 reasoning chains,解释 DFGN 预测的 entity graph masks
- 在HotpotQA数据集上实验,验证了模型的有效性
相关工作
text-based QA
给予支持信息是否是结构化的,QA任务可以分为两类:
- 基于知识的,knowledge-based QA (KBQA)
- 基于文本的,text-based QA (TBQA)
基于推理的复杂度,可以分为两类:
- 单跳:SQuAD
- 多跳:HotpotQA
信息检索式(IR)的方法可以用于单跳QA,却很难用于多跳QA
多跳QA推理
- GNN、GAN、GRN(Graph Recurrent Network)已经证明了QA任务中需要推理
- Coref-GRN 利用 GRN
模型
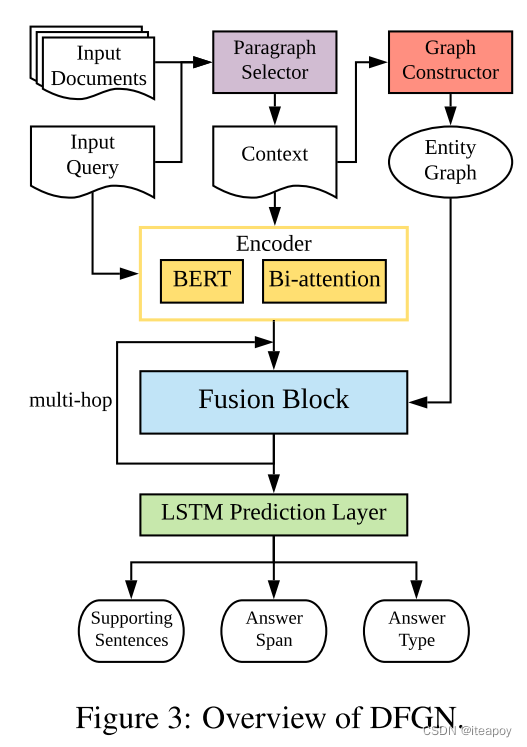
- 模型由五个部分组成:
- a paragraph selection subnetwork,段落选择器
- a module for entity graph construction,entity graph生成器
- an encoding layer 编码模块
- a fusion block for multi-hop reasoning 多跳预测所用的 Fusion Block
- a final prediction layer 最后的预测层
段落选择器
hotpotQA 数据集中有 10 个段落
训练一个子网络来选择相关的段落,基于BERT模型做分类
- 输入一个query 和一个段落,输出一个 0-1 的相关度打分
- 对每个 Q&A 对来说,给有至少一个支持句子的段落赋值为1
- 在推理阶段,选择预测分值大于 η \eta η 的段落,并且拼接为上下文 C C C
构建实体图
- 用 Stanford corenlp toolkit 去识别命名实体 C C C,抽取得到 N N N 个实体
- 实体图,以实体为点,边的添加规则如下:
- 一对实体出现在 C C C 中的同一个句子中(sentence- level links)
- 一对实体出现在 C C C 中(context-level links)
- 一个中心实体与另外的实体在同一个段落中(paragraph-level links)
- 在QA数据集中,title就是实体
编码 Query 和 Context
- 把
Q
Q
Q 和
C
C
C 拼接,从BERT模型得到表示
- Q = [ q 1 , … , q L ] ∈ R L × d 1 Q=[q_1,\ldots,q_L]\in R^{L\times d_1} Q=[q1,…,qL]∈RL×d1
- C T = [ c 1 , … , c M ] ∈ R M × d 1 C^T=[c_1,\ldots,c_M]\in R^{M\times d_1} CT=[c1,…,cM]∈RM×d1
- d 1 d_1 d1 是 BERT 的隐藏层大小
- 实验发现:拼接后传入 BERT 比分别传入 BERT 效果要好
- 把表示通过 bi-attention 层,的到 query 和 context 之间的表示,效果比只用 BERT 编码效果要好
Fusion Block 推理
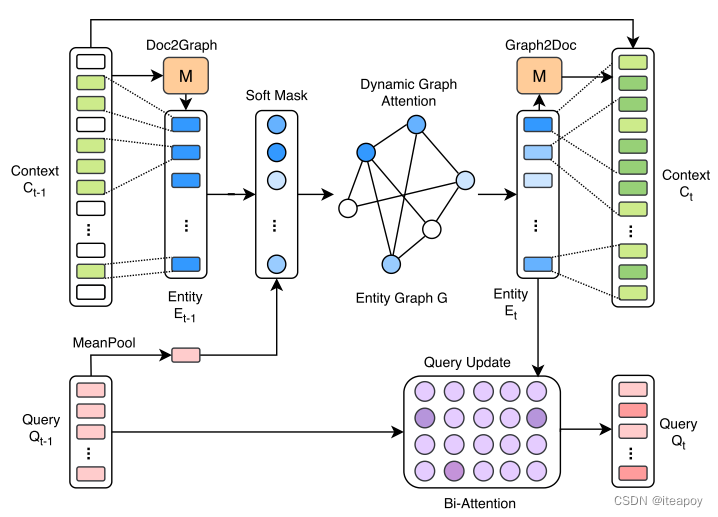
Doc2Graph
- 计算命名实体的嵌入
- 01矩阵
M
M
M 表示一个实体的 text span(文本范围)
- M i , j = 1 M_{i,j}=1 Mi,j=1 表示第 i i i 个token 是第 j j j 个实体的一部分
- Tok2Ent
- token embedding传到一个 mean-max 池化层,计算得到 entity embedding
Dynamic Graph Attention
- 利用 GAT的方式计算两个实体间的注意力评分
Update Query
- 最近访问的 entity 会成为下一步的 start entity
- 利用 bi-attention network 去更新 query embeddings
- Q ( t ) = \mathbf{Q}^{(t)}= Q(t)= Bi-Attention ( Q ( t − 1 ) , E ( t ) ) \left(\mathbf{Q}^{(t-1)}, \mathbf{E}^{(t)}\right) (Q(t−1),E(t))
Graph2Doc
- 把实体信息复原回context中的token
- 用同一个 01 矩阵
M
M
M
- M M M 中每一行表示一个token
- 用它从 E t E_t Et 中 选择一个实体嵌入 -> M E ME ME
- 用 LSTM 去生成下一层的 context 表示
- C ( t ) = LSTM ( [ C ( t − 1 ) , M E ( t ) ⊤ ] ) \mathbf{C}^{(t)}=\operatorname{LSTM}\left(\left[\mathbf{C}^{(t-1)}, \mathbf{M} \mathbf{E}^{(t) \top}\right]\right) C(t)=LSTM([C(t−1),ME(t)⊤])
预测
- 与 hotpotQA 的结构相同
- 四个输出:
- 支持句子
- 回答的开始位置
- 回答的结束位置
- 回答的类型
- 用一个级联网络解决输出的依赖性
- 四个 LSTM F i \mathcal{F}_i Fi 一层层堆叠
- 最后一个 fusion bloack 的上下文表示输入到第一个LSTM中
- O sup = F 0 ( C ( t ) ) O start = F 1 ( [ C ( t ) , O sup ] ) O end = F 2 ( [ C ( t ) , O sup , O start ] ) O type = F 3 ( [ C ( t ) , O sup , O end ] ) \begin{aligned} \mathbf{O}_{\text {sup }} &=\mathcal{F}_0\left(\mathbf{C}^{(t)}\right) \\ \mathbf{O}_{\text {start }} &=\mathcal{F}_1\left(\left[\mathbf{C}^{(t)}, \mathbf{O}_{\text {sup }}\right]\right) \\ \mathbf{O}_{\text {end }} &=\mathcal{F}_2\left(\left[\mathbf{C}^{(t)}, \mathbf{O}_{\text {sup }}, \mathbf{O}_{\text {start }}\right]\right) \\ \mathbf{O}_{\text {type }} &=\mathcal{F}_3\left(\left[\mathbf{C}^{(t)}, \mathbf{O}_{\text {sup }}, \mathbf{O}_{\text {end }}\right]\right) \end{aligned} Osup Ostart Oend Otype =F0(C(t))=F1([C(t),Osup ])=F2([C(t),Osup ,Ostart ])=F3([C(t),Osup ,Oend ])
- 每一个输出的 logit O \mathbf{O} O 计算交叉熵损失
- 把四个 loss 拼接起来,引入不同权重: L = L start + L end + λ s L sup + λ t L type \mathcal{L}=\mathcal{L}_{\text {start }}+\mathcal{L}_{\text {end }}+\lambda_s \mathcal{L}_{\text {sup }}+\lambda_t \mathcal{L}_{\text {type }} L=Lstart +Lend +λsLsup +λtLtype