cuda教程目录
第一章 指针篇
第二章 CUDA原理篇
第三章 CUDA编译器环境配置篇
第四章 kernel函数基础篇
第五章 kernel索引(index)篇
第六章 kenel矩阵计算实战篇
第七章 kenel实战强化篇
第八章 CUDA内存应用与性能优化篇
第九章 CUDA原子(atomic)实战篇
第十章 CUDA流(stream)实战篇
第十一章 CUDA的NMS算子实战篇
第十二章 YOLO的部署实战篇
第十三章 基于CUDA的YOLO部署实战篇
cuda教程背景
随着人工智能的发展与人才的内卷,很多企业已将深度学习算法的C++部署能力作为基本技能之一。面对诸多arm相关且资源有限的设备,往往想更好的提速,满足更高时效性,必将更多类似矩阵相关运算交给CUDA处理。同时,面对市场诸多教程与诸多博客岑子不起的教程或高昂教程费用,使读者(特别是小白)容易迷糊,无法快速入手CUDA编程,实现工程化。
因此,我将结合我的工程实战经验,我将在本专栏实现CUDA系列教程,帮助读者(或小白)实现CUDA工程化,掌握CUDA编程能力。学习我的教程专栏,你将绝对能实现CUDA工程化,完全从环境安装到CUDA核函数编程,从核函数到使用相关内存优化,从内存优化到深度学习算子开发(如:nms),从算子优化到模型(以yolo系列为基准)部署。最重要的是,我的教程将简单明了直切主题,CUDA理论与实战实例应用,并附相关代码,可直接上手实战。我的想法是掌握必要CUDA相关理论,去除非必须繁杂理论,实现CUDA算法应用开发,待进一步提高,将进一步理解更高深理论。
cuda教程内容
第一章到第三章探索指针在cuda函数中的作用与cuda相关原理及环境配置;
第四章初步探索cuda相关函数编写(global、device、__host__等),实现简单入门;
第五章探索不同grid与block配置,如何计算kernel函数的index,以便后续通过index实现各种运算;
第六、七章由浅入深探索核函数矩阵计算,深入探索grid、block与thread索引对kernel函数编写作用与影响,并实战多个应用列子(如:kernel函数实现图像颜色空间转换);
第八章探索cuda内存纹理内存、常量内存、全局内存等分配机制与内存实战应用(附代码),通过不同内存的使用来优化cuda计算性能;
第九章探索cuda原子(atomic)相关操作,并实战应用(如:获得某些自加索引等);
第十章探索cuda流stream相关应用,并给出相关实战列子(如:多流操作等);
第十一到十三章探索基于tensorrt部署yolo算法,我们首先将给出通用tensorrt的yolo算法部署,该部署的前后处理基于C++语言的host端实现,然后给出基于cuda的前后处理的算子核函数编写,最后数据无需在gpu与host间复制操作,实现gpu处理,提升算法性能。
目前,以上为我们的cuda教学全部内容,若后续读者有想了解知识,可留言,我们将根据实际情况,更新相关教学内容。
大神忽略
源码链接地址点击这里
文章目录
- cuda教程目录
- cuda教程背景
- cuda教程内容
- 源码链接地址[点击这里](https://github.com/tangjunjun966/cuda-tutorial-master)
- 前言
- 一、内存知识回顾
- 二、GPU内存信息查询
- 三、可分页内存与页锁定内存
- 四、cudaMallocHost 和 cudaMalloc(可分页内存与页锁定内存)
- 1、内存分配方式
- Host端内存分配(Pageable Memory)
- 2、分配的内存类型
- 3、内存的使用方式
- 4、内存的传输方式
- 5、性能
- 6、总结
- 八、总结
前言
以上章节中,我们已经比较熟练掌握如何使用cuda编写自己想要的计算逻辑,已能成功编写cuda代码了。 那么,另外一个重要问题值得我们关注,如何优化其性能,使其工程部署能加速运行了。而这种性能优化与cuda内存密切相关。为此,我们在本节中介绍cuda内存相关内容,并附其源码。
一、内存知识回顾
我再次简单回顾下相关内存概念,详细内容可看我第二章内容(我个人局的还是重要)链接点击这里。
Registers:寄存器是GPU中最快的memory,kernel中没有什么特殊声明的自动变量都是放在寄存器中的。当数组的索引是constant类型且在编译期能被确定的话,就是内置类型,数组也是放在寄存器中。 寄存器变量是每个线程私有的,一旦thread执行结束,寄存器变量就会失效。
Shared Memory:用__shared__修饰符修饰的变量存放在shared memory中。Shared Memory位于GPU芯片上,访问延迟仅次于寄存器。所有Thread来进行访问的,可以实现Block内的线程间的低开销通信。 要使用__syncthread()同步。
Local Memory:本身在硬件中没有特定的存储单元,而是从Global Memory虚拟出来的地址空间。是为寄存器无法满足存储需求的情况而设计的,主要是用于存放单线程的大型数组和变量。Local Memory是线程私有的,线程之间是不可见的。它的访问是比较慢的,跟Global Memory的访问速度是接近的。使用情景,无法确定其索引是否为常量的数组;会消耗太多寄存器空间的大型结构或数组;如果内核使用了多于寄存器的任何变量(这也称为寄存器溢出);
Constant Memory:固定内存空间驻留在设备内存中,并缓存在固定缓存中(constant cache),范围是全局的,针对所有kernel; kernel只能从constant Memory中读取数据,因此其初始化必须在host端使用下面的function调用:cudaError_t cudaMemcpyToSymbol(const void* symbol,const void* src,size_t count); 当一个warp中所有线程都从同一个Memory地址读取数据时,constant Memory表现会非常好,会触发广播机制。
Global Memory:Global Memory在某种意义上等同于GPU显存,kernel函数通过Global Memory来读写显存。Global Memory是kernel函数输入数据和写入结果的唯一来源。
Texture Memory:是GPU的重要特性之一,也是GPU编程优化的关键。Texture Memory实际上也是Global Memory的一部分,但是它有自己专用的只读cache。这个cache在浮点运算很有用,Texture Memory是针对2D空间局部性的优化策略,所以thread要获取2D数据就可以使用texture Memory来达到很高的性能。从读取性能的角度跟Constant Memory类似。
Host Memory:主机端存储器主要是内存可以分为两类:可分页内存(Pageable)和页面 (Page-Locked 或 Pinned)内存。可分页内存通过操作系统 API(malloc/free) 分配存储器空间,该内存是可以换页的,即内存页可以被置换到磁盘中。可分页内存是不可用使用DMA(Direct Memory Acess)来进行访问的,普通的C程序使用的内存就是这个内存。
二、GPU内存信息查询
代码如下:
int inquire_GPU_info() {
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int dev;
for (dev = 0; dev < deviceCount; dev++)
{
int driver_version(0), runtime_version(0);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
if (dev == 0)
if (deviceProp.minor = 9999 && deviceProp.major == 9999)
printf("\n");
printf("\nDevice%d:\"%s\"\n", dev, deviceProp.name);
cudaDriverGetVersion(&driver_version);
printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10);
cudaRuntimeGetVersion(&runtime_version);
printf("CUDA运行时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10);
printf("设备计算能力: %d.%d\n", deviceProp.major, deviceProp.minor);
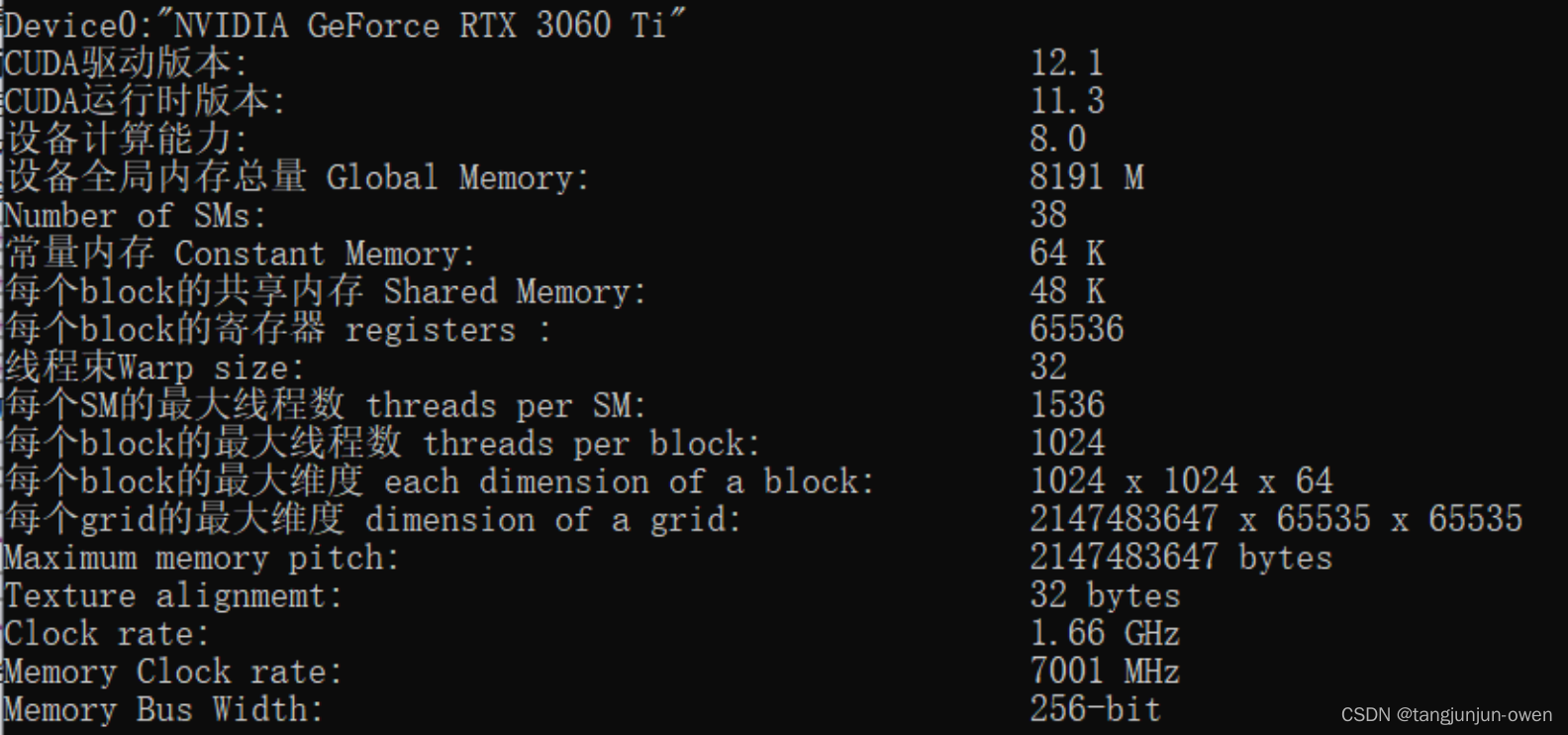
printf("设备全局内存总量 Global Memory: %u M\n", deviceProp.totalGlobalMem/(1024*1024));
printf("Number of SMs: %d\n", deviceProp.multiProcessorCount);
printf("常量内存 Constant Memory: %u K\n", deviceProp.totalConstMem/1024);
printf("每个block的共享内存 Shared Memory: %u K\n", deviceProp.sharedMemPerBlock/1024);
printf("每个block的寄存器 registers : %d\n", deviceProp.regsPerBlock);
printf("线程束Warp size: %d\n", deviceProp.warpSize);
printf("每个SM的最大线程数 threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor);
printf("每个block的最大线程数 threads per block: %d\n", deviceProp.maxThreadsPerBlock);
printf("每个block的最大维度 each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]);
printf("每个grid的最大维度 dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);
printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch);
printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment);
printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f);
printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f);
printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth);
}
return 0;
}
}
查询结果显示如下:
三、可分页内存与页锁定内存
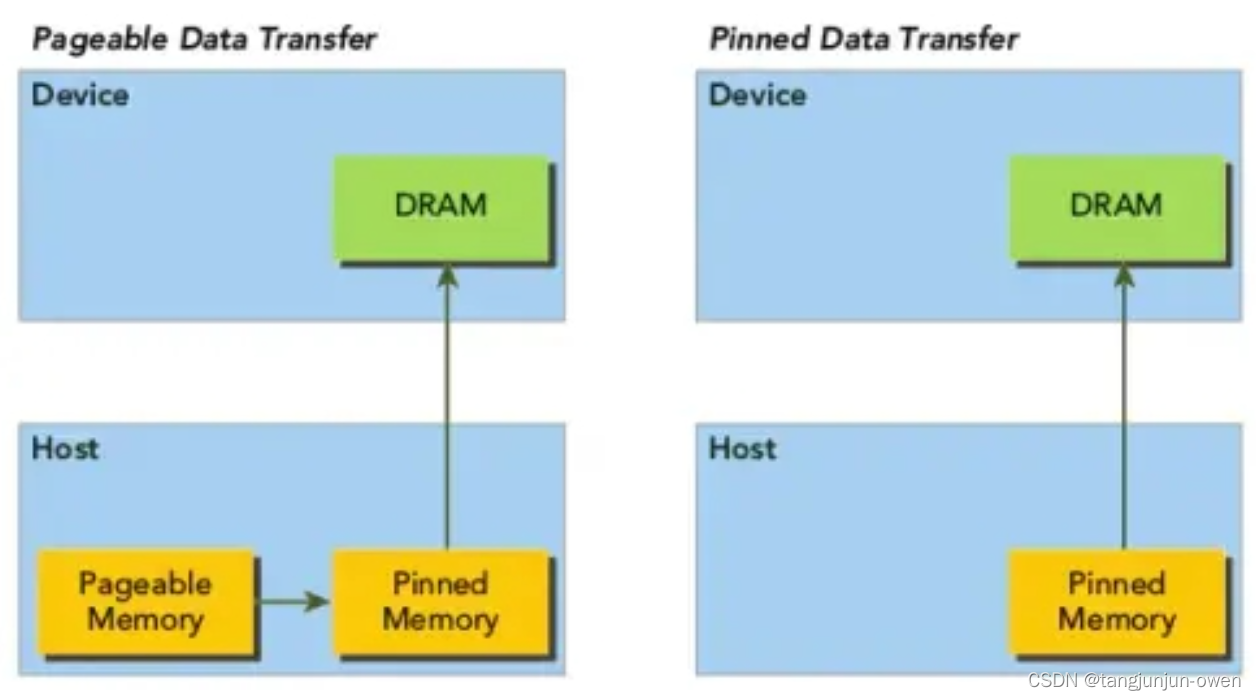
CPU内存,称之为Host Memory,逻辑上可分为Pageable Memory(可分页内存)、Page Lock Memory(页锁定内存),Page Lock Memory又称为Pinned Memory,从字面意思上而言Page Lock Memory是锁定的内存,一旦申请后就专供申请者使用,Pageable Memory则没有锁定特性,申请后可能会被交换。
总结如下:
①、pinned memory具有锁定特性,是稳定不会被交换的;
pageable memory没有锁定特性,对于第三方设备(比如GPU),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据;
②、pageable memory的性能比pinned memory差,很可能降低你程序的优先级然后把内存交换给别人用;
pageable memory策略使用内存假象,实际8GB但是可以使用15GB,可以提高程序运行数量,但运行速度会降低;
pinned memory太多,会导致操作系统整体性能降低,因为程序运行数量减少了;
③、GPU可以直接访问pinned memory而不能访问pageable memory(因为第二条)。
说明:当将pageable host Memory数据送到device时,CUDA驱动会首先分配一个临时的page-locked或者pinned host Memory,并将host的数据放到这个临时空间里。然后GPU从这个所谓的pinned Memory中获取数据,如下图所示:
四、cudaMallocHost 和 cudaMalloc(可分页内存与页锁定内存)
之前章节一直以实例介绍cuda代码编写,也对host与device端的变量进行了内存分配,并未重点说明cudaMallocHost 和 cudaMalloc的使用方法,我个人觉得很重要,对于不同设备的数据传输(如host与GPU间)均需要使用复制方法,而针对GPU内存分配与CPU数据间关系,需要我们有更深入了解,在此,我介绍重点介绍一下。
1、内存分配方式
以上介绍gpu如何访问cpu的内存方式。对于给GPU访问而言,距离计算单元越近,内存访问效率越高。为此,由低到高访问速度为:Pinned Memory < Global Memory < Shared Memory。
重点说明,GPU可以直接访问Pinned Memory,称之为DMA Direct Memory Access
接下来,我将介绍实际内存分配的几种方式:
Host端内存分配(Pageable Memory)
之前代码使用cudaMallocHost对内存分配,但也可使用new或malloc分配,而该分配属于Pageable Memory可分页内存。
其分配内存代码如下:
std::cout << "设置new(malloc)可分页内存" << std::endl;
float* memory_device = nullptr;
float* memory_host = new float[100]; // Pageable Memory
for (int i = 0; i < 100; i++) { memory_host[i] = i * 100; }
checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device
show_value << <dim3(1), dim3(100) >> > (memory_device);
以上直接使用CPU分配内存,然后使用cudaMemcpy复制给memory_device中,仍然可以实现,然这种效率较低。但切记,这种memory_host可以直接使用new赋值在核函数中使用。同时,这种速度较慢,不建议使用。
预测结果显示(仅显示前10个数)如下:
2、分配的内存类型
cudaMallocHost 分配的内存是页锁定内存,而 cudaMalloc 分配的内存是普通可分页内存。
3、内存的使用方式
cudaMallocHost 分配的内存可以通过主机和设备访问,而 cudaMalloc 分配的内存只能通过设备访问。
cudaMalloc分配内存方式为GPU的全局内存,代码如下:
std::cout << "设置全局内存" << std::endl;
float* memory_device = nullptr; // Global Memory
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device
以上代码实际在前面章节中已大量使用,实际作用为:使用cudaMalloc在gpu设备上分配一个全局内存空间,便于在kernel计算中存储数据。
cudaMallocHost分配内存方式,代码如下:
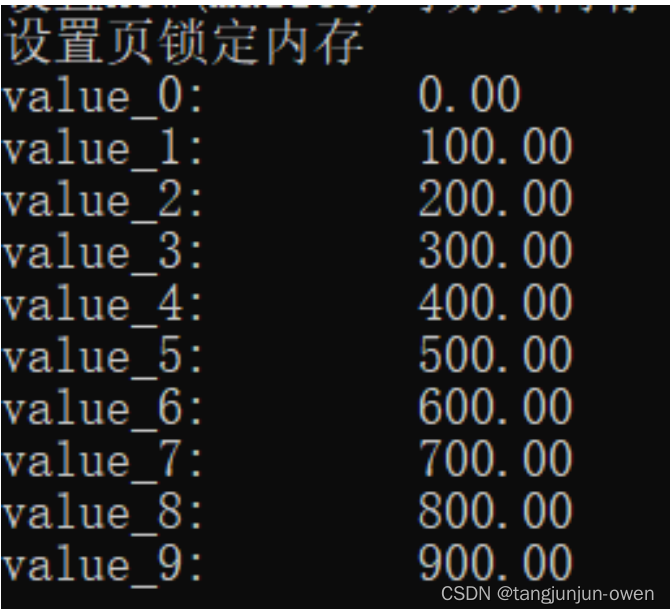
std::cout << "设置页锁定内存" << std::endl;
float* memory_device = nullptr;
float* memory_page_locked = nullptr; // Pinned Memory
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_locked
checkRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost)); // 将其返回host内存
以上代码实际在前面章节中已大量使用,实际作用也就是上面解释,即使用cudaMallocHost在gpu设备上分配内存,可使主机host和设备device均可访问,并使用cudaMemcpy赋值gpu数据。
4、内存的传输方式
由于 cudaMallocHost 分配的内存可以通过主机和设备访问,因此可以通过零拷贝技术(Zero-Copy)将数据直接从主机内存传输到设备内存,而 cudaMalloc 分配的内存则需要使用显式的数据传输函数(如 cudaMemcpy)进行传输。
5、性能
由于 cudaMallocHost 分配的内存是页锁定内存,因此可以避免在主机和设备之间进行数据传输时产生额外的复制操作,从而提高数据传输的性能。
6、总结
尽量多用Pinned Memory储存host端数据,或者显式处理Host到Device时用PinnedMemory做缓存,都是提高性能的关键。因此,如果需要在主机和设备之间进行频繁的数据传输,建议使用 cudaMallocHost 分配内存。如果只需要在设备上进行计算,并且不需要频繁地与主机进行数据交换,则可以使用 cudaMalloc 分配内存。
八、总结
以上为cuda内存应用与性能优化篇关于内存的相关知识和简单代码说明,旨在掌握在host端与device端间内存传输与分配相关原理,后面篇章将介绍如何定义常量内存、共享内存、纹理内存等相关方法,并附上相应代码。




![当执行汇编指令MOV [0001H] 01H时,CPU都做了什么?](https://img-blog.csdnimg.cn/8fba2176cb0b4130a5fb01c77bf402f2.png)