写在前面
本文看下MySQL的基础内容以及常见的优化方式。
1:MySQL基础内容
1.1:什么是关系型数据库
以二维的数据格式来存储数据的数据库叫做关系型数据库,其中关系包括一对一,一对多,多对多,都通过二位数据中的行与行关联来表达关系。
1.2:E-R图
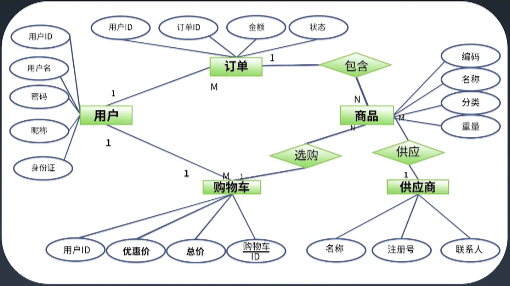
e的意思是entity,r的意思是relation,E-R图,即实体关系图,表达的是关系型数据库中的表之间的关系,一对一,一对多,多对多,如下图是一个电商系统中可能的关系图:
1.3:数据库范式
先来看一些重要的概念:
1.3.1:重要的概念
1.3.1.1:主键、候选键、超键
- 主键
能够唯一标识一行的键就叫做主键,比如如下的表:
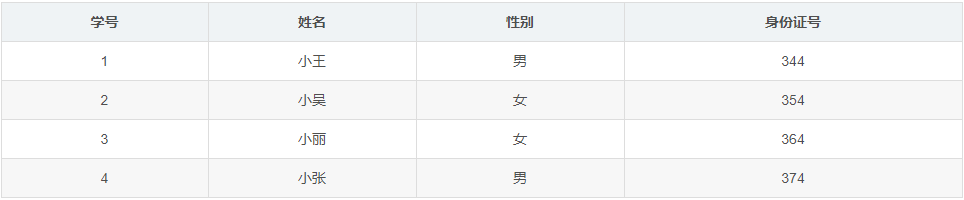
其中(学号),(身份证号),二者中的任何一个都能唯一的标识一行,因此二者中任何一个我们都叫做主键,但注意主键只能有一个。
- 候选键
能够作为主键的键和集合,我们叫做候选键,即候选键中的任何一个都可以作为主键,如下的表:
其中[(学号),(身份证号)]的集合就是这个表的候选键。
- 超键
在候选键中任意添加其他的列,构成的键就叫做超建,即包含了主键的键,如下表:
候选集为[(学号),(身份证号)],我们可以添加性别到学号,添加姓名到身份证号,变为如下:[(学号,性别),(身份证号,姓名)]。即超键肯定能作为主键(但不一定符合某些范式)。
1.3.1.2:函数依赖,部分依赖,传递依赖
- 函数依赖
一个或者是一组属性的值可以确定(推导出)其他属性的值,就叫做函数依赖,比如下表:
通过(学号)可以推导出姓名,就可以说姓名函数依赖于学号。
- 部分依赖
即通过主键中的部分属性就能推导出非主键属性,就叫做部分依赖,如下表:
如果使用(学号,姓名)作为主键,通过学号可以推导出姓名,就可以说姓名函数依赖于(学号,姓名),问题的本质是把超键当做主键来用了。
- 传递依赖
主属性A可以推导出非主属性B,而非主属性B又可以推到出非主属性C,则主属性A推导非主属性C的过程就叫做传递依赖,如下表:

比如我们使用(学号)作为主键,则存在学号->班级编号->院系,这里学号对院系就是传递依赖。
1.3.2:五种数据库范式
范式类似于设计模式 ,都是一种经验,可以直到我们更好的设计数据库,范式的英文是Normal Form,简称NF,范式有如下的6种:
1:1NF
第一范式
2:2NF
第二范式
3:3NF
第三范式
4:BCNF
BC范式,因为介于3NF和4NF之间,所以有时也叫做3.5NF
5:4NF
第四范式
6:5NF
第五范式
1.3.2.1:1NF
数据库第一范式,定义为,对于关系R,当且仅当关系R的每个属性的值域只包含原子项,接下来用人话翻译一遍,就是,对于一张表R,表R的每个列的值都不可再分,如下表:
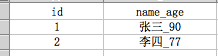
其中name_age列就是可以在分为name和age的,因此并不是原子项,不符合第一范式,如果修改为如下,则符合第一范式:
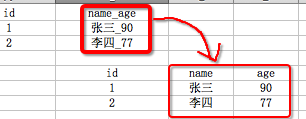
1.3.2.2:2NF
在满足第一范式的基础上,不存在部分函数依赖,即消除非主属性对主属性的部分函数依赖,如下表:
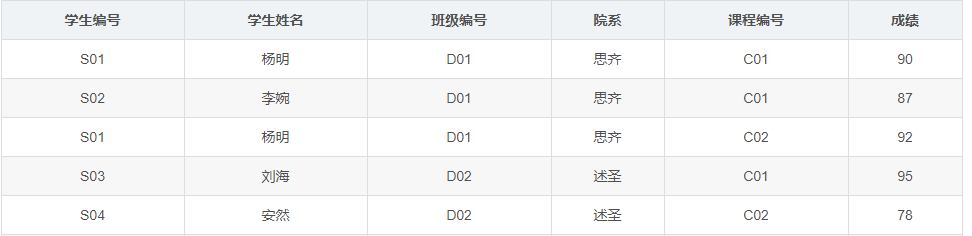
主键为(学生编号,课程编号),但是存在通过学生编号就可以推导出学生姓名的情况,即存在部分函数依赖,所以不满足第二范式,因此将该表拆分为如下的两个表就可以满足第二范式了:
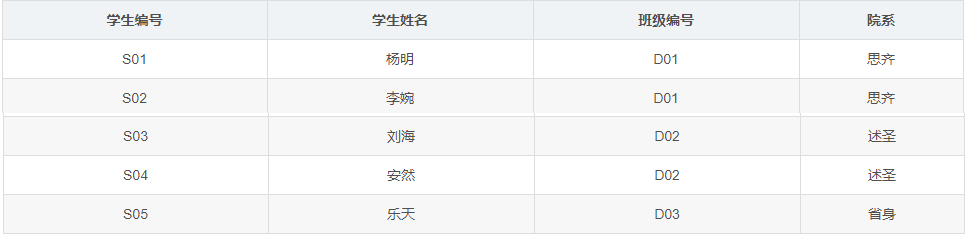
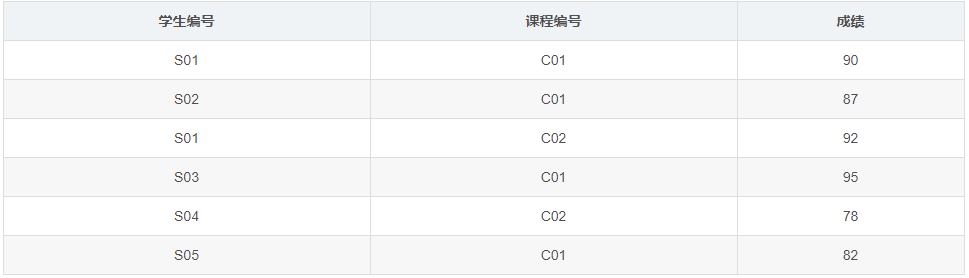
1.3.2.3:3NF
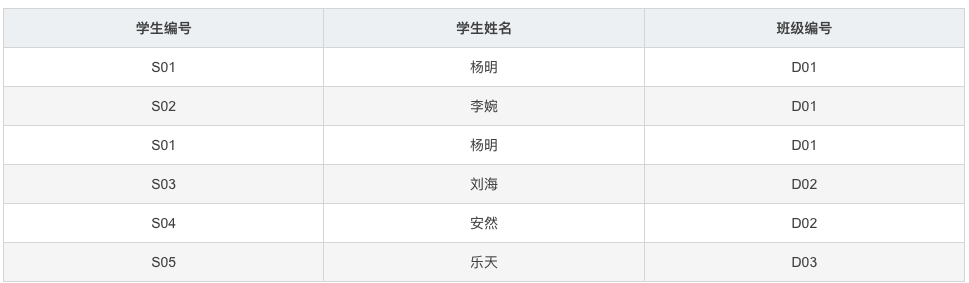
在满足第二范式的基础上,消除传递函数依赖,如下表:
主键是(学生编号),虽然其能够决定院系,但并非直接决定,而是通过学生编号->班级编号->院系,即是通过传递函数依赖确定的,因此此时是不符合第三范式的,可修改为如下表结构:

1.3.2.4:BCNF
只有存在联合主键的时候才可能存在不满足BCNF的情况。
在满足第三范式的基础上,消除主属性对于码的传递函数依赖和部分函数依赖。来看个例子,假定某物流公司有很多仓库,每个仓库都有一个仓库管理员,每个仓库都可以存放多种物品,每种物品都有数量,设计出来后如下表:
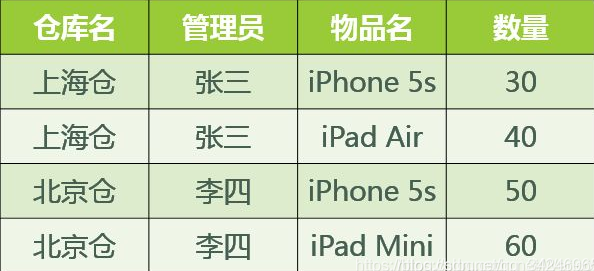
此时码(即联合主键)是(仓库名,管理员,物品名),存在如下的问题:

此时会出现的问题是,如果我们有新的仓库,比如火星仓,则必须在配备了管理员,准备了物品后,才能创建该仓库,这明显是不能满足业务的使用的,删除也是同样的道理,现在某个管理员离职,更换其他管理员,更新的成本也很高,可以修改为如下的表,使其符合BCNF:
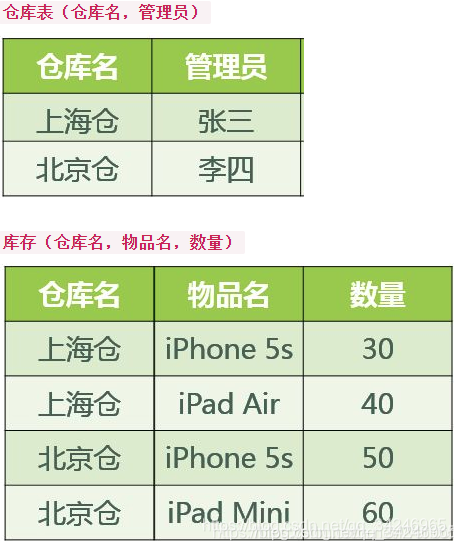
1.3.2.5:4NF
在满足3NF的基础上,消除表内的多对多关系,如下表:
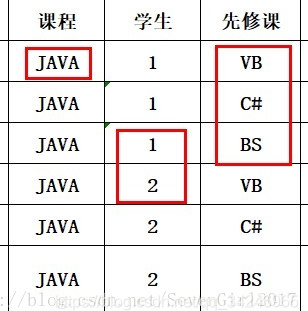
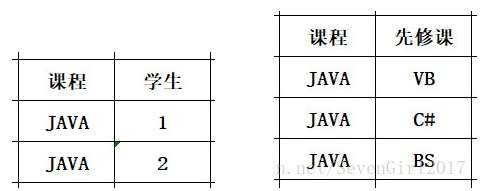
课程->学生和课程->先修课,都是1:n的关系,因此表的数据冗余度将会非常高,可修改为如下:
1.3.2.6:5NF
TODO
1.4:SQL语言
1.4.1:简介
全称是structure query language,即结构化查询语言,是一种用来操作关系型数据库的语言,在1970年由boyce和chanberlin提出(也就是BCNF中的BC),sql根据执行的操作不同可以分为如下的几种:
DQL:
data query language,数据查询语言,或“数据检索语句”,即select ...。用来查询数据。
DML:
data monipulation[məˌnɪpjʊˈleɪʃ(ə)n] language,数据操纵语言,如insert,update,delete。用来增删改查数据。
DDL:
data definition language,数据定义语言,如create table,drop table,alter table等。用来创建表和修改表结构。
TCL:
transaction control language,事务控制语言,如start transaction,begin,commit,savepoint,rollback等。用来通过事务控制数据的增删改成功。
DCL:
data control language,数据控制语言,如grant,revoke等。用来控制用户对库表,以及各种增删改查等操作的权限。
前两种使用的最多的,因为我们的程序就是在查询和修改数据,第三种也会用到,但没那么多了。
1.4.2:历史
在1986年有了第一个版本,SQL-86,最后一个版本是在2011年,SQL:2011,具体如下图:
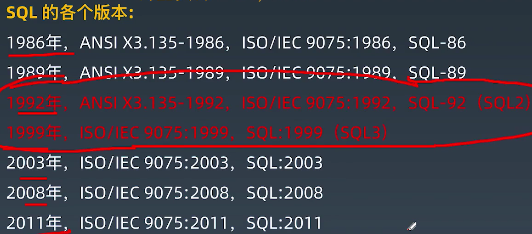
其中目前使用最多的还是1992年的SQL2和1999年的SQL3。
1.5:MySQL数据库历史
monty是MySQL的开发,第一行代码就由其编写(据说第一行代码,其实是一行注释,可见注释还是重要啊!!!),之后monty和朋友合伙创建了MySQL AB公司,接着在2008年sun公司以10亿美元收购了MySQL AB公司,但monty并未随之进入sun公司,而是单起炉灶成立了另外一家公司,之后在2009年Oracle以74亿美元收购了sun公司(有没有一种大鱼吃小鱼,小鱼吃虾米的感觉)。MySQL创世人monty担心Oracle公司将MySQL商业化,闭源,就有基于MySQL拉了另一个分支,开发了mariaDB,如下图:

MySQL的my是monty和首任妻子所生大闺女的名字,mariaDB是monty和二婚妻子所生二闺女的名字,看来不管是中国人还是老外,还真都是女儿奴啊!!!
接着我们来看下MySQL本身的发展历史。
4.0
在该版本中通过innodb支持了事务
5.0(2003年)
5.6
5.7
8.0
8.0版本相对于5.7版本发生了非常大的变化,所以直接叫做8.0版本了,按照官方的计划,是大力发展该版本,并使该版本成为时长的主流,但事与愿违,因为8.0版本的变化是在是太大,迁移的成本太高,所以用户量一直也没有太大的升高,反而,用户不断的将版本升级为5.7版本,因此当前5.7版本是最主流的MySQL版本,如果有一个新业务,也可以考虑使用该版本,那么每个版本都有哪些更新呢,也来看下:
5.7:
增加json处理功能
mgr(mysql group replication) 一种基于paxos协议的分布式解决方案
分区表
修复XA问题
8.0
json增强,优化json处理的性能
自增列持久化
utf8mb4为默认编码
8以前的版本,默认编码是utf-8,但其utf-8是假u8很多,因为很多编码都不支持,而真正的u8编码是utf8mb4,所以8默认的编码是真正的u8编码了。
2:优化
2.1:参数优化
2.1.1:连接请求变量
- max_connections
尽量不让达到最大连接。
最大连接数,最大值16384,可适当调大该值,最优值为达到85%的使用量,即max_used_connection/max_connnects约等于85%最好。
当连接数达到max_connections时,用来等待可用连接时存放的临时区域,一般设置为3000左右。
- wait_timeout/interactive_timeout
设置客户端超时,分别用户非交互式(jdbc)和交互式(mysql cli)连接超时时长。超过会断开连接,默认是8个小时,一般不需要修改。
2.1.2:缓冲区变量
- key_buffer_size
设置myisam存储引擎存储索引的缓存大小。虽然当前一般都是使用的innodb存储引擎,但还存在临时磁盘表的情况,但需要的内存不多,一般设置为32M左右即可。 - sort_buffer_size
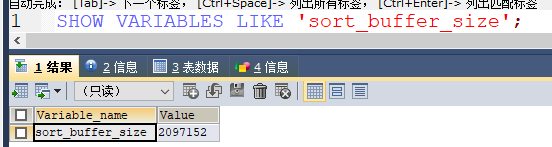
执行排序的内存大小,需要设置合理大小,避免发生基于磁盘文件排序,发生IO,降低效率,一般设置为2M左右即可,如下rds配置:
- query_cache_size
查询缓存大小,如果是读多写少的场景可以考虑设置,但是一般都是关闭的,因为维护缓存的成本比较高,单个表改变,将会导致相关的所有的缓存全部失效,如下rds配置:
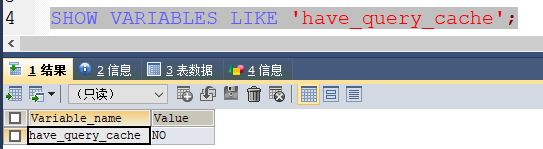
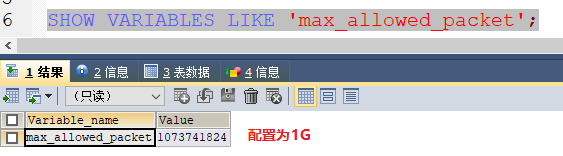
- max_allowed_packet
允许的最大包大小,一般给个较大个值即可,避免出现比较大的sql时无法执行,如500M,1G这种,如下rds配置:
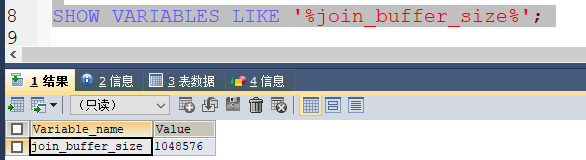
- join_buffer_size
执行表连接的缓存大小,设置一个合理的值,可以加快表连接的效率,一般设置为1M左右即可,如下rds而配置:
- thread_cache_size
线程缓存大小,提高线程的复用率,减少线程的重复创建,提高效率。
2.1.3:innodb相关变量
因为innodb比较重要,目前用的最多,所以单独看下其相关的变量。
- innodb_buffer_pool_size
设置索引内存缓存的大小,因为innodb数据就是存储在索引上的,所以一般该值可以设置的较大,总内存的80%左右即可。 - innodb_flush_log_at_trx_commit
该参数用来控制修改写入到redo log的策略,修改最终写入到磁盘需要经过redo log buffer->page cache->redo log磁盘文件,如下图:
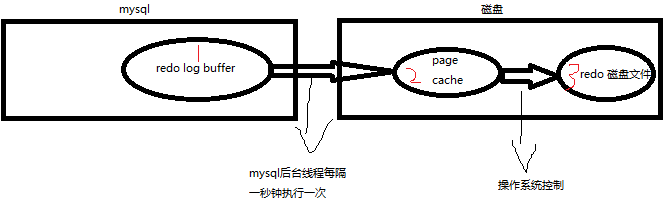
该参数可能的取值有如下三个:
0:每次只写到redo log buffer中,此时如果数据库异常重启将会导致数据丢失,因为后台线程刷盘每一秒钟执行一次,所以最多会有一秒钟的数据丢失,不建议设置该值。
1:每次都会将数据写到redo log磁盘文件中,这种方式可以保证数据不丢失,但是每次事务提交都要发生磁盘IO,所以性能不会很好,如果你的系统压力不是特别大,建议设置该值,否则不建议设置。
2:每次都会将数据写到page cache中,此时数据已经写到操作系统的缓存中,所以MySQL服务器本身的异常重启,不会丢失数据,但是如果是机器掉电,还是会丢失数据,但掉电概率相对较低,如果是对性能要求较高,可以考虑该值
总结如图:

一般情况下,数据安全才是第一位的,所以该值一般设置为1,如下是我司线上环境rds配置:
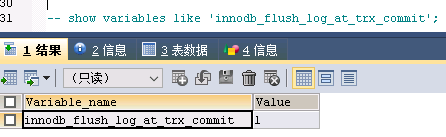
当然如果经过业务的分析,允许少量数据丢失的话,并且对性能要求比较高可以考虑将该值设置为2,但是不建议设置为0,因为丢失数据的风险太高了,且0在性能表现上并不比2好太多。
- innodb_thread_concurrent
限制并发执行查询的线程的数据量,当事务处于空闲时,以及处于锁等待时,对应的线程是不占用innodb_thread_concurrent的,比如某一时刻执行了一个事务,当该事务执行查询是innodb_thread_concurrent=1,当该事务空闲,或者是因为被其他事务的行锁阻塞时,innodb_thread_concurrent会减1,变为0,即innodb_thread_concurrent只有正在消耗CPU资源的线程才做基数,如下:
时刻1:事务A开始并执行一个查询,开始消耗CPU资源,innodb_thread_concurrent变为1
时刻2:在事务A的查询结束前事务B开始,并执行一个查询,开始消耗CPU资源,innodb_thread_concurrent+1变为2
时刻3:事务A查询依然没有结束,事务B被事务A的间隙锁阻塞等待,因为此时事务B不在消耗CPU资源,所以innodb_thread_concurrent-1,变为1
时刻4:事务A结束,innodb_thread_concurrent-1变为0
时刻5:事务B结束锁等待,开始执行查询,开始消耗CPU资源,innodb_thread_concurrent+1变为1
时刻6:事务B结束,innodb_thread_concurrent-1变为0
最后再看一个设置innodb_thread_concurrent为3,阻塞主第四个事务查询的例子,如下图:
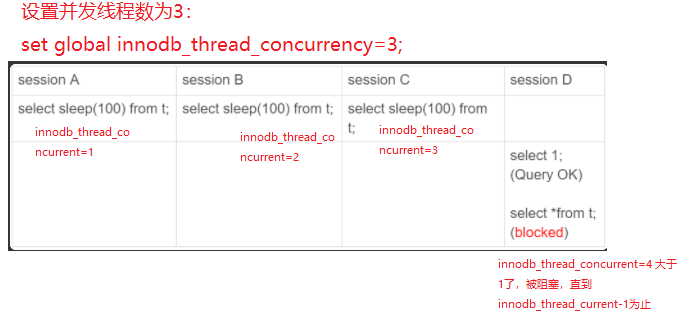
实践上,不建议将该值设置为0,此时不限制线程数,可能会导致过多的线程,而导致严重上下文切换,引起性能问题,一般建议设置在64~128之间,具体的值可以根据具体压测的情况来确定。
注意的就是:如果一个线程某个时刻不占用CPU资源,则不占用innodb_thread_concurrent的计数。
- innodb_log_buffer_size
设置innodb日志缓冲区的大小,合理的设置该值可以有效的减少写redo带来的磁盘IO开销,一般建议设置不要超过64M(MySQL本身的限制),如下是我司设置的为8M:
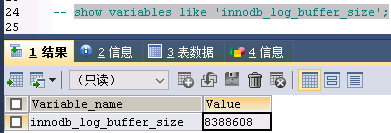
如下是极客时间AI给出的答案,很全面,也截图放在这里:

- innodb_log_file_size
设置日志文件大小,即redo log单个文件的大小,可以根据情况设置为一个较大的值,官方建议为总内存的1/2到1/4,同时需要注意,不要随意修改该值,因为修改该值需要删除老的logfile,并且需要重启服务器,还存在数据丢失的风险,如下是极客时间给出的答案:

- innodb_log_files_in_group
设置redo log文件的个数,默认值为2,innodb_log_files_in_group*inndb_log_file_size的值就是redo log文件的总大小。一般建议设置1到4个,正常使用默认值即可。设置为2的好处是可以分离插入数据的操作和更新删除数据的操作,提高并发性能。如下是极客时间AI给出的答案:

- read_buffer_size
查询操作从磁盘读取数据发送给客户端的缓冲区大小,如果是查询数据量较大可以考虑设置512k,1M这类比较大的值,如果是查询数据量不大可设置较小值,注意该值不可设置过大,避免内存占用过大影响其他的操作,以及增大响应客户端的延迟。 - read_rnd_buffer_size
read_rnd_buffer_size,用于设置read rdn buffer的大小,read rnd buffer是MRR 优化用到的缓冲区,该缓冲区用于对将要访问索引的一组数据进行排序,进而能够尽量的顺序读盘,提升性能,该值一般给1M即可,也可以根据具体情况调整该值,但不可设置过大,影响其他操作。 - bulk_insert_buffer_size
临时存储大量插入数据的内存区域,该值默认是16M,如果是有大量的输入插入可适当的调大该值,如64M。
2.1.4:表设计相关优化
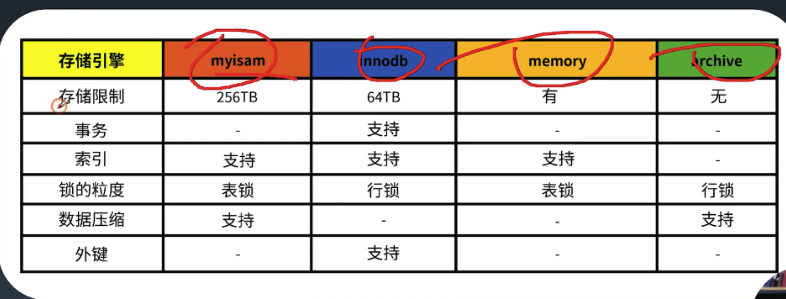
- 存储引擎选择
常用的存储引擎有innodb。myisam,memory,archive,比如如下:
- 字段类型
使用尽量小的字段类型,减少存储,内存成本,提高网络传输效率,进而提高数据查询的速度。云厂商数据库1G每年的存储成本大概是10元人民币,所以,不必要的过大数据类型也会带来不必要的成本支出。
你设计的数据不仅仅存储在你的业务数据库,还有有多个slave,数据还可能同步到大数据部门进行,所以这个数据影响的范围会进一步增大。
- 外键
不要使用外键,而由业务控制表关系。 - 触发器
不要使用触发器,降低不必要的性能开销。 - 文件,图片存储
不要直接存储文件,图片数据本身,因为数据较大,存储成本高,而是将文件,图片存储到文件服务器,数据库只存储文件服务器的标识即可。 - 索引创建
不能滥用索引,例如某联合索引包含某单个索引,则可删除单个索引,降低磁盘占用,以及数据变更对索引的维护成本。
写在后面
参考文章列表
让人敬佩的白发程序员——MySQL/MariaDB之父Monty阿里交流会 。
范式通俗理解:1NF、2NF、3NF和BNCF 。
数据库范式详细介绍(1NF,2NF,3NF,BCNF,4NF) 。
MySQL历史,名称由来及版本 。
23 | MySQL是怎么保证数据不丢的? 。
29 | 如何判断一个数据库是不是出问题了? 。
35 | join语句怎么优化? 。