初学者总是喜欢自己吓自己,在听到缓存击穿、缓存穿透、缓存雪崩等问题后,就觉得这根本不是自己这个级别所能接触的知识点,甚至不敢下定决心去了解。
然而,缓存击穿、缓存穿透、缓存雪崩等概念只是听着高大上罢了,实则并没有你想想的那么难以理解。
缓存
缓存:大多数情况下,加缓存的目的是为了:减轻数据库的压力,提高系统性能。

缓存用的好,到来的性能提升是非常明显的。但如果用不好,比如出现下面两种情况,甚至可能造成系统服务器挂机。
-
用户请求的 key 在缓存中不存在 (有可能时请求的 key 过期了)。
-
恶意用户伪造不存在的 key 发起请求。
缓存穿透
缓存穿透:缓存 和 数据库中都没有请求查询的数据,每次从缓存中都查不到数据,请求转发到数据库上,同时在数据库中也查询不到该数据,查不到数据则不写入缓存。这就导致每次请求这个不存在的数据时,都要到数据库中查询,缓存根本没有起到作用,好像被穿透了一样。每次都会去访问数据库,这就是我们所说的缓存穿透问题。

缓存穿透带来的问题:
如果穿透了缓存,如果是在洪峰流量下,全部的请求都会转发到数据库中,从而导致数据库压力过大,甚至可能会因为扛不住压力而挂掉。
解决方案:
-
使用布隆过滤器:如果数据比较少,可以将数据库中的数据,全部放到内存中的一个Map中,这样就可以快速识别数据在缓存中是否存在。如果存在,则请求查询缓存。如果不存在,则直接拒绝该请求。但如果数据量太多了,有数千万或者上亿的数据,全都放到内存中,会占用太多的内存空间。 如何使用少量的内存来达到这种效果呢 ??? - - - > 布隆过滤器(Bloom Filter)就应运而生。
-
加互斥锁:缓存不存在时,先去获取锁,得到锁后,再去请求数据库。没有得到锁,则休眠一段时间后重试。
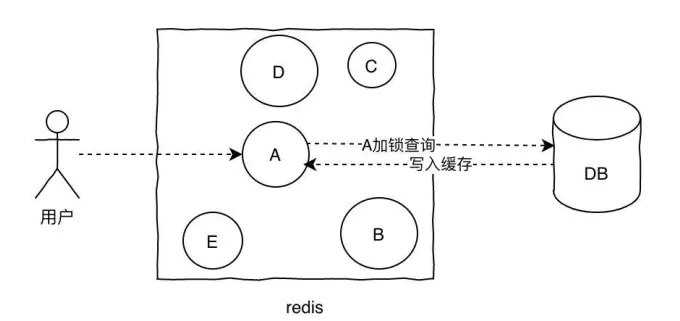
-
缓存空对象:从缓存和数据库中都查不到数据时,将这个 key 的 value 值设置为 null,并设置较短的过期时间 (设置过期时间太长会导致正常情况也没法使用),一般不超过5分钟,30秒为宜。
redisTemplate.opsForValue().set(key, null, 30, TimeUnit.SECONDS);
缓存击穿
缓存击穿:缓存击穿是指缓存中没有数据 (一般是 key 过期了),但数据库中有该数据。在洪峰流量下,同时查询缓存没有查询到数据,请求全部打到数据库上,导致数据库压力过大,大量请求堆积。

解决方案:
-
设置热点 key 永不过期
-
加互斥锁:缓存不存在时,先去获取锁,得到锁后,再去请求数据库。没有得到锁,则休眠一段时间后重试。
缓存雪崩
缓存雪崩:在洪峰流量下,大量 key 集中在一段时间内过期失效,所有查询请求都打到数据库上,造成了缓存雪崩。
- 与缓存击穿的区别是:缓存击穿是因为一个热点 key 过期失效导致的情况,而缓存雪崩是指缓存中大批量的数据同时过期,巨量请求直接落在数据库中,引起数据库压力过大甚至宕机。
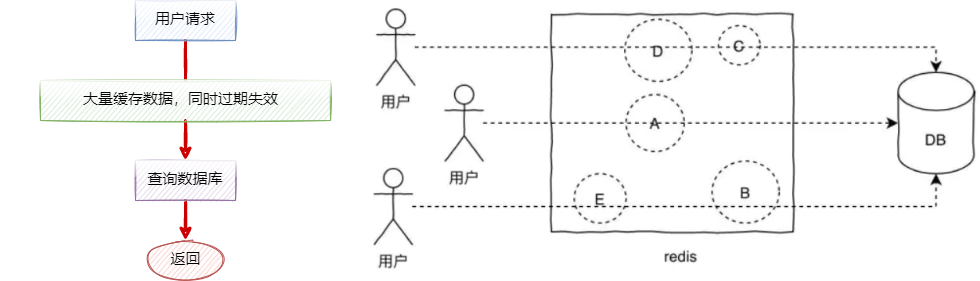
解决方案:
-
加互斥锁:缓存不存在时,先去获取锁,得到锁后,再去请求数据库查询数据,并写入缓存。没有得到锁,则休眠一段时间后重试。
-
数据预热:通过缓存 reload 重加载机制,预先更新缓存,再即将发生高并发访问前,手动触发加载缓存不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
-
做二级缓存 / 双缓存策略:Cache1为原始缓存,Cache2为拷贝缓存。Cache1失效时可以访问Cache2。Cache1缓存过期时间设置为短期,Cache2设置为长期。
-
过期时间加随机值:在缓存的时候,给过期时间加上一个随机值,这样就可以大幅度减少缓存在同一时间过期。
redisTemplate.opsForValue().set(Key, value, time + Math.random() * 1000, TimeUnit.SECONDS); -
设置热点 key 永不过期:(热点 key 就是最常被请求查询,且请求数量非常大的 key)





![[附源码]Node.js计算机毕业设计电子购物商城Express](https://img-blog.csdnimg.cn/2d82967ef9b444ff95f354b9a19fb367.png)
![[附源码]计算机毕业设计电商小程序Springboot程序](https://img-blog.csdnimg.cn/dba09e01e9ae47a2bc1e8c01bd30bdcc.png)