深度学习(37)—— 图神经网络GNN(2)
这一期主要是一些简单示例,针对不同的情况,使用的数据都是torch_geometric的内置数据集
文章目录
- 深度学习(37)—— 图神经网络GNN(2)
- 1. 一个graph对节点分类
- 2. 多个graph对图分类
- 3.Cluster-GCN:当遇到数据很大的图
1. 一个graph对节点分类
from torch_geometric.datasets import Planetoid # 下载数据集用的
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.nn import GCNConv
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import torch
from torch.nn import Linear
import torch.nn.functional as F
# 可视化部分
def visualize(h, color):
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())
plt.figure(figsize=(10, 10))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")
plt.show()
# 加载数据
dataset = Planetoid(root='data/Planetoid', name='Cora', transform=NormalizeFeatures()) # transform预处理
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print()
print(data)
print('===========================================================================================================')
# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')
# 网络定义
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
torch.manual_seed(1234567)
self.conv1 = GCNConv(dataset.num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GCN(hidden_channels=16)
print(model)
# 训练模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
for epoch in range(1, 101):
loss = train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)
2. 多个graph对图分类
- 图也可以进行batch,做法和图像以及文本的batch是一样的
- 和对一张图中的节点分类不同的是:多了聚合操作
将各个节点特征汇总成全局特征,将其作为整个图的编码
import torch
from torch_geometric.datasets import TUDataset # 分子数据集:https://chrsmrrs.github.io/datasets/
from torch_geometric.loader import DataLoader
from torch.nn import Linear
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.nn import global_mean_pool
# 加载数据
dataset = TUDataset(root='data/TUDataset', name='MUTAG')
print(f'Dataset: {dataset}:')
print('====================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print(data)
print('=============================================================')
# Gather some statistics about the first graph.
# print(f'Number of nodes: {data.num_nodes}')
# print(f'Number of edges: {data.num_edges}')
# print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
# print(f'Has isolated nodes: {data.has_isolated_nodes()}')
# print(f'Has self-loops: {data.has_self_loops()}')
# print(f'Is undirected: {data.is_undirected()}')
train_dataset = dataset
print(f'Number of training graphs: {len(train_dataset)}')
# 数据用dataloader加载
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
for step, data in enumerate(train_loader):
print(f'Step {step + 1}:')
print('=======')
print(f'Number of graphs in the current batch: {data.num_graphs}')
print(data)
print()
# 模型定义
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super(GCN, self).__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, hidden_channels)
self.conv3 = GCNConv(hidden_channels, hidden_channels)
self.lin = Linear(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index, batch):
# 1.对各节点进行编码
x = self.conv1(x, edge_index)
x = x.relu()
x = self.conv2(x, edge_index)
x = x.relu()
x = self.conv3(x, edge_index)
# 2. 平均操作
x = global_mean_pool(x, batch) # [batch_size, hidden_channels]
# 3. 输出
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin(x)
return x
model = GCN(hidden_channels=64)
print(model)
# 训练
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
for data in train_loader: # Iterate in batches over the training dataset.
out = model(data.x, data.edge_index, data.batch) # Perform a single forward pass.
loss = criterion(out, data.y) # Compute the loss.
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
optimizer.zero_grad() # Clear gradients.
def test(loader):
model.eval()
correct = 0
for data in loader: # Iterate in batches over the training/test dataset.
out = model(data.x, data.edge_index, data.batch)
pred = out.argmax(dim=1) # Use the class with highest probability.
correct += int((pred == data.y).sum()) # Check against ground-truth labels.
return correct / len(loader.dataset) # Derive ratio of correct predictions.
for epoch in range(1, 3):
train()
train_acc = test(train_loader)
print(f'Epoch: {epoch:03d}, Train Acc: {train_acc:.4f}')
3.Cluster-GCN:当遇到数据很大的图
- 传统的GCN,层数越多,计算越大
- 针对每个cluster进行GCN计算之后更新,数据量会小很多
但是存在问题:如果将一个大图聚类成多个小图,最大的问题是如何丢失这些子图之间的连接关系?——在每个batch中随机将batch里随机n个子图连接起来再计算
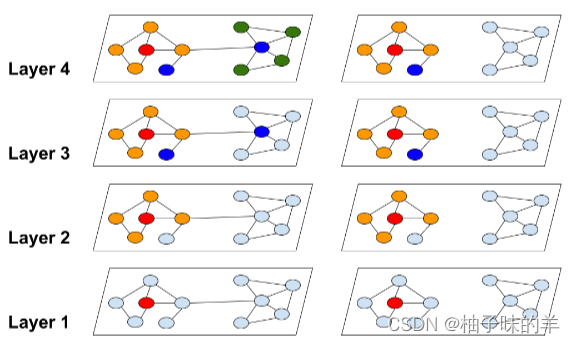
-
使用
torch_geometric的内置方法- 首先使用cluster方法分区
- 之后使用clusterloader构建batch
【即】分区后对每个区域进行batch的分配
# 遇到特别大的图该怎么办?
# 图中点和边的个数都非常大的时候会遇到什么问题呢?
# 当层数较多时,显存不够
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
from torch_geometric.loader import ClusterData, ClusterLoader
dataset = Planetoid(root='data/Planetoid', name='PubMed', transform=NormalizeFeatures())
print(f'Dataset: {dataset}:')
print('==================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print(data)
print('===============================================================================================================')
# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.3f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')
# 数据分区构建batch,构建好batch,1个epoch中有4个batch
torch.manual_seed(12345)
cluster_data = ClusterData(data, num_parts=128) # 1. 分区
train_loader = ClusterLoader(cluster_data, batch_size=32, shuffle=True) # 2. 构建batch.
total_num_nodes = 0
for step, sub_data in enumerate(train_loader):
print(f'Step {step + 1}:')
print('=======')
print(f'Number of nodes in the current batch: {sub_data.num_nodes}')
print(sub_data)
print()
total_num_nodes += sub_data.num_nodes
print(f'Iterated over {total_num_nodes} of {data.num_nodes} nodes!')
# 模型定义
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super(GCN, self).__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GCN(hidden_channels=16)
print(model)
# 训练模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
for sub_data in train_loader:
out = model(sub_data.x, sub_data.edge_index)
loss = criterion(out[sub_data.train_mask], sub_data.y[sub_data.train_mask])
loss.backward()
optimizer.step()
optimizer.zero_grad()
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
accs = []
for mask in [data.train_mask, data.val_mask, data.test_mask]:
correct = pred[mask] == data.y[mask]
accs.append(int(correct.sum()) / int(mask.sum()))
return accs
for epoch in range(1, 51):
loss = train()
train_acc, val_acc, test_acc = test()
print(f'Epoch: {epoch:03d}, Train: {train_acc:.4f}, Val Acc: {val_acc:.4f}, Test Acc: {test_acc:.4f}')
这个还是很基础的一些,下一篇会说如何定义自己的数据。还有进阶版的案例。
所有项目代码已经放在github上了,欢迎造访