传送门
分布式定时任务系列1:XXL-job安装
分布式定时任务系列2:XXL-job使用
分布式定时任务系列3:任务执行引擎设计
分布式定时任务系列4:任务执行引擎设计续
Java并发编程实战1:java中的阻塞队列
引子
这篇文章的主要目不是讨论XXL-job的使用,而是要通过它的任务线程实现机制来分析java中阻塞队列的应用!
而这一切要从上周某天,公司一个普通的下午说起。
当时一个同事要添加任务,就随口问了一句:“阻塞处理策略选啥?”,我心里一惊,以前没注意过这个地方,每次都是默认的,也就是单机串行。
就是下图这个:
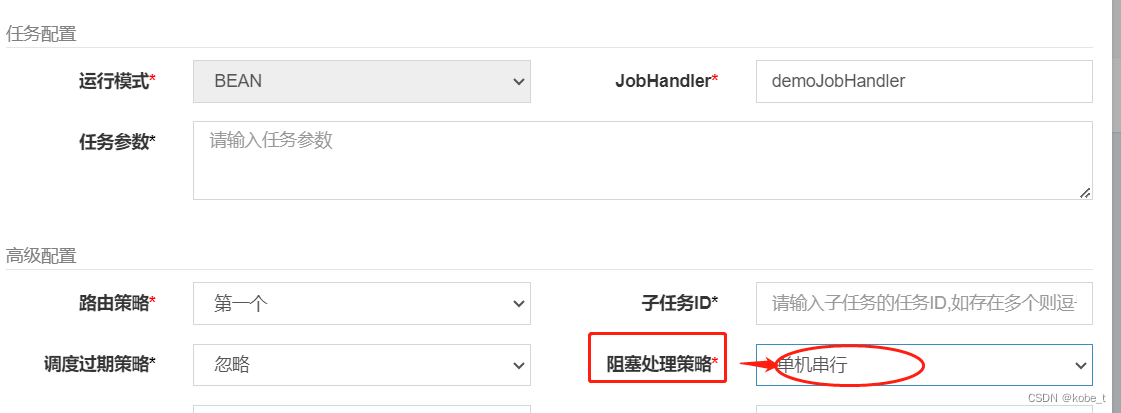
这里面有3个选项:
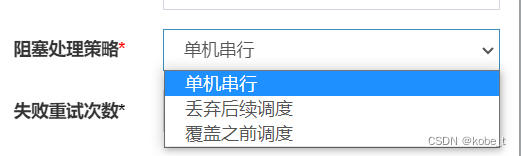
众人先是侃侃讨论了半天,后面再去翻了源码来查看,发现了下面的blockingQueue

阻塞队列
什么是阻塞队列
关于java阻塞队列,可以看看java中的阻塞队列。里面例子用到的是有界队列ArrayBlockingQueue,XXL-job里面用的是无界队列LinkedBlockingQueue。不论它们的相似及区别点,最重要的都是拥有阻塞特性。
要分析XXL-job是怎么使用阻塞队列的,就从XXL-job的调度触发机制入手!