机器学习——01基础知识
github地址:https://github.com/yijunquan-afk/machine-learning
参考资料
[1] 庞善民.西安交通大学机器学习导论2022春PPT
[2] 周志华. 机器学习.北京:清华大学出版社,2016
[3] AIlearning
一、机器学习算法的应用
目前,机器学习算法在自然语言处理、无人驾驶、复杂病情诊断还没有超越人类。棋牌、语音识别、人脸识别已经超越了人类
深度学习神经网络并不是人工智能的终极解决方案
数据驱动,需要大量训练样本才能达到满意精度
无法自适应环境与任务变化
一种算法只做一件事,无法做到多面手
需要大量手工调试与试错
成本高
鲁棒性较差
二、什么是机器学习算法
定义:Machine learning, a branch of artificial intelligence, is about the construction and study of systems that can learn from data
机器学习是人工智能的一个分支,是关于构建和研究可以从数据中学习的系统
机器学习算法的一般应用框架
1️⃣ 定义需要实现的功能。
2️⃣ 采集足够多的正例与负例样本: T = { x i , y i } I N T=\{x_i,y_i\}_I^N T={xi,yi}IN
3️⃣ 利用训练样本 T = { x i , y i } I N T=\{x_i,y_i\}_I^N T={xi,yi}IN 通过迭代训练,得到模型
y = f ( x , Θ ) y=f(x,\Theta) y=f(x,Θ)
4️⃣ 如果标签y∈{-1, +1}是离散的,这就是一个分类问题;如果y,是连续的,这就是一个回归问题
模型:模型是用来描述某个特定现象或事务的
归纳模型:由一个数学公式构成,每个变量都有明确物理意义
预测模型:由一个万能函数构成,每个参数一般不具备任何物理意义,一般只能模拟或预测目标系统的输出
直推模型:没有明确的模型或函数,但是可计算出模型在特定点的值
每个数据都是对目标世界的取样,当所在世界的取样足够全面和密集时,就获得了对这个世界的完整描述
Inductive inference
归纳模型Predictive inference
预期模型Transdictive inference
直推模型目标 发现事物的真正规律 发现预测规则 评估未知预测函数在某些点的值 复杂度 比较困难 相对容易 最容易 适用性 少数变量就能描述的简单世界 需要多个变量描述的复杂世界 需要多个变量描述的复杂世界 计算成本 低 高 最高 泛化能力 低 高 最高
传统机器学习和深度学习的比较
本质完全相同:都是利用一个万能函数拟合训练样本
区别在于:深度学习神经网络是拥有极高自由度的万能函数,能够很好地拟合任意复杂度的分布。
深度学习关键词:数据驱动,越多的数据做训练,就能达到越高的精度
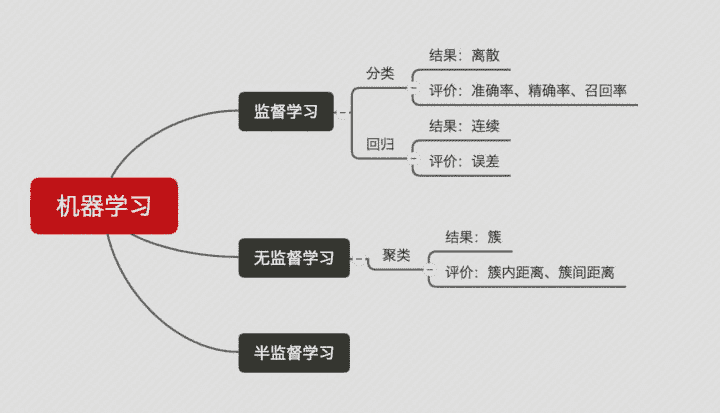
三、机器学习算法的分类
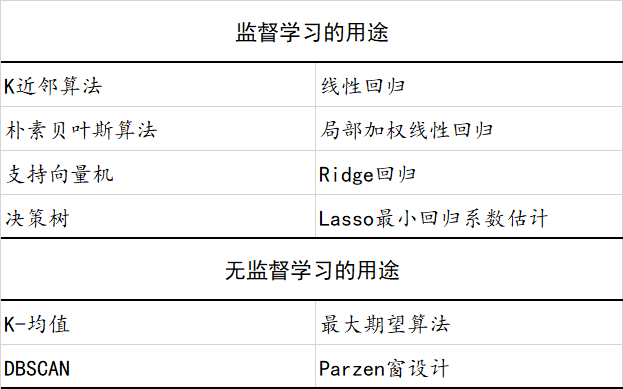
🏷 非监督学习与监督学习
非监督学习:不需要训练样本的机器学习算法,如数据聚类算法。
监督学习:需要训练样本的机器学习算法,如大多数分类、回归算法。
🏷 生成模型与判别模型(generative vs. discriminative)
生成模型计算数据x与标签y的联合概率P(x,y),用下列公式计算分类概率:P(y|x) = P(x,y)/P(x)
K-means
判别模型直接计算分类概率P(y|x)
GMM
🏷 简单数据模型与复杂数据模型
简单数据模型:被用来处理相互独立的简单数据
复杂数据模型:被用来处理具有时空关联性的复杂数据:语音识别
四、机器学习算法的重要构成要素
三个重要方面
1️⃣ Structural model:我们选择哪一类函数 f ( x , Θ ) f(x, \Theta) f(x,Θ)来建立模型?
2️⃣ Error model:我们选择哪一类损失函数(lossfunction) L ( y , f ( x , Θ ) ) L(y,f(x,\Theta)) L(y,f(x,Θ))来做训练?损失函数相当于为模型的选择制定考核标准。
3️⃣ Optimization procedure:我们选择哪一种数值计算方法来获取最优模型 f ∗ ( x , Θ ) f^*(x,\Theta) f∗(x,Θ)?
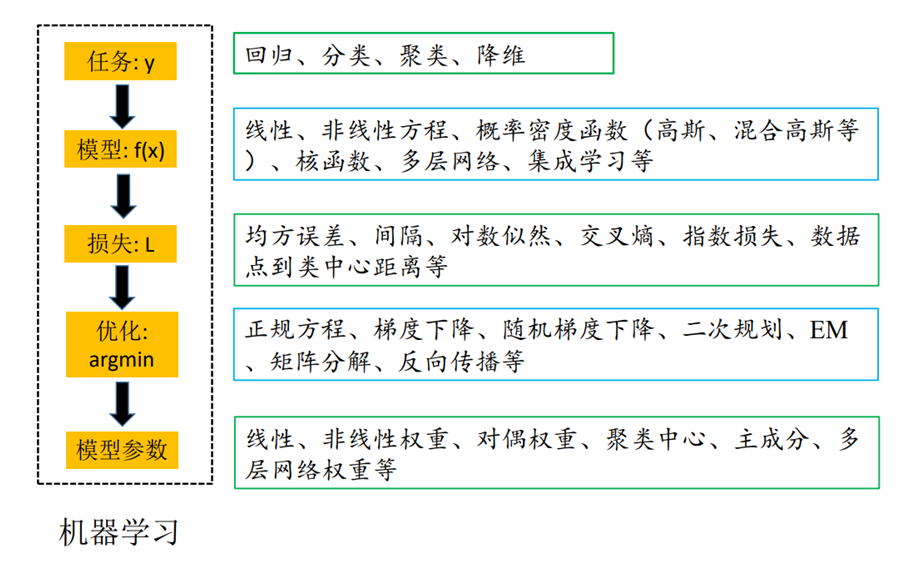
五、机器学习组成
主要任务
- 分类(classification): 将实例数据划分到合适的类别中。
- 应用实例: 判断网站是否被黑客入侵(二分类 ),手写数字的自动识别(多分类)
- 回归(regression): 主要用于预测数值型数据。
- 应用实例: 股票价格波动的预测,房屋价格的预测等。
监督学习(supervised learning)
- 必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。 (包括: 分类和回归)
- 样本集: 训练数据 + 测试数据
- 训练样本 = 特征(feature) + 目标变量(label: 分类-离散值/回归-连续值)
- 特征通常是训练样本集的列,它们是独立测量得到的。
- 目标变量: 目标变量是机器学习预测算法的测试结果。
- 在分类算法中目标变量的类型通常是标称型(如: 真与假),而在回归算法中通常是连续型(如: 1~100)。
- 监督学习需要注意的问题:
- 偏置方差权衡
- 功能的复杂性和数量的训练数据
- 输入空间的维数
- 噪声中的输出值
知识表示- 可以采用规则集的形式【例如: 数学成绩大于90分为优秀】
- 可以采用概率分布的形式【例如: 通过统计分布发现,90%的同学数学成绩,在70分以下,那么大于70分定为优秀】
- 可以使用训练样本集中的一个实例【例如: 通过样本集合,我们训练出一个模型实例,得出 年轻,数学成绩中高等,谈吐优雅,我们认为是优秀】
非监督学习(unsupervised learning)
- 在机器学习,无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案。
- 无监督学习是密切相关的统计数据密度估计的问题。然而无监督学习还包括寻求,总结和解释数据的主要特点等诸多技术。在无监督学习使用的许多方法是基于用于处理数据的数据挖掘方法。
- 数据没有类别信息,也不会给定目标值。
- 非监督学习包括的类型:
- 聚类: 在无监督学习中,将数据集分成由类似的对象组成多个类的过程称为聚类。
- 密度估计: 通过样本分布的紧密程度,来估计与分组的相似性。
- 此外,无监督学习还可以减少数据特征的维度,以便我们可以使用二维或三维图形更加直观地展示数据信息。
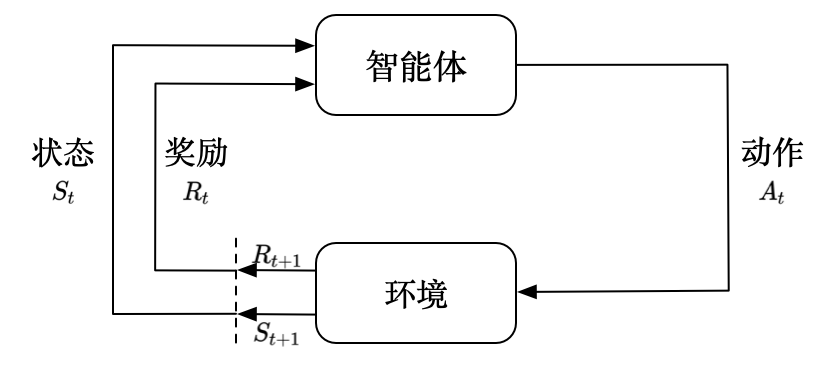
强化学习
这个算法可以训练程序做出某一决定。程序在某一情况下尝试所有的可能行动,记录不同行动的结果并试着找出最好的一次尝试来做决定。 属于这一类算法的有马尔可夫决策过程。
算法汇总
六、机器学习使用
选择算法需要考虑的两个问题
- 算法场景
- 预测明天是否下雨,因为可以用历史的天气情况做预测,所以选择监督学习算法
- 给一群陌生的人进行分组,但是我们并没有这些人的类别信息,所以选择无监督学习算法、通过他们身高、体重等特征进行处理。
- 需要收集或分析的数据是什么
举例

开发流程
- 收集数据: 收集样本数据
- 准备数据: 注意数据的格式
- 分析数据: 为了确保数据集中没有垃圾数据;
- 如果是算法可以处理的数据格式或可信任的数据源,则可以跳过该步骤;
- 另外该步骤需要人工干预,会降低自动化系统的价值。
- 训练算法: [机器学习算法核心]如果使用无监督学习算法,由于不存在目标变量值,则可以跳过该步骤
- 测试算法: [机器学习算法核心]评估算法效果
- 使用算法: 将机器学习算法转为应用程序
七、补充知识
Learning rate —— 学习率,通俗地理解,可以理解为步长,步子大了,很容易错过最佳结果。就是本来目标尽在咫尺,可是因为我迈的步子很大,却一下子走过了。步子小了呢,就是同样的距离,我却要走很多很多步,这样导致训练的耗时费力还不讨好。
专业术语
- 模型(model): 计算机层面的认知
- 学习算法(learning algorithm),从数据中产生模型的方法
- 数据集(data set): 一组记录的合集
- 示例(instance): 对于某个对象的描述
- 样本(sample): 也叫示例
- 属性(attribute): 对象的某方面表现或特征
- 特征(feature): 同属性
- 属性值(attribute value): 属性上的取值
- 属性空间(attribute space): 属性张成的空间
- 样本空间/输入空间(samplespace): 同属性空间
- 特征向量(feature vector): 在属性空间里每个点对应一个坐标向量,把一个示例称作特征向量
- 维数(dimensionality): 描述样本参数的个数(也就是空间是几维的)
- 学习(learning)/训练(training): 从数据中学得模型
- 训练数据(training data): 训练过程中用到的数据
- 训练样本(training sample):训练用到的每个样本
- 训练集(training set): 训练样本组成的集合
- 假设(hypothesis): 学习模型对应了关于数据的某种潜在规则
- 真相(ground-truth):真正存在的潜在规律
- 学习器(learner): 模型的另一种叫法,把学习算法在给定数据和参数空间的实例化
- 预测(prediction): 判断一个东西的属性
- 标记(label): 关于示例的结果信息,比如我是一个“好人”。
- 样例(example): 拥有标记的示例
- 标记空间/输出空间(label space): 所有标记的集合
- 分类(classification): 预测是离散值,比如把人分为好人和坏人之类的学习任务
- 回归(regression): 预测值是连续值,比如你的好人程度达到了0.9,0.6之类的
- 二分类(binary classification): 只涉及两个类别的分类任务
- 正类(positive class): 二分类里的一个
- 反类(negative class): 二分类里的另外一个
- 多分类(multi-class classification): 涉及多个类别的分类
- 测试(testing): 学习到模型之后对样本进行预测的过程
- 测试样本(testing sample): 被预测的样本
- 聚类(clustering): 把训练集中的对象分为若干组
- 簇(cluster): 每一个组叫簇
- 监督学习(supervised learning): 典范–分类和回归
- 无监督学习(unsupervised learning): 典范–聚类
- 未见示例(unseen instance): “新样本“,没训练过的样本
- 泛化(generalization)能力: 学得的模型适用于新样本的能力
- 分布(distribution): 样本空间的全体样本服从的一种规律
- 独立同分布(independent and identically distributed,简称i,i,d.):获得的每个样本都是独立地从这个分布上采样获得的。
数据集的划分
- 训练集(Training set) —— 学习样本数据集,通过匹配一些参数来建立一个模型,主要用来训练模型。类比考研前做的解题大全。
- 验证集(validation set) —— 对学习出来的模型,调整模型的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。类比 考研之前做的模拟考试。
- 测试集(Test set) —— 测试训练好的模型的分辨能力。类比 考研。这次真的是一考定终身。




![[go 语言学习笔记] 7天用Go从零实现分布式缓存GeeCache 「持续更新中」](https://img-blog.csdnimg.cn/0209182fba704a4e9602bdd87bb0cc95.png)


![[附源码]计算机毕业设计的中点游戏分享网站Springboot程序](https://img-blog.csdnimg.cn/2bf9fbc41c9249a6bdc84569dc4f3599.png)