文章目录
- Redis 集合(Set)
- Set简介
- 常用命令
- 应用场景
- 共同关注实例
- 整数集合
- 整数集合介绍
- 整数集合的升级
- 哈希表
- 哈希表的原理和实现
- Redis中的哈希表
- rehash
- 渐进式rehash
Redis 集合(Set)
Set简介
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的哈希表或者整数集合,所以添加,删除,查找的复杂度都是O(1)。
- 如果集合中的元素都是整数且元素个数小于
512(默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构; - 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
一个集合最多可以存储 2^32-1 个元素。概念和数学中个的集合基本类似,可以交集,并集,差集等等,所以 Set 类型除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。
常用命令
向集合中添加元素
- sadd …

查看集合中的值
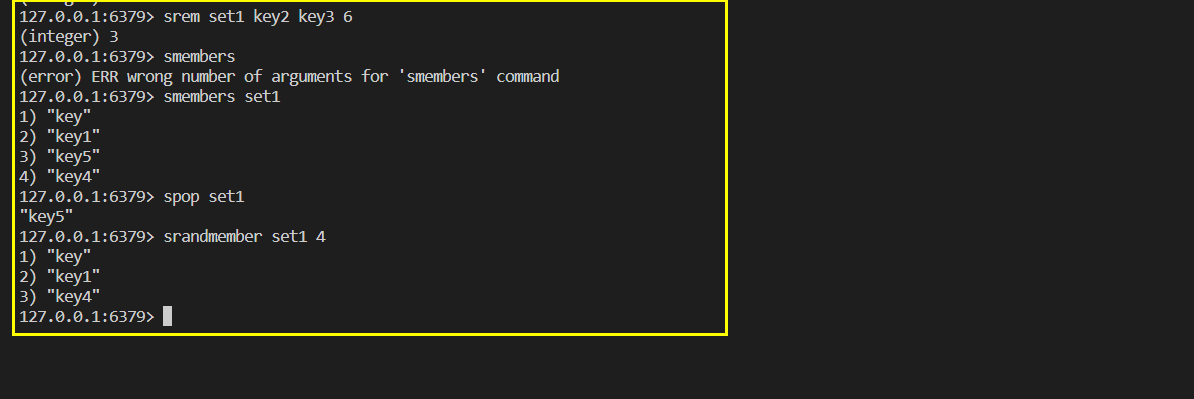
- smembers

判断一个元素是否在集合中
- sismember 判断集合是否为含有该值,有1,没有0

集合的元素个数。
- scard返回该集合的元素个数。

Set的删除和取值
- srem … 删除集合中的某个元素。
- spop 随机从该集合中吐出一个值。
- srandmember 随机从该集合中取出n个值。不会从集合中删除 。
集合间运算
- smove value把集合中一个值从一个集合移动到另一个集合
- sinter 返回两个集合的交集元素。
- sunion 返回两个集合的并集元素。
- sdiff 返回两个集合的差集元素(key1中的,不包含key2中的)

集合的运算
- sinterstore destination key [ key… ]将交集的结果存入新集合destination中
- sunionstore destination key [ key… ]将并集结果存入新集合destination中
- sdiffstore destination key [ key…] 将差集结果存入新集合destination中

应用场景
因此 Set 类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等,当我们存储的数据是无序并且需要去重的情况下,比较适合使用集合类型进行存储。
Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
共同关注实例
Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。key 可以是用户id,value 则是已关注的公众号的id。
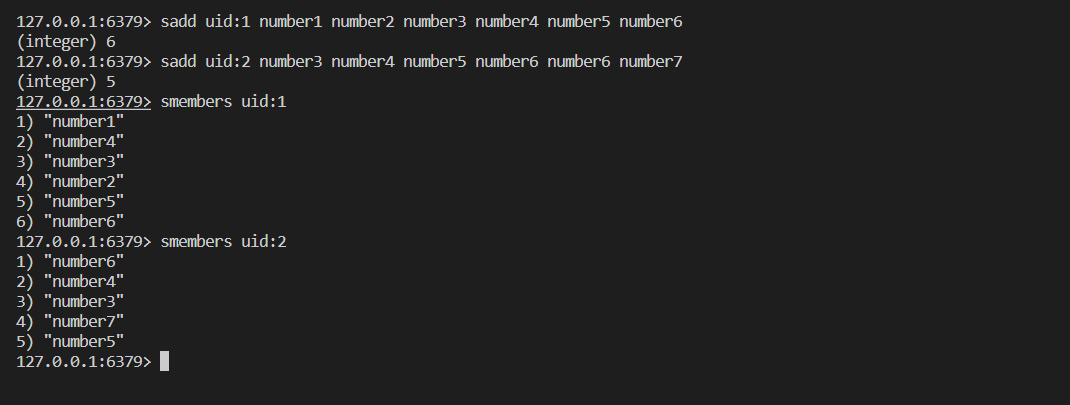
uid1 和 uid2共同关注的公众号

uid:1 向uid:2 推荐公众号

验证某个公众号是否同时被
uid:1或uid:2关注:
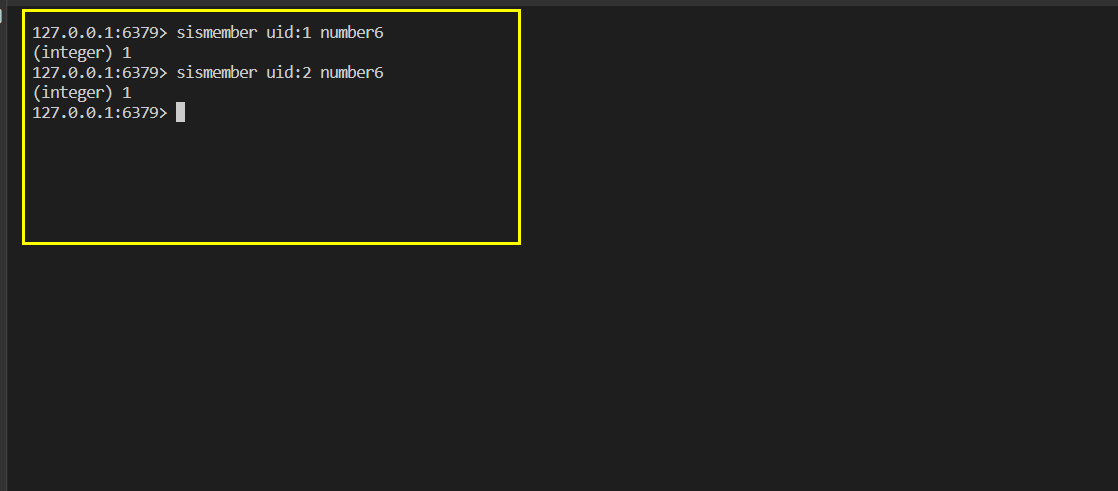
number6公众号被uid:1和uid:2同时关注
整数集合
整数集合介绍
当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集这个数据结构作为底层实现。
整数集合本质上是一块连续内存空间
typedef struct intset {
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
} intset;
contents数组中的数据类型取决于encoding的取值类型
- 如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
- 如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
- 如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
整数集合的升级
当我们将一个新的元素插入到整数集合中,如果新加入元素类型比整数集合现有所有元素类型都要长,整数集合就需要升级。按照整数集合中最长类型进行升级。
整数集合升级的过程不会重新分配一个新类型的数组,而是在原本的数组上扩展空间
在升级的过程中,要保证底层数组的有序性不变。
比如原数组中有1,2,3三个元素
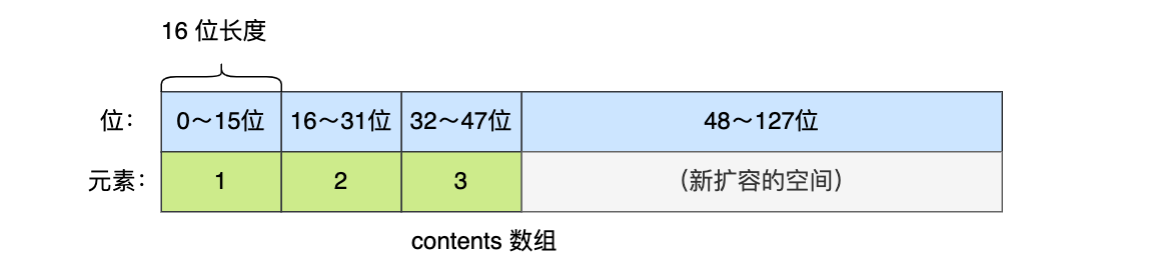
此时向数组中插入一个65535
原数组中int16_t类型需要升级为int32_t类型,首先进行扩容。

然后按照顺序,将原元素放入到正确的位置。该过程中要保证元素的顺序保持不变。
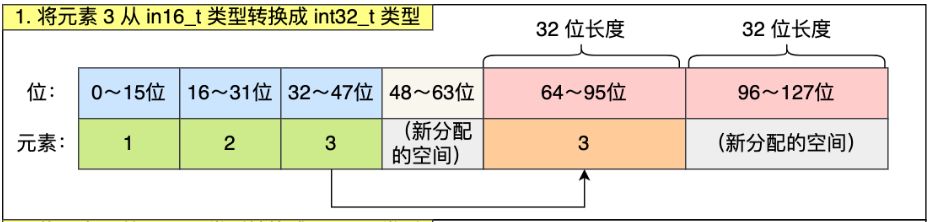
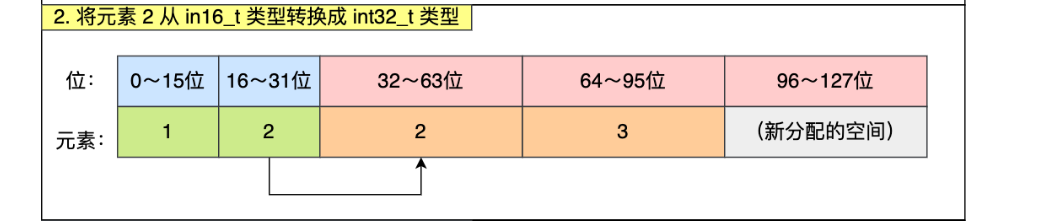

向整数集合中添加新的元素
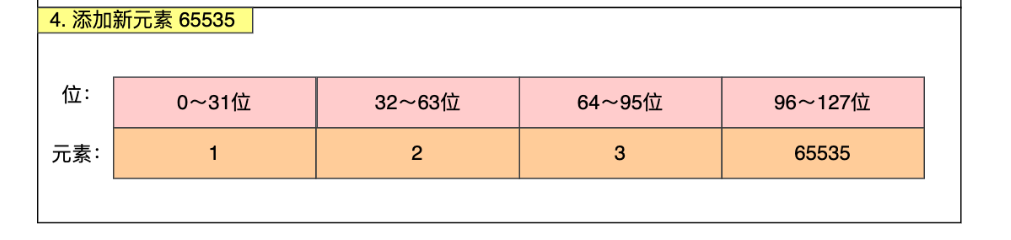
整数升级的最大好处就是可以有效的节约资源。
哈希表
哈希表的原理和实现
关于哈希表的实现和介绍:
哈希表的原理和实现
位图、布隆过滤器和一致性哈希
Redis中的哈希表
Redis中哈希采用链式结构存储数据
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;

哈希表dictEnty中的每一个元素指向一个链表。链表的每个节点是哈希表结点。
哈希表结点的定义
typedef struct dictEntry {
//键值对中的键
void *key;
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
rehash
rehash,也就是对哈希表的大小进行扩展。实际应用中,Redis定义一个dict 结构体,这个结构体里定义了两个哈希表,用于rehash
typedef struct dict {
…
//两个Hash表,交替使用,用于rehash操作
dictht ht[2];
…
} dict;
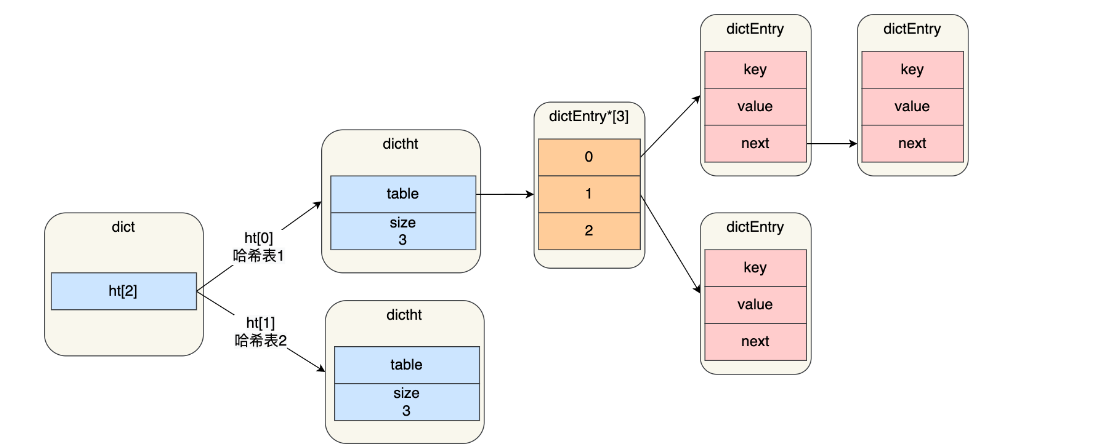
在对哈希表进行扩展时,就需要使用上两个哈希表。
在正常服务请求阶段,插入的数据,都会写入到「哈希表 1」,此时的「哈希表 2 」 并没有被分配空间。随着数据的进一步添加,达到了rehash的条件:
- 给「哈希表 2」 分配空间,一般会比「哈希表 1」 大 2 倍;
- 将「哈希表 1 」的数据迁移到「哈希表 2」 中;
- 迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。
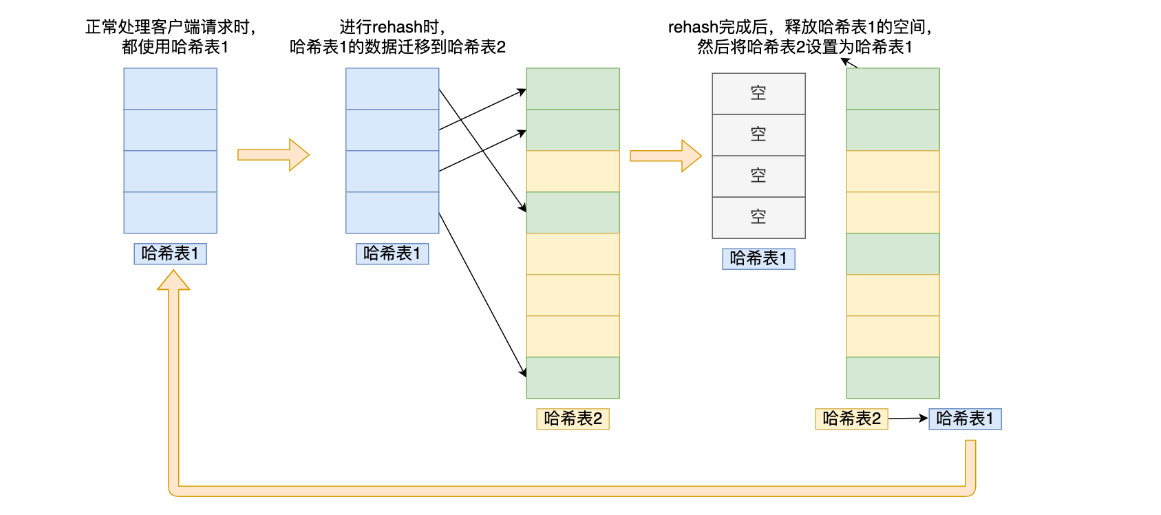
渐进式rehash
为了避免 rehash 在数据迁移过程中,因拷贝数据的耗时,影响 Redis 性能的情况,所以 Redis 采用了渐进式 rehash,也就是将数据的迁移的工作不再是一次性迁移完成,而是分多次迁移。
- 在rehash进行期间,每次哈希元素进行增删改查操作时,redis除了执行对应的操作,还会顺序将哈希表1中索引位置上的所有key-value迁移到哈希表2中。
- 直到某个时间段,哈希表1的所有key-value都被迁移到哈希表2中,此时完成了rehash操作。
注意:
在进行渐进式rehash的过程中,存在两个哈希表,因此哈希表的增删查改操作,都会在两个表中进行。
- 在查找元素时,会先在哈希表1中查找,如果没有找到,就会在哈希表2中查找。
- 在添加元素时,元素会被保存在哈希表2中;删除元素,先删除哈希表1中的元素,如果没有,再删除哈希表2中的元素。这样,保证了哈希表1的数据只减少,随着操作进行,哈希表1最后会变成一个空表。




![[go 语言学习笔记] 7天用Go从零实现分布式缓存GeeCache 「持续更新中」](https://img-blog.csdnimg.cn/0209182fba704a4e9602bdd87bb0cc95.png)


![[附源码]计算机毕业设计的中点游戏分享网站Springboot程序](https://img-blog.csdnimg.cn/2bf9fbc41c9249a6bdc84569dc4f3599.png)