💓博主个人主页:不是笨小孩👀
⏩专栏分类:数据结构与算法👀 刷题专栏👀 C语言👀
🚚代码仓库:笨小孩的代码库👀
⏩社区:不是笨小孩👀
🌹欢迎大家三连关注,一起学习,一起进步!!💓

堆
- 堆的实现
- 堆的结构
- 堆的接口及实现
- 堆的插入
- 堆的删除
- 其他接口
- 堆的应用
- 堆排序
- 向上调整法建堆
- 向下调整法建堆
- TopK问题
堆的实现
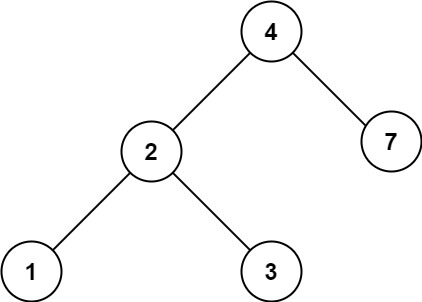
我们说堆在物理上是一个数组,逻辑上它是一个完全二叉树,我们可以通过它的下标来计算父亲和孩子之间的关系。
> 左孩子=父亲×2+1;
右孩子=父亲×2+2;
父亲=(孩子-1)/2;
堆的结构
堆的结构和顺序表是一样的。
typedef int HPDateType;
typedef struct Heap
{
HPDateType* a;
int size;
int capacity;
}HP;
堆的接口及实现
堆的接口有哪些呢?
//初始化
void HeapInit(HP* php);
//销毁
void HeapDestroy(HP* php);
//插入
void HeapPush(HP* php, HPDateType x);
//删除
void HeapPop(HP* php);
//取对顶的数据
HPDateType HeapTop(HP* hp);
// 堆的数据个数
int HeapSize(HP* hp);
// 堆的判空
int HeapEmpty(HP* hp);
我们主要讲一下删除和插入,其他的非常简单。
堆的插入
假设先插入一个10到数组的尾上,再进行向上调整算法,直到满足堆。

代码如下:
void HeapPush(HP* php, HPDateType x)
{
assert(php);
if (php->capacity == php->size)
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDateType* pa = (HPDateType*)realloc(php->a, sizeof(HPDateType) * newcapacity);
if (pa == NULL)
{
perror("realloc fail");
exit(-1);
}
php->a = pa;
php->capacity = newcapacity;
}
php->a[php->size] = x;
php->size++;
//向上调整算法
AdjustUp(php->a, php->size-1);
}
不知道向上调整算法的,请戳。
堆的删除
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法,使数组满足堆的性质。
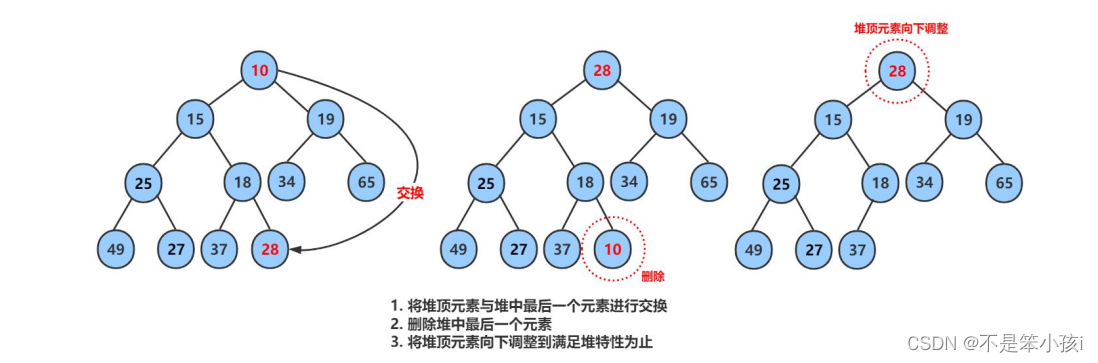
代码如下:
//删除
void HeapPop(HP* php)
{
assert(php);
assert(php->size);
//交换
Swap(&php->a[0], &php->a[php->size - 1]);
//删除数据
php->size--;
//向下调整算法
AdjustDown(php->a, php->size, 0);
}
不懂向下调整算法请戳。
其他接口
其他接口和顺序表差不多,这里给大家看一下代码。
//初始化
void HeapInit(HP* php)
{
assert(php);
php->a = NULL;
php->capacity = 0;
php->size = 0;
}
//取对顶的数据
HPDateType HeapTop(HP* php)
{
assert(php);
assert(php->size);
return php->a[0];
}
// 堆的数据个数
int HeapSize(HP* php)
{
assert(php);
return php->size;
}
// 堆的判空
int HeapEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
//销毁
void HeapDestroy(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->size = php->capacity = 0;
}
那么堆的实现就是这么多的内容,重点是向上调整,向下调整算法,而向下调整算法是最最最重要的。
堆的应用
堆排序
我们先思考一个问题,排升序的话建大堆还是建小堆
答案是建大堆,有人就会有疑惑了,为什么要建大堆,问什么不建小堆呢,如果建小堆的话,那么堆顶的元素就是最小的,由于要排升序,我们就需要跳过第一个元素,但是后面的元素的父子关系就全乱了,需要重新建堆,而重新建堆的代价是非常大了,所以我们要建大堆,然后和删除一样,这时堆顶的元素是最大的,我们将堆顶的元素和最后一个元素换一下,然后使用向下调整算法,只不过需要将有效数据的个数减少一个就可以了。
排升序建大堆,那么排降序就是建小堆。
有人会说我们实现了堆,我们可以把数组的元素依次插入堆,然后依次按上面的操作,就可以实现排序了,最后再把数据拷回来就可以了。但是我们一般不这样玩,因为那样插入需要空间复杂度,而且把数据拷回来也是很挫的操作,我们一般都是在原数组之间建堆,我们可以用向上调整法建堆,也可以用向下调整法建堆。
向上调整法建堆
把数据都分割开,看出依次插入的,因为第一个数据就一个数据本身就是一个堆,所以直接从第二个数据开始就可以。
for (int i = 1; i < sz; i++)
{
//这就和我们上面画的图想对应,依次插入,并且保证前面是堆
//向上调整传的是数组和孩子节点(也就是需要调整的节点)
AdjustUp(arr, i);
}
向下调整法建堆
向下调整的前提是两个孩子都是堆,所以我们可以从后往前调,而叶子节点不需要调,所以我们从最后一片叶子的父亲开始就可以。
for(int i = (sz - 1 - 1) / 2; i >= 0; i--)
{
//sz是数组的大小
//向下调整传的是数组,数组的大小,以及需要调的父亲节点
AdjustDown(arr, sz, i);
}
我们搞清楚这个以后就可以开始我们的堆排序了。
1.我们需要建堆。
2.我们需要交换堆顶和最后一个元素的数据,然后进行向下调整算法。
由于我们建堆和调整数据都需要向下调整算法,所以我们掌握了向下调整算法就可以完成堆排序。
代码如下:
//交换函数
void Swap(int* p1, int* p2)
{
int tmp = 0;
tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//向上调整算法
void AdjustUp(int* arr, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[child] > arr[parent])
{
Swap(arr + child, arr + parent);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//向下调整算法
void AdjustDown(int* arr, int sz, int parent)
{
//假设是左孩子
int child = 2 * parent + 1;
while (child < sz)
{
if (child+1<sz && arr[child] < arr[child + 1])
{
child++;
}
if (arr[child] > arr[parent])
{
Swap(arr + child, arr + parent);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int* arr, int sz)
{
//假设排升序,建大堆
//向上调整算法建堆
/*for (int i = 1; i < sz; i++)
{
AdjustUp(arr, i);
}*/
//向下调整算法建堆
for(int i = (sz - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, sz, i);
}
//交换收尾,接着向下调整算法
int end = sz - 1;
while (end > 0)
{
//交换首尾
Swap(&arr[0], &arr[end]);
//向下调整
AdjustDown(arr, end, 0);
end--;
}
}
堆排序就讲到这里,有什么不理解的可以私信博主。
TopK问题
TopK是什么?
求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
那这怎么解决呢?和堆又有什么关系呢?
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能
数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆- 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
我这里用数组来给大家实现一下:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(int* arr, int sz, int parent)
{
int child = parent*2+1;
while (child < sz)
{
if (child+1<sz && arr[child] > arr[child + 1])
{
child++;
}
if (arr[parent] > arr[child])
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void PrintTopK(int* a, int n, int k)
{
//直接在原数组的前K个建小堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, k, i);
}
int top = 0;
for (int i = k; i < n; i++)
{
top = a[i];
//取后k个元素依次和堆顶的元素比较,大的就替换,然后向下调整
if(a[0] < top)
{
a[0] = top;
AdjustDown(a, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", a[i]);
}
}
void TestTopk()
{
int n = 10000;
int* a = (int*)malloc(sizeof(int) * n);
srand((size_t)time(NULL));
//生成一万个随机数
for (int i = 0; i < n; ++i)
{
a[i] = rand() % 1000000;
}
a[5] = 1000000 + 1;
a[1231] = 1000000 + 2;
a[531] = 1000000 + 3;
a[5121] = 1000000 + 4;
a[115] = 1000000 + 5;
a[2335] = 1000000 + 6;
a[9999] = 1000000 + 7;
a[76] = 1000000 + 8;
a[423] = 1000000 + 9;
a[3144] = 1000000 + 10;
PrintTopK(a, n, 10);
free(a);
}
int main()
{
TestTopk();
return 0;
}
那么堆讲到这里就结束了,今天的分享到这里也结束了,感谢大家的关注和支持。