注意:本文只针对离散随机变量做出探讨,连续随机变量的情况不适用于本文探讨的内容!
(一)自信息
1. 自信息
I
(
x
)
=
−
l
o
g
n
P
(
x
)
\color{blue}I(x) = - log_{n}{P(x)}
I(x)=−lognP(x)
注意:
若n = 2,叫做bit
若n = 3,叫做tet
若n = e,叫做nat
若n = 10,叫做hat
一般来讲,在信息论中,以2为底数比较普遍。
从公式的含义来看,
由于
P
(
x
)
代表的是概率的大小,其值介于区间
(
0
,
1
)
之间,
当
p
(
x
)
趋于
0
时代表信息量是无穷大的;而当
p
(
x
)
趋于
1
时,它代表的信息量是
0
。
\color{red}从公式的含义来看,\\由于P(x)代表的是概率的大小,其值介于区间(0,1)之间,\\ 当p(x)趋于0时代表信息量是无穷大的;而当p(x)趋于1时,它代表的信息量是0。
从公式的含义来看,由于P(x)代表的是概率的大小,其值介于区间(0,1)之间,当p(x)趋于0时代表信息量是无穷大的;而当p(x)趋于1时,它代表的信息量是0。
自信息还包括条件自信息和联合自信息。其中条件自信息定义如下:
I
(
x
y
)
=
−
log
P
(
x
∣
y
)
=
−
log
p
(
x
y
)
p
(
y
)
I(xy) = - \log P(x|y) = - \log \frac {p(xy)}{p(y)}
I(xy)=−logP(x∣y)=−logp(y)p(xy)
联合自信息的定义如下:
I
(
x
y
)
=
−
l
o
g
n
P
(
x
y
)
\color{red}I(xy) = - log_{n}{P(xy)}
I(xy)=−lognP(xy)
联合自信息的特点:
I
(
x
y
)
=
I
(
y
∣
x
)
+
I
(
x
)
=
I
(
x
∣
y
)
+
I
(
y
)
\color{red}I(xy) = I(y|x) + I(x) = I(x|y) + I(y)
I(xy)=I(y∣x)+I(x)=I(x∣y)+I(y)
当x 与y 相互独立时有:
I
(
x
y
)
=
I
(
x
)
+
I
(
y
)
\color{red}I(xy) = I(x) + I(y)
I(xy)=I(x)+I(y)
2. 条件熵
条件熵是平均条件自信息的另一种解释,是条件自信息的期望值。
I
(
x
∣
y
)
=
−
∑
x
∈
X
P
(
x
i
∣
y
i
)
∑
y
∈
Y
P
(
y
i
)
l
o
g
P
(
x
i
∣
y
i
)
=
−
∑
x
∈
X
∑
y
∈
Y
P
(
x
y
)
L
o
g
P
(
x
∣
y
)
I(x|y) = -\sum_{x\in X}P(x_i|y_i)\sum_{y \in Y}P(y_i)logP(x_i|y_i)=-\sum_{x\in X}\sum _{y \in Y}P(xy)LogP(x|y)
I(x∣y)=−x∈X∑P(xi∣yi)y∈Y∑P(yi)logP(xi∣yi)=−x∈X∑y∈Y∑P(xy)LogP(x∣y)
要注意:此处log符号前的概率是
p
(
x
y
)
\color{green}p(xy)
p(xy)而不是
p
(
x
∣
y
)
\color{green}p(x|y)
p(x∣y)
另外,从上面的公式可知,必须要计算整个y的条件概率,而不是
y
i
y_i
yi的条件概率,故log符号前面是p(xy)而不是p(x|y)
3. 互信息
I ( x ; y ) = ∑ x ∈ X ∑ y ∈ Y l o g p ( x y ) p ( x ) p ( y ) = ∑ x ∈ X ∑ y ∈ Y l o g p ( x ∣ y ) p ( x ) = ∑ x ∈ X ∑ y ∈ Y l o g p ( y ∣ x ) p ( y ) = I ( y ; x ) I(x;y) = \sum_{x \in X} \sum_{y \in Y} log \frac {p(xy)} {p(x) p (y)} =\\ \sum_{x \in X} \sum_{y \in Y} log \frac {p(x|y)} {p(x)} =\sum_{x \in X} \sum_{y \in Y} log \frac {p(y|x)} {p(y)} = I(y;x) I(x;y)=x∈X∑y∈Y∑logp(x)p(y)p(xy)=x∈X∑y∈Y∑logp(x)p(x∣y)=x∈X∑y∈Y∑logp(y)p(y∣x)=I(y;x)
互信息的重要性质:
I ( x ; y ) = H ( x ) − H ( x ∣ y ) = H ( y ) − H ( y ∣ x ) I(x; y) = H(x) - H(x|y) = H(y) -H(y|x) I(x;y)=H(x)−H(x∣y)=H(y)−H(y∣x)
证明:
H
(
x
)
−
H
(
x
∣
y
)
=
−
∑
x
∈
X
P
(
x
)
l
o
g
P
(
x
)
+
∑
x
∈
X
∑
y
∈
Y
p
(
x
y
)
l
o
g
P
(
x
∣
y
)
=
−
∑
x
∈
X
p
(
x
)
l
o
g
p
(
x
)
∑
y
∈
Y
p
(
y
∣
x
)
+
∑
x
∈
X
∑
y
∈
Y
p
(
x
y
)
l
o
g
P
(
x
∣
y
)
=
−
∑
x
∈
X
∑
y
∈
Y
p
(
x
y
)
l
o
g
p
(
x
)
+
∑
x
∈
X
∑
y
∈
Y
p
(
x
y
)
l
o
g
P
(
x
∣
y
)
=
∑
x
∈
X
∑
y
∈
Y
p
(
x
y
)
l
o
g
P
(
x
y
)
P
(
x
)
P
(
y
)
=
I
(
x
;
y
)
H(x) - H (x|y) = -\sum_{x \in X} P(x)log P(x) + \sum_{x \in X} \sum_{y \in Y} p(xy)log P(x|y) \\ = - \sum_{x \in X}p(x) log p(x) \sum_{y \in Y} p(y|x) +\sum_{x \in X} \sum_{y \in Y} p(xy)log P(x|y)\\ = - \sum_{x \in X} \sum_{y \in Y}p(xy)logp(x) + \sum_{x \in X} \sum_{y \in Y} p(xy)log P(x|y) \\ = \sum_{x \in X} \sum_{y \in Y} p(xy)log \frac {P(xy)}{P(x)P(y)}= I(x;y)
H(x)−H(x∣y)=−x∈X∑P(x)logP(x)+x∈X∑y∈Y∑p(xy)logP(x∣y)=−x∈X∑p(x)logp(x)y∈Y∑p(y∣x)+x∈X∑y∈Y∑p(xy)logP(x∣y)=−x∈X∑y∈Y∑p(xy)logp(x)+x∈X∑y∈Y∑p(xy)logP(x∣y)=x∈X∑y∈Y∑p(xy)logP(x)P(y)P(xy)=I(x;y)
此处要注意的是一个知识点就是, ∑ y ∈ Y p ( y i ∣ x ) = ∑ y ∈ Y p ( x ∣ y i ) p ( y i ) p ( x ) = 1 \sum_{y \in Y} p(y_i|x) =\sum_{y \in Y} \frac {p(x|y_i)p(y_i)}{p(x)} = 1 ∑y∈Yp(yi∣x)=∑y∈Yp(x)p(x∣yi)p(yi)=1
4.平均互信息
注意平均互信息和互信息的区别。平均互信息即为互信息的期望值,其定义为:
I
(
x
;
y
)
=
∑
x
∈
X
∑
y
∈
Y
P
(
x
y
)
l
o
g
p
(
x
y
)
p
(
x
)
p
(
y
)
=
∑
x
∈
X
∑
y
∈
Y
P
(
x
y
)
l
o
g
p
(
x
∣
y
)
p
(
x
)
=
∑
x
∈
X
∑
y
∈
Y
P
(
x
y
)
l
o
g
p
(
y
∣
x
)
p
(
y
)
=
I
(
y
;
x
)
I(x;y) = \sum_{x \in X} \sum_{y \in Y} P(xy) log \frac {p(xy)} {p(x) p (y)} =\\ \sum_{x \in X} \sum_{y \in Y} P(xy) log \frac {p(x|y)} {p(x)} =\sum_{x \in X} \sum_{y \in Y} P(xy) log \frac {p(y|x)} {p(y)} = I(y;x)
I(x;y)=x∈X∑y∈Y∑P(xy)logp(x)p(y)p(xy)=x∈X∑y∈Y∑P(xy)logp(x)p(x∣y)=x∈X∑y∈Y∑P(xy)logp(y)p(y∣x)=I(y;x)
5. 条件互信息
联合集XYZ中,给定条件Z下,X与Y的互信息定义如下:
I ( x ; y ∣ z ) = I ( x ∣ z ) − I ( x ∣ y z ) = − log P ( x ∣ z ) + log P ( x ∣ y z ) = log p ( x ∣ y z ) p ( x ∣ z ) I(x;y|z) = I(x|z) - I(x|yz) = -\log P(x|z) + \log P(x|yz) = \log \frac {p(x|yz)}{p(x|z)} I(x;y∣z)=I(x∣z)−I(x∣yz)=−logP(x∣z)+logP(x∣yz)=logp(x∣z)p(x∣yz)
(二)熵
熵的定义比较重要,重点讲述,但是其含义跟上一个标题中的平均互信息、条件熵类似,都是一种期望值。
熵的定义:自信息的数学期望为信源的平均自信息量(信息熵)。 用数学期望值的原因是因为,自信息是一个随机事件的概率 , 不能用作整个信源的信息测度。 由此可见,熵是自信息概念的进一步扩展,是自信息的期望值 \color{red}熵的定义:自信息的数学期望为信源的平均自信息量(信息熵)。\\用数学期望值的原因是因为,自信息是一个随机事件的概率, 不能用作整个信源的信息测度。\\由此可见,熵是自信息概念的进一步扩展,是自信息的期望值 熵的定义:自信息的数学期望为信源的平均自信息量(信息熵)。用数学期望值的原因是因为,自信息是一个随机事件的概率,不能用作整个信源的信息测度。由此可见,熵是自信息概念的进一步扩展,是自信息的期望值
二元熵
二元熵是熵的一个特例,也就是一件事情有两种情况发生,这两种情况的概率已知,那么这件事情的熵计算公式如下:
H
(
x
)
=
−
p
l
o
g
p
−
(
1
−
p
)
l
o
g
(
1
−
p
)
H(x) = - p log p - (1-p) log(1-p)
H(x)=−plogp−(1−p)log(1−p)
离散熵:
H ( x ) = E x [ I ( x ) ] = − ∑ i = 1 n [ P ( x i ) l o g n P ( x i ) ] \color{blue} H(x) = E_x[I(x)]=-\sum^{ n }_{i=1} [P(x_i)log_nP(x_i)] H(x)=Ex[I(x)]=−i=1∑n[P(xi)lognP(xi)]
连续熵:
H ( x ) = E x [ I ( x ) ] = − ∫ + ∞ − ∞ P ( x ) l o g n P ( x ) d x \color{green}H(x) = E_{x}[I(x)] = - \int_{+\infty}^{-\infty}P(x)log_{n}P(x)dx H(x)=Ex[I(x)]=−∫+∞−∞P(x)lognP(x)dx
注意:积分中是对x微分而不是P(x)
熵的一些重要知识点:
根据极限相关知识,可得:
lim P ( x ) → 0 − P ( x ) l o g n P ( x ) = lim x → 0 l o g n P ( x ) 1 − P ( x ) = 1 P ( x ) P ( x ) 2 = P ( x ) = 0 \color{red}\lim_{P(x) \to 0}-P(x)log_nP(x) = \lim_{x \to 0} \frac {log_nP(x)} {\frac{1}{-P(x)}} = \frac{1}{P(x)} P(x)^2 = P(x) = 0 P(x)→0lim−P(x)lognP(x)=x→0lim−P(x)1lognP(x)=P(x)1P(x)2=P(x)=0
同时,当P(x)= 1时,H(x) = 0。
连续熵的导数为0时,
H
′
(
x
)
=
−
P
(
x
)
l
o
g
n
P
(
x
)
=
0
H'(x) = -P(x) log_nP(x) = 0
H′(x)=−P(x)lognP(x)=0,可得:
(1)当熵的导数为0时,可得P(x) = 1(
P
(
x
)
=
0
不在定义域中,不符合条件
\color{green}P(x) = 0不在定义域中,不符合条件
P(x)=0不在定义域中,不符合条件),因此熵在该点处取得极值。
(2)再考察P(x) = 1 左右处的值,左侧导数大于0,右侧导数小于0,因此在P(x) = 1处连续熵函数取得最小值0。(
此处似乎有错误
,
问题在于离散熵和连续熵函数具有很大的区别,其细节问题,留待勘查
\color{red}此处似乎有错误,问题在于离散熵和连续熵函数具有很大的区别,其细节问题,留待勘查
此处似乎有错误,问题在于离散熵和连续熵函数具有很大的区别,其细节问题,留待勘查)
(3)熵的值总是大于0。由于P(x)的含义是x的概率,概率总是大于0小于1的,又
−
P
(
x
)
l
o
g
n
P
(
x
)
=
P
(
x
)
l
o
g
n
1
P
(
x
)
-P(x)log_nP(x) =P(x)log_n \frac{1}{P(x)}
−P(x)lognP(x)=P(x)lognP(x)1,根据log函数的性质,
l
o
g
n
1
P
(
x
)
log_n\frac{1}{P(x)}
lognP(x)1也大于0,故熵的值必然大于0。
(4)H(xy) = H(x) + H(y|x)
证明:
H
(
x
)
+
H
(
y
∣
x
)
=
−
∑
i
=
1
n
P
(
x
y
)
l
o
g
P
(
x
y
)
P
(
x
)
−
∑
i
=
1
n
P
(
x
)
l
o
g
P
(
x
)
=
−
∑
i
=
1
n
P
(
x
y
)
l
o
g
P
(
x
y
)
=
H
(
x
y
)
H(x) + H(y|x) =- \sum_{i=1}^n P(xy) log \frac {P(xy) }{P(x)} - \sum _{i=1}^n P(x)log P(x) =\\ -\sum_{i=1}^n P(xy) log P(xy) = H(xy)
H(x)+H(y∣x)=−i=1∑nP(xy)logP(x)P(xy)−i=1∑nP(x)logP(x)=−i=1∑nP(xy)logP(xy)=H(xy)
同理,H(xy) = H(y) + H(x|y)
另外,还有几个重要的结论:
(1)当已知分布上下限时均匀分布的熵最大,当知道均值和方差时正态分布的熵最大。
(2)给定一串数据,其中数据元 x 出现的概率为p(x),则最佳编码长度为
−
l
o
g
2
P
(
x
)
-log_2P(x)
−log2P(x),整段文本的平均编码长度为
−
∑
i
=
1
n
P
(
x
i
)
l
o
g
2
P
(
x
i
)
-\sum_{i=1}^{n}P(x_i)log_2P(x_i)
−∑i=1nP(xi)log2P(xi),即底为2的熵。
(3)最大离散熵定理:
具有n个符号的离散信源,只有在n个信源等概率的情况下熵才能取得最大值,即等概率的熵最大,这叫做最大离散熵定理。
此定理是熵的判定中一个重要定理。
最大离散熵定理的证明:
已知条件: ∑ i = 1 n p i = 1 , H ( x ) = − ∑ i = 1 n p i l o g p i , p 1 = p 2 = . . = p i = p n , 根据拉格朗日乘数法则得: H ( x ) = − ∑ i = 1 n p i l o g p i + λ ( ∑ i = 1 n p i − 1 ) , ∂ H ( x ) ∂ p i = − n l o g p i − n + n λ = 0 , p i = 1 n ,由此得知: p i = e λ − 1 ,即 p i 服从指数分布 已知条件:\\ \sum _{i = 1} ^ np_i = 1, \\ H(x) = -\sum_{i=1}^{n} p_i log p_i,\\ p_1 = p_2 = .. = p_i = p_n,\\ 根据拉格朗日乘数法则得:\\ H(x) = -\sum_{i=1}^{n} p_i log p_i + \lambda(\sum _{i = 1}^n p_i -1) ,\\ \frac {\partial H(x)}{\partial p_i} = - nlogp_i - n + n \lambda = 0, p_i = \frac {1}{n},由此得知:\\ p_i = e ^ {\lambda - 1},即p_i服从指数分布 已知条件:i=1∑npi=1,H(x)=−i=1∑npilogpi,p1=p2=..=pi=pn,根据拉格朗日乘数法则得:H(x)=−i=1∑npilogpi+λ(i=1∑npi−1),∂pi∂H(x)=−nlogpi−n+nλ=0,pi=n1,由此得知:pi=eλ−1,即pi服从指数分布
(4)已知均值和方差时,正态分布下熵的值最大,该证明的参考链接如下:
https://zhuanlan.zhihu.com/p/309831227
(5)任何概率分布下的信息熵一定不会大于它对其它概率分布下自信息的数学期望(交叉熵有极小值)
证明:
∵
l
n
x
≤
x
−
1
∴
∑
i
=
1
n
p
i
×
l
n
q
i
p
i
≤
∑
i
=
n
n
p
i
×
(
q
i
p
i
−
1
)
=
∑
i
=
1
n
q
i
−
∑
i
=
1
n
p
i
=
0
∴
∑
i
=
1
n
p
i
×
l
n
q
i
p
i
=
∑
i
=
1
n
p
i
l
n
q
i
−
∑
i
=
1
n
p
i
l
n
p
i
≤
0
∴
∑
i
=
1
n
p
i
l
n
q
i
≤
∑
i
=
1
n
p
i
l
n
p
i
\because lnx \le x - 1\\ \therefore \sum _{i=1}^{n} p_i \times ln \frac {q_i}{p_i} \le \sum _{i=n} ^{n} p_i \times \bigl ( \frac{q_i}{p_i} - 1) = \sum _{i=1}^{n}q_i - \sum _{i=1} ^ {n} p_i = 0 \\ \therefore \sum _{i=1}^{n} p_i \times ln \frac {q_i}{p_i} = \sum _{i=1}^{n} p_i ln q_i - \sum _{i=1}^{n} p_i ln p_i \le 0 \\ \therefore \sum _{i=1}^{n} p_i ln q_i \le \sum _{i=1}^{n} p_i ln p_i
∵lnx≤x−1∴i=1∑npi×lnpiqi≤i=n∑npi×(piqi−1)=i=1∑nqi−i=1∑npi=0∴i=1∑npi×lnpiqi=i=1∑npilnqi−i=1∑npilnpi≤0∴i=1∑npilnqi≤i=1∑npilnpi
交叉熵有极小值也是机器学习的基础理论之一。
(6)熵函数具有上凸性,熵函数必有最大值。(此结论只针对离散随机变量)
(三)熵几个概念之间的图形化关系
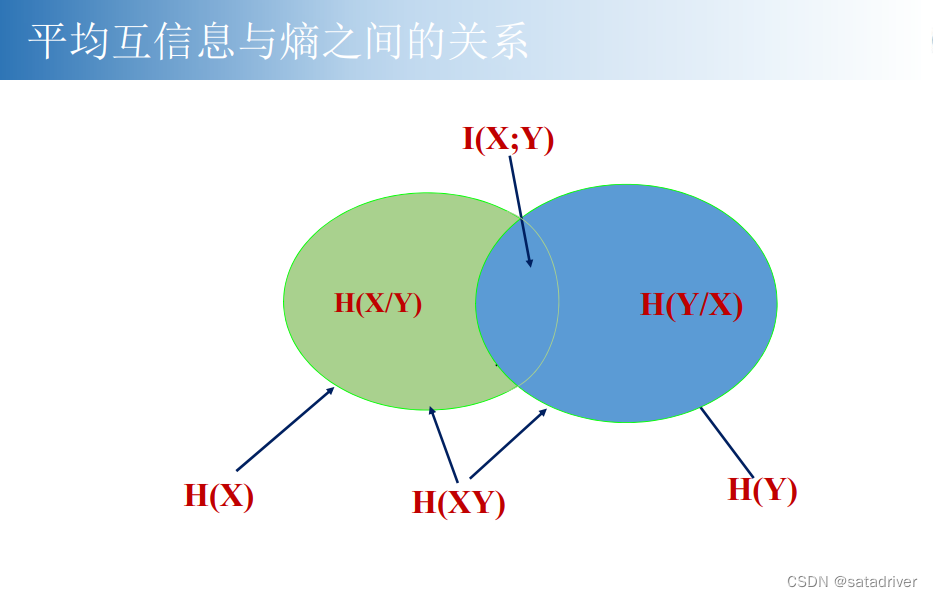
最后,关于信息论中各个部分的关系如下,其中:
图中H(X)与H(Y)是X,Y两个部分的熵,I(XY)是两者熵的重合部分。
H(X|Y)是H(X) 去掉I(XY)部分,H(Y|X)是H(Y) 去掉I(XY)部分,H(XY)是两者的面积去掉I(xy)的部分。