1.连接数据库
mysql (-h IP) -u root -p 密码
2.查看数据库
show databases
3.使用数据库
use db_name
4.查看表
show tables [from db_name]
5.查看表结构
desc tb_name
6.创建、删除、选择数据库
create database db_name
drop database db_name
use db_name
7.数据类型
参考链接:https://www.runoob.com/mysql/mysql-data-types.html
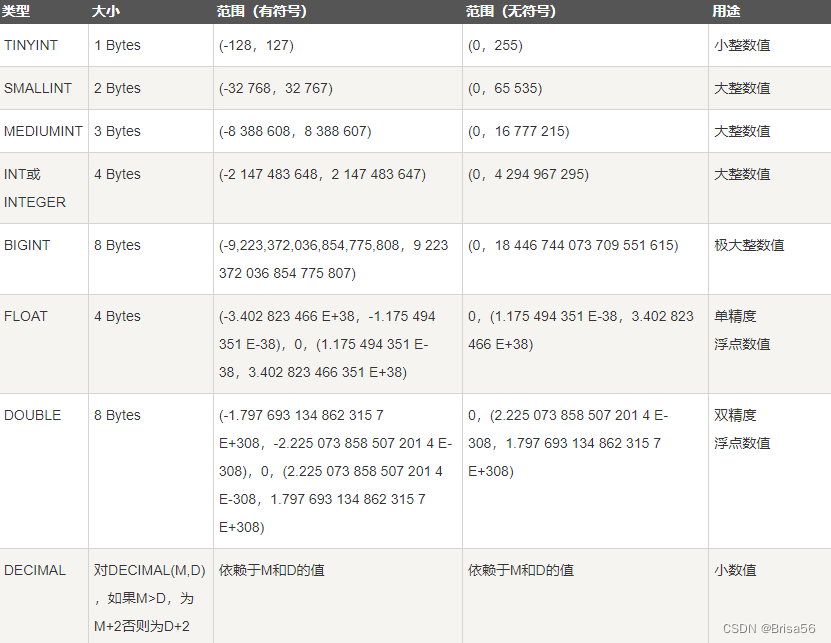
● 数值类型
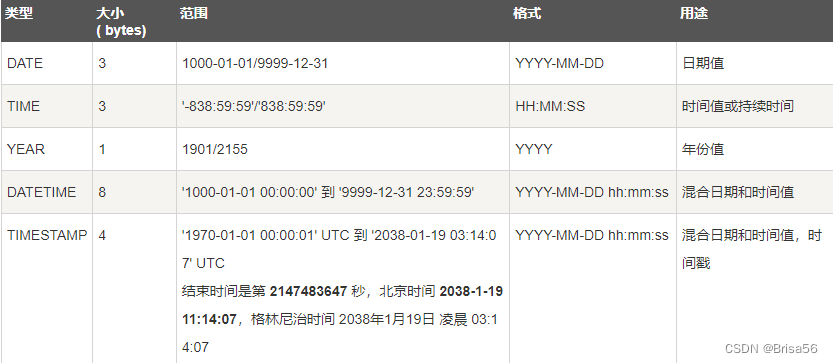
● 日期和时间类型
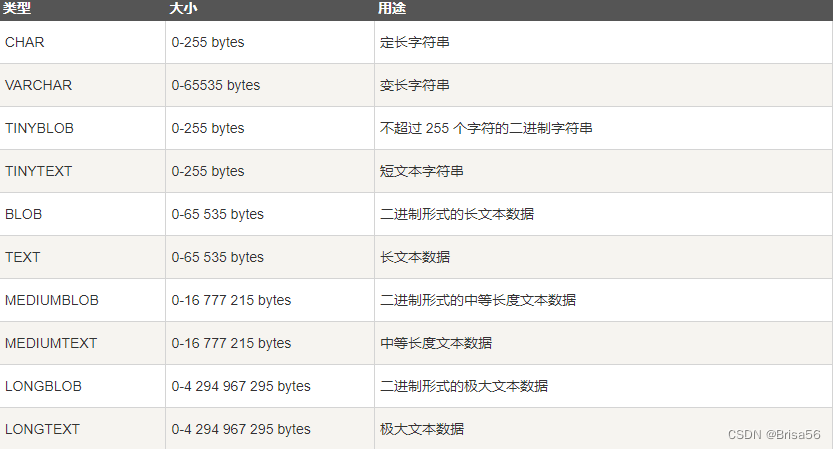
● 字符串类型
8.创建、删除数据表
create table [if not exsits] tb_name (
`id` INT UNSIGNED AUTO_INCREMENT,
`title` VARCHAR(100) NOT NULL,
`author` VARCHAR(40) NOT NULL,
`submission_date` DATE,
PRIMARY KEY ( `id` )
) default charset=utf8;
drop table tb_name
9.插入、查询、修改、删除数据
insert into tb_name (field1, field2,...,fieldN) values (value1, value2,...valueN)
select * from tb_name
select field1, field2,... from tb_name [where ...] [limit n] [offset m] -- n是限制查询返回的结果,m是开始查询的数据偏移量,默认0
select field1,field2,... from tb_name1, tb_name2,... [where condition1 and/or condition2 ...]
-- condition 中可以用如下操作符 =,<>或者!= (不等于),>,<,>=,<=
update tb_name set field1=xxx, fieldn=xxx [where caluse]
delete from tb_name [where clause]
10.like子句
-- SQL LIKE 子句中使用百分号 %字符来表示任意字符,类似于UNIX或正则表达式中的星号 *
-- 要获取 author 字段含有 "COM" 字符的所有记录
SELECT * from tb_name WHERE author LIKE '%COM'
11.注释
-- 采用 "--"(双减号)进行单行注释,注意:"--"与注释内容要用空格隔开才会生效
-- 采用 /*…*/进行多行注释
12.union
-- UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据
select expression1, expression2, ... expression_n from tb_name1 [where conditions]
UNION [ALL | DISTINCT] -- all 所有结果 distinct 删除重复数据
select expression1, expression2, ... expression_n from tb_name2 [where conditions];
13.排序
-- order by
select field1, ...,fieldn from tb_name [where clause] [order by field1 [asc], field2 desc]
-- order by 默认是asc升序排列
14.分组
-- group by 语句根据一个或多个列对结果集进行分组。
-- 在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
select column_name, function(column_name) from tb_name [where clause] group by column_name
-- WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)
select column_name1, function(column_name2) from tb_name [where clause] group by column_name [with rollup]
-- 我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:
select coalesce(a,b,c);
-- 参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
SELECT coalesce(name, '总数'), SUM(signin) as signin_count FROM employee_tbl GROUP BY name WITH ROLLUP;
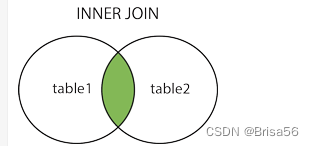
15.连接
-- 可以在 SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
-- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
select field1 from tb_name1 a inner join tb_name1 b on a.field2 = b.field3
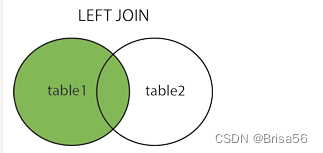
-- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
select field1 from tb_name1 a left join tb_name1 b on a.field2 = b.field3
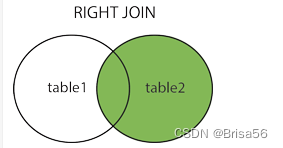
-- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
select field1 from tb_name1 a right join tb_name1 b on a.field2 = b.field3
16.NULL的处理
不能使用 = NULL 或 != NULL 在列中查找 NULL 值
在 MySQL 中,NULL 值与任何其它值的比较(即使是 NULL)永远返回 NULL,即 NULL = NULL 返回 NULL 。
MySQL 中处理 NULL 使用 IS NULL 和 IS NOT NULL 运算符。
-- IS NULL: 当列的值是 NULL,此运算符返回 true。
-- IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。
-- <=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。
select * from tb_name where field1 is null
select * from tb_name where field1 is not null
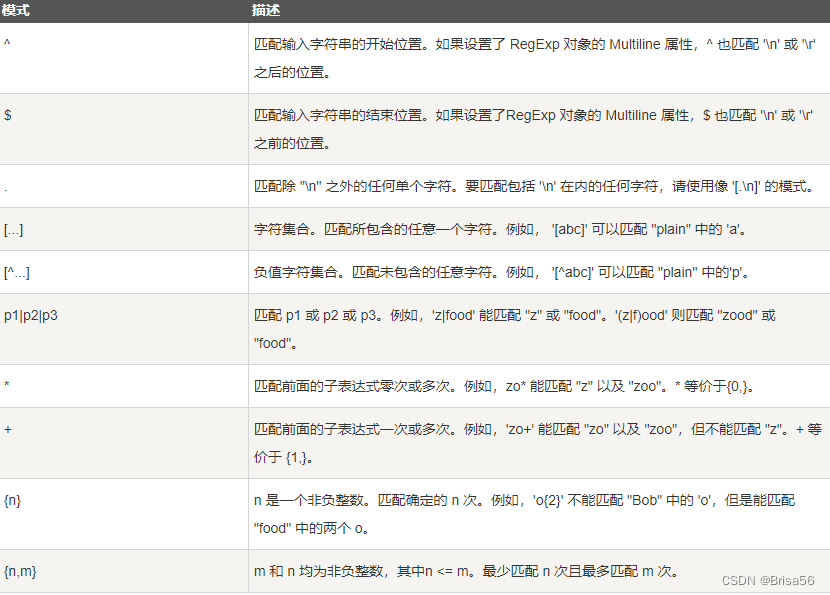
17.正则表达式
-- MySQL中使用 REGEXP 操作符来进行正则表达式匹配
SELECT * FROM tb_name WHERE field REGEXP '^xxx';
18.事务
事务控制语句
● BEGIN 或 START TRANSACTION 显式地开启一个事务;
● COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的;
● ROLLBACK 也可以使用 ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
● SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
● RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
● ROLLBACK TO identifier 把事务回滚到标记点;
● SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
MYSQL 事务处理主要有两种方法:
1.用 BEGIN, ROLLBACK, COMMIT来实现
● BEGIN 开始一个事务
● ROLLBACK 事务回滚
● COMMIT 事务确认
2.直接用 SET 来改变 MySQL 的自动提交模式:
● SET AUTOCOMMIT=0 禁止自动提交
● SET AUTOCOMMIT=1 开启自动提交
begin --开始事务
... --一些sql语句
commit (rollback) --结束、回滚事务
19.ALTER命令
-- 需要修改数据表名或者修改数据表字段时,就需要使用到 MySQL ALTER 命令。
-- 添加列
alter table tb_name add new_field_name data_type
-- 修改列
alter table tb_name modify field_name new_data_type --类型
alter table tb_name change old_field_name new_field_name data_type --名字,类型
--删除列
alter table tb_name drop field_name
-- 添加约束
alter table tb_name add primary key (field_name) -- 添加主键
alter table tb_name add foreign key (field_name) references referenced_tb (reference_field_name) -- 添加外键
alter table tb_name add constraint constraint_name unique (field_name) --添加唯一约束
-- 创建索引
alter table tb_name add index index_name(field_name1 [asc|desc],field_name2 [asc|desc] ,...) --普通索引
alter table tb_name add unique index index_name(field_name1 [asc|desc],field_name2 [asc|desc] ,...) -- 唯一索引
alter table tb_name drop index index_name --删除索引
-- 表重命名
alter table tb_name rename to new_tb_name
-- 修改表存储引擎
alter table tb_name engine=new_storage_engine
20.索引
-- 索引名在表中必须唯一
-- 创建索引
create [unique] index index_name on tb_name (ield_name1 [asc|desc],field_name2 [asc|desc] ,...)
-- 修改表为其添加索引
alter table tb_name add [unique] index index_name(field_name1 [asc|desc],field_name2 [asc|desc] ,...) --普通索引
-- 创建表时指定索引
create table tb_name (
...
index index_name [unique] (field_name1 [asc|desc],field_name2 [asc|desc] ,...)
)
-- 删除索引
drop index index_name on tb_name
alter table tb_name drop index index_name
-- 显示索引信息
show index from tb_name
21.临时表
-- MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
create temporary table tb_name (...)
22.复制表
-- 1、先获取表的完整结构
show create table tb_name
-- 2、复制上述结果,修改sql语句中的表面并执行sql语句
-- 3、拷贝数据
insert into clone_tb (...)
select (...) from origin_tb
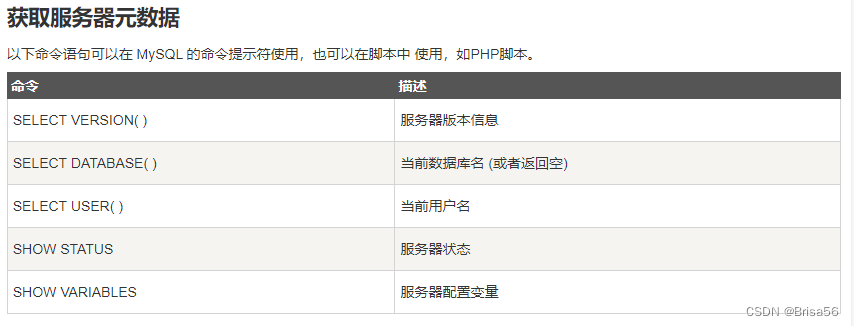
23.元数据
24.序列使用
AUTO_INCREMENT
25.处理重复数据
primary key
unique
-- 统计重复数据
/* 确定哪一列包含的值可能会重复。
在列选择列表使用COUNT(*)列出的那些列。
在GROUP BY子句中列出的列。
HAVING子句设置重复数大于1。 */
select count(*) as xx, filed1, field2 from tb_name group by field1,field2 having xx > 1
-- 过滤重复数据
select distinct field from tb_name
-- 删除重复数据
26.导出、导入数据
-- 使用 SELECT ... INTO OUTFILE 语句导出数据
select * into outfile '地址' [fields terminated by ',' optionally enclosed by '"'
lines terminated BY '\n']
from tb_name
-- 导入数据
source '地址' --sql文件
load data local infile '地址' into table tb_name
27.函数、运算符
函数:https://www.runoob.com/mysql/mysql-functions.html
运算符:https://www.runoob.com/mysql/mysql-operator.html






![[Kubernetes]Kubeflow Pipelines - 基本介绍与安装方法](https://img-blog.csdnimg.cn/cc1407aa91ba4f59bf08118ecfd7cd66.png)