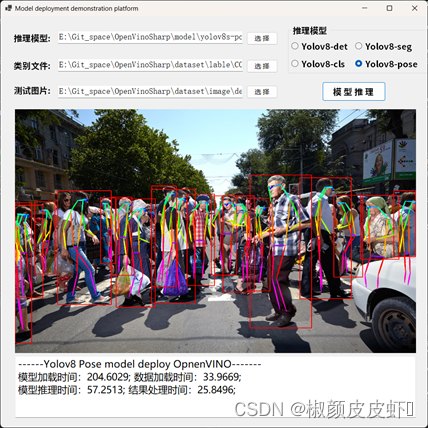
1)最大二叉树
654. 最大二叉树 - 力扣(LeetCode)
题目解析:
1)首先我们找到了整个数组中最大的元素作为我们的根节点,然后再从左区间中找到最大的元素作为当前根节点的左子树,然后再从右区间里面找到最大的元素作为根节点的右子树
2)本题中使用前序遍历的方式来构建一棵二叉树,像这种构建一颗二叉树的题目都是必须先进行遍历出根节点,然后再进行构建右树或者是左树
class Solution { public TreeNode createTree(int[] nums,int left,int right){ if(left>right) return null; int maxIndex=left; int maxData=nums[left]; for(int i=left+1;i<=right;i++){ if(nums[i]>maxData){ maxData=nums[i]; maxIndex=i; } } TreeNode root=new TreeNode(maxData); root.left=createTree(nums,left,maxIndex-1); root.right=createTree(nums,maxIndex+1,right); return root; } public TreeNode constructMaximumBinaryTree(int[] nums) { return createTree(nums,0,nums.length-1); } }2)二叉树迭代器
173. 二叉搜索树迭代器 - 力扣(LeetCode)思路1:我们可以将二叉搜索树做一次完全的中序遍历,获取中序遍历的结果并存放到数组中,随后我们可以利用数组本身来实现迭代器
class BSTIterator { private int index=-1; private List<Integer> result; public void dfs(TreeNode root){ if(root==null) return; dfs(root.left); result.add(root.val); dfs(root.right); } public BSTIterator(TreeNode root) { result=new ArrayList<>(); index=0;//记录当前遍历到哪一个位置 dfs(root); } public int next() { return result.get(index++); } public boolean hasNext() { return index<result.size(); } }思路2:除了递归的方法之外,我们还可以使用迭代的方式针对于整棵二叉树做中序遍历,但是我们无需对这棵二叉树做一个完整的中序遍历,只需要维护栈的情况即可
class BSTIterator { Stack<TreeNode> stack=new Stack<>(); TreeNode current=null; public BSTIterator(TreeNode root) { this.current=root; } public int next() { while(current!=null){ stack.push(current); current=current.left; } TreeNode node=stack.pop(); current=node.right; return node.val; } public boolean hasNext() { return !stack.isEmpty()||current!=null; } }3)合并二叉树
解法1:深度优先遍历
同时遍历两颗二叉树的根节点左节点和右节点
class Solution { public TreeNode mergeTrees(TreeNode root1, TreeNode root2) { if(root1==null) return root2; if(root2==null) return root1; TreeNode root=new TreeNode(root1.val+root2.val); root.left=mergeTrees(root1.left,root2.left); root.right=mergeTrees(root1.right,root2.right); return root; } }解法2:宽度优先遍历:
在这里面我们使用的是三个队列,第一个队列存放的是第一个二叉树的左右节点,第二个队列存放的是第二个二叉树的左右节点,第三个队列存放的是合并完之后的节点充当根节点;
class Solution { public TreeNode mergeTrees(TreeNode root1, TreeNode root2) { if(root1==null) return root2; if(root2==null) return root1; Queue<TreeNode> queue1=new LinkedList<>(); Queue<TreeNode> queue2=new LinkedList<>(); Queue<TreeNode> queue=new LinkedList<>(); queue1.add(root1); queue2.add(root2); TreeNode rootNode=new TreeNode(root1.val+root2.val); queue.add(rootNode); while(!queue1.isEmpty()&&!queue2.isEmpty()){ TreeNode root=queue.poll(); TreeNode node1=queue1.poll(); TreeNode node2=queue2.poll(); TreeNode left1=node1.left; TreeNode right1=node1.right; TreeNode left2=node2.left; TreeNode right2=node2.right; if(left1!=null||left2!=null){ if(left1!=null&&left2!=null){ TreeNode left=new TreeNode(left1.val+left2.val); root.left=left; queue.add(left); queue1.add(left1); queue2.add(left2); }else if(left1!=null){ root.left=left1; }else if(left2!=null){ root.left=left2; } } if(right1!=null||right2!=null){ System.out.println(11); if(right1!=null&&right2!=null){ TreeNode right=new TreeNode(right1.val+right2.val); root.right=right; queue.add(right); queue1.add(right1); queue2.add(right2); }else if(right1!=null){ root.right=right1; }else if(right2!=null){ root.right=right2; } } } return rootNode; } }4)二叉树的最大路径和
124. 二叉树中的最大路径和 - 力扣(LeetCode)
算法原理:本体还是使用后序遍历的方式来做的,因为进行计算二叉树的最大路径和,针对于每一个节点来说,都是采取这样的方式来进行计算的:
1)递推公式:当前节点的路径和=当前的结点的值+左节点向上最大路径+右节点向上路径和
2)而左右节点又是拥有着自己的路径和,而这些路径和又有可能是最大的路径和
3)节点向上最大路径:当前节点+Math.max(左子树的最大路径,右子树的最大路径)
在这里面dfs函数被赋予的任务就是得到一个根节点的向上返回的最大路径
4)相当于是说我们在求出从一个节点到叶子节点的最大路径和的过程中就更新了最终想要的结果
class Solution { //返回经过root的单边分支最大和,即Math.max(root, root+left, root+right) int max=Integer.MIN_VALUE; public int dfs(TreeNode root){ if(root==null) return 0; //计算左边分支最大值,左边分支如果为负数还不如不选择 int left=Math.max(dfs(root.left),0); //计算右边分支最大值,右边分支如果为负数还不如不选择,left->root->right 作为路径与已经计算过历史最大值做比较 int right=Math.max(dfs(root.right),0); //更新最终结果 max=Math.max(left+root.val+right,max); //返回经过root的单边最大分支给当前root的父节点计算使用 return root.val+Math.max(left,right); } public int maxPathSum(TreeNode root) { dfs(root); return max; } }
5)验证二叉树的前序序列化
331. 验证二叉树的前序序列化 - 力扣(LeetCode)
解法1:将所有的#当作是一个叶子节点,所有的非#字符当成一个非叶子节点,那么最终要满足的条件就是度是0的叶子节点=度是2的节点+1
在没有针对于整个二叉树做先序遍历之前,叶子结点的数量一定是小于等于非叶子节点的数量的
class Solution { public boolean isValidSerialization(String str) { int leafCount=0; int nodeCount=0; String[] string=str.split(","); for(String s:string){ if(leafCount>nodeCount) return false; if(s.equals(",")) continue; else if(s.equals("#")) leafCount++; else nodeCount++; } return nodeCount+1==leafCount; } }class Solution { public boolean isValidSerialization(String str) { int leafCount=0; int nodeCount=0; String[] strings=str.split(","); for(int i=strings.length-1;i>=0;i--){ if(strings[i].equals("#")) leafCount++; else{ if(leafCount>=2) leafCount--; else return false; } } return leafCount==1; } }
6)二叉搜索树中的众数:
采用左中右中序遍历的方式来解决这道问题
class Solution { List<Integer> list=new ArrayList<>(); int prev=Integer.MIN_VALUE; int count=0; int maxCount=-1; public void dfs(TreeNode root){ if(root==null) return; dfs(root.left); //更新count值 if(prev==Integer.MIN_VALUE){ count=1; }else if(prev==root.val){ count++; }else count=1; //更新最终结果 if(count==maxCount) list.add(root.val); else if(count>maxCount){ list.clear(); list.add(root.val); maxCount=count; } //修改指针指向 prev=root.val; dfs(root.right); } public int[] findMode(TreeNode root) { dfs(root); int[] nums=new int[list.size()]; System.out.println(list); int i=0; for(int num:list){ nums[i]=num; i++; } return nums; } }class Solution { public int MaxCount=Integer.MIN_VALUE; public int prev=Integer.MAX_VALUE; HashMap<Integer,Integer> map=new HashMap<>(); public int count=0; public void dfs(TreeNode root){ if(root==null) return; dfs(root.left); if(root.val==prev){ count++; }else{ count=1; } if(count>=MaxCount){ MaxCount=count; map.put(root.val,MaxCount); } prev=root.val; dfs(root.right); } public int[] findMode(TreeNode root) { if(root.left==null&&root.right==null) return new int[]{root.val}; dfs(root); List<Integer> list=new ArrayList<>(); for(Map.Entry<Integer,Integer> entry:map.entrySet()){ if(entry.getValue()==MaxCount){ list.add(entry.getKey()); } } int[] result=new int[list.size()]; int index=0; for(int num:list){ result[index]=num; index++; } return result; } } 控制台7)二叉搜索树的最近公共祖先:
1)如果是单纯的针对于二叉树来说,最近公共祖先就是我们在左子树中进行寻找有没有出现过p或者是q,然后如果左子树中有,那么就直接返回根节点,然后再从右子树中进行寻找p或者是q,如果右子树中也没有,那么直接返回null,有的话直接返回根节点,只要左子树或者是右子树出现了p或者是q就像向上返回,当然这也是我们的重复子问题;
2)针对于这个题来说,本质上还是使用后序遍历的的方式来进行处理,因为左右根,我们可以在根节点拿到左右子树的信息,从而进行整合,然后最后将根节点向上返回
class Solution { public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if(root==null) return null; else if(p.val<root.val&&q.val>root.val) return root; else if(p.val>root.val&&q.val<root.val) return root; else if(p==root) return p; else if(q==root) return q; else{ TreeNode root1=lowestCommonAncestor(root.left,p,q); TreeNode root2=lowestCommonAncestor(root.right,p,q); if(root1==null&&root2==null){ return null; }else if(root1!=null&&root2==null){ return root1; }else if(root1!=null&&root2!=null){ return root; }else{ return root2; } } } }class Solution { public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if(root==null) return root; if(p.val==root.val||q.val==root.val) return root; if(p.val<root.val&&q.val<root.val){ TreeNode left=lowestCommonAncestor(root.left,p,q); System.out.println(left.val); if(left!=null) return left; }else if(p.val>root.val&&q.val>root.val){ TreeNode right=lowestCommonAncestor(root.right,p,q); if(right!=null) return right; } return root; } }非递归代码:利用二叉搜索树的特性
class Solution { public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if(root==null) return null; while(root!=null){ if(root.val>p.val&&root.val>q.val){ root=root.left; }else if(root.val<p.val&&root.val<q.val){ root=root.right; }else{ return root; } } return null; } }
8)路经总和:
目标是遍历到叶子结点的时候进行收集结果
class Solution { List<Boolean> list=new ArrayList<>(); int sum=0; int targetSum=0; List<Integer> path=new ArrayList<>(); public void dfs(TreeNode root){ if(root==null) return; if(root.left==null&&root.right==null){ sum+=root.val; if(sum==targetSum){ list.add(true); }else{ list.add(false); } sum-=root.val; return; } if(root.left!=null){ path.add(root.val); sum+=root.val; dfs(root.left); sum-=root.val; path.remove(path.size()-1); } if(root.right!=null){ path.add(root.val); sum+=root.val; dfs(root.right); sum-=root.val; path.remove(path.size()-1); } } public boolean hasPathSum(TreeNode root, int targetSum) { this.targetSum=targetSum; dfs(root); System.out.println(list); for(boolean flag:list){ if(flag==true) return true; } return false; } }解法2:还是回溯+递归:
1)目的是当我们进行深度优先遍历的时候,遇到一个结点的时候就让sum-root.val就做一次减法,如果遇到叶子节点,况且此时我们的sum值被减为0了,说明沿着路径的节点进行相加和等于目标值
2)递归的结束出口也是我们收集结果的的一个出口:
class Solution { public boolean dfs(TreeNode root,int targetSum){ if(root==null) return false; if(root.left==null&&root.right==null){ targetSum=targetSum-root.val; if(targetSum==0) return true; else return false;//说明这个路径不是我所想要的路径 } boolean flag1=false,flag2=false; //将左子树是否出现了等于目标和的路径返回给根节点 if(root.left!=null) flag1=dfs(root.left,targetSum-root.val);//回溯的过程做隐藏了 //将右子树是否出现了等于目标和的路径返回给根节点,回溯的过程体现在递归函数的下面 if(root.right!=null) flag2=dfs(root.right,targetSum-root.val); //向上一层进行返回 return flag1||flag2; } public boolean hasPathSum(TreeNode root, int targetSum) { return dfs(root,targetSum); } }

9)二叉树的最大直径
算法原理:
1)首先求出一个根节点的左子树的深度,在求出右子树的深度
2)此时以当前根节点为二叉树的直径就是左子树的深度+右子树的深度
3)相当于是说在求出二叉树的高度的时候就可以直接更新结果了
543. 二叉树的直径 - 力扣(LeetCode)
class Solution { int max=0; public int getHeight(TreeNode root){ if(root==null) return 0; if(root.left==null&&root.right==null) return 1; int leftHeight=getHeight(root.left); int rightHeight=getHeight(root.right); //更新结果 max=Math.max(max,leftHeight+rightHeight); //返回树的高度 return Math.max(leftHeight,rightHeight)+1; } public int diameterOfBinaryTree(TreeNode root) { getHeight(root); return max; } }
10)二叉树的坡度:
563. 二叉树的坡度 - 力扣(LeetCode)
算法原理:二叉树的坡度就是左子树的节点之和和右子树的节点之和的差的绝对值
这道算法题是在递归的过程中在不断的进行更新结果值,其实本质上dfs被赋予的任务就是计算出每一个节点的左右子树之和+当前根节点之和
lass Solution { int sum=0; public int dfs(TreeNode root){ if(root==null) return 0; int left=dfs(root.left); int right=dfs(root.right); sum=sum+Math.abs(left-right); return left+right+root.val; } public int findTilt(TreeNode root) { dfs(root); return sum; } }
11)在二叉树中增加一行
623. 在二叉树中增加一行 - 力扣(LeetCode)
12)二叉树的锯齿形层序遍历:
103. 二叉树的锯齿形层序遍历 - 力扣(LeetCode)