内容为:https://juejin.cn/book/7240731597035864121的学习笔记
导包
import numpy as np
numpy数组创建
- 创建全0数组,正态分布、随机数组等就不说了,提供了相应的方法
- 通过已有数据创建有两种 arr1=np.array([1,2,3,4,5]) 或者data=np.loadtxt(‘C:/Users/000001_all.csv’,dtype=‘float’,delimiter=‘,’,skiprows=1) (data=np.genfromtxt(‘C:/Users/000001_all.csv’,dtype=‘float32’,delimiter=‘,’,skip_header=1) )
- 注意浅拷贝与深拷贝
arraycopy是深,asarray是浅
import numpy as np
arr1=np.array([1,2,3,4,5])
arr2=np.array(arr1)
arr3=np.asarray(arr1)
arr4=np.copy(arr1)
arr1[0]=100
print('更改后arr2为:',arr2)
print('更改后arr3为:',arr3)
print('更改后arr4为:',arr4)
更改后arr2为: [1 2 3 4 5]
更改后arr3为: [100 2 3 4 5]
更改后arr4为: [1 2 3 4 5]
- 数组的切片也是浅拷贝
Score=np.array([69,80,90,40,60,20,90,94,90,99])#学生的成绩
Score[:3]=0
print('修改切片对象成绩后的Score为',Score)
Score1=[69,80,90,40,60,20,90,94,90,99]
Score1_list=Score1[:3]
Score1_list=0
print('修改Score1_list后的Score1为',Score1)
修改切片对象成绩后的Score为 [ 0 0 0 40 60 20 90 94 90 99]
修改Score1_list后的Score1为 [69, 80, 90, 40, 60, 20, 90, 94, 90, 99]
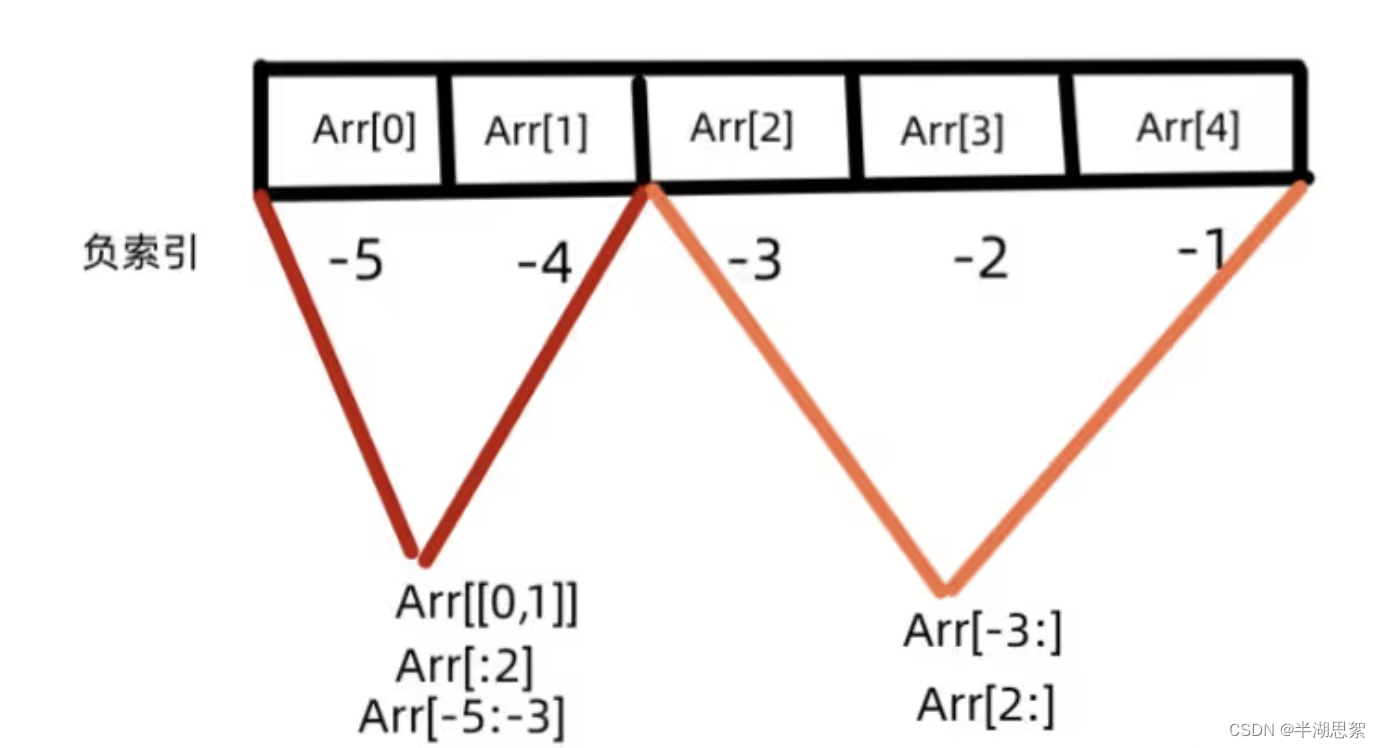
索引的访问
访问某个下标(一个元素)得到的也是一个数值;如果访问的是多个下标,得到的是一个数组
一维
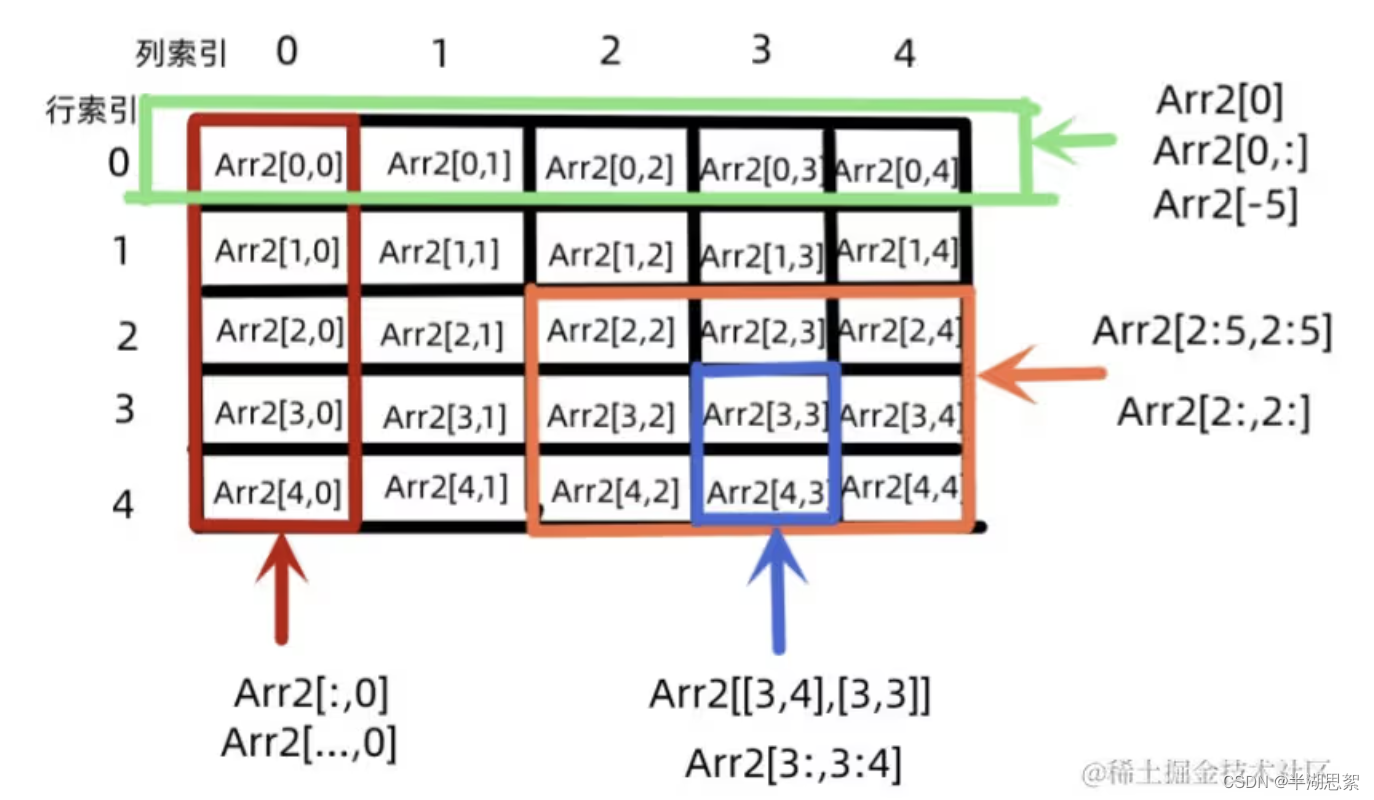
二维
Score2=np.array([[69,40,30],[80,90,40],[90,100,50],[40,20,99],[60,60,66],
[20,66,44],[90,88,56],[94,99,67],[90,20,70],[99,50,86]])
print('学号为1的同学的语文和英语成绩为',Score2[[0,0],[0,2]])
学号为 1 的同学的语文和英语成绩为 [69 30]
三维
Space=np.array([
[[5,4,8],[5,9,2],[4,5,3]],
[[4,9,6],[2,2,5],[4,3,4]],
[[4,2,1],[7,6,3],[4,6,5]]
])
print(Space[[0,0,1],[0,1,2],[0,0,2]])
[5 5 4]

数组的运算
广播
3种
广播机制的原则是如果两个数组的从后数第一个维度轴长度相符或其中一个数组的轴长为 1,则认为它们能够广播
- 一
Arr1=np.array([1,2,3])
print(Arr1)
print(Arr1*3)
[1 2 3]
[3 6 9]
- 二
Arr2=np.array([[1,2,3],[4,5,6]])
Arr1=np.array([1,2,3])
print(Arr1)
print(Arr2)
print(Arr1+Arr2)
[1 2 3]
**********
[[1 2 3]
[4 5 6]]
**********
[[2 4 6]
[5 7 9]]
- 三
Arr2=np.array([[1,2,3],[4,5,6]])
Arr=np.array([[1],[2]])
print(Arr2)
print(Arr)
print(Arr2+Arr)
[[1 2 3]
[4 5 6]]
**********
[[1]
[2]]
**********
[[2 3 4]
[6 7 8]]
数值与数组的标量运算,就用到了广播机制,会把数据扩充到跟待运算一样的大小,按位相加/减/乘/除
计算函数
除了可以arr1与arr2直接相运算,如arr1*arr2,也有相应的方法
方法:add() 加法函数,subtract() 减法函数,multiply() 乘法函数,divide() 除法函数,mod() 取余函数。
Score_F=np.array([69,80,90,40,60,20,90,94,90,99])#第一次成绩
Score_S=np.array([70,92,63,20,50,96,33,44,55,30])#第二次成绩
Score_chaju=np.subtract(Score_F,Score_S)
print('求两次成绩的和',np.add(Score_F,Score_S))
print('第一次成绩的0.6加第二次成绩的0.4',np.add(np.multiply(Score_F,0.6),np.multiply(Score_S,0.4)))
print('查看两次成绩的差距,差距以正数显示',np.abs(Score_chaju))
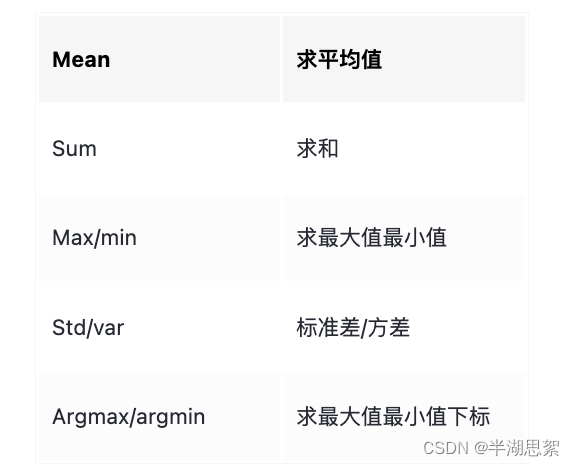
统计函数
axis有两个值,为0求的是纵向的聚合值,为1求的是横向的聚合值,
常用的聚合函数如下:mean,sum,max,min,std,var
标准差是方差的算数平方根(标准差和原数据单位相同,方差多个平方),所以方差>标准差,说明偏差大;方差<标准差,说明偏差小

逻辑运算
提供了all、any 和 where 这三个方法
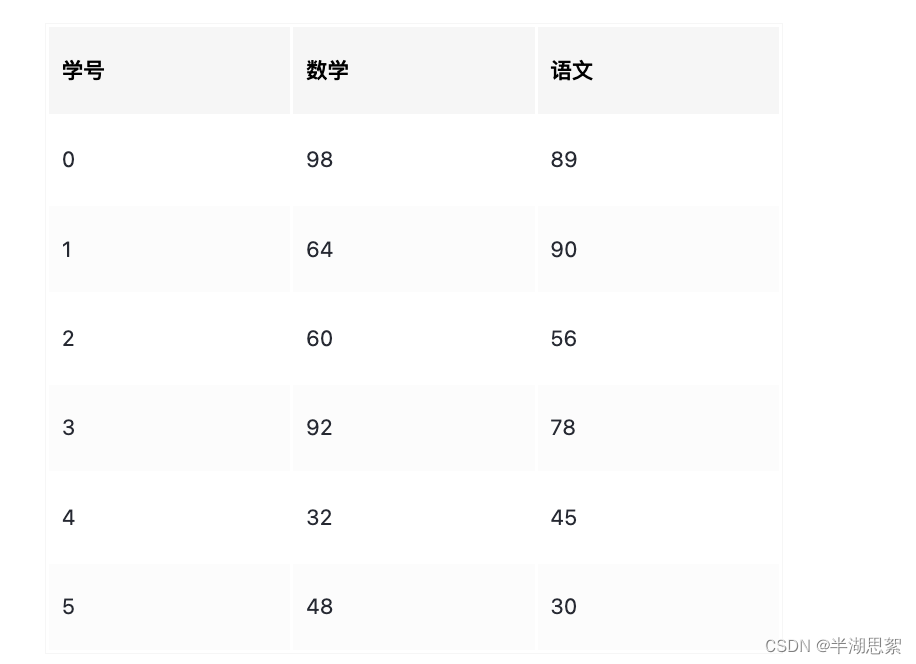
# 得到两门成绩都及格的同学的成绩
import numpy as np
Score=np.array([[98,89],[64,90],[60,56],[92,78],[32,45],[48,30]])
Score60=Score>60
Score_bool=np.all(Score60,axis=1)
print(Score_bool)
print(Score[Score_bool])
[ True True False True False False]
[[98 89]
[64 90]
[92 78]]
#查看数学或者语文超过 90 分同学的成绩
Score90=Score>90
Score_bool=np.any(Score90,axis=1)
print(Score_bool)
print(Score[Score_bool])
[ True False False True False False]
[[98 89]
[92 78]]
# 成绩大于60的分数有哪些
import numpy as np
Score_math=np.array([98,64,60,92,32,48])
score60_index = np.where(Score_math>60)
score60 = Score_math[score60_index]
print(score60_index)
print(score60)
(array([0, 1, 3]),)
[98 64 92]
矩阵运算
可以用@或dot来实现,它俩是等价的
注意是(3, 2)*(2, 4)=(3, 4) 只有
fruit_price=np.array([[5,4,3]]) # 1*3
jinshu=np.array([[2],[3],[1]]) # 3*1
print('水果的总价格为:\n',fruit_price@jinshu) #得到的是1*1的矩阵
print('水果的总价格为:\n',np.dot(fruit_price,jinshu))
水果的总价格为:
[[25]]
水果的总价格为:
[[25]]
数组的拆分与合并
合并
水平可以用concatenate 方法、hstack 方法和 column_stack 方法
垂直可以用concatenate 方法、vstack 方法和 row_stack 方法
- 水平
import numpy as np
Stock1=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802]])
Stock2=np.array([[14.652,14.192],[14.832,14.422],[15.022,14.592],[15.152,14.722]])
# 方式1
Stock=np.concatenate((Stock1,Stock2),axis=1)
# 方式2
Stock=np.hstack((Stock1,Stock2))
# 方式3
Stock=np.column_stack((Stock1,Stock2))
print(Stock)#上面3种得到的结果一样,写一块了
[[14.322 14.552 14.652 14.192]
[14.472 14.532 14.832 14.422]
[14.592 15.022 15.022 14.592]
[14.852 14.802 15.152 14.722]]
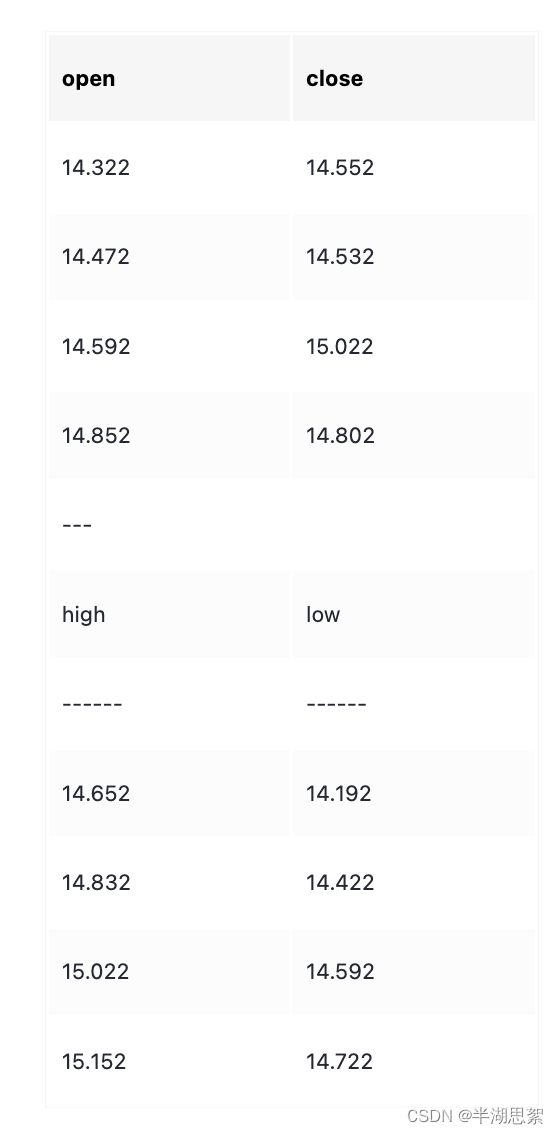
- 垂直
import numpy as np
Stock1=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802]])
Stock2=np.array([[14.912,14.932],[14.772,14.602]])
Stock=np.concatenate((Stock1,Stock2),axis=0)
Stock=np.vstack((Stock1,Stock2))
Stock=np.row_stack((Stock1,Stock2))
print(Stock)
[[14.322 14.552]
[14.472 14.532]
[14.592 15.022]
[14.852 14.802]
[14.912 14.932]
[14.772 14.602]]
分割
# 水平
import numpy as np
Stock=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802],[14.912,14.932],[14.772,14.602]])
open,close=np.split(Stock,2,axis=1)
print('open为{},close为{}'.format(open,close))
open为[[14.322]
[14.472]
[14.592]
[14.852]
[14.912]
[14.772]],close为[[14.552]
[14.532]
[15.022]
[14.802]
[14.932]
[14.602]]
# 垂直
# 这里面对行下标做切分,包含头不包含尾如按[1,3,4]: 0, 1,2, 3, 4,5
import numpy as np
Stock=np.array([[14.322,14.552],[14.472,14.532],[14.592,15.022],[14.852,14.802],[14.912,14.932],[14.772,14.602]])
arr1,arr2,arr3,arr4=np.split(Stock,[1,3,4],axis=0)
print('arr1为{},arr2为{},arr3为{},arr4为{}'.format(arr1,arr2,arr3,arr4))
arr1为[[14.322 14.552]],arr2为[[14.472 14.532]
[14.592 15.022]],arr3为[[14.852 14.802]],arr4为[[14.912 14.932]
[14.772 14.602]]
综合案例:
https://juejin.cn/book/7240731597035864121/section/7255506664244117559