引言
本文介绍检索式对话系统进阶方法,主要介绍两篇论文工作。
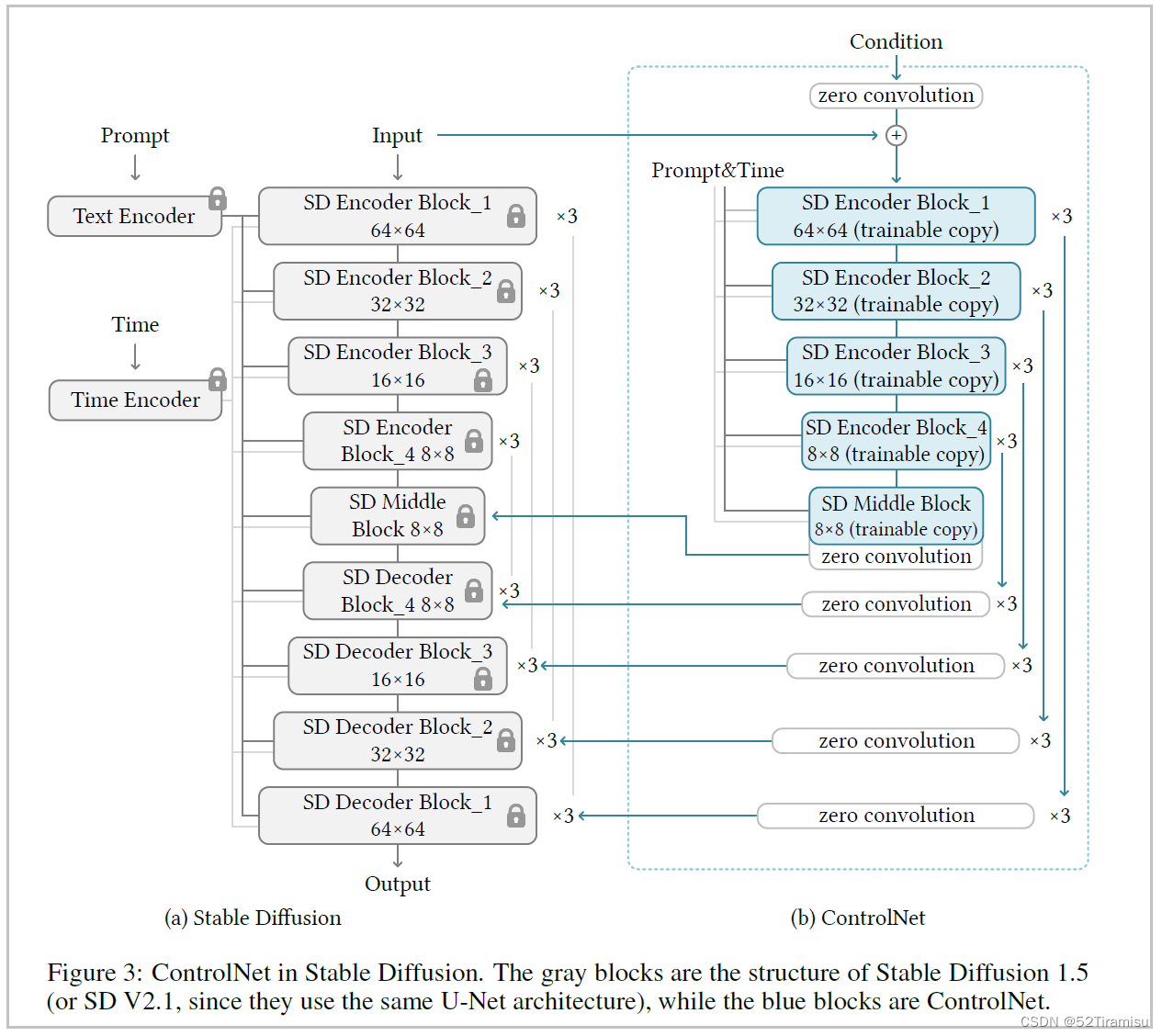
Fine-grained Post-training for Improving Retrieval-based Dialogue Systems
这里的post-training是定义在pre-training和fine-turning中间的阶段,具体的思想是用一些特定领域的数据去做更深入的预训练。
比如做金融相关的对话系统,那么可以用预训练模型在金融领域数据集上去做进一步地预训练,最后再拿一些有标签数据做微调。
模型
假设数据集
D
=
{
(
c
i
,
r
i
,
y
i
)
}
i
=
1
N
D=\{(c_i,r_i,y_i)\}_{i=1}^N
D={(ci,ri,yi)}i=1N是一个由
N
N
N个三元组组成的数据集,三元组包含上下文
c
i
c_i
ci、回复
r
i
r_i
ri和真实标签
y
i
y_i
yi。
上下文就是语句序列
c
i
=
{
u
1
,
u
2
,
⋯
,
u
M
}
c_i=\{u_1,u_2,\cdots,u_M\}
ci={u1,u2,⋯,uM},这里
M
M
M是最大上下文长度;
第
j
j
j个语句
u
j
=
{
w
j
,
1
,
⋯
,
w
j
,
L
}
u_j=\{w_{j,1},\cdots,w_{j,L}\}
uj={wj,1,⋯,wj,L}包含了
L
L
L个token,
L
L
L是最大序列长度;
每个回复
r
i
r_i
ri是单个语句;
标签
y
i
∈
{
0
,
1
}
y_i \in \{0,1\}
yi∈{0,1},
y
i
=
1
y_i=1
yi=1表示给定的三元组中
r
i
r_i
ri是关于上下文
c
i
c_i
ci的正确回复;
这里的任务是去找到给定数据
D
D
D的匹配模型
g
(
⋅
,
⋅
)
g(\cdot,\cdot)
g(⋅,⋅),给定一个上下文-回复对
(
c
i
,
r
i
)
(c_i,r_i)
(ci,ri),该模型输出它们的匹配程度。
从预训练语言模型问世之后,几乎都是使用预训练-微调的范式。那么如何应用该范式到检索任务中呢。
首先这项工作是基于二分类去微调BERT来做回复选择任务,分析上下文和回复之间的关系。现有的BERT输入格式是([CLS],sequence A,[SEP],sequence B,[SEP]),其中[CLS]和[SEP]是CLS和SEP词元。
为了衡量上下文-回复对的匹配程度,通过将sequence A作为上下文、sequence B作为回复的形式构建输入。另外,将语句结束词元(EOU,end of the utterance)放到语句后面用于在上下文中区分它们。即对于BERT的输入格式为:
x
=
[
C
L
S
]
u
1
[
E
O
U
]
⋯
u
M
[
E
O
U
]
[
S
E
P
]
r
i
[
S
E
P
]
(1)
x = [CLS] \,\, u_1\,\, [EOU] \cdots u_M \,\, [EOU] \,\, [SEP]\,\, r_i\,\, [SEP] \tag 1
x=[CLS]u1[EOU]⋯uM[EOU][SEP]ri[SEP](1)
x
x
x经过位置、片段和词元嵌入的累加后变成输入表示。BERT中的transformer 块会计算上下文和回复输入表示之间的交叉注意力,通过自注意力机制。然后,BERT中第一个输入词元
T
[
C
L
S
]
T_{[CLS]}
T[CLS]最终的隐状态作为上下文-回复对的聚合表示。最后的得分
g
(
c
,
r
)
g(c,r)
g(c,r),即上下文和回复之间的匹配得分,通过将这个
T
[
C
L
S
]
T_{[CLS]}
T[CLS]喂给一个单层神经网络而得:
g
(
c
,
r
)
=
σ
(
W
f
i
n
e
T
[
C
L
S
]
+
b
)
(2)
g(c,r) = \sigma(W_{fine}T_{[CLS]} +b) \tag 2
g(c,r)=σ(WfineT[CLS]+b)(2)
其中
W
f
i
n
e
W_{fine}
Wfine是任务相关的可训练参数,用于微调。最终,使用交叉熵损失更新模型的参数:
L
o
s
s
=
−
∑
(
c
i
,
r
i
,
y
i
)
∈
D
y
i
log
(
g
(
c
i
,
r
i
)
)
+
(
1
−
y
i
)
log
(
1
−
g
(
c
i
,
r
i
)
)
(3)
Loss = -\sum_{(c_i,r_i,y_i) \in D} y_i \log (g(c_i,r_i)) + (1-y_i) \log (1-g(c_i,r_i)) \tag 3
Loss=−(ci,ri,yi)∈D∑yilog(g(ci,ri))+(1−yi)log(1−g(ci,ri))(3)
那在pre-training和fine-tuning的基础上如何加入post-training呢?
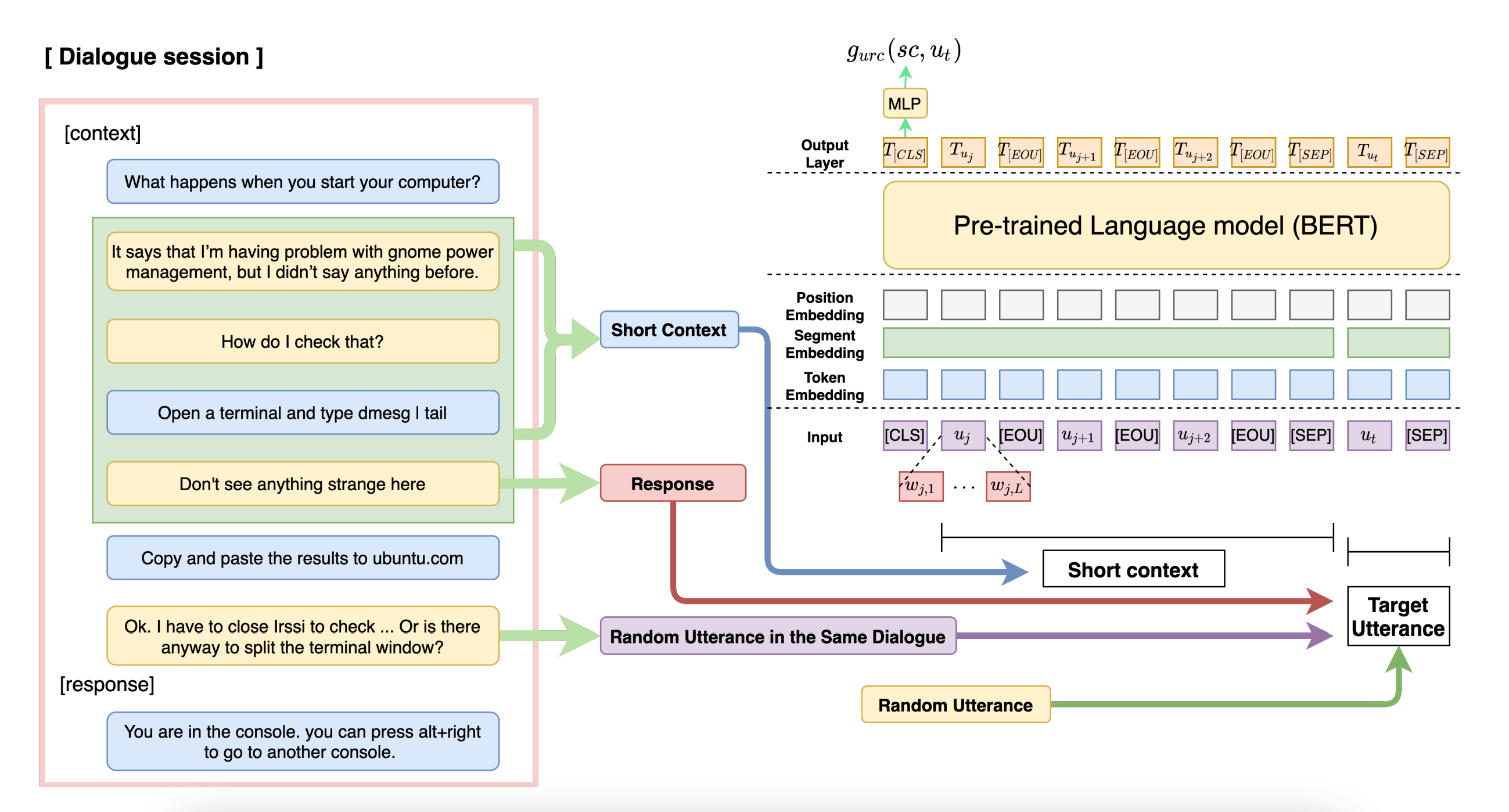
如上图所示,短上下文长度
k
=
3
k=3
k=3。post-training方法有两个学习策略。整个会话被分为多个短上下文-回复对,并使用URC(见下文解释)作为训练目标之一。通过前者模型学习了对话中内部语句的相关性,通过后者学习了语句间的语义相关性和连贯性。
构建多个短上下文-回复对的目的是学习语句级的交互。把每个语句看成是一个回复,且它的前 k k k个语句看成是短上下文。每个短上下文-回复对用于训练内部的语句交互,最终允许模型理解整个对话中所有语句的关系。同时也让模型学习与回复相邻语句的紧密交互,因为上下文并设定为一个较短的长度。
NSP任务不足以捕获语句见的连贯性。因为NSP通过区分随机和下一句主要学习了主题的语义相关性。通过使用SOP(sentence-order prediction)作为一个目标函数,由于模型学习了具有相似主题的两个语句的连贯性,使得识别语义相关性的能力降低。
为了同时学习一个对话中的语义相关性和连贯性,作者提出了一个新的称为URC(utterance relevance classification,语句关系分类)的目标函数。如下图所示:
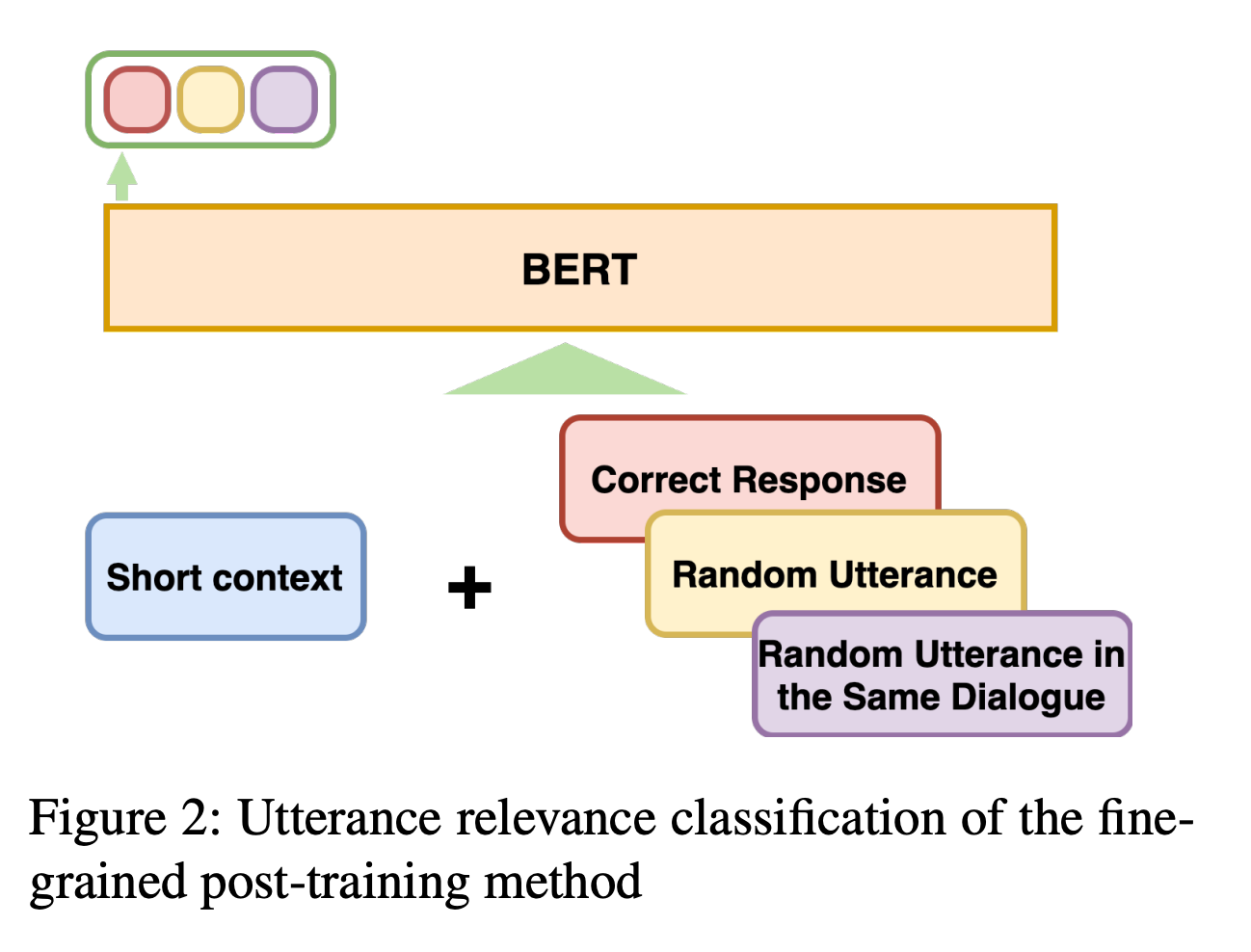
URC将给定短上下文的目标语句分成三个标签之一。第一个是随机语句;第二个是一个语句,但不是回复,不过是从同个会话中随机采用出来的。虽然通过会话中的语句与正确回复有类似的主题,但不能看做是连贯性的;第三个是正确的回复。
模型通过在随机语句和正确回复之间进行分类任务来学习主题预测,然后通过区分同对话中的随机语句和正确回复学习连贯性预测。
这样,通过将短上下文和目标语句分为三种类别,模型可以同时对话中的学习语义相关信息和连贯性信息。
具体的训练过程为,首先,给定会话
U
i
=
{
u
1
,
⋯
,
u
M
,
u
M
+
1
=
r
i
}
U_i=\{u_1,\cdots,u_M,u_{M+1}=r_i\}
Ui={u1,⋯,uM,uM+1=ri},选择了连续的语句并形成了一个长度为
k
k
k的短上下文-回复对
S
j
=
{
u
j
,
u
j
+
1
,
⋯
,
u
j
+
k
−
1
,
u
j
+
k
}
S_j = \{u_j,u_{j+1},\cdots,u_{j+k-1},u_{j+k}\}
Sj={uj,uj+1,⋯,uj+k−1,uj+k}。模型分类一个短上下文
s
c
=
{
u
j
,
u
j
+
1
,
⋯
,
u
j
+
k
−
1
}
sc=\{u_j,u_{j+1},\cdots,u_{j+k-1}\}
sc={uj,uj+1,⋯,uj+k−1}和给定目标语句
u
t
u_t
ut的关系。目标语句可以是三种情况之一:一个随机语句
u
r
u_r
ur;来自同一个对话
u
s
u_s
us中的随机语句;目标回复
u
j
+
k
u_{j+k}
uj+k,这里
1
≤
s
≤
M
+
1
1 \leq s \leq M+1
1≤s≤M+1且
j
+
k
≠
s
j+k \neq s
j+k=s。那么我们可以表示输入序列
x
x
x的post-training为:
x
=
[
C
L
S
]
u
1
[
E
O
U
]
⋯
u
j
+
k
−
1
[
E
O
U
]
[
S
E
P
]
u
t
[
S
E
P
]
(4)
x = [CLS] \,\, u_1\,\, [EOU] \cdots u_{j+k-1} \,\, [EOU] \,\, [SEP]\,\, u_t\,\, [SEP] \tag 4
x=[CLS]u1[EOU]⋯uj+k−1[EOU][SEP]ut[SEP](4)
T
[
C
L
S
]
T_{[CLS]}
T[CLS]作为一个聚合表示,最终的得分
g
u
r
c
(
s
c
,
u
t
)
g_{urc} (sc,u_t)
gurc(sc,ut)通过将该聚合表示喂给一个单层感知机,输出的得分作为短上下文和目标语句之间的相关度。
为了计算URC损失,使用交叉熵损失:
L
U
R
C
=
−
∑
∑
i
3
y
i
log
(
g
u
r
c
(
s
c
,
u
t
)
i
)
(5)
L_{URC} = -\sum\sum _i ^3 y_i \log (g_{urc}(sc,u_t)_i) \tag 5
LURC=−∑i∑3yilog(gurc(sc,ut)i)(5)
同时使用MLM和URC来训练模型。在MLM中,应用的是RoBERTa提出的动态掩码策略。模型可以学习更语境化的表示因为通过每次随机遮盖词元来学习,而不是遮盖一个预定的词元。为了优化模型,使用MLM和URC的交叉熵损失之和:
L
F
P
=
L
M
L
M
+
L
U
R
C
(6)
L_{FP} = L_{MLM} + L_{URC} \tag 6
LFP=LMLM+LURC(6)
ConveRT
作者认为原始的BERT对于对话来说太重了,导致训练缓慢费钱。接着作者提出了ConveRT,一个针对对话任务的预训练框架,能满足高效、可用(便宜)、快速训练的要求。使用一个基于检索的回复选择任务来预训练,高效地利用量化和双编码器的子词级参数构建一个轻量级的内存和能量有效(energy-efficient)的模型。
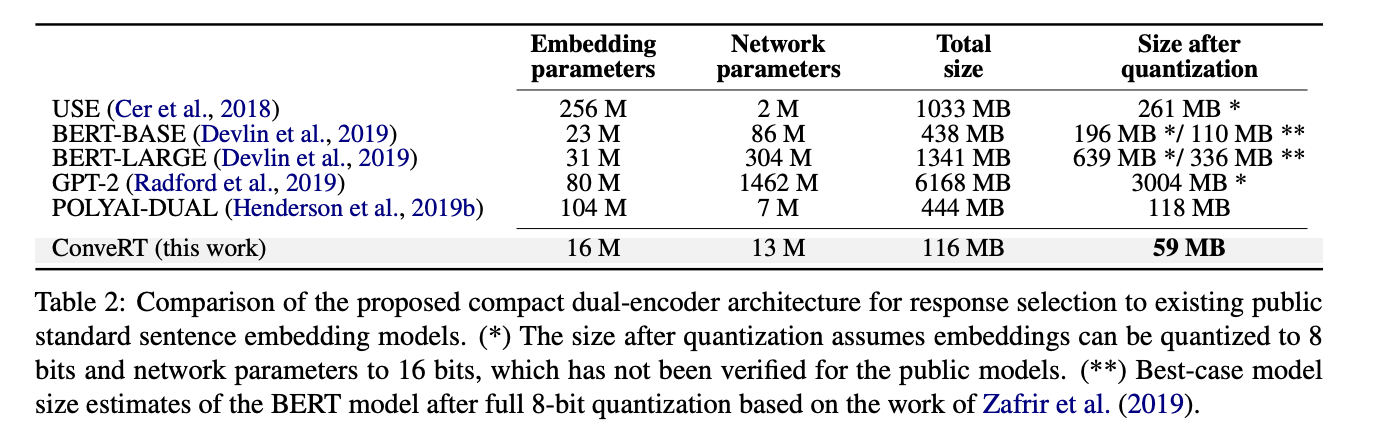
上表是作者给出了高效量化效果,最下面的一行代表本篇工作,它的模型大小只有59MB。
作者首先利用无标注对话数据,把回复选择任务加入到预训练过程中。同时压缩了BERT模型的大小。
回复选择 是一个给定对话历史选择一个最合适的回复任务。该任务是基于检索式对话系统的核心,通常需要在联合语义空间中编码上下文和大量回复。然后通过匹配query表示和每个候选回复表示检索最相关的回复。核心思想为: 1)利用大量无标签对话数据集在通用回复选择任务上来预训练一个模型;2)然后微调这个模型,通常会添加额外的网络层,使用少得多的任务相关数据。
双塔编码器(dual encoder)架构在回复选择上预训练变得越来越流行。
本篇工作引入了一个针对对话压缩的预训练回复选择模型。ConveRT仅有59MB的大小,使得它比之前SOTA级别的dual encoder(444MB)小得多。这种显著地大小减小和训练加速是通过结合8-bit的嵌入量化和量化感知的训练、子词级参数化,并对自注意力进行剪枝来实现的。
多上下文建模 ConveRT超越了单上下文的限制,提出了一个多上下文dual encoder模型,它在回复选择任务中组合了当前上下文和前面的对话历史。该多上下文ConveRT变体仍然是压缩的(共73MB),并且在大量的回复选择任务上带来了性能提升。
输入和回复表示 在训练之前,获得一个子词词典
V
V
V,该词典同时由输入端和回复端共享:从Reddit上随机采样10M个句子,然后迭代地运行子词分词算法。最终得到了词典
V
V
V包含31476个子词token。在训练和推理阶段,在 UTF8标点符号和单词边界上进行初始的单词级分词后,输入文本
x
x
x被拆分到子词集中。用同样的方式分词所有的回复
y
y
y。
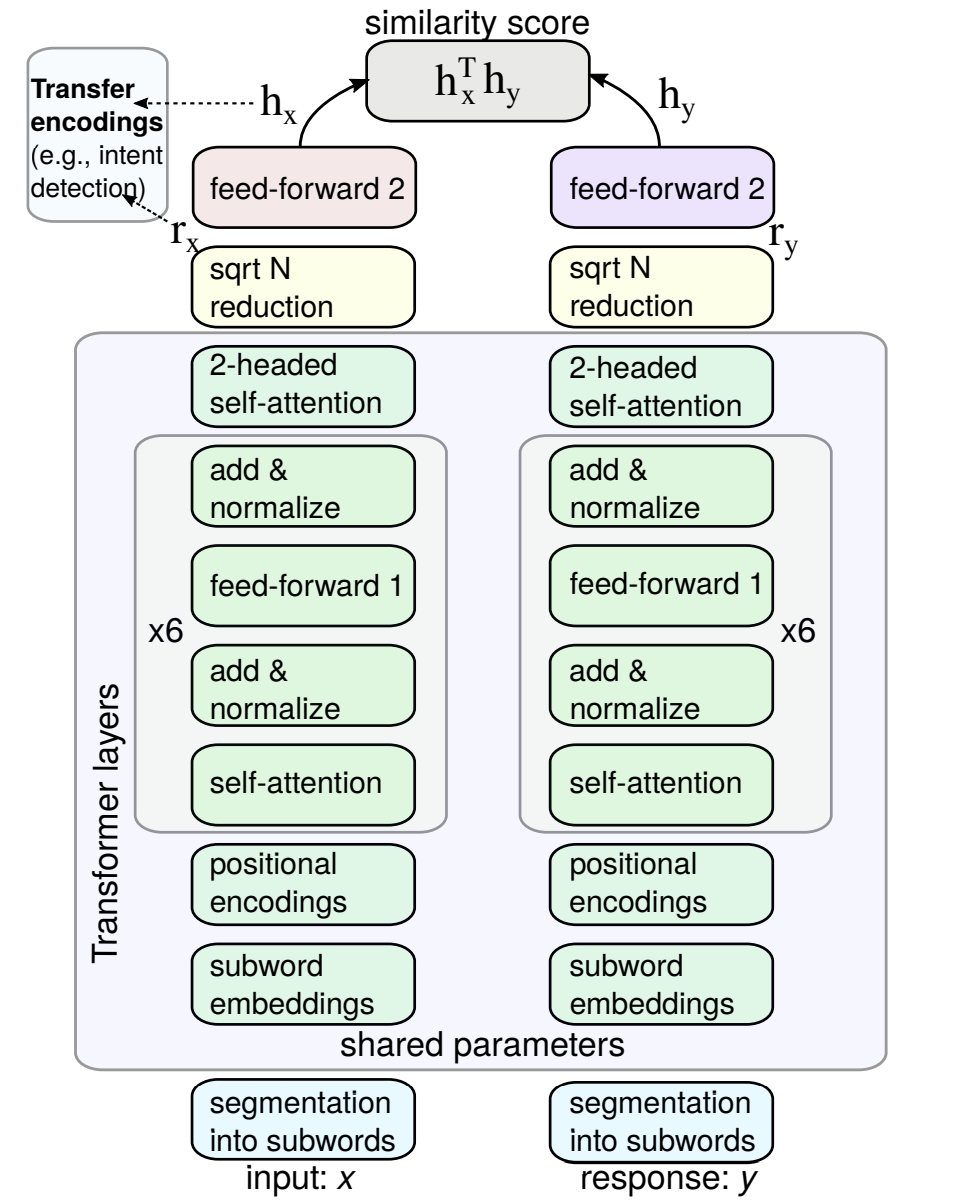
输入和回复编码器 输入和回复的子词嵌入然后经过一系列转换。该转换基于标准的Transformer架构,见上图。在经过自注意块之前,作者在子词嵌入上增加了位置编码。并且学习不同大小的两个位置编码矩阵, M 1 M^1 M1的维度是47512; M 2 M^2 M2是11512。在位置 i i i的嵌入累加为: M i 1 m o d 47 + M i 2 m o d 11 {M^1_i}_{mod \,\, 47} + {M^2_i}_{mod \,\, 11} Mi1mod47+Mi2mod11。接下来的层类似原始Transformer架构,但做了微小的调整。首先,在6层上设置了不同最大相对注意力,这可以帮助模型泛化到长序列和远距离依赖上:前面的层组合学习短语级语义,而后面的层建模更大的模式。并且在整个网络中使用单头注意力。
在进入softmax之前,增加了一个偏置到注意力得分中,它仅依赖相对位置。这可以帮助模型理解相对位置,但对比完全相对位置编码更高效。同样可以使模型泛化到更长的序列。
6个Transformer块使用一个64维的投影用于计算注意力权重,一个2048维的核(图1中前馈网络),和512维嵌入。注意所有的Transformer层使用的参数对于输入端和输出端是共享的。使用square-root-of-N reduction层把嵌入序列转换成固定维度向量。reduction层的输出分别记为 r x r_x rx和 r y r_y ry,是1024维的,喂给两个“端特定”的前馈网络(不共享参数)。
最后是一个线性层映射文本到最终的L2正则化的512维表示:输入文本是 h x h_x hx;相应的回复文本是 h y h_y hy。
输入-回复交互 然后,每个回复与给定输入的相关性通过得分
S
(
x
,
y
)
S(x,y)
S(x,y)来量化,通过计算
h
x
h_x
hx和
h
y
h_y
hy的相似度得到。
量化 每个参数不是标准的32位(bit),所有的嵌入参数仅通过8位来表示,其他网络参数只有16位。
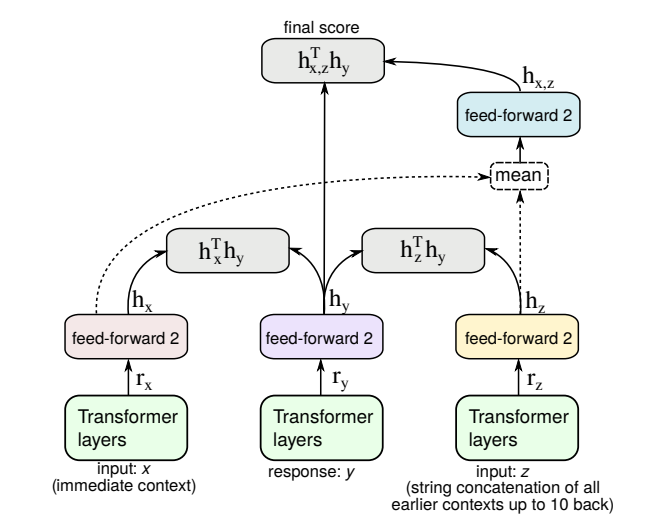
多上下文的ConveRT 作者构建一个多上下文的dual encoder通过使用最多10个之前的语句。这些上下拼接了最近的10个语句,当成网络的一个额外特征,如上图所示。注意,所有上下文表示仍然独立于候选回复的表示,因此我们仍然可以进行高效的响应检索和训练。完整训练目标是三个子目标的线性组合:1)给定立即上下文排序回复 2)给定仅额外(非立即)上下文排序回复 3)给定立即和额外上下文的均值排序回复。
参考
- 贪心学院课程
- Fine-grained Post-training for Improving Retrieval-based Dialogue Systems
- ConveRT: Efficient and Accurate Conversational Representations from Transformers