目录(故障预防,故障发现,故障处理)
集群分组隔离
线程池隔离
DB 双库,慢 SQL 隔离
多级缓存
redis 主要缓存
mapdb 降级缓存
localCache
限流
分类进行频次统计限流
sentinel 平台精细化接口限流
降级
熔断
自动预案
稳定性相关的前置知识在前两篇文章已经说的比较多了,个人也在网上对比看了下稳定性相关的内容,都是偏概念,因此此处更加偏向于系统实战设计实现。
本章例子以设计一个调用量很大的中后台系统为例,服务主要是对外提供很多稳定 rpc 接口,以及为其后台管理页面提供 web 服务。系统要求:服务稳定,响应快速。
需要注意的是,本篇的内容说到的,需要依赖前面两篇文章提到的系统分析,需要对系统掌控全面才能针对性的制作稳定性设计策略。
稳定性治理主要是需设计故障预防、故障发现、故障处理三个环节。总体设计如下: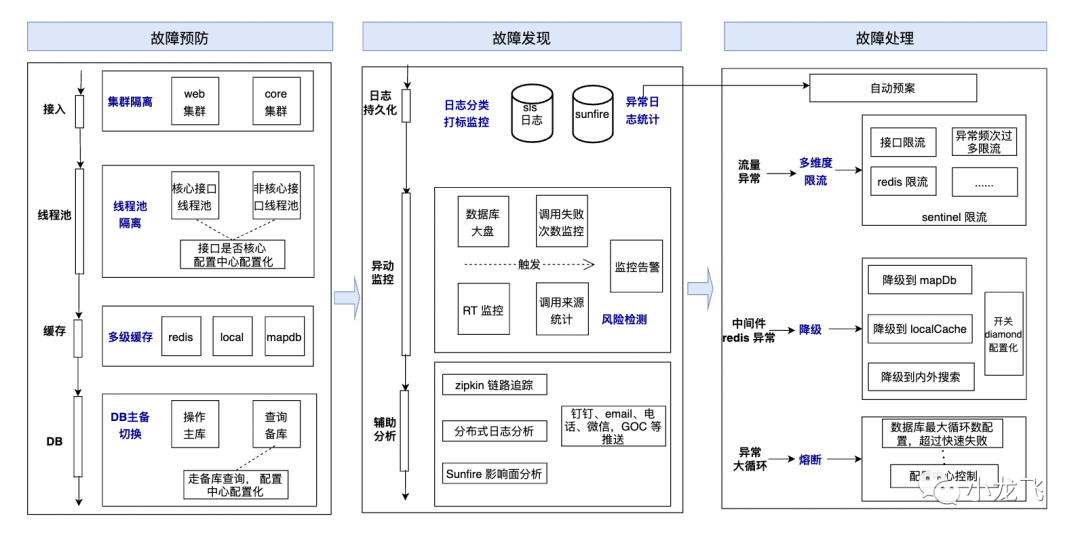
故障预防
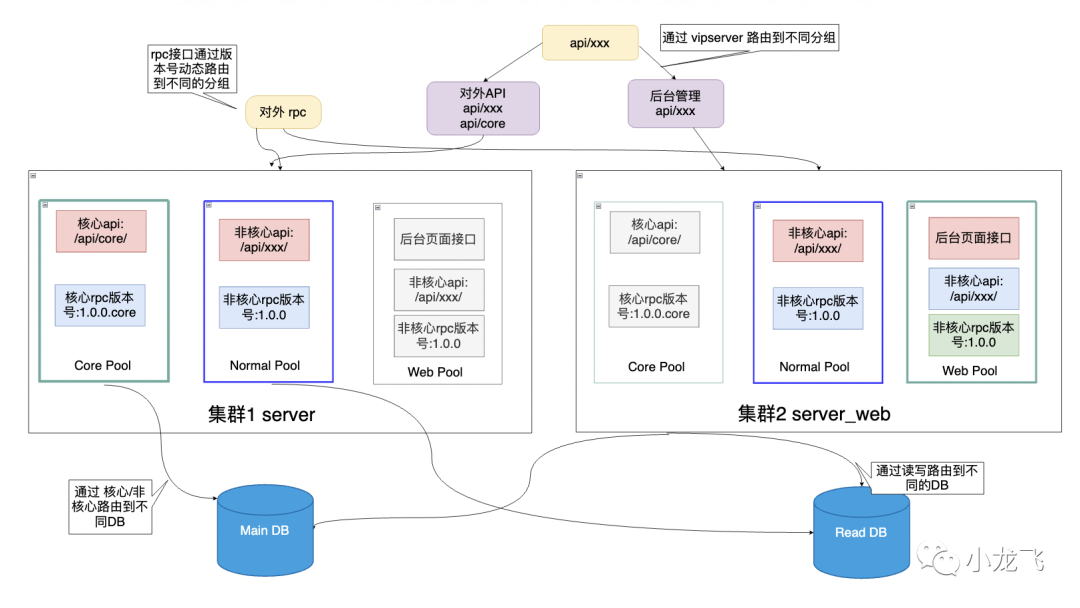
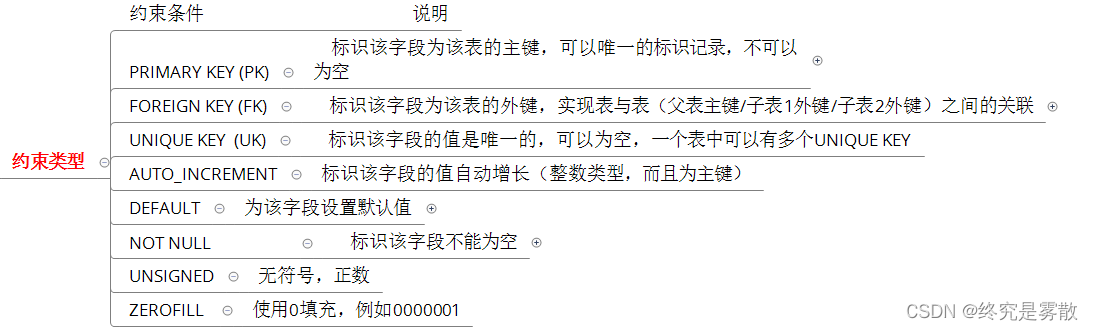
系统对外提供的服务分为以下三种:
核心服务:rt 很低且 QPS 很高的接口(rpc+http 协议);
非核心服务:rt 较高且访问较低频的接口(rpc+http 协议);
后台服务:仅为管理员后台提供的 web 接口(涉及很多大 sql,http 协议);
其中非核心和后台服务具有访问的随机性和偶然性:绝大多数情况下对整体毫无影响,但偶尔因为某个特别的参数或请求拖慢整个应用,极大的威胁到核心接口的稳定。
集群分组隔离
集群分组原因:其中一些非核心和后台服务具有访问的随机性和偶然性:绝大多数情况下对整体毫无影响,但偶尔因为某个特别的参数或大 sql 请求拖慢整个应用,极大的威胁到核心接口的稳定。
因此,将同一个应用拆分为两套集群分组,将对外 RPC 服务和后台服务拆成两个集群进行部署,集群隔离,即使这部分接口引发问题也能保证那些重要的核心接口依然能正常提供服务。
具体的实现:
rpc 接口通过接口版本号来进行路由不同的集群分组
http 接口通过路径来进行路由
线程池隔离
核心接口和非核心接口,各自分开定义自己的线程池,防止调用量大的时候抢夺资源,导致核心接口失败。
DB 双库,慢 SQL 隔离
这里的主库和读库不是 DB 的主备,而是实实在在的两套数据库,每一套都是主备架构的。
系统发展到后面的瓶颈往往都是数据库,解决的方式要不是水平拆库或者垂直拆库,但是这些都涉及到代码系统的改造以及各种回归测试,工作量较大。如果要快速的解决一些数据库慢查询或者数据库资源瓶颈导致的系统速度慢问题,做两套库隔离掉 SQL 是一个好的选择。
创建读库方式:使用一些中间件从主库进行同步,创建出第二套数据库资源。
应用内使用动态数据源,统一拦截 Mapper 层,根据可配置的规则将 DB 请求导流到不同库,规则可以配置在配置中心里面,可以进行快速的调整和修改。
写操作、核心接口的读操作、事务中的操作直接访问主库,其它慢速 SQL 访问读库。
多级缓存
redis 主要缓存
大部分的查询结果都会缓存到 redis 等类似内存存储中,这里需要注意缓存的刷新策略制定维护,失效时间,兜底刷新策略等,切不可出现缓存不一致问题,这个对系统是致命打击。
一些重要的接口缓存还需要再系统启动时进行缓存预热。
mapdb 降级缓存
引入 mapdb 原因: 系统接口对 redis 缓存依赖很重,基本逻辑都是提前计算好结果缓存在 redis 里做加速,但是 redis 本身就是一个不稳定因素。
生产也发生过好几次因为 redis 或网络故障引起的大面积告警,这种时候可以说除了寄希望于外部故障消除之外毫无办法,因此需要建设降级链路。针对这种情况需要引入了本地缓存,由于待缓存的数据量较大(GB级别),不可能使用纯内存 cache,所以我们使用了 MapDB,一个可以把本地文件映射为内存 map 或 tree 的工具。
mapdb 过期策略: 本地缓存不能使用类似 redis 一样的自动过期策略,因为那样的话就失去了作为备用数据源的意义,因此需采取了多重自动刷新策略来更新数据,例如:按id递增遍历更新、按修改时间更新、按手动设置参数更新。这样才可以满足随时常态化降级的需求。
mapdb 降级触发时机 需要单独的制定降级策略,策略关键的参数可以配置在配置中心,达到阈值则触发降级策略。
localCache
内存缓存,配合中心进行配置开启开关,本地缓存是最后一道屏障。
故障发现

故障发现要从系统开发打日志的时候就进行设计好,再配合好日志持久化工具、异动场景监控设计、辅助分析工具,就可以最快的发现问题,而且降级和熔断策略也和日志埋点相关。
RT场景分析: 低频低速接口和高频高速接口通常拥有不同的正常 rt 和 QPS 范围,如果拉通来进行统计和预警是极不准确的。因此一般需要引入自定义业务日志,在接口层和 DB 层均可以根据不同接口定义不同的 rt 范围、qps 范围等,只有超出设定范围的才算作风险请求,根据这个配置出来的预警规则非常具体且灵活。同时,因为只会记录超出范围的请求,所以日志总量不会特别大,允许我们进一步记录下这些风险请求的具体参数、运行时环境等详细信息,便于迅速定位到问题所在。
监控产品市场上有很多种,主要是分布式日志采集,机器监控,分布式链路追踪,告警推送等。
日志埋点和指标制定需要适度,什么都打相当于没打,但是又要分析出来重要的核心指标以便发现问题,因此需要系统owner对自己的系统有很强的掌控力。具体的日志设计,每个系统关注的指标都不一样,而且监控设计一定是越来越健全的,需要持续关注和投入,并且需要周期性的投入固定的时间进行日志分析。
故障处理
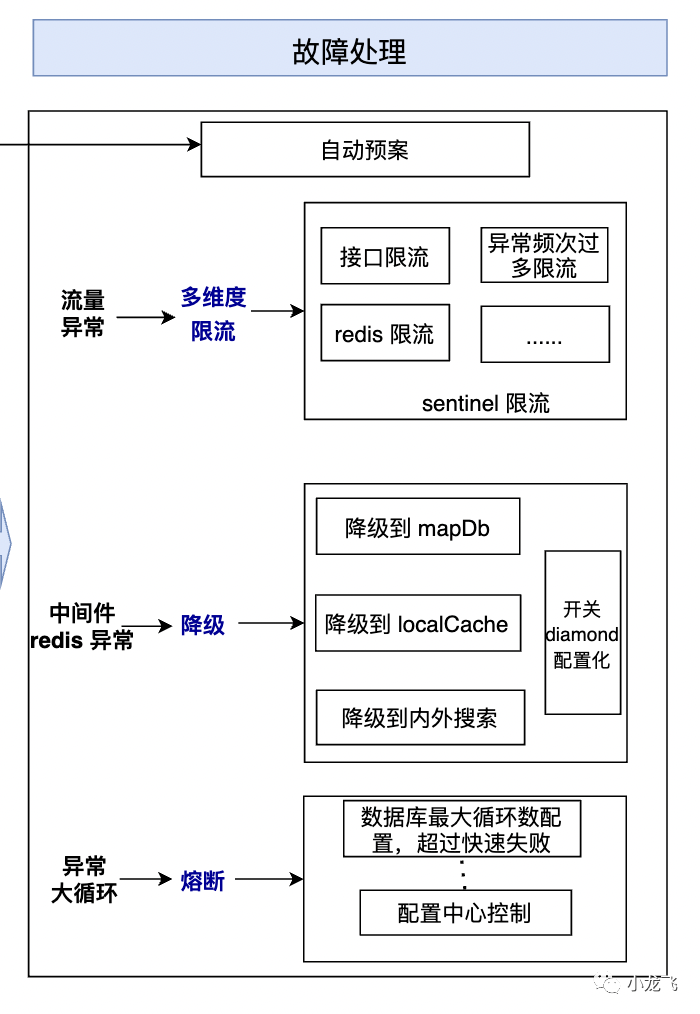
限流
分类进行频次统计限流
sentinel 是保护应用不被异常流量打挂的重要设施,在发生流控时默认会被鹰眼(监控工具)统计为 rpc 错误,对于系统来说,自身接口和下游接入应用都非常多,发生少量限流是每时每刻都会存在的事情,但这会导致频繁的报 rpc 成功率下降,每次人工排查都有虚惊一场的感觉。
基于这种情况拦截了这块异常处理逻辑,可以选择的配置成发生流控依然算是 hsf 成功,避免不必要的触发成功率下降告警。同时有监控专门统计被流控的频次,超过一定范围同样会告警,并不会对流控情况完全失去感知。
配置中心可以配置参数,控制子方法限流过滤器日志打印开关,流控频次统计分为类似下面四种统计,超过一定的范围分别告警。
S("S","成功"),
T("T","redis 限流),
B("B","sentinel 限流"),
E("E","异常")sentinel 平台精细化接口限流
可以精确按照 接口+方法+来源应用 的维度来进行限流。
降级
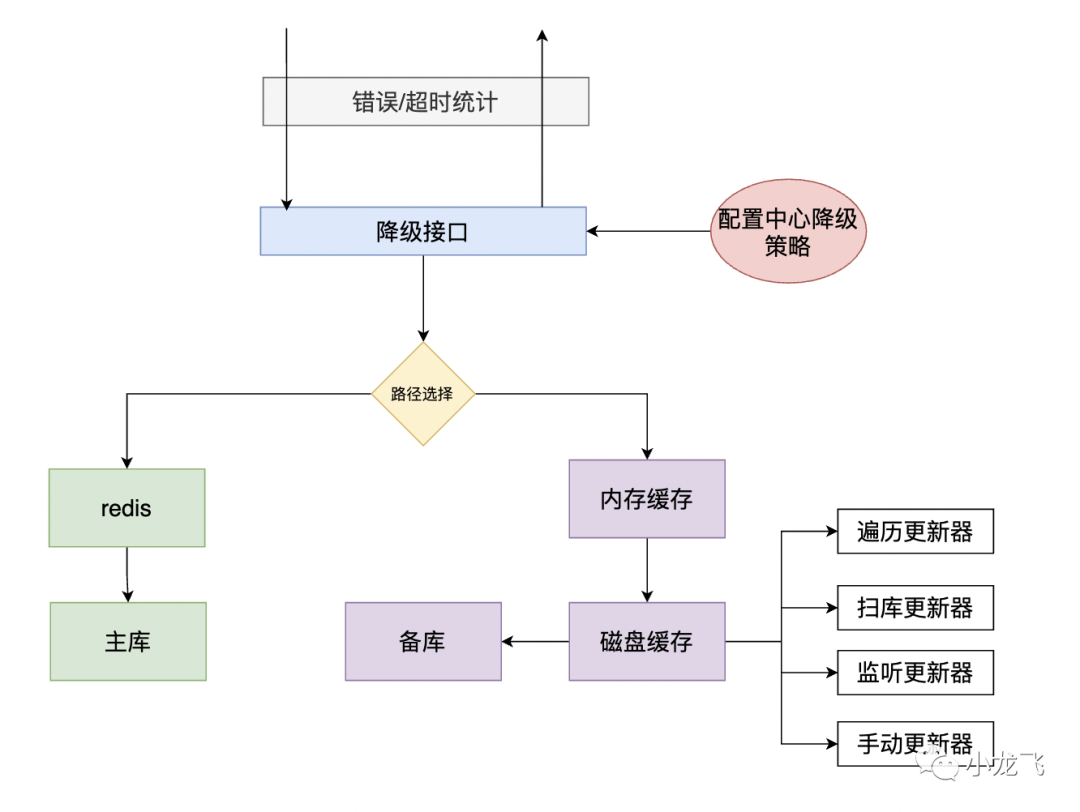
所有的请求进来,都会经过 xx 拦截器进行拦截,其多个实现配置了 rpc 请求策略,然后根据配置中心配置的参数,触发不同接口的不同降级策略,策略里面会进行请求错误和超时统计。
在应用内部记录下核心接口的慢、错频次,一旦这些值超过自定义阈值,便可以在分钟级内自动切换到降级模式。这种降级是按单机为粒度的,因此单机故障不会干扰到其它机器。
熔断
熔断很依赖日志埋点打标,根据不同的场景来制定相应的熔断策略,
熔断场景如下
系统内部循环 针对这种问题,在记录业务日志时加入了计数器,根据 traceId 和 rpcId 统计同一次请求下访问某种资源的频次,如果超过设定值就识别为风险
服务超时:当服务请求不能在指定的时间内得到响应时,熔断可以帮助防止客户端无限制地等待响应。
服务故障:当服务不可用或出现错误时,熔断可以帮助降低服务的影响,避免服务雪崩。
防止资源过度消耗:当服务的请求量过大或频繁请求时,熔断可以帮助防止服务过度消耗资源,保护系统的稳定性。
限流策略:当请求量达到一定程度时,熔断可以帮助限流,防止服务过载影响系统的正常运行。
异常流量:当出现异常流量时,熔断可以帮助防止服务受到攻击或者恶意请求的干扰。
自动预案
系统自动预案是指在系统出现异常或故障时,系统自动执行预先设定好的应急措施,以确保系统的稳定性和可用性。下面是一些系统自动预案的例子:
自动切换到备份服务器:当主服务器出现故障时,系统自动切换到备份服务器上提供服务,以确保服务的连续性。
自动重启服务:当服务崩溃或出现异常时,系统自动重启服务,以恢复服务的正常运行。
自动调整资源分配:当系统负载过高或资源紧张时,系统自动调整资源分配,以保证系统的稳定性和性能。
自动触发告警:当系统出现异常或故障时,系统自动触发告警,向 owner 发送警报信息,以便及时处理问题。
自动执行紧急修复:当出现安全漏洞或其他紧急问题时,系统自动执行紧急修复,以确保系统的安全和稳定性。
大公司一般都有预案平台,进行配置预案场景和规则。
本篇先到这里,喜欢技术干货欢迎关注我。
本期相关
稳定性治理一,重新认识系统
稳定性治理二,稳定性分析
![Java并发编程(二)并发理论[JMM/重排序/内存屏障/Happens-Before 规则]](https://img-blog.csdnimg.cn/e68f405fe4fa420fad74e04cdfe2fae1.png)