在工作中要求写一个籍贯的级联选择器,记录一下自己写这个级联选择器的过程,因为自己才刚开始工作,有很多地方都没有考虑的很清楚,希望各位大佬能给出建议。
一、需求
A:正常的23个省,籍贯由“省+区/县/市”组成,即写到县(区)一级,比如:浙江省温岭市、浙江省苍南县、安徽省阜南县、湖北省孝感市。不需要细化到“浙江省台州市温岭市”、“浙江省温州市苍南县”
B:直辖市的籍贯写法由“直辖市+区/县”组成,比如:北京市朝阳区、上海市杨浦区、重庆市南岸区
C :部分少数民族自治区的籍贯写法。 (内蒙古自治区、新疆维吾尔自治区、宁夏回族自治区、广西壮族自治区、西藏自治区) 部分少数民族自治区的籍贯由“自治区+自治县/县/县级市”组成,即写到县(县)一级,例如内蒙古自治区包头市
二、实现方案
从省和市这种从属关系,我打算给前端返回一个树,省为最顶层,因为直辖市和香港澳门特别行政区的关系,把直辖市和香港澳门特别行政区也当做是树的根节点。因此数据库的设计就是要有一个当前区域代码和父区域代码来给树建立关系。
三、城市数据的获取
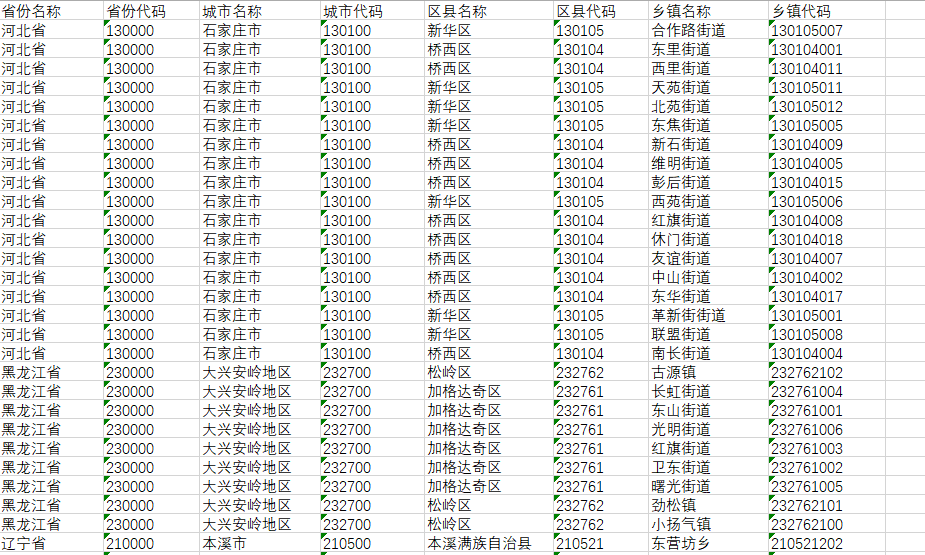
同事给了我这样一个文件Township_Area_A_20230425.xlsx,这个文件包括了中国各个区域的代码,可以到乡镇。这样的数据不方便我们形成树,所以我把这个数据进行了整理。
这是我根据数据库的设计处理完的数据城市区域数据库导入文件.xlsx ,这样处理可以大大减少数据存放的数据,树的根节点parent_code为空。
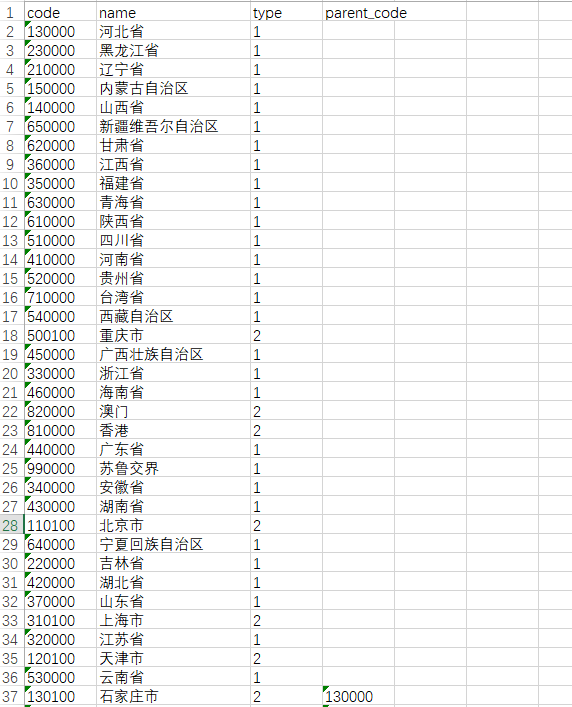
四、数据库设计
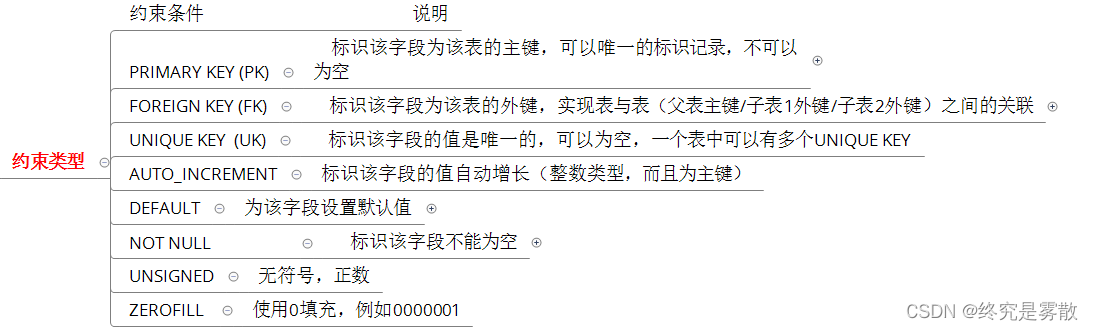
最重要的是要能返回一个树形结构所以需要有一个parent_code字段,根据type可以知道区域的类型。
CREATE TABLE `t_city` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`code` int DEFAULT NULL COMMENT '区域编码',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '区域名称',
`type` int DEFAULT NULL COMMENT '区域类型类型',
`parent_code` int DEFAULT NULL COMMENT '父区域编码',
`state` tinyint DEFAULT NULL COMMENT '状态',
`created_by` bigint DEFAULT NULL COMMENT '创建人',
`created_date` datetime DEFAULT NULL COMMENT '创建时间',
`updated_by` bigint DEFAULT NULL COMMENT '更新人',
`updated_date` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=964 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
五、代码实现
获取树
public List<CommonTreeDTO<City>> getCityTree() {
QueryWrapper<City> queryWrapper = new QueryWrapper<>();
QueryWrapper<City> wrapper = queryWrapper.isNull("parent_code").orderByAsc("name");
List<City> cities = baseDao.selectList(wrapper);
return buildTree(cities,null);
}
/**
* 构建树
* @param parenList 父节点
*/
public List<CommonTreeDTO<City>> buildTree(List<City> parenList,Integer parentCode){
List<CommonTreeDTO<City>> list=new ArrayList<>();
parenList.forEach(city -> {
CommonTreeDTO<City> dto = new CommonTreeDTO<>();
dto.setId(city.getId());
dto.setKey(String.valueOf(city.getCode()));
dto.setLabel(city.getName());
dto.setLevel(city.getType());
dto.setInfo(city);
if (Objects.nonNull(parentCode)){
dto.setPid((long)parentCode);
}
// 查询子节点
QueryWrapper<City> queryWrapper = new QueryWrapper<>();
List<City> childList = baseDao.selectList(queryWrapper.eq("parent_code", city.getCode()));
List<CommonTreeDTO<City>> childDTOList=new ArrayList<>();
// 如果有子节点就继续递归查找
if (CollectionUtils.isNotEmpty(childList)){
childDTOList = buildTree(childList,city.getCode());
}
if (CollectionUtils.isNotEmpty(childList)){
dto.setChildren(childDTOList);
}
list.add(dto);
});
return list;
}
根据code查找区域名称
这里前端是会传入一个逗号分隔的字符串,所以要对字符串进行处理然后再插叙出所有code对应的城市名称。
public String getCityByCode(String codes) {
if (StringUtils.isNotBlank(codes)){
String[] codeList = codes.split(",");
List<String> cityNames = new ArrayList<>();
for (String code : codeList) {
City city = baseDao.selectOne(new QueryWrapper<City>().eq("code", code));
if (Objects.nonNull(city)){
cityNames.add(city.getName());
}
}
return String.join("", cityNames);
}
return "";
}
六、总结
因为当时做的时候比较赶做的比较粗糙,很多地方都需要进行优化,有时间要研究一下树。当时设计数据库的时候考虑了一下是用parent_id好呢还是parent_code,最终我还是选择用parent_code,我想的是code是他们的关联关系,这样设计查询的时候还要转换一下数据的格式,增加了一些麻烦。