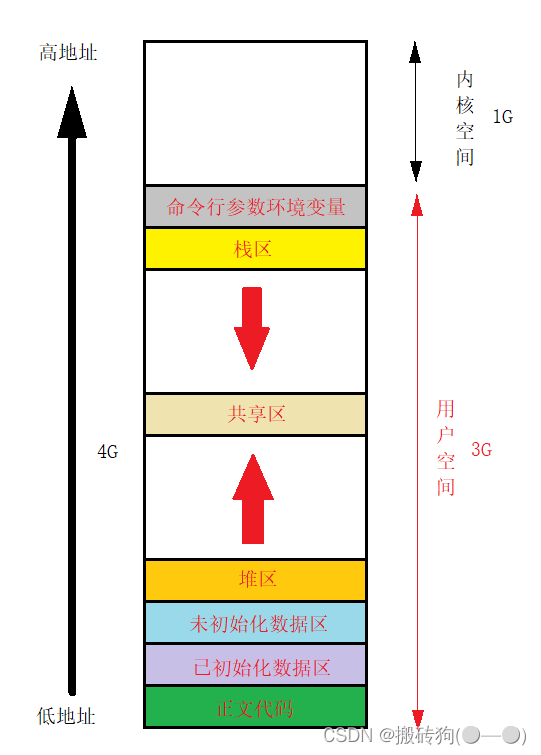
进程地址空间
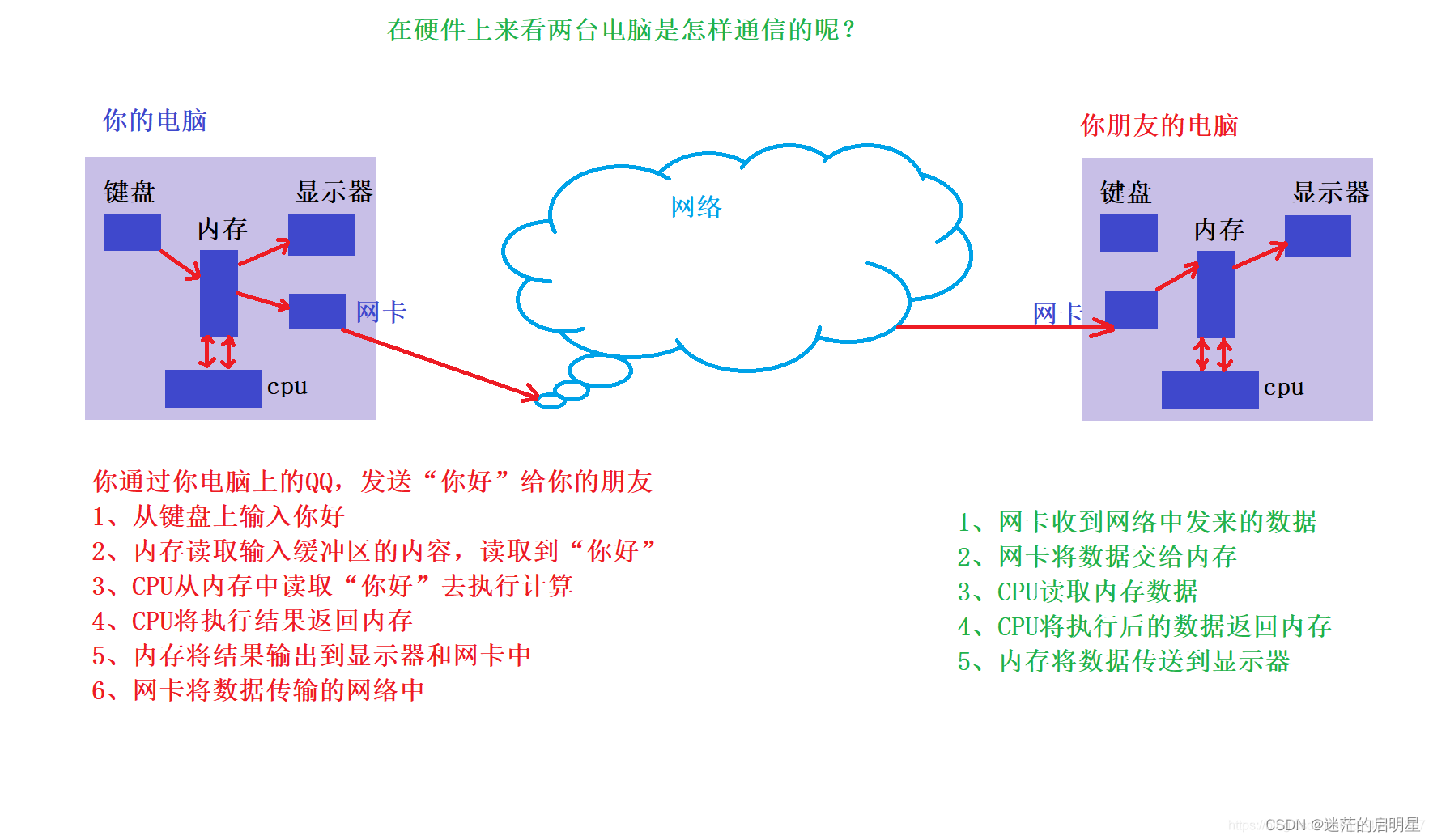
- 程序地址空间
- 进程地址空间
程序地址空间
在Linux环境下,我们可以对上述程序空间地址进行验证:
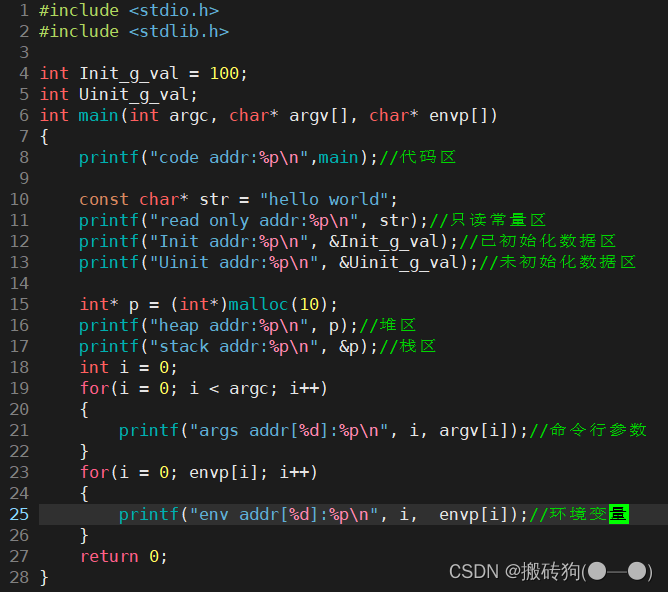
运行程序,可以看到,我们就可以很好看出程序的地址空间的排布了:
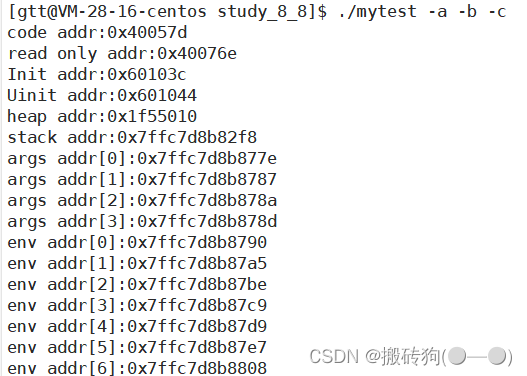
进程地址空间
严格来说,我们上面所说的程序地址空间并不完全正确,他应该叫做进程地址空间才对。
接下来我们来看一段比较奇怪的代码:
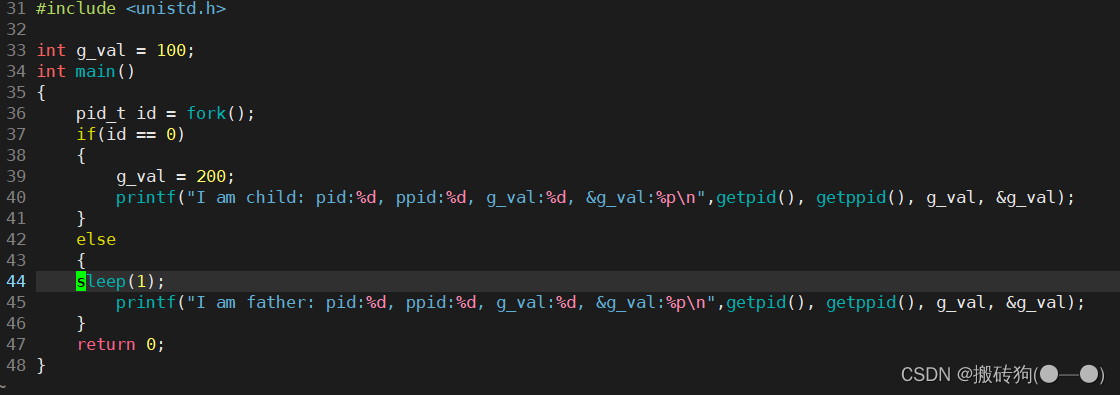
运行程序会发现:

即使我们改变了g_val的值,我们程序的地址并没有发生任何变化,这是为什么呢?
接下来我们就需要引出虚拟地址空间的概念:
我们需要知道的是,我们平时所打印出来的地址,其实都不是物理地址,而是虚拟地址,是由操作系统进行管理的,我们是看不到的。而我们所谓的进程地址空间就相当于他的起始位置为0x00000000,结束位置为0xffffffff,然后划分为我们所说的代码区,堆区,栈区…,他其实是一种数据结构,在Linux下它是由结构体mm_struct实现的。
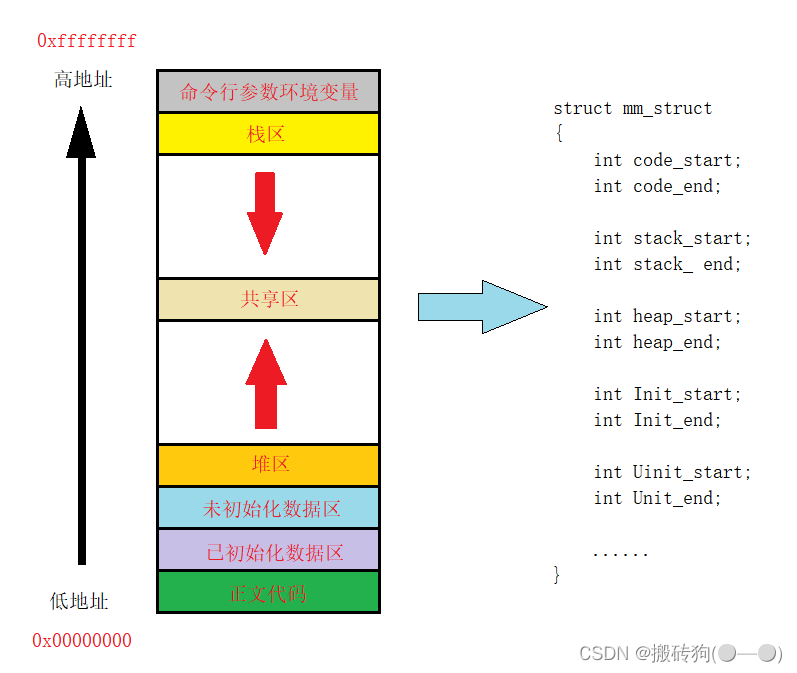
mm_struct中记录了每一个边界的开始位置与结束位置,而每一个区域之中都会存在各种的虚拟地址。
每个进程被创建时,他的进程控制块(task_atruct)和进程地址空间也会相应的被创建,task_atruct中会存储一个指针指向进程地址空间,进程控制块通过这个指针会找到进程地址空间进行访问,而进程地址空间与物理内存之间又是通过页表联系起来,最终完成对物理内存的访问。
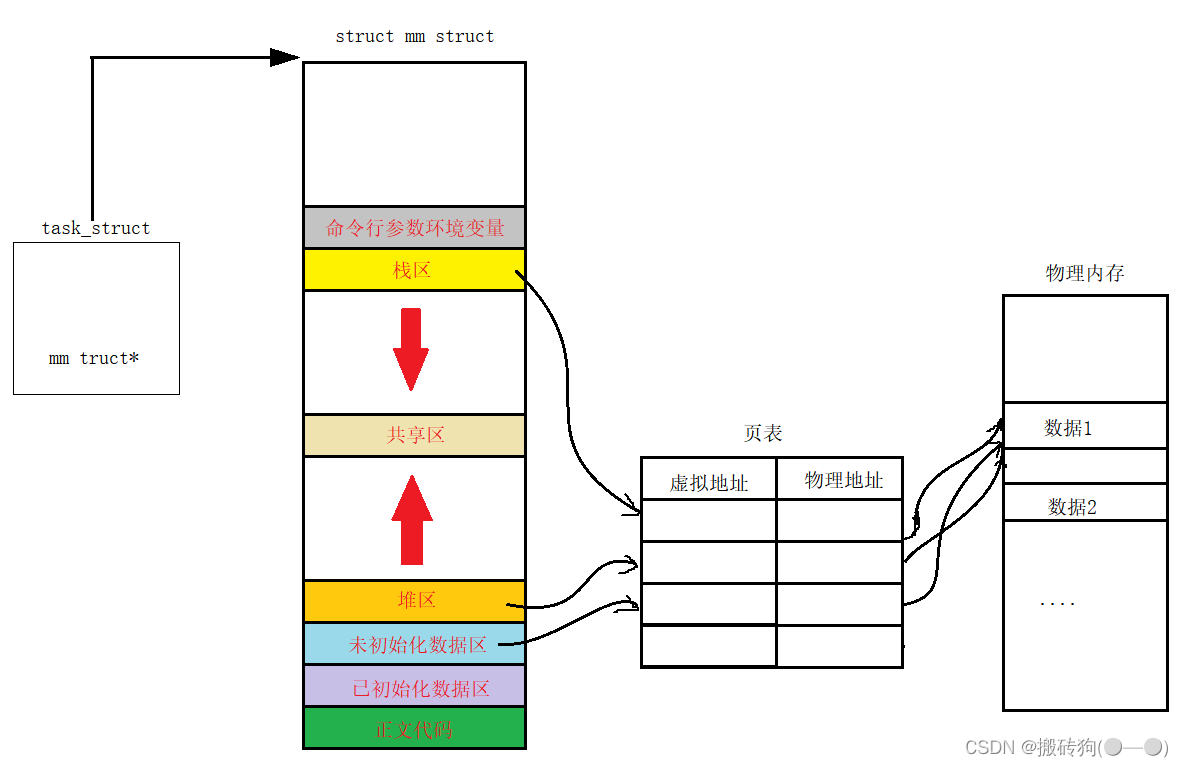
地址空间和页表(用户级)每一个进程都私有一份,只要保证每一个页表映射到不同的物理内存区域,就能使进程之间不会相互影响,保证了进程的独立性。
接下来我们就可以理解最开始我们所提出的问题了,fork()以后,子进程产生,它包含了父进程的大部分属性,其中他们的虚拟地址就可以是一样的,此时的子进程与父进程共享物理内存中的代码与数据,而如果我们此时需要更改子进程的数据,会将父进程的数据拷贝一份,并不会影响父进程,子进程的页表会重新映射子进程在物理内存中的数据,这就是为什么我们更改了数据,但是地址并没有发生改变的原因。
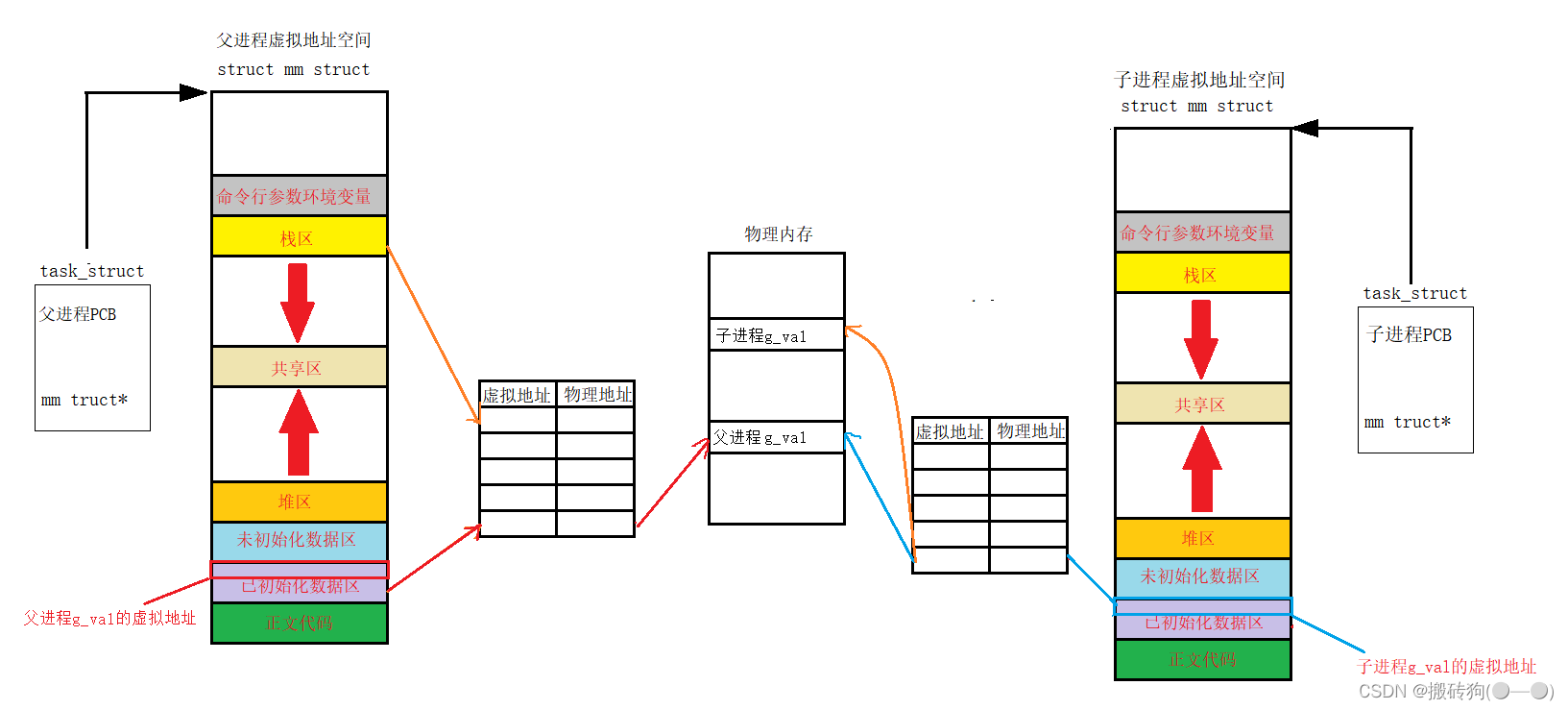
这也就是为什么一个变量可能会同时保存两个不同的值,return的本质就是对id的写入,写入的过程中发生了写时拷贝,这样父进程和子进程在物理内存中就会有自己不同的变量空间,但是他们在用户层是共用一个变量(虚拟地址)的。
我们还需了解的是,当我们的可执行程序并没有被加载到内存中的时候,其实就已经形成了地址,即编译器在编译代码的过程中就已经形成了代码区,数据区…各个区域,并对每个变量,每一行代码进行了编址,所以程序在编译的时候,就已经形成了虚拟地址。
当CPU得到指令以后,磁盘的数据加载到内存当中,此时CPU通过虚拟地址空间与页表对物理内存进行访问,而物理内存中的变量和函数都被编译器赋予了相应的虚拟地址,当CPU访问到这些函数与变量时,所读取的并不是物理内存的地址,而是虚拟地址,所以CPU所读取的指令地址是虚拟地址。
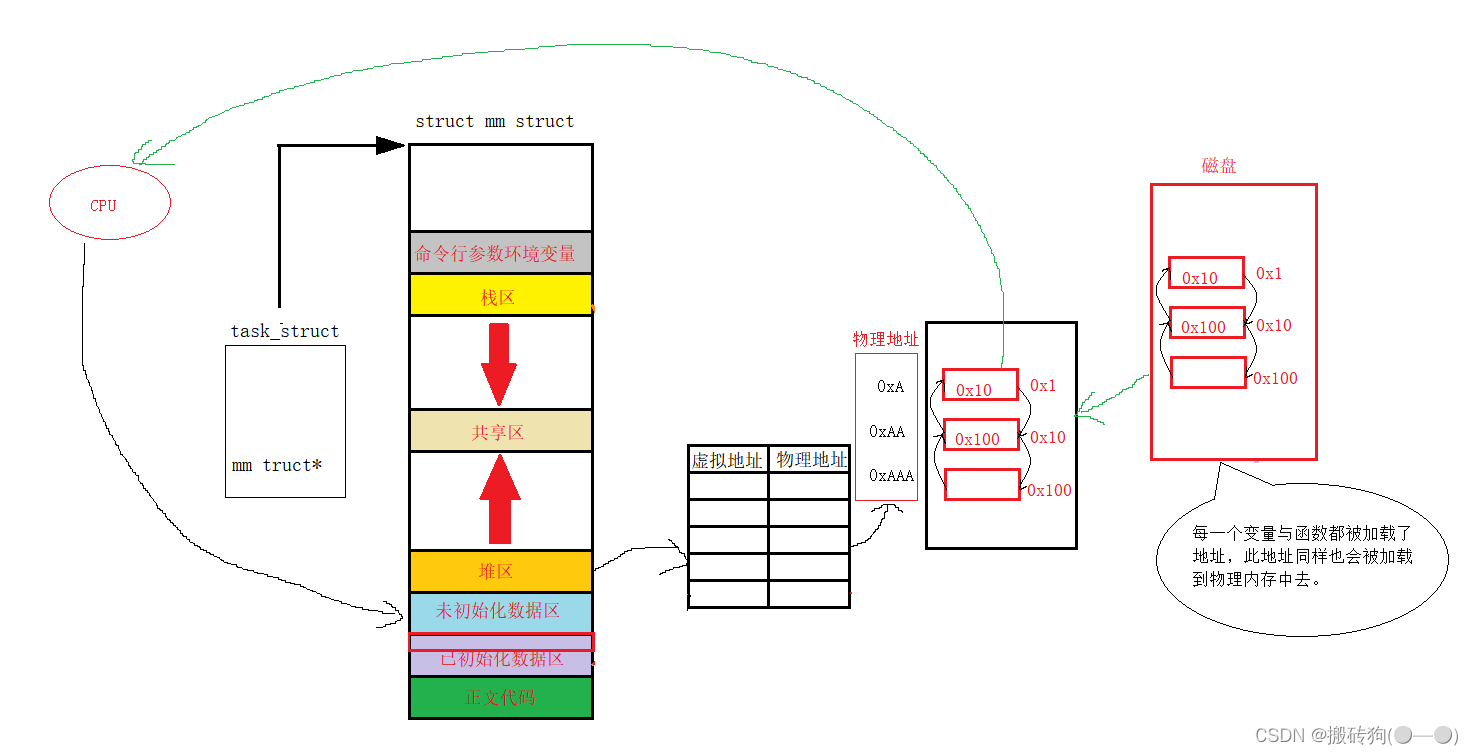
那么为什么会存在进程地址空间呢?
主要有以下三点原因:
- 我们的物理内存并不是随便就能访问的,对于非法的访问和映射OS会识别到,终止此进程,这就有效的保护了我们的物理内存空间,也就是保护了进程与内核空间有效数据。
- 因为进程地址空间与页表的存在,磁盘中的数据可以加载到物理内存中的任意位置,所以内存管理模块和进程管理模块就完成了解耦合,物理内存和进程管理就可以做到没有联系。这样就算我们开辟了虚拟地址空间,如果我们不进行使用,物理内存可以一个字节都不给,当我们真正需要进行物理地址空间使用的时候,才会执行相关算法,为你申请内存,构建页表,访问物理内存,这种延迟分配的策略,就极大的提高了程序的效率。
- 在物理内存中可以再任意位置加载,看似是无序的,但是由于页表与进程地址空间的存在,通过映射关系,在进程视角看来,内存的分配又是有序的,进程地址空间的存在,可以让每个进程都以为自己拥有4GB的空间,并且每个区域都是有序的,进而通过构建页表访问物理地址空间,进程与进程之间就会互相不产生影响,甚至就不会知道其他进程的存在,也就实现了进程的独立性。
那么我们就可以重新理解我们的挂起状态:
加载的本质就是在创建进程,但是并不是将所有的代码和数据全部加载到内存当中去,通过上面的知识我们就可以知道,我们只会将我们所需要立即使用的数据加载进内存,这叫做唤入,当他长时间不会使用时,数据和代码就会被换出,这就叫做挂起状态。