引言
本项目基于pytorch构建了一个深度学习神经网络,网络包含卷积层、池化层、全连接层,通过此网络实现对MINST数据集手写数字的识别,通过本项目代码,从原理上理解手写数字识别的全过程,包括反向传播,梯度下降等。
1 卷积神经网络介绍
1.1 什么是卷积神经网络
卷积神经网络是一种多层、前馈型神经网络。从功能上来说,可以分为两个阶段,特征提取阶段和分类识别阶段。

特征提取阶段能够自动提取输入数据中的特征作为分类的依据,它由多个特征层堆叠而成,每个特征层又由卷积层和池化层组成。处在前面的特征层捕获图像中局部细节的信息,而后面的特征层能够捕获到图像中更加高层、抽象的信息。
1.1.1 卷积核(Convolution Kernel)
在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征图(featureMap),每个特征图由一些矩形排列的的神经元组成,同一特征图的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。
1.1.2 感受野(Receptive Field)
定义:在卷积神经网络中,卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。在典型CNN结构中,FC层每个输出节点的值都依赖FC层所有输入,而CONV层每个输出节点的值仅依赖CONV层输入的一个区域, 这个区域之外的其他输入值都不会影响输出值,该区域就是感受野。下图为感受野示意图:

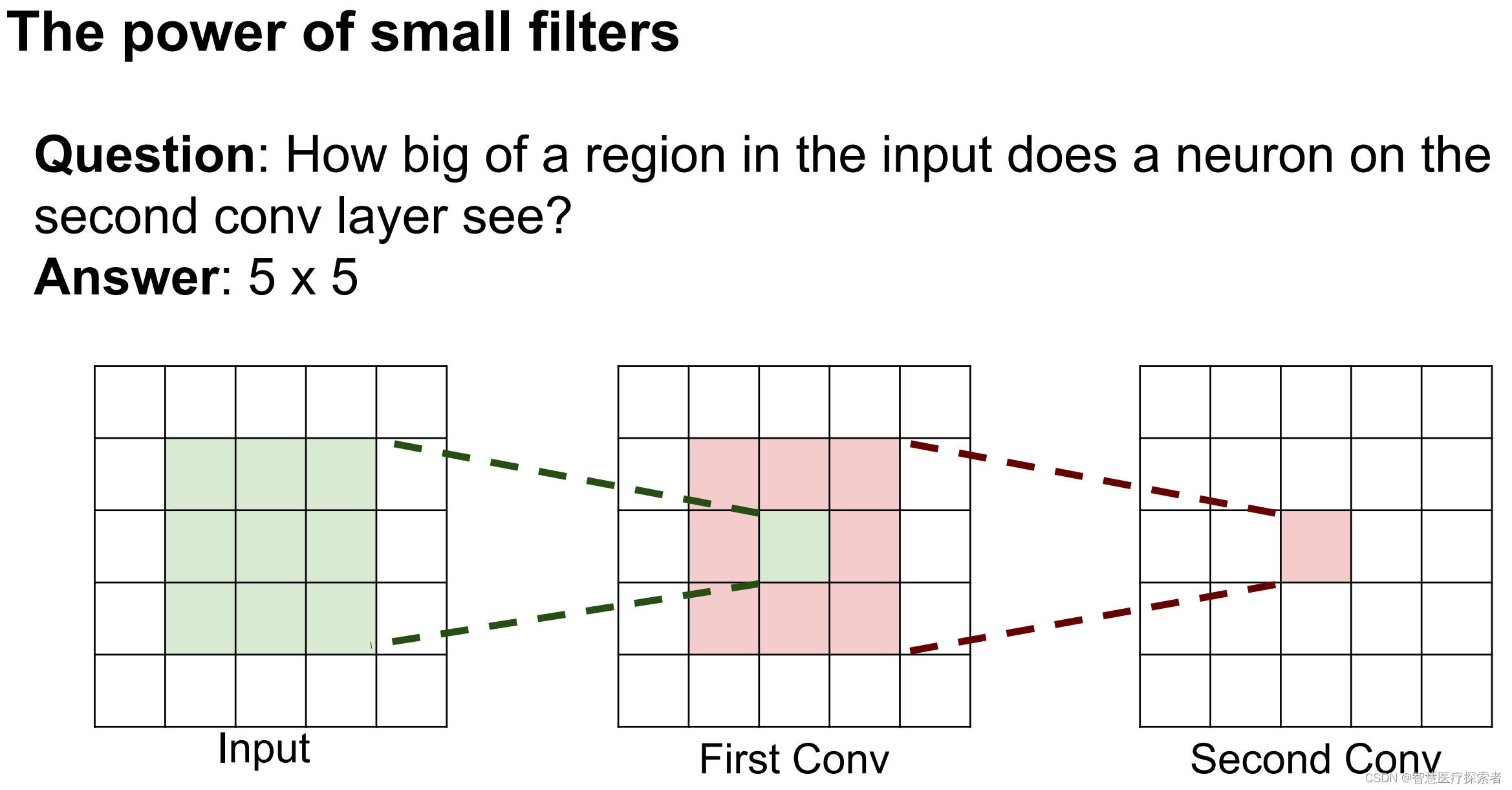
当我们采用尺寸不同的卷积核时,最大的区别就是感受野的大小不同,所以经常会采用多层小卷积核来替换一层大卷积核,在保持感受野相同的情况下减少参数量和计算量。例如十分常见的用两层3*3卷积核来替换一层5*5卷积核的方法

1.3 标准化(Batch Normalization)
在引入BN之前,以前的model training有一些系统性的问题,导致很多算法收敛速度都非常慢,甚至根本就不能工作,尤其在使用sigmoid激活函数时。在机器学习中我们通常会对输入特征进行标准化或归一化,因为直接输入的数据每个维度量纲可能不同、数值差别很大,导致模型不能很好地从各个特征中学习。当上一层输出值太大或太小,其经过sigmoid激活函数时会落在饱和区域,反向传播会有梯度消失的问题。
批标准化(Batch Normalization):对一小批数据(batch),做标准化处理。使数据符合0均值,1为标准差的分布。

Batch Normalization层通常添加在每个神经网络层和激活层之间,对神经网络层输出的数据分布进行统一和调整,变成均值为0方差为1的标准正态分布,解决神经网络中梯度消失的问题使输出位于激活层的非饱和区,达到加快收敛的效果。

1.1.4 池化层(Pooling)
池化 (Pooling) 用来降低神经网络中的特征图(Feature Map)的维度。在卷积神经网络中,池化操作通常紧跟在卷积操作之后,用于降低特征图的空间大小。池化操作的基本思想是将特征图划分为若干个子区域(一般为矩形),并对每个子区域进行统计汇总。池化通常有均值子池化(mean pooling)和最大值池化(max pooling)两种形式。池化可以看作一种特殊的卷积过程。卷积和池化大大简化了模型复杂度,减少了模型的参数。
- 最大值池化可提取图片纹理
- 均值池化可保留背景特征

1.2 卷积的计算过程
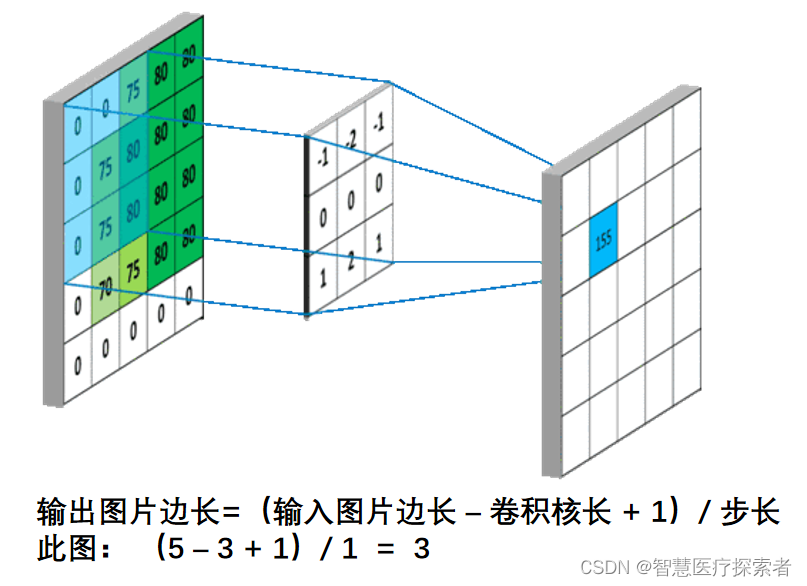
假设我们输入的是5*5*1的图像,中间的那个3*3*1是我们定义的一个卷积核(简单来说可以看做一个矩阵形式运算器),通过原始输入图像和卷积核做运算可以得到绿色部分的结果,怎么样的运算呢?实际很简单就是我们看左图中深色部分,处于中间的数字是图像的像素,处于右下角的数字是我们卷积核的数字,只要对应相乘再相加就可以得到结果。例如图中‘3*0+1*1+2*2+2*2+0*2+0*0+2*0+0*1+0*2=9’
计算过程如下动图:

图中最左边的三个输入矩阵就是我们的相当于输入d=3时有三个通道图,每个通道图都有一个属于自己通道的卷积核,我们可以看到输出(output)的只有两个特征图意味着我们设置的输出d=2,有几个输出通道就有几层卷积核(比如图中就有FilterW0和FilterW1),这意味着我们的卷积核数量就是输入d的个数乘以输出d的个数(图中就是2*3=6个),其中每一层通道图的计算与上文中提到的一层计算相同,再把每一个通道输出的输出再加起来就是绿色的输出数字。
步长:每次卷积核移动的大小
输出特征尺寸计算:在了解神经网络中卷积计算的整个过程后,就可以对输出特征图的尺寸进行计算。如下图所示,5×5的图像经过3×3大小的卷积核做卷积计算后输出特征尺寸为3×3
全零填充
当卷积核尺寸大于 1 时,输出特征图的尺寸会小于输入图片尺寸。如果经过多次卷积,输出图片尺寸会不断减小。为了避免卷积之后图片尺寸变小,通常会在图片的外围进行填充(padding),如下图所示
全零填充(padding):为了保持输出图像尺寸与输入图像一致,经常会在输入图像周围进行全零填充,如下所示,在5×5的输入图像周围填0,则输出特征尺寸同为5×5。
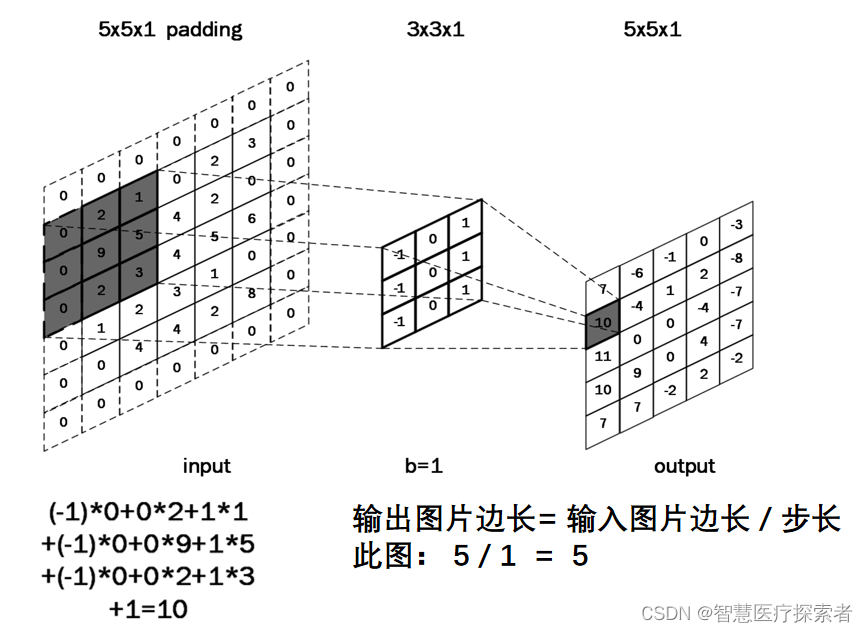
当padding=1和paadding=2时,如下图所示:

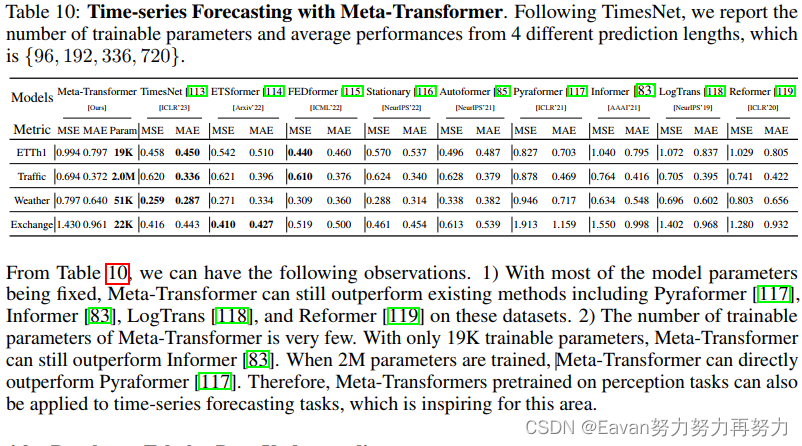
2 使用CNN实现MNIST手写数字识别
机器识图的过程:机器识别图像并不是一下子将一个复杂的图片完整识别出来,而是将一个完整的图片分割成许多个小部分,把每个小部分里具有的特征提取出来,再将这些小部分具有的特征汇总到一起,从而完成机器识别整个图像。
2.1 MNIST数据介绍
MNIST数据集是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60,000个示例的训练集以及10,000个示例的测试集。其中的图像的尺寸为28*28。采样数据显示如下:

2.2 基于pytorch的代码实现
import torch
import torch.nn as nn
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.utils.data as data_utils
import matplotlib.pyplot as plt
import numpy as np
#获取数据集
train_data=dataset.MNIST(root="./data",
train=True,
transform=transforms.ToTensor(),
download=True
)
test_data=dataset.MNIST(root="./data",
train=False,
transform=transforms.ToTensor(),
download=False
)
train_loader=data_utils.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
test_loader=data_utils.DataLoader(dataset=test_data, batch_size=64, shuffle=True)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#创建网络
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv=nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.bat2d=nn.BatchNorm2d(32)
self.relu=nn.ReLU()
self.pool=nn.MaxPool2d(2)
self.linear=nn.Linear(14 * 14 * 32, 70)
self.tanh=nn.Tanh()
self.linear1=nn.Linear(70,30)
self.linear2=nn.Linear(30, 10)
def forward(self,x):
y=self.conv(x)
y=self.bat2d(y)
y=self.relu(y)
y=self.pool(y)
y=y.view(y.size()[0],-1)
y=self.linear(y)
y=self.tanh(y)
y=self.linear1(y)
y=self.tanh(y)
y=self.linear2(y)
return y
cnn=Net()
cnn = cnn.to(device)
#损失函数
los=torch.nn.CrossEntropyLoss()
#优化函数
optime=torch.optim.Adam(cnn.parameters(), lr=0.001)
#训练模型
accuracy_rate = [0]
num_epochs = 10
for epo in range(num_epochs):
for i, (images,lab) in enumerate(train_loader):
images=images.to(device)
lab=lab.to(device)
out = cnn(images)
loss=los(out,lab)
optime.zero_grad()
loss.backward()
optime.step()
print("epo:{},i:{},loss:{}".format(epo+1,i,loss))
#测试模型
loss_test=0
accuracy=0
with torch.no_grad():
for j, (images_test,lab_test) in enumerate(test_loader):
images_test = images_test.to(device)
lab_test=lab_test.to(device)
out1 = cnn(images_test)
loss_test+=los(out1,lab_test)
loss_test=loss_test/(len(test_data)//100)
_,p=out1.max(1)
accuracy += (p==lab_test).sum().item()
accuracy=accuracy/len(test_data)
accuracy_rate.append(accuracy)
print("loss_test:{},accuracy:{}".format(loss_test,accuracy))
accuracy_rate = np.array(accuracy_rate)
times = np.linspace(0, num_epochs, num_epochs+1)
plt.xlabel('times')
plt.ylabel('accuracy rate')
plt.plot(times, accuracy_rate)
plt.show()
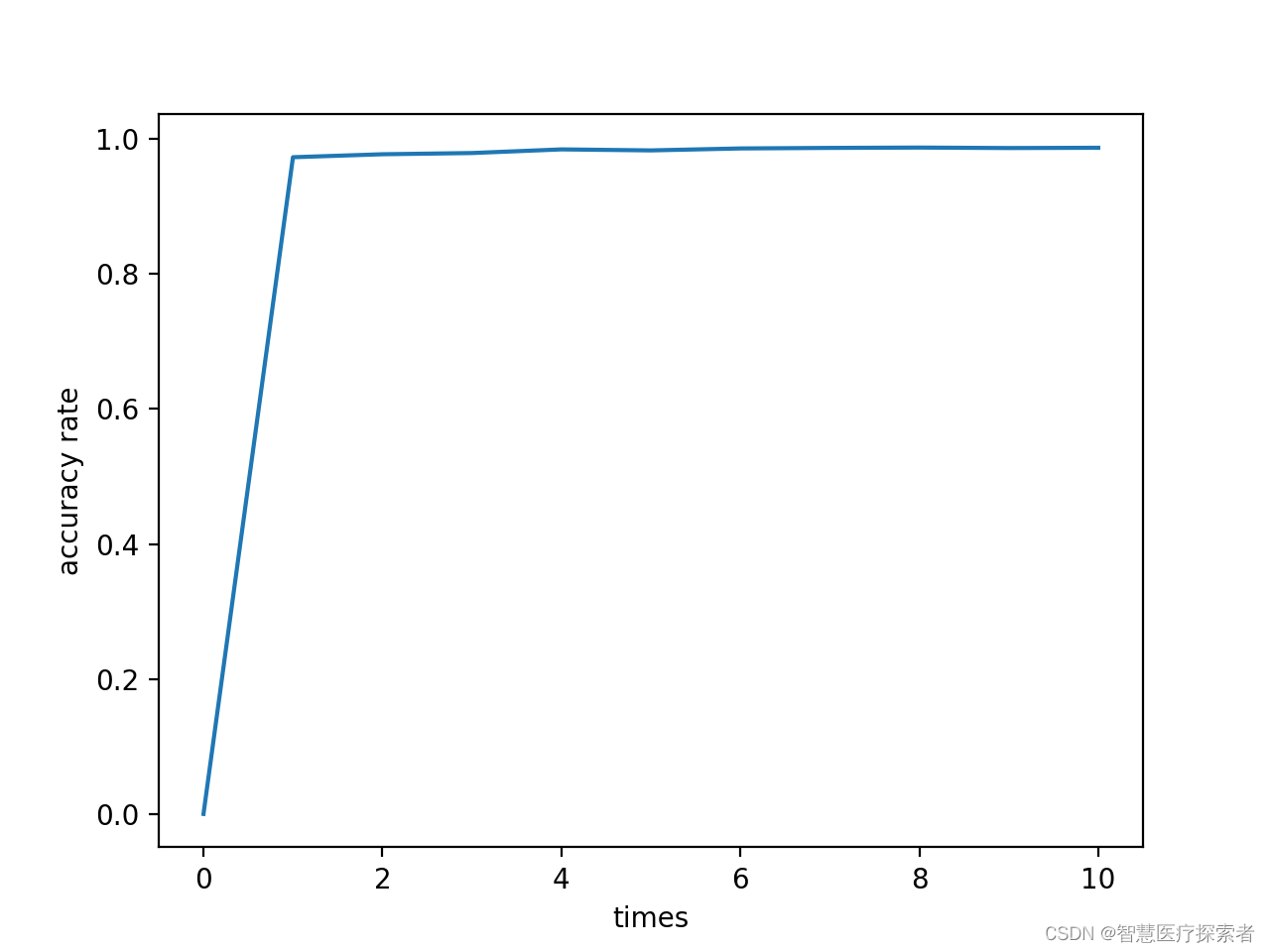
运行结果:
epo:1,i:937,loss:0.2277517020702362
loss_test:0.0017883364344015718,accuracy:0.9729
epo:2,i:937,loss:0.01490325853228569
loss_test:9.064914047485217e-05,accuracy:0.9773
epo:3,i:937,loss:0.0903361514210701
loss_test:0.0003304268466308713,accuracy:0.9791
epo:4,i:937,loss:0.003910894505679607
loss_test:0.00019427068764343858,accuracy:0.9845
epo:5,i:937,loss:0.011963552795350552
loss_test:3.232352901250124e-05,accuracy:0.983
epo:6,i:937,loss:0.04549657553434372
loss_test:0.0001462855434510857,accuracy:0.9859
epo:7,i:937,loss:0.02365218661725521
loss_test:3.670657861221116e-06,accuracy:0.9867
epo:8,i:937,loss:0.00040980291669256985
loss_test:1.4913265658833552e-05,accuracy:0.9872
epo:9,i:937,loss:0.024399513378739357
loss_test:7.590289897052571e-05,accuracy:0.9865
epo:10,i:937,loss:0.0012365489965304732
loss_test:0.00014759502664674073,accuracy:0.9869
3 总结
本文介绍了卷积神经网络中的关键概念,包含卷积核、池化、标准化、感受野等,并基于MNIST数据集,构建了卷积神经网络识别模型,经过10个epochs训练,正确率达到了98%,充分展示了卷积神经网络在图片识别中的作用。