文章目录
- 一 准备用户行为日志-DWD层
- 1 代码实现
- (1)识别新老访客
- (2)利用侧输出流实现数据拆分
- (3)将不同流的数据推送到下游kafka的不同Topic(分流)
- a 封装方法
- b 程序中调用kafka工具类获取sink
- c 测试
- 2 dwd层日志数据采集总结
一 准备用户行为日志-DWD层
1 代码实现
(1)识别新老访客
保存每个mid的首次访问日期,每条进入该算子的访问记录,都会把mid对应的首次访问时间读取出来,跟当前日期进行比较,只有首次访问时间不为空,且首次访问时间早于当日的,则认为该访客是老访客,否则是新访客。
同时如果是新访客且没有访问记录的话,会写入首次访问时间。
is_new为0不用修复,已经访问过,状态是正确的;为1时才会出现状态不准确的情况。
日志格式如下:

// TODO 5 修复新老访客状态
// 按照设备id进行分组
// 匿名内部类
// jsonObjDS.keyBy(new KeySelector<JSONObject, String>() {
// @Override
// public String getKey(JSONObject jsonObj) throws Exception {
// return jsonObj.getJSONObject("common").getString("mid");
// }
// });
// 按照设备id进行分组
// lambda表达式
KeyedStream<JSONObject, String> keyedDS = jsonObjDS.keyBy(
jsonObj -> jsonObj.getJSONObject("common").getString("mid")
);
// 修复,修改json中的某个属性值
SingleOutputStreamOperator<JSONObject> jsonObjWithNew = keyedDS.map(
new RichMapFunction<JSONObject, JSONObject>() {
// 不能在声明的时候初始化状态,这时还不能获取到RuntimeContext
// 富函数只有在调用到open方法时,才可以获取到RuntimeContext
private ValueState<String> lastVisitDateState;
private SimpleDateFormat sdf;
@Override
public void open(Configuration parameters) throws Exception {
lastVisitDateState = getRuntimeContext().getState(new ValueStateDescriptor<String>("lastVisitDateState", Types.STRING));
sdf = new SimpleDateFormat("yyyyMMdd");
}
@Override
public JSONObject map(JSONObject jsonObj) throws Exception {
String isNew = jsonObj.getJSONObject("common").getString("is_new");
if (isNew.equals("1")) {
// 如果之前系统判断是新访客,可能出现错误
// 将之前的访问信息保存到状态中
String lastVisitDate = lastVisitDateState.value();
String curVisitDate = sdf.format(jsonObj.getLong("ts"));
// 判断状态中的上次访日期是否为空
if (lastVisitDate != null && lastVisitDate.length() > 0) {
// 访问过
// 判断是否在同一天访问
if (!lastVisitDate.equals(curVisitDate)) {
isNew = "0";
jsonObj.getJSONObject("common").put("is_new", isNew);
}
} else {
lastVisitDateState.update(curVisitDate);
}
}
return jsonObj;
}
}
);
(2)利用侧输出流实现数据拆分
根据日志数据内容,将日志数据分为3类,页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流。
// TODO 6 按照日志类型对日志进行分流
// 启动 -- 启动侧输出流
// 曝光 -- 曝光侧输出流
// 页面 -- 主流
// 声明侧输出流标签
OutputTag<String> startTag = new OutputTag<String>("start"){};
OutputTag<String> displayTag = new OutputTag<String>("display"){};
// 使用Flink侧输出流进行分流
SingleOutputStreamOperator<String> pageDS = jsonObjWithNew.process(
new ProcessFunction<JSONObject, String>() {
@Override
public void processElement(JSONObject jsonObj, Context context, Collector<String> out) throws Exception {
// 获取启动jsonObj
JSONObject startJsonObj = jsonObj.getJSONObject("start");
String jsonStr = jsonObj.toJSONString();
Long ts = jsonObj.getLong("ts");
// 判断是否为启动日志
if (startJsonObj != null && startJsonObj.size() > 0) {
// 放到启动侧输出流
context.output(startTag, jsonStr);
} else {
// 如果不是启动日志,那么其他日志都属于页面日志,放到主流中
out.collect(jsonStr);
String pageId = jsonObj.getJSONObject("page").getString("page_id");
// 判断是否是曝光日志,曝光日志是一个数组
JSONArray displaysArr = jsonObj.getJSONArray("displays");
if (displaysArr != null && displaysArr.size() > 0) {
// 遍历数据,获取每一条曝光数据
for (int i = 0; i < displaysArr.size(); i++) {
JSONObject displayJsonObj = displaysArr.getJSONObject(i);
displayJsonObj.put("ts", ts);
displayJsonObj.put("page_id", pageId);
// 将曝光日志输出到曝光侧输出流
context.output(displayTag, displayJsonObj.toJSONString());
}
}
}
}
}
);
// 获取不同流数据,输出测试
DataStream<String> startDS = pageDS.getSideOutput(startTag);
DataStream<String> displayDs = pageDS.getSideOutput(displayTag);
pageDS.print("主流:");
startDS.print("启动流:");
displayDs.print("曝光流:");
开启需要的环境,运行程序,执行日志数据生成jar包,观察输出结果。
(3)将不同流的数据推送到下游kafka的不同Topic(分流)
a 封装方法
在MyKafkaUtil中封装获取kafka生产者的方法。
// 获取kafka的生产者
public static FlinkKafkaProducer<String> getKafkaSink(String topic){
return new FlinkKafkaProducer<String>(KAFKA_SERVER,topic,new SimpleStringSchema());
}
b 程序中调用kafka工具类获取sink
// TODO 7 将不同流的数据写到kafka的dwd不同主题中
pageDS.addSink(MyKafkaUtil.getKafkaSink("dwd_page_log"));
startDS.addSink(MyKafkaUtil.getKafkaSink("dwd_start_log"));
displayDs.addSink(MyKafkaUtil.getKafkaSink("dwd_diaplay_log"));
c 测试
# 开启三个kafka消费者
kfkcon.sh dwd_page_log
kfkcon.sh dwd_start_log
kfkcon.sh dwd_display_log
# 启动程序,生成日志数据,观察结果
结果如下图:

2 dwd层日志数据采集总结
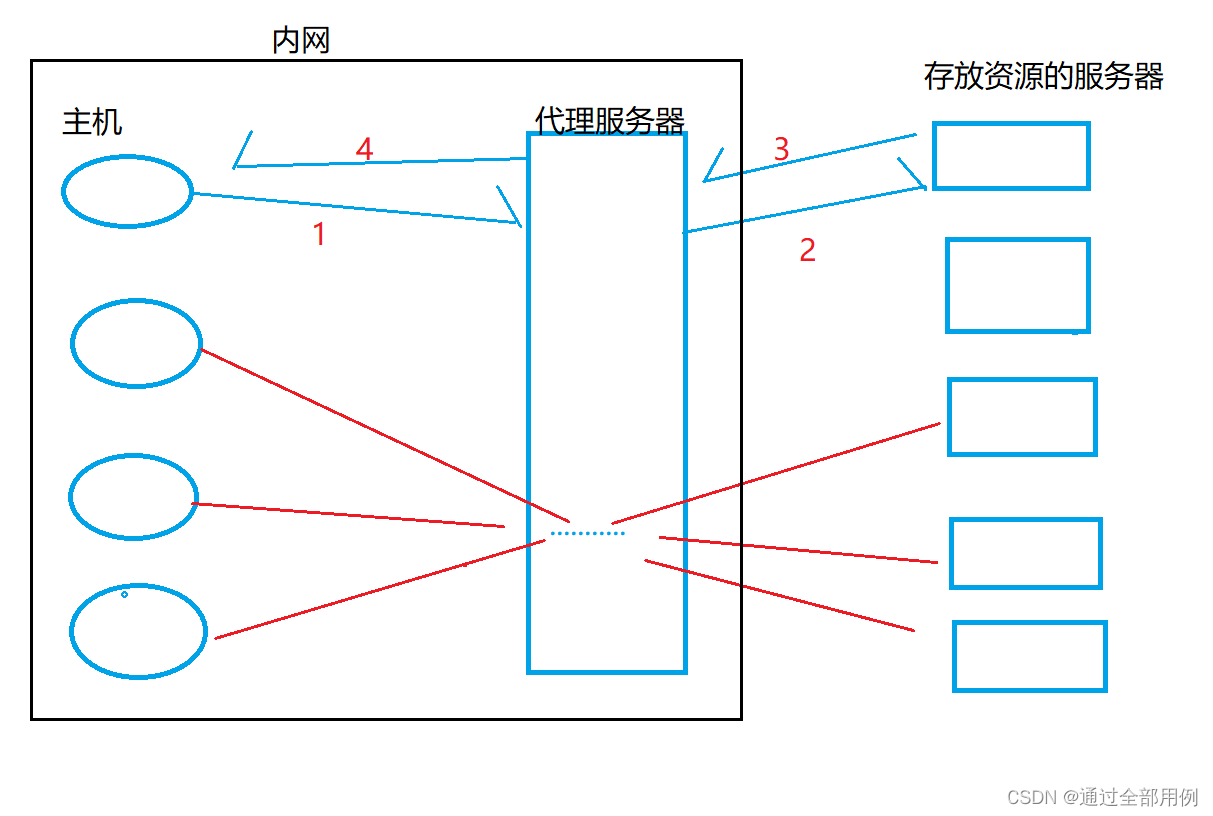
日志数据分流执行流程
-
需要启动的进程
- zookeeper
- kafka
- 如果开启检查点,需要启动hdfs
- logger.sh【日志采集 + nginx】
-
生成模拟生成日志的jar包
-
将生成的日志发送给Nginx
-
Nginx接收到数据之后,进行请求转发,将请求发送给101,102,103上的日志采集服务
-
日志采集服务对数据进行输出、落盘以及发送到kafka的ods_base_log
-
BaseLogApp从ods_base_log读取数据
-
结构转换 String -> JSONObject
-
状态修复 分组、修复
-
分流
-
将分流后的数据写到kafka的dwd不同主题中
-