微服务中统一日志-ELK
- 一.简介
- 1.介绍
- 2.流程
- 3.要求
- 4.下载地址
- 二.安装Elasticsearch
- 1.创建文件存放目录
- 2.进入目录
- 3.下载
- 4.解压
- 5.修改配置
- 5.1.介绍
- 5.2.系统配置
- 5.3修改es配置
- 5.4启动,测试
- 三.安装Kibana
- 1.进入目录
- 2.下载
- 3.解压
- 4.修改配置
- 4.1介绍
- 4.2修改kibana配置
- 4.3启动,测试
- 四.安装Logstash
- 1.进入目录
- 2.下载
- 3.解压
- 4.修改配置
- 4.1介绍
- 4.2修改kibana配置
- 4.3启动
- 五.安装Filebeat
- 1.进入目录
- 2.下载
- 3.解压
- 4.修改配置
- 4.1介绍
- 4.2修改kibana配置
- 4.3启动
- 六.注意,里面的'host.ip'可以查看是哪个服务器发出的错误
一.简介
1.介绍
ELK 是 Elasticsearch、Logstash、Kibana 的简称,准确地说是 ELKB,即 ELK + Filebeat,其中 Filebeat 是用于转发和集中日志数据的轻量级传送工具。Elasticsearch 是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能,可扩展的分布式系统。
2.流程
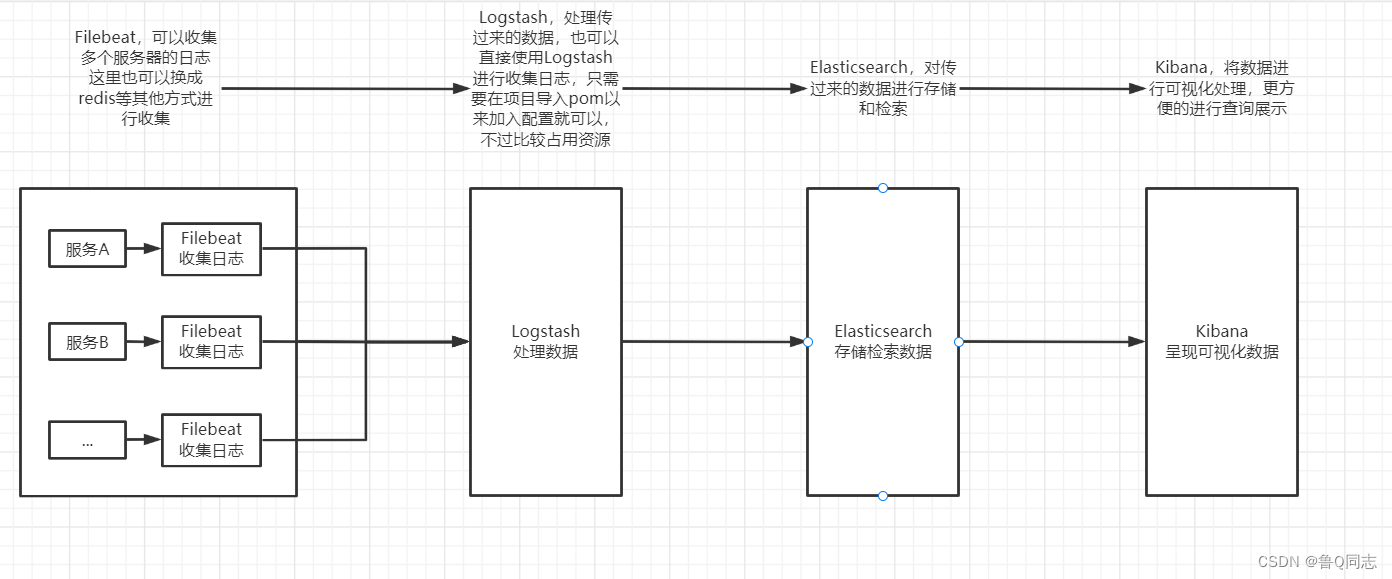
filebeat收集日志>>>Logstash处理过滤数据>>>Elasticsearch存储查询数据>>>Kibana查看日志(可视化)
filebeat可以直接到Elasticsearch不过会占用es大量资源,应该让es专注于查询处理数据
3.要求
查看es的版本支持:https://www.elastic.co/cn/support/matrix#matrix_jvm
1.elasticsearch支持JDK1.8的,仅仅是7.17.x 及其之前的版本。如果下载的最新版本,最低JDK17及其以上
2.ElasticSearch从5.x版本开始为了安全起见,不能直接使用root用户启用
3.jdk最低版本是1.8.0_131
4.linux要求内存最低是1.5g以上
因为我本机安装的是
java version "1.8.0_144",为了兼容jdk这里就不选最新的8.5.2选用低于7.17.x的版本7.16.3,其他的版本也要统一,所以都选择7.16.3
我这里使用虚拟机,版本为CentOS Linux release 7.9.2009 (Core),内存是2g,虚拟机ip地址为192.168.56.11(别想了,我这是电脑启动的虚拟机,只有和电脑一个网段的才能访问我的虚拟机,如果你是服务器的话就不要随便暴露内网IP了,以下只是搭建elk测试的,就没有考虑密码,后面会加上,很简单)
我这里有两个虚拟机,10和11,这里就简单搭建一下,不弄多节点分布式什么的(在日志数据量大,处理复杂的情况下就需要搭建Logstash多节点处理数据,es也可以搭建分布式减少单个的压力),这里只是用于测试。
| 服务器 | 搭建的环境 |
|---|---|
| 11 | Elasticsearch ,Kibana,Logstash,Filebeat |
| 10 | Filebeat |
4.下载地址
Elasticsearch:https://www.elastic.co/cn/downloads/elasticsearch
Logstash:https://www.elastic.co/cn/downloads/logstash
Kibana :https://www.elastic.co/cn/downloads/kibana
Filebeat: https://www.elastic.co/cn/downloads/beats/filebeat
可以在电脑下载完然后在上传到服务器上,也可以在服务器使用wget命令下载,这里使用wget命令进行下载,这里选用的是服务器的
/usr/local/elk目录,这里是测试环境我就把防火墙关闭了,正式的话就要对外放开端口
关闭防火墙
systemctl stop firewalld
二.安装Elasticsearch
1.创建文件存放目录
mkdir /usr/local/elk
2.进入目录
cd /usr/local/elk/
3.下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.16.3-linux-x86_64.tar.gz
4.解压
之后就可以吧压缩包删除了
tar zxvf elasticsearch-7.16.3-linux-x86_64.tar.gz
进入文件
cd elasticsearch-7.16.3
创建
elk用户
adduser elk
给用户赋予文件权限
chown -R elk:elk /usr/local/elk/elasticsearch-7.16.3
在这里创建存储目录
mkdir /home/elk/data & mkdir /home/elk/logs
chown -R elk:elk /home/elk
5.修改配置
5.1.介绍
Elasticsearch 有三个配置文件:这些文件位于 config 目录中
elasticsearch.yml用于配置 Elasticsearchjvm.options用于配置 Elasticsearch JVM 设置log4j2.properties用于配置 Elasticsearch 日志记录
es对文件的限制,线程创建权限需要4096个,文件创建限制65536(是需要这么多,不是直接创建这么多)
linux给普通用户默认可创建分配的是
- 线程创建是1024
- 文件创建限制65535
所以要进行修改
5.2.系统配置
修改文件/线程限制
vi /etc/security/limits.conf
在文件末尾加上如下内容
有的人会报错
max number of threads [xxx] for user [xxx] is too low, increase to at least [4096]
原因就是这里没有进行配置,还有就是linux内存不足1.5g
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
root soft nproc unlimited
# End of file
linux默认不开启虚拟内存,需要手动修改约束
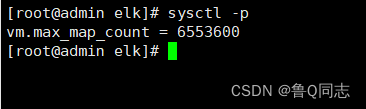
es要求虚拟内存最少65536个字节(大约是65k…),这里给的大一些6553600(大约是6m…)
vi /etc/sysctl.conf
在文件末尾加上如下内容
vm.max_map_count=6553600
加载配置
sysctl -p
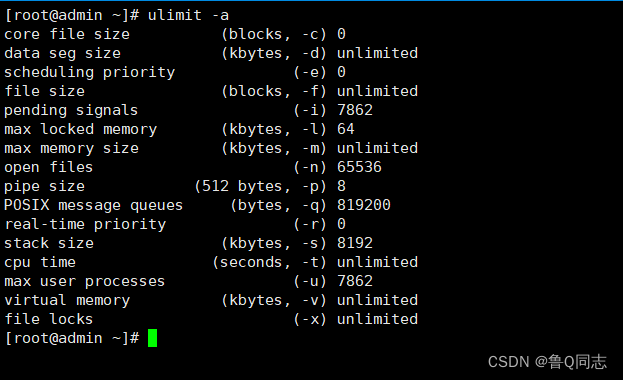
nofile对应open_files,nproc对应max_user_processes,因为是新建用户,这个需要在新建的用户里面查询,修改的话就要在root里面进行修改(创建的用户没有修改权限,只用于启动es)
5.3修改es配置
修改
elasticsearch.yml文件
vi config/elasticsearch.yml
因为配置文件里面的代码都是注释的,这里给他去掉注释就可以,没有的加上就可以
#集群名称
cluster.name: my-cluster
#节点名称
node.name: node-1
#是不是有资格主节点
#node.master: true
#是否存储数据
#node.data: true
#最大集群节点数
#node.max_local_storage_nodes: 2
#存储数据/日志路径,后续在进行创建目录
path.data: /home/elk/data
path.logs: /home/elk/logs
#可以访问的ip地址,这里根据自己需要定义
network.host: 0.0.0.0
#访问端口号
http.port: 9200
#这里我放的是自己虚拟机的ip
discovery.seed_hosts: ["192.168.56.11"]
cluster.initial_master_nodes: ["node-1"]
#启用X-Pack,开启账号密码
#xpack.security.enabled: true
#xpack.security.enrollment.enabled: true
#为 HTTP API 客户端连接启用加密,例如 Kibana、Logstash 和 Agents
#xpack.security.http.ssl:
# enabled: false
# keystore.path: certs/http.p12
#启用集群节点之间的加密和相互认证
#xpack.security.transport.ssl:
# enabled: false
#关闭geoip数据库的更新
ingest.geoip.downloader.enabled: false
#设置为false禁用X-Pack机器学习功能
xpack.ml.enabled: false
修改
jvm.options文件
vi config/jvm.options
大约是31行左右,根据自己的需求和配置进行修改
-Xms1g
-Xmx1g
5.4启动,测试
切换用户
su elk
启动es
bin/elasticsearch
测试
curl 127.0.0.0.1
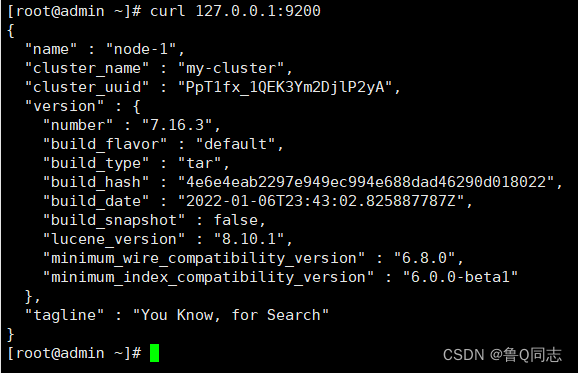
因为开放了防火墙,也可以在外部进行访问(开放端口也可以),ip+端口号码
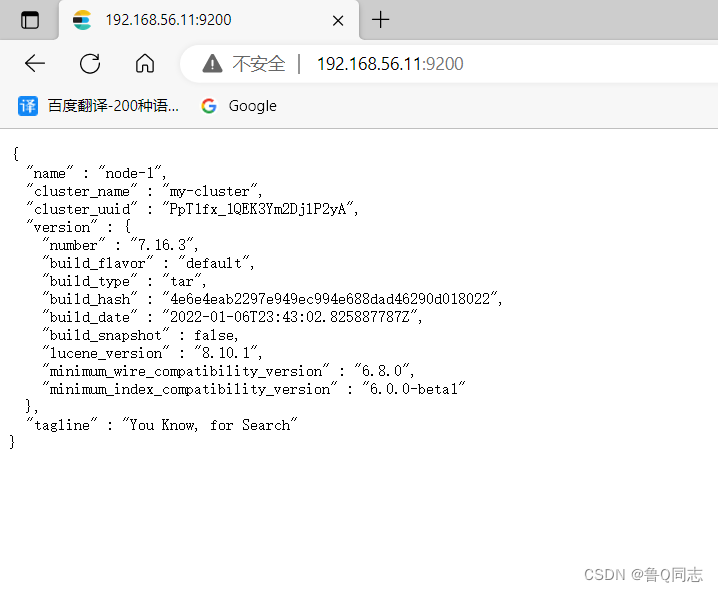
三.安装Kibana
1.进入目录
因为之前运行了一个es,这里需要新建一个链接窗口
cd /usr/local/elk
2.下载
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.16.3-linux-x86_64.tar.gz
3.解压
tar zxvf kibana-7.16.3-linux-x86_64.tar.gz
4.修改配置
4.1介绍
Kibana是对 Elasticsearch索引中的数据进行搜索、查看、交互操作的工具,可以很方便的利用图表、表格等对数据进行多元化的分析和呈现
4.2修改kibana配置
进入文件
cd kibana-7.16.3-linux-x86_64
修改配置
vi config/kibana.yml
文件里面的内容都注释掉了,改成下面内容
#端口号
server.port: 5601
#可以访问的ip,这里可以指定一个固定的访问地址
server.host: "0.0.0.0"
#用于配置对外访问地址,如果不配置页面会有警告信息
server.publicBaseUrl: "http://192.168.56.11:5601"
#服务名
server.name: "kibana-demo"
#下面是之前那个es的地址
elasticsearch.hosts: ["http://192.168.56.11:9200"]
#kibana使用es中的索引来存储保存的检索,可视化控件以及仪表板.如果没有,Kibana就会创建一个新的索引
kibana.index: ".kibana"
#下面这个开启之后界面就变成中文了,一些设置展示除外
#i18n.locale: zh-CN
xpack.monitoring.ui.container.elasticsearch.enabled: true
4.3启动,测试
给用户赋予文件权限,因为kibana也不能在root用户下运行
chown -R elk:elk /usr/local/elk/kibana-7.16.3-linux-x86_64
切换用户
su elk
启动,当前是在
/usr/local/elk/kibana-7.16.3-linux-x86_64目录下面
bin/kibana
测试,浏览器输入既可访问,这里点击自己浏览,如果上面的配置没有使用
i18n.locale: zh-CN开启汉化的话,浏览器应该有翻译功能,反正点这里就行
四.安装Logstash
1.进入目录
这里新建一个链接窗口
cd /usr/local/elk
2.下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.16.3-linux-x86_64.tar.gz
3.解压
tar zxvf logstash-7.16.3-linux-x86_64.tar.gz
4.修改配置
4.1介绍
Logstash 是一款强大的数据处理工具,它可以实现数据传输,格式处理,格式化输出,对数据进行过滤等,常用于日志处理
4.2修改kibana配置
进入文件
cd logstash-7.16.3
根据
logstash-sample.conf模板修改配置文件
cp config/logstash-sample.conf config/logstash-demo.conf
修改logstash-demo.conf文件
vi config/logstash-demo.conf
内容如下
# beats传入的端口,默认5044
input {
beats {
port => 5044
}
}
# 输出日志的方式
output {
# 按照日志标签对日志进行分类处理,日志标签后续会在filebeat中定义,区分日志
if "demo1-log" in [tags] {
elasticsearch {
#传输地址
hosts => ["http://192.168.56.11:9200"]
#索引
index => "[demo1-log]-%{+YYYY.MM.dd}"
}
}
if "demo2-log" in [tags] {
elasticsearch {
#传输地址
hosts => ["http://192.168.56.11:9200"]
index => "[demo2-log]-%{+YYYY.MM.dd}"
}
}
}
修改logstash.yml文件
因为默认Logstash在管道各阶段之间使用内存队列来缓存事件,如果发生意外的终止,则内存中的事件都将丢失。为了防止数据丢失,可以启用Logstash的queue.type: persisted配置,将正在运行的事件持久保存到磁盘,下面的path.queue可以不进行设置,因为默认就在data目录下
queue.type: persisted
#以下都可以不用设置,使用默认的就可以
path.queue: /usr/local/elk/logstash-7.16.3/data #队列存储路径;如果队列类型为persisted,则生效
queue.page_capacity: 200mb #队列为持久化,单个队列大小,根据实际需要进行配置
queue.max_bytes: 1000mb #队列最大容量
queue.max_events: 0 #当启用持久化队列时,队列中未读事件的最大数量,0为不限制
queue.checkpoint.acks: 1024 #在启用持久队列时强制执行检查点的最大数量,0为不限制
queue.checkpoint.writes: 1024 #在启用持久队列时强制执行检查点之前的最大数量的写入事件,0为不限制
queue.checkpoint.interval: 1000 #当启用持久队列时,在头页面上强制一个检查点的时间间隔
4.3启动
启动
bin/logstash -f config/logstash-demo.conf
就会发现连接窗口出现下面代码,表示连接成功
Starting server on port: 5044
五.安装Filebeat
1.进入目录
新建链接窗口
cd /usr/local/elk
2.下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.16.3-linux-x86_64.tar.gz
3.解压
tar zxvf filebeat-7.16.3-linux-x86_64.tar.gz
4.修改配置
4.1介绍
Filebeat是一个轻量级日志文件收集工具,filebeat会监控日志目录或者指定的日志文件,并且转发这些信息到es,logstarsh,redis等存放。
4.2修改kibana配置
进入文件
cd filebeat-7.16.3-linux-x86_64
11服务器,修改配置,间隔是两个空格,这里截取的是java的日志,这里的multiline:这一块就是根据java里面的时间进行过滤成一条

vi filebeat.yml
# 从日志文件输入日志
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/jar/log/*.log
tags: ["demo1-log"]
#排除空行
#exclude_lines: ['^$']
multiline:
type: pattern
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
setup.template.settings:
#设置主分片数
index.number_of_shards: 1
#因为测试环境只有一个es节点,所以将副本分片设置为0,否则集群会报黄
index.number_of_replicas: 0
#下面的Elasticsearch 没有注释需要注释掉
# ---------------------------- Elasticsearch Output ----------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
#输出到logstash,这个是注释掉的要去掉注释
output.logstash:
#logstash所在服务器的ip和端口
hosts: ["192.168.56.11:5044"]
10服务器,修改配置,和11服务器的配置都是一样的,就里面的tags不一样
# 从日志文件输入日志
filebeat.inputs:
- type: log
enabled: true
paths:
- /opt/jar/log/*.log
tags: ["demo2-log"]
#排除空行
#exclude_lines: ['^$']
multiline:
type: pattern
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
setup.template.settings:
#设置主分片数
index.number_of_shards: 1
#因为测试环境只有一个es节点,所以将副本分片设置为0,否则集群会报黄
index.number_of_replicas: 0
#下面的Elasticsearch 没有注释需要注释掉
# ---------------------------- Elasticsearch Output ----------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
#输出到logstash,这个是注释掉的要去掉注释
output.logstash:
#logstash所在服务器的ip和端口
hosts: ["192.168.56.11:5044"]
4.3启动
这里先启动11服务器的进行测试查看
./filebeat -e -c filebeat.yml
因为采集日志的目录在
/opt/jar/log/*.log
这里创建文件上传jar包
mkdir -p /opt/jar/log
我这里把jar上传到
/opt/jar目录下日志存放在/opt/jar/log目录下
我的代码就做了简单的测试
server:
port: 9001
spring:
application:
name: demo1
package com.ly.demo1.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class demo1 {
private static final Logger LOG = LoggerFactory.getLogger(demo1.class);
@GetMapping("/info")
public String info(){
LOG.info("[demo1 log]"+"info");
return "info";
}
@GetMapping("/err")
public String error(){
LOG.error("[demo1 error]"+"error");
int i = 1/0;
return "error";
}
}
nohup java -jar demo1.jar > log/a.log &
启动完jar包之后,我们先打开那个5601端口进行查看
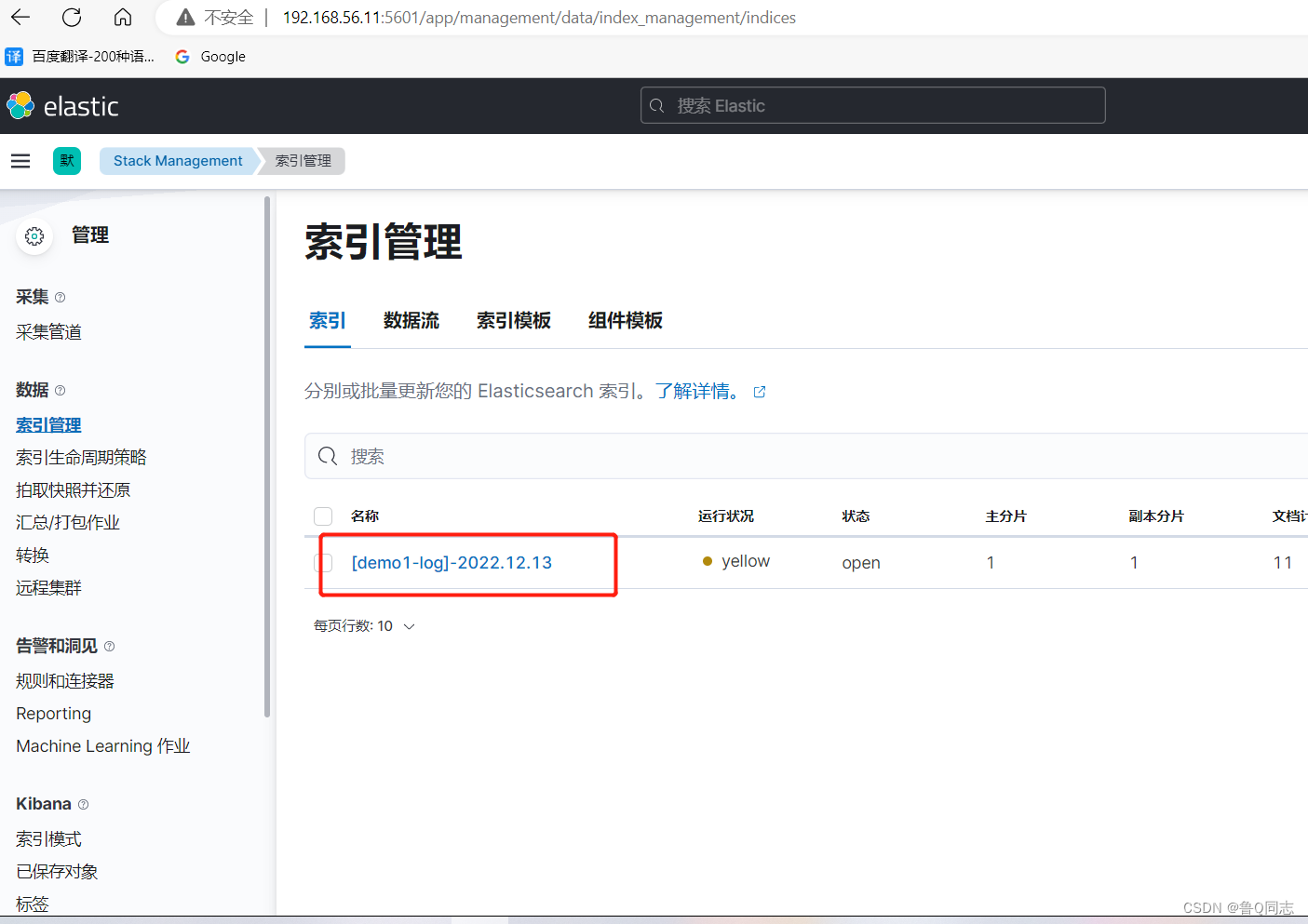
就会发现已经出现了一个索引
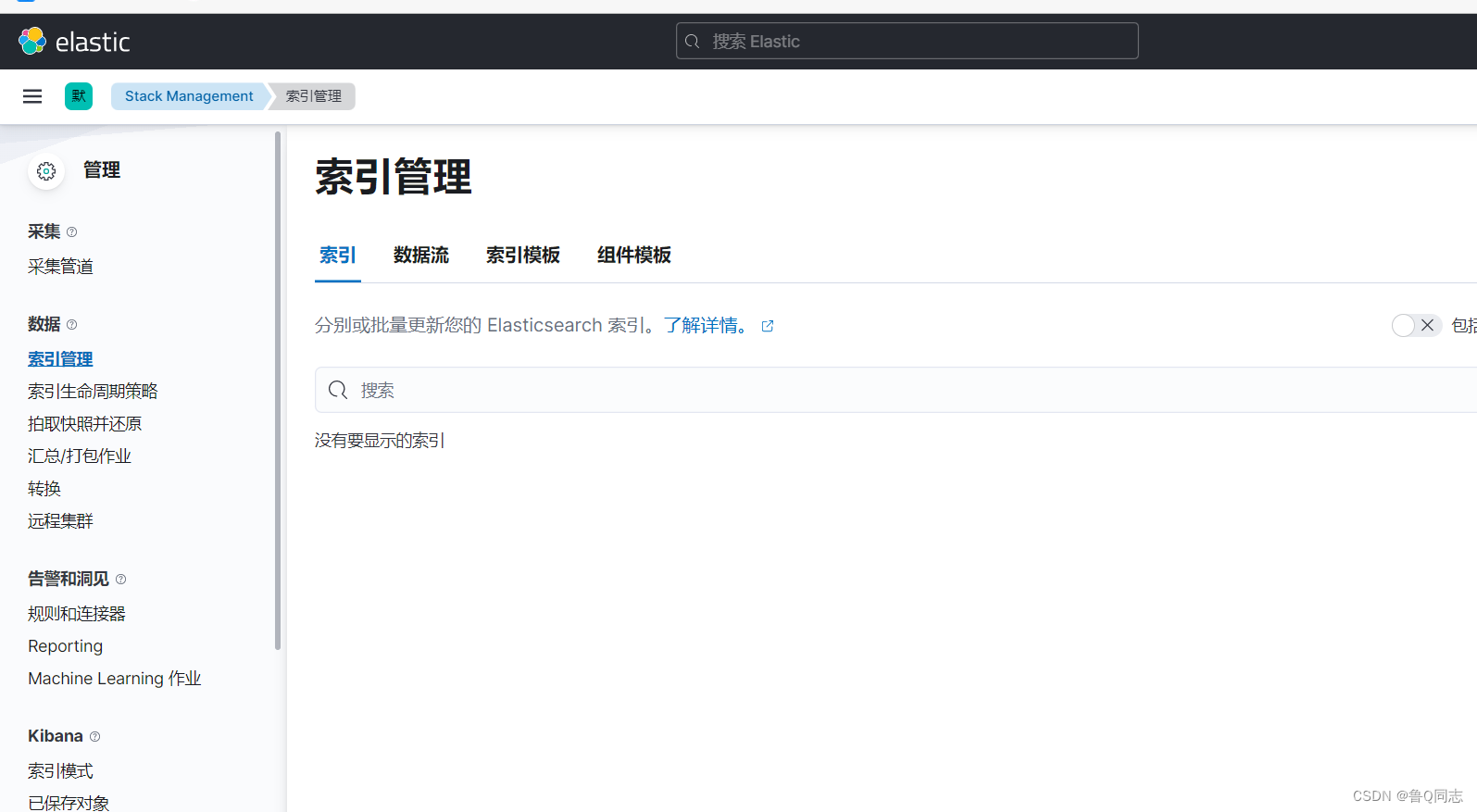
没有启动jar包之前是没有的
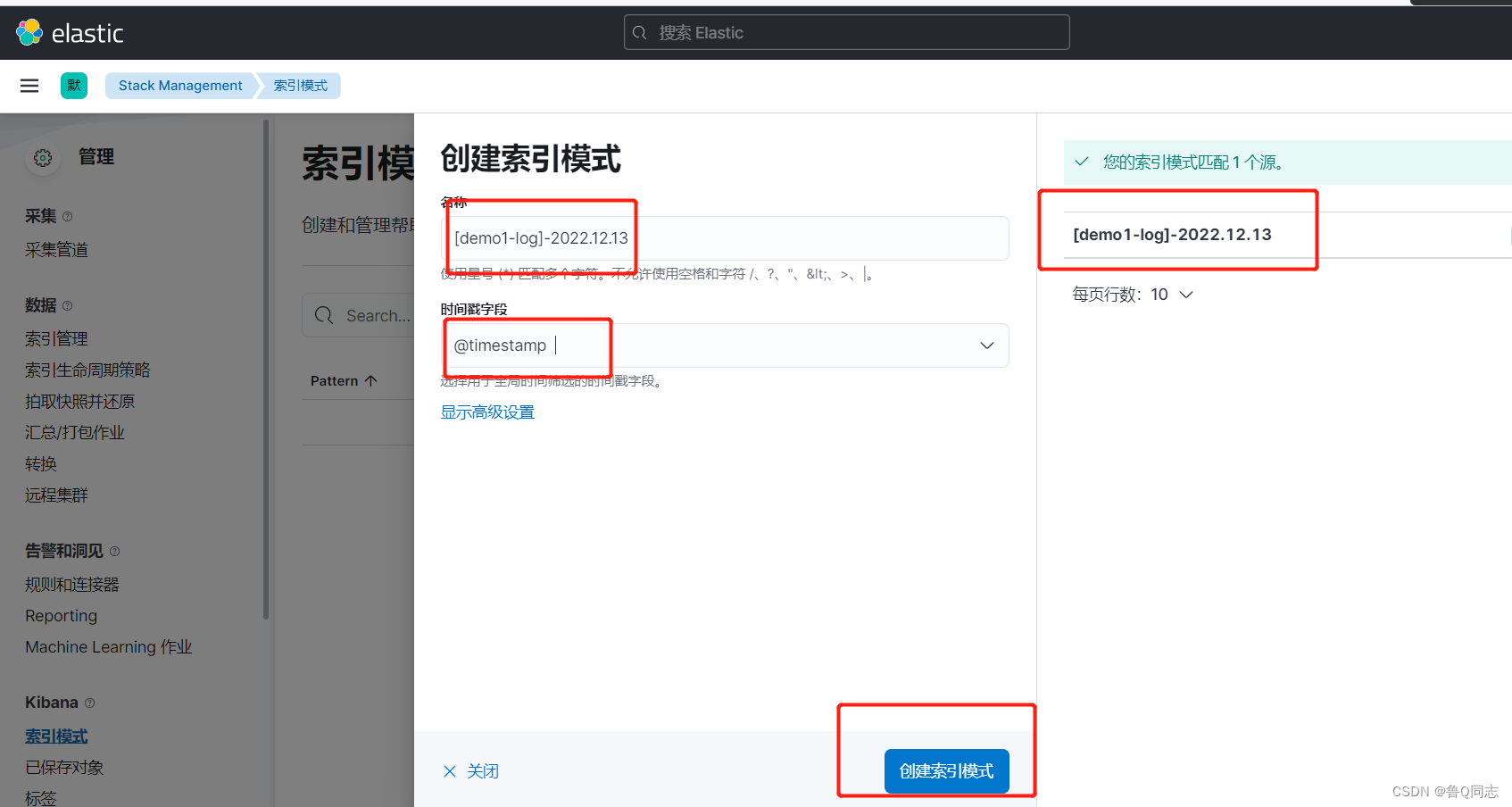
直接通过索引进行搜索日志是不行的,需要先进行创建
这个名称和左侧是的一样,时间戳选择第一个@timestamp
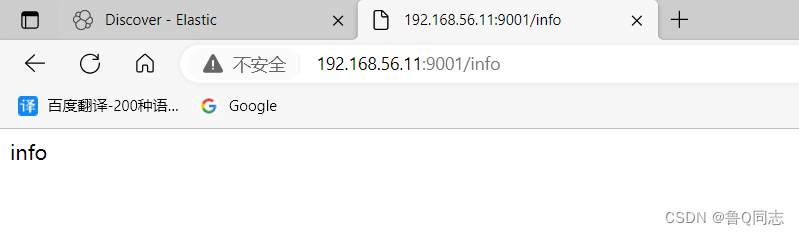
访问192.168.56.11:9001/info查看日志
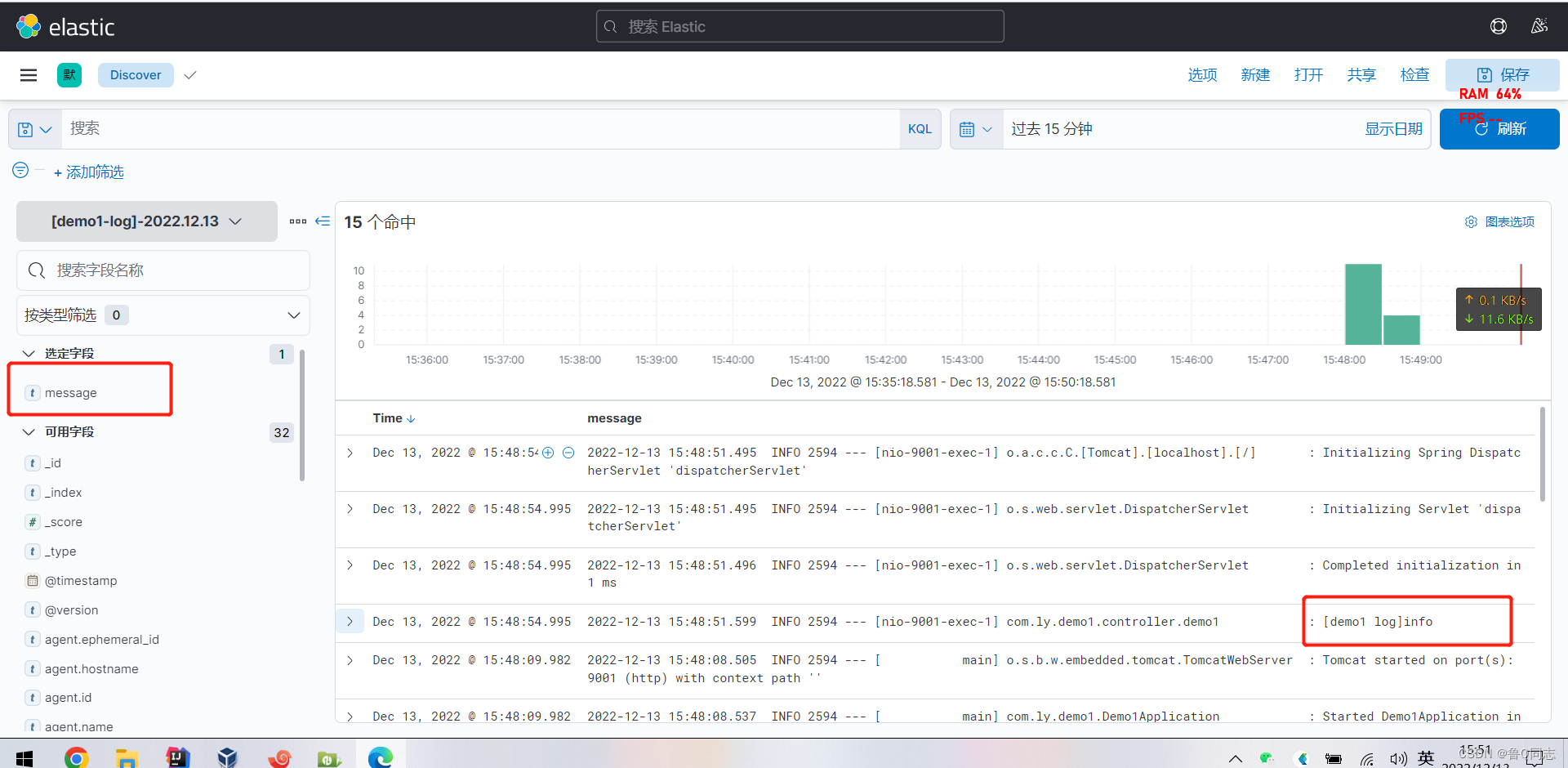
可以根据左边的进行筛选,然后就能看到输出的日志
也可以查看报错
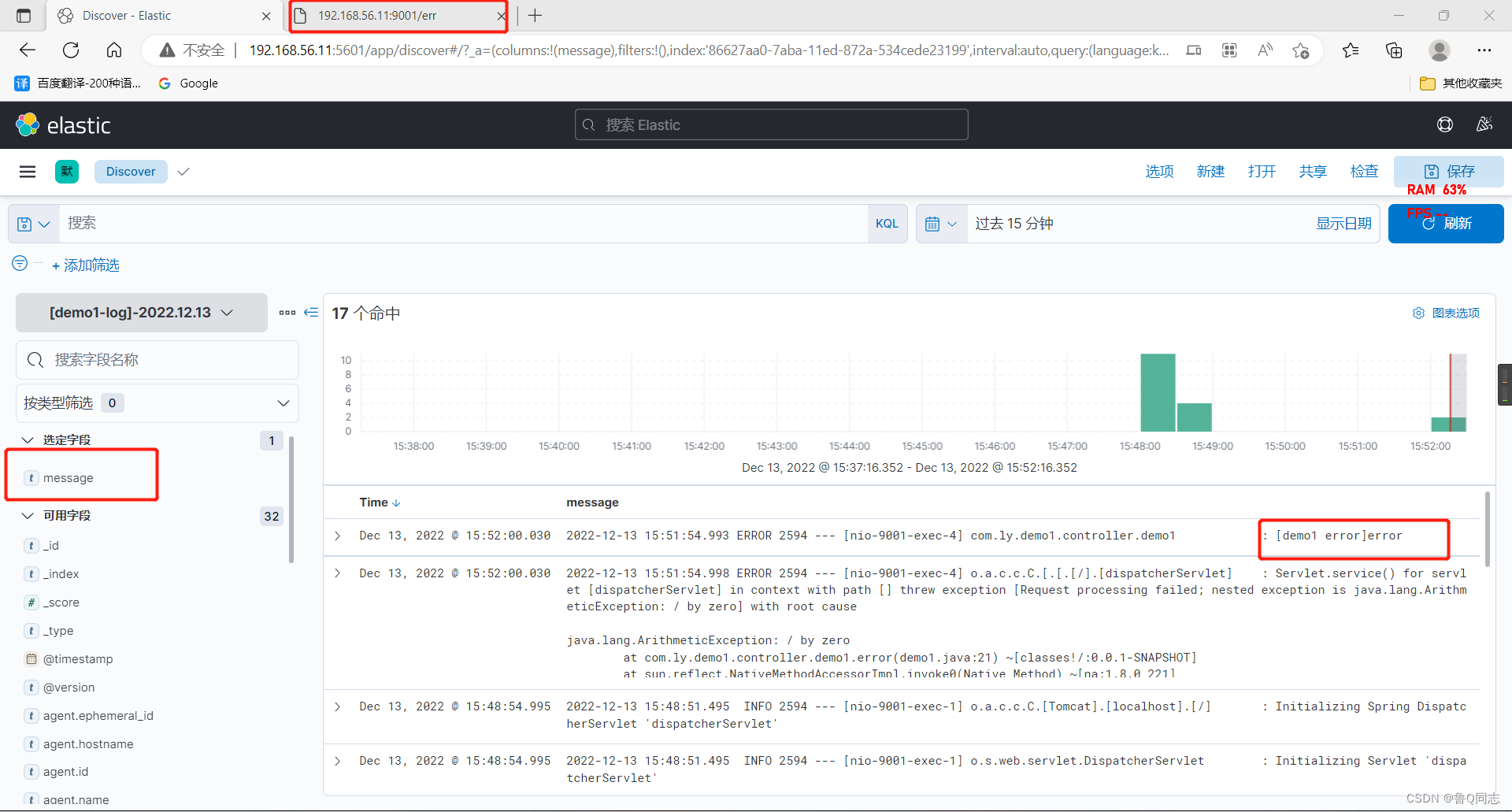
六.注意,里面的’host.ip’可以查看是哪个服务器发出的错误
现在同样启动10虚拟机里面的jar和filebeat服务
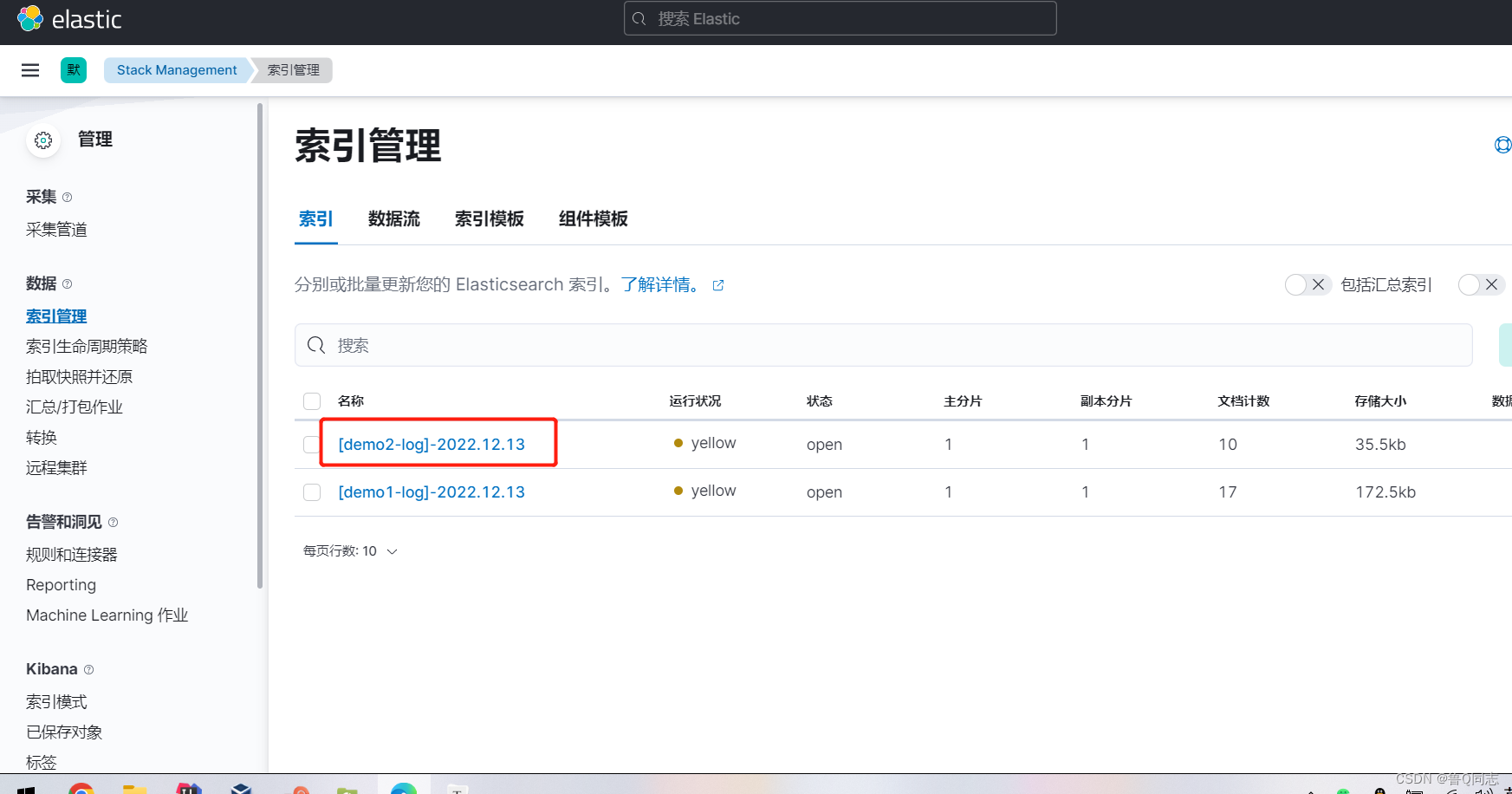
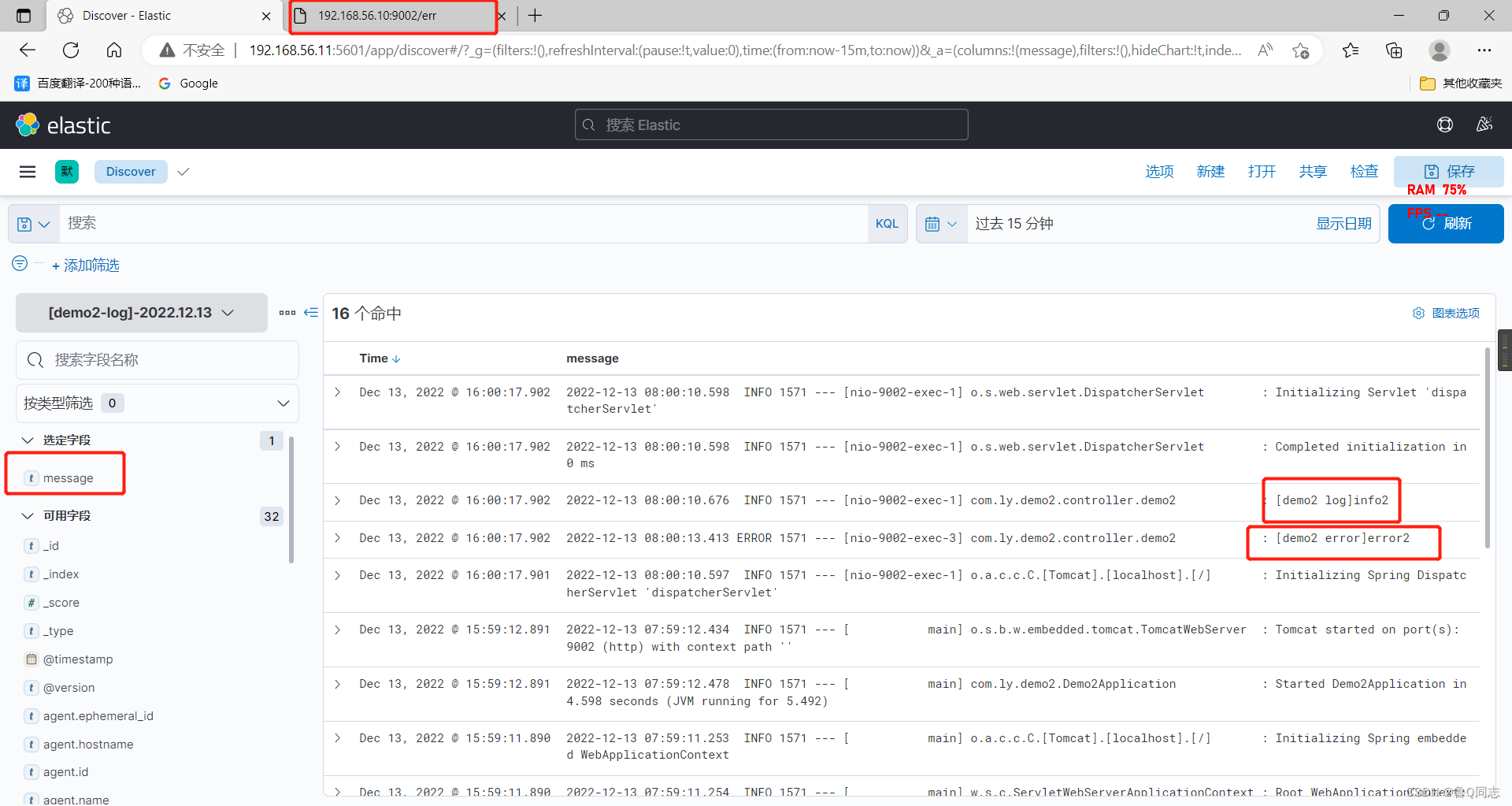
至此,直接结束








![[附源码]Python计算机毕业设计电影院订票系统Django(程序+LW)](https://img-blog.csdnimg.cn/fb20d44cce7349d0be795ad86b23d737.png)



![[附源码]Nodejs计算机毕业设计基于RationalRose的教务管理系统开发Express(程序+LW)](https://img-blog.csdnimg.cn/6b3d13784f8d4997a2f2f2886ac407d2.png)