Spring Data基本介绍
目录
- Spring Data Redis 官方API参考手册!
- ★ Spring Data的价值
- ★ Spring Data及其子项目
- ★ 强大的Spring Data
- ★ Repository接口
- ★ 具体Repository接口
- ★ Spring Data JPA开发
- ★ Spring Boot如何选择DataSource
- ★ 数据源相关配置
- ★ 配置第三方数据源(C3P0)
- ★ 配置多个数据源
- ★ 方法名关键字查询(全自动)
- ★ @Query查询(半自动:提供SQL或JPQL)
- ★ 命名查询
- ★ 自定义查询(全手动)
- ★ 样本查询
- ★ Specification查询
Spring Data Redis 官方API参考手册!
👉:🔗Spring Data Redis 官方API参考手册
👉:🔗Lettuce 6.2.5.RELEASE API官方API参考手册
★ Spring Data的价值
高度统一:只需要一套API: Spring Data,可以同时访问SQL数据和NoSQL数据库。
真正掌握Spring Data之后,你可以做到随心所欲地访问任意的SQL数据库和NoSQL数据库。
开发者:只需要面向通用的Spring Data API编程,程序就可以自由地在各种SQL或NoSQL技术之间切换。
★ Spring Data及其子项目
从结构上来说,Spring Data相当于是一个总的项目,Spring Data包括如下子项目:
Spring Data JDBC:Spring Data对传统JDBC的封装。
Spring Data JPA:Spring Data对JPA的封装。
Spring Data MongoDB:Spring Data对MongoDB的封装。
Spring Data Redis:Spring Data对Redis的封装。
…
从逻辑关系上来说,Spring Data相当于Spring Data Xxx子项目的抽象层,而Spring Data Xxx是具体实现。
实际上Spring Data还包括一个Spring Data Commons子项目,该子项目就是Spring Data的通用抽象层。
习惯:常常所说的,面向Spring Data编程,其实是面向Spring Data Commons子项目编程,
该子项目才是Spring Data的通用抽象层。
★ 强大的Spring Data
▲ 从代码简化的角度来说,DAO组件(官方叫Repository组件)的各种通常CRUD方法完全不需要开发者编写任何代码,
Spring Data能通过动态代理的方式动态地生成CRUD方法。
如果你要简单,Spring Data说:OK,你不需要写任何代码。我就能帮你搞定通用的CRUD操作。
▲ 从功能强大的角度来说,Spring Data既允许开发者自定义SQL或NoSQL查询语句来执行查询、从而优化查询。
如果你要优化SQL语句,Spring Data说:OK,你只要用注解提供SQL语句,剩下的查询过程我就能帮你搞定。
▲ 也允许开发者直接调用相应技术的底层API来实现数据访问,完全是鱼和熊掌可以得兼。
如果你要完全接管数据库访问访问的代码实现,Spring Data说:OK,剩下的交给你了。
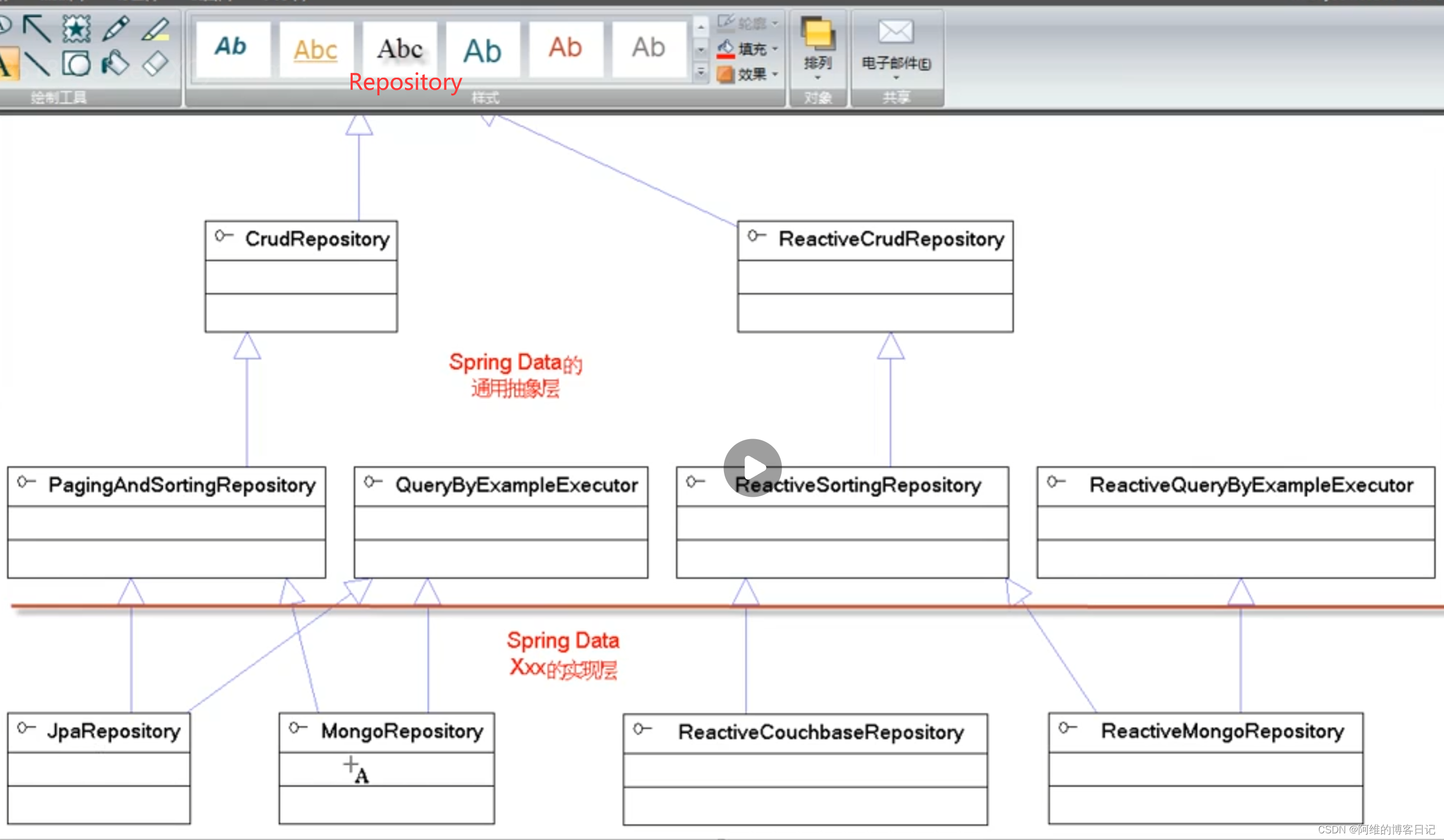
★ Repository接口
▲ Repository接口是Spring Data通用抽象层的核心API,所有DAO组件都应该继承它或它的子接口。
Repository接口派生了如下两个子接口:
- CrudRepository:主要提供了各种CRUD方法,继承该接口的DAO组件不用编写任何代码
就可执行各种通用的CRUD数据访问及各种数据查询 。
- ReactiveCrudRepository:类似于CrudRepository接口,只不过它的方法都是反应式的,
因此它的方法的返回值都是Mono或Flux。
PagingAndSortingRepository接口继承了CrudRepository接口,增加了分页和排序功能。(额外增加了分页和排序的方法)
——补充一点,其实CrudRepository本身也可做分页和排序(通过传入额外参数),因此实际上CrudRepository用得更多一些。
ReactiveSortingRepository接口则继承了ReactiveCrudRepository接口,它相当于PagingAndSortingRepository的反应式版本。
★ 具体Repository接口
前面4个XxxRepository属于Spring Data Commons子项目,属于Spring Data的通用抽象层,如果让DAO组件继承它们,这样DAO组件的底层就可以在任意持久化技术、甚至任意数据存储技术(不管是SQL数据库也好,还是NoSQL数据库也好)之间自由切换。
此外,各Spring Data Xxx子项目也提供了对应的XxxRepository,比如:
Spring Data JPA提供了JpaRepository、
Spring Data MongoDB提供了MongoRepository……
这些针对特定技术的Spring Data Xxx子项目提供的XxxRepository都是PagingAndSortingRepository
或ReactiveSortingRepository的子接口。
一般,并不建议面向XxxRepository接口编程,因为这种接口是属于Spring Data Xxx子项目。不是Spring Data抽象层。
★ Spring Data JPA开发
(1)配置数据源。
(2)配置JPA相关属性,这些属性由JpaProperties类负责处理。
——上面2步都在application.properties中配置即可。
(3)使用JPA注解定义实体类。
(4)继承CrudRepository或其子接口实现DAO组件,如要实现反应式DAO组件,继承ReactiveCrudRepository或其子接口。
我们只需要开发DAO组件的接口,并不需要提供实现类。
如果要做分页查询,需要使用Pageable参数,但Pageable有个实现类:PageRequest,调用它的of方法即可创建 Pageable对象
★ Spring Boot如何选择DataSource
HikariCP > Tomcat pooling DataSource > Commons DBCP2
Spring Boot的spring-data-starter-jdbc默认就自带了HikariCP 的JAR包。
如果你不指定任何额外信息,Spring Boot默认会为我们创建HikariCP 的数据源。
★ 数据源相关配置
数据源的通用配置以spring.datasource.*开头的属性进行配置。
spring.datasource.*开头的属性由DataSourceProperties类负责加载、处理。
如果想对特定数据源实现增加配置,可通过特定前缀的属性进行配置,例如:
- spring.datasource.hikari.*:专门配置HikariCP的属性。
- spring.datasource.tomcat.*:专门配置Tomcat池化数据源的属性。
- spring.datasource.dbcp2.*:专门配置DBCP2数据源的属性。
@ConfigurationProperties可修饰类,将该类变成属性处理类。
@ConfigurationProperties还可修饰@Bean配置Bean组件,
此时该注解读取的配置文件中的每个属性都会调用该Bean的一个setter方法
比如在配置文件中读到一个abc属性,它就会尝试调用配置Bean的setAbc()方法
★ 配置第三方数据源(C3P0)
首先需要排除HikariCP依赖库,还要添加C3P0的依赖
▲ 简单配置方式,只要一行(不能定制,早期版本才支持,Spring Boot 2.4开始不再支持):
spring.datasource.type=com.mchange.v2.c3p0.ComboPooledDataSource
▲ 复杂配置(用自定义的数据源代替自动配置的数据源)
(1)先在容器中用@Bean配置一个C3P0数据源
(2)然后用@ConfigurationProperties读取配置属性来对C3P0数据源进行配置
★ 配置多个数据源
可在容器中用@Bean配置多个数据源。
如果希望Spring Boot能依赖注入某个数据源,可用@Primary注解修饰它。
——该注解修饰的数据源将作为整个应用默认的数据源。
【注意:】,如果你要配置多个数据源泉,必须自己显式地在容器中配置多个。
不可能说你配置一个,Spring Boot帮你自动配置一个,这是不可能的。
Spring Boot自动配置的DataSource Bean有一个@ConditionalOnMissingBean(DataSource.class)。
★ 方法名关键字查询(全自动)
(1)继承CrudRepository接口的DAO组件可按特定规则来定义查询方法,
只要这些查询方法的方法名遵守特定的规则,Spring Data将会自动为这些方法生成查询语句、提供方法实现体。
(2)方法名关键字的查询方法能以find...By、read...By、query…By、count…By(查询记录的条数)、get…By开头,
并在方法名中嵌入特定关键字即可,Spring Data就会自动生成相应的查询方法体。
▲ 关键字规则
在方法名中将属性名、运算符都设计成关键字,比如如下:
- findByName(String name),这表明根据name属性执行查询。
- findByAgeGreaterThan(int age):表明查询age属性大于指定值的记录。
具体可参考教材中表5.1
▲ 关键字方法中同样可定义Pagable、Sort参数,用于控制分页和排序。
说明:如果要做分页或排序的查询,其实没必须要去继承PagingAndSortingRepository,继承CrudRepository也是可行的
▲ 需要说明的情况:
一种情况需要说明,对比如下两个方法:
- findByAddressAndZip:该方法要根据address和zip两个属性进行查询,
它对应的JPQL片段为:... where x.address = ?1 and zip = ?2。
- findByAddressZip:留意该方法名的Address和Zip之间既没有And,也没有Or,
那就表明用的是“属性路径”方式,表明该方法要根据address属性的zip属性进行查询,
它对应的JPQL片段为:... where x.address.zip = ?1。
如果你的方法名中的关键字写错了,往往就会报QueryCreateException。
★ @Query查询(半自动:提供SQL或JPQL)
——让开发者指定JPQL或SQL查询,剩下的事情由Spring Data来负责完成:帮你生成查询方法、实现查询功能。
▲ @Query注解
通过使用@Query注解修饰查询方法,可以让查询方法使用自定义的JPQL或SQL执行查询,该注解可以指定如下常用属性:
- name:指定使用哪个命名查询。
命名查询的本质就是为JPQL或SQL语句起个名字,因此指定使用哪个命名查询也就是指定了JPQL或SQL语句。
- nativeQuery:指定是否为SQL查询,如果该属性为true,表明是原生SQL查询,否则就是JPQL查询。
- value:指定自定义的JPQL或SQL语句。
你想指定JPQL语句也行,你想指定SQL语句也行——你想怎么优化就怎么优化。
▲ Modifying注解
如果@Query注解指定的查询语句要对底层数据进行修改,还需要使用@Modifying注解修饰该方法,
该注解修饰的方法可以修改底层的数据。
【提示:】 Spring Boot有一个很优秀的设计,当你在测试DAO组件的方法时,测试完成后方法的测试结果会自动回滚。
如果你确实想在测试DAO组件时,测试结束后提交事务,而不是回滚事务(默认设置)。
—— 只要将测试方法添加@Rollback(false)
★ 命名查询
甚至不再需要使用@Query注解
——只要让@NamedQuery或@NamedNativeQuery所定义的命名查询的查询名等于实体类的类名+DAO组件的查询方法的方法名
中间以点号(.)隔开。
@NamedQuery或@NamedNativeQuery一般用在实体类上定义查询语句。
不难发现,命名查询与直接用@Query来定义查询的本质是一样,只不过它们定义SQL或JPQL语句的位置不同。
★ 自定义查询(全手动)
——Spring Data什么都不干,所有查询方法的方法体完全由开发者来实现。
▲ 自定义查询方法的设计(编程步骤)
(1) 让DAO组件接口额外继承一个自定义DAO接口
(2) 自定义DAO接口可以定义数据访问方法,再为该自定义DAO接口定义实现类、在该实现类中实现自定义的方法。
Spring Data就能将自定义DAO接口的实现类中实现的查询方法“移植”给自己的DAO组件。
▲ 自定义查询方法的实现原理
DAO组件的实现类由Spring Data使用动态代理来动态生成的,因此DAO组件中所有查询方法的方法体都由Spring Data负责生成。
对于DAO接口中从父接口(自定义接口)中继承得到的方法,Spring Data会直接用其父接口的实现类所实现的查询方法作为其实现。
★ 样本查询
给Spring Data传入一个样本数据,Spring Data就能从数据库中查询出和样本相同的数据。
被查询的数据并不需要和样本是完全相同的,可能只需要和样本有几个属性是相同的。
▲ 样本查询的API(QueryByExampleExecutor):
JpaRepository继承了QueryByExampleExecutor接口,该接口提供了如下“样本查询”方法:
- <S extends T> Optional<S> findOne(Example<S> example);
- <S extends T> Iterable<S> findAll(Example<S> example);
- <S extends T> Iterable<S> findAll(Example<S> example, Sort sort);
- <S extends T> Page<S> findAll(Example<S> example, Pageable pageable);
- <S extends T> long count(Example<S> example);
- <S extends T> boolean exists(Example<S> example);
只要让DAO接口继承该QueryByExampleExecutor接口,DAO组件就可调用上面的样本查询方法。
——方法实现不要你操心,Spring Data会负责搞定它们。
▲ 创建Example
Example查询的关键在于Example参数,它提供了如下两个of()类方法来创建Example对象:
- of(T probe):以probe对象创建最简单的Example对象,使用默认的匹配规则。
要求被查询对象与样本对象所有属性都严格相等。
- of(T probe, ExampleMatcher matcher):以probe创建Example对象,并使用matcher指定匹配规则。
▲ ExampleMatcher提供了如下静态方法来创建实例:
- static ExampleMatcher matching():创建一个需要所有属性都匹配的匹配器。 (and运算符)
- static ExampleMatcher matchingAll():完全等同于matching()方法
- static ExampleMatcher matchingAny():创建一个只要任意一个属性匹配的匹配器。(or运算符)
▲ ExampleMatcher还可通过如下方法来指定对特定属性的匹配规则:
- withIgnoreCase():指定属性匹配时默认不区分大小写。
- withIgnoreCase(String... propertyPaths):指定propertyPaths参数列出的属性在匹配时不区分大小写。
- withIgnoreNullValues():指定不比较Example对象中属性值为null的属性。
- withIgnorePaths(String... ignoredPaths):指定忽略ignoredPaths参数列出的属性,也就是这些属性不参与匹配。
- withIncludeNullValues():强行指定要比较Example对象中属性值为null的属性。
- withMatcher(String propertyPath, 比较器):对propertyPath参数指定的属性使用专门的匹配规则。
▲ 样本查询的步骤:
(1) 让DAO接口要么继承JpaRepository(是QueryByExampleExecutor的子接口),或者增加继承QueryByExampleExecutor
(2) DAO组件可调用QueryByExampleExecutor的样本查询方法
★ Specification查询
它也是Spring Data提供的查询——是对JPA本身Criteria动态查询的包装。
▲ 为何要有动态查询
页面上常常会让用户添加不同的查询条件,程序就需要根据用户输入的条件,动态地组合不同的查询条件。
JPA为动态查询提供了Criteria查询支持。
Spring Data JPA则对Criteria查询进行了封装,封装之后的结果就是Specification查询。
——Specification查询比Jpa的Criteria动态查询更加简单。
▲ 核心API: JpaSpecificationExecutor
- long count(Specification spec):返回符合Specification条件的实体的总数。
- List findAll(Specification spec):返回符合Specification条件的实体。
- Page findAll(Specification spec, Pageable pageable):返回符合Specification条件的实体,
额外传入的Pageable参数用于控制排序和分页。 - List findAll(Specification spec, Sort sort):返回符合Specification条件的实体,
额外传入的Sort参数用于控制排序。 - Optional findOne(Specification spec):返回符合Specification条件的单个实体,
如果符合条件的实体有多个,该方法将会引发异常。
▲ Specification查询的步骤:
(1)让你的DAO接口继承JpaSpecificationExecutor。
(2)构建Specification对象,用于以面向对象的方式来动态地组合查询条件。
——最方面的地方(改进的地方),这一步就是为了解决动态拼接SQL的问题,而是改为使用面向对象的方式来组合查询条件。
▲ 如何创建Specification对象(用于组合多个查询条件)
- Specification参数用于封装多个代表查询条件的Predicate对象。
- Specification接口只定义了一个toPredicate()方法,该方法返回的Predicate对象就是Specification查询的查询条件,
程序通常使用Lambda表达式来实现toPredicate()方法来定义动态查询条件。
▲ 还涉及如下两个API(本身就是在JPA的规范)
Predicate - 代表了单个查询条件,相当于sql语句的where子句中的单个的条件。也可用于组合多个查询条件。
CriteriaBuilder - 专门用于构建单个Predicate。
▲ 如何组合多个查询条件?
两种方式:
A - 用Specification的and或or来组合多个 Specification——每个Specification只组合一个查询条件。
B - 先用CriteriaBuilder的and或or来组合多个Predicate对象,得到一个最终的Predicate,然后再将Predicate包装成Specification。