常见分布式ID解决方案总结
- 分布式ID
- 分布式ID方案之数据库
- 数据库主键自增
- 数据库号段模式
- Redis自增
- MongoDB
- 分布式ID方案之算法
- UUID
- Snowflake(雪花算法)
- 雪花算法的使用
- IdWorker工具类
- 配置分布式ID生成器
- 分布式ID方案之开源组件
- uid- generator(百度)
- Tinyid(滴滴)
- Leaf(美团)
- 三者比较
- Leaf组件的使用
- 源码打包
- 引入依赖
- Leaf配置参数
- 号段模式配置
- Snowflake模式配置
- 注解启动leaf
- API的使用
- 号段模式测试
- 雪花算法测试
分布式ID
分布式 ID(Distributed ID)是指在分布式系统中生成全局唯一的标识符,用于标识不同实体或数据对象。在分布式系统中,由于数据存储、计算和处理都分散在不同的节点上,因此需要一个可靠的方式来跟踪和标识这些数据对象。
分布式ID最低要求:
全局唯一 :ID 的全局唯一性肯定是首先要满足的
高性能 : 分布式 ID 的生成速度要快,对本地资源消耗要小
高可用 :生成分布式 ID 的服务要保证可用性无限接近于 100%
方便易用 :拿来即用,使用方便,快速接入
优秀的分布式 ID
安全 :ID 中不包含敏感信息
有序递增 :如果ID存放在数据库,ID的有序性可以提升数据库写入速度。有利于ID来进行排序
有具体的业务含义 :生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)
独立部署 :分布式系统单独有一个发号器服务,专门用来生成分布式 ID
分布式ID方案之数据库
数据库主键自增
数据库自增ID是在数据库中创建表时,通过设置一个自增的ID字段来实现的。每当插入一条记录时,数据库会自动为该记录生成一个唯一的ID。
数据库自增ID可以很好地保证ID的唯一性,但在高并发和大规模的分布式系统中,容易出现瓶颈和性能问题。同时,由于数据库自增ID只能在单个数据库中保证唯一性,因此需要通过分库分表等方式来支持多台机器上的生成。
简言之:
简单方便,有序递增,方便排序和分页
并发性能不高,受限于数据库性能
分库分表,需改造,较复杂
自增数据量泄露
数据库号段模式
数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,数据库压力大。因此,可以批量获取,然后存在内存里面,需要用到的时候,直接从内存里面拿来使用
主键自增
1,2,3......
号段模式:每请求一次分配一个号段
100,200,300
1...100,101...200,201...300
号段模式相比主键自增而言: 性能提高且自增
Redis自增
Redis 可以通过自增命令来实现分布式 ID 的生成。常用的方法是使用 Redis 的自增命令 INCR,将一个特定的 key 自增,并将其作为 ID 返回。这种方法是线程安全的,可以在分布式系统中使用
即使有AOF和RDB,但是依然会存在数据丢失的可能,有可能会造成ID重复
性能不错并且生成的 ID 是有序递增的,但是自增存在数据量泄露
MongoDB
MongoDB ObjectId是MongoDB数据库中的一个内置数据类型,用于唯一标识MongoDB文档(Document)。
它由12个字节组成,其中前4个字节表示时间戳,接下来3个字节表示机器ID,然后2个字节表示进程ID,最后3个字节表示随机值。
优缺点:
生成的 ID 是有序递增的
当机器时间不对的情况下,可能导致会产生重复 ID
ID生成有规律性,存在安全性问题
分布式ID方案之算法
UUID
UUID是一种通用唯一识别码,它是由一组算法和标准组成的,可以保证在全球范围内唯一性。UUID不依赖于任何中心节点,可以在分布式系统中很好地保证ID的唯一性。缺点是它生成的ID比较长,不利于索引和查询
开放软件基金会(OSF)规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。利用这些元素来生成UUID。
优缺点:
通过本地生成,没有经过网络I/O,性能较快
无序,无法预测他的生成顺序
存储消耗空间大(32 个字符串,128 位)
不能生成递增有序的数字
当机器时间不对的情况下,可能导致会产生重复 ID
Snowflake(雪花算法)
雪花算法是 Twitter 提出的一种分布式ID生成算法。雪花算法可以在多台机器上生成不重复的ID,支持高并发和大规模的分布式系统,但需要保证数据中心ID和机器ID的唯一性。
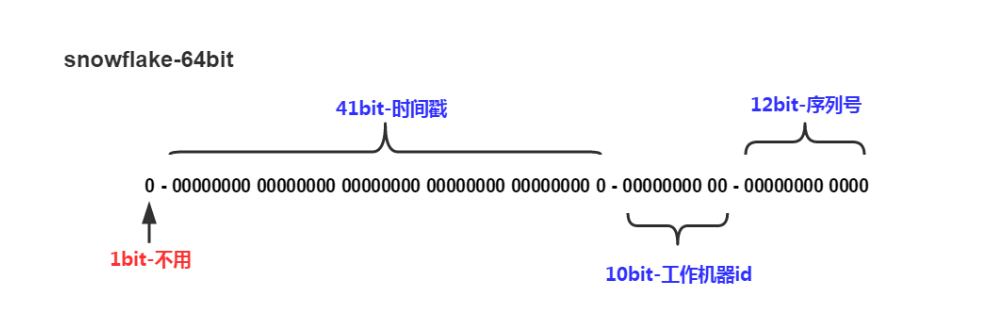
它的原理是将一个64位的long类型的ID分为4个部分:时间戳、数据中心ID、机器ID和序列号。
时间戳占用了42位,可以使用69年,数据中心ID和机器ID分别占用了5位,可以支持32个数据中心和32个机器,序列号占用了12位,可以支持每个节点每毫秒生成4096个ID。
细一点说:生成的64位ID可以分成5个部分:
1位符号位标识 - 41位时间戳 - 5位数据中心标识 - 5位机器标识 - 12位序列号
时间范围
2^41/(365*24*60*60*1000)=69年
工作进程数量
5+5 :区域+服务器标识
2^10=1024
序列号数量
2^12=4096
| 分段 | 作用 | 说明 |
|---|---|---|
| 1bit | 保留不用 | long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1 |
| 41bit | 时间戳,精确到毫秒 | 存储的是时间截的差值(当前时间截 - 开始时间截),结果约等于69.73年 |
| 5bit | 数据中心 | 最多支持2的5次方(32)个节点 |
| 5bit | 机器id | 最多支持2的5次方(32)个节点 |
| 12bit | 毫秒内的计数器 | 每个节点每毫秒最多产生2的12次方(4096)个id |
默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1024台机器,序列号支持1毫秒产生4096个自增序列id 。SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右
优缺点:
生成速度比较快、生成的 ID 有序递增、比较灵活
依赖时间,当机器时间不对的情况下,可能导致会产生重复 ID
雪花算法的使用
IdWorker工具类
/**
* Twitter的Snowflake JAVA实现方案
* 分布式自增长ID
*/
public class IdWorker {
// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
private final static long twepoch = 1288834974657L;
// 机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public IdWorker() {
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId 工作机器ID
* @param datacenterId 序列号
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* <p>
* 获取 maxWorkerId
* </p>
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* <p>
* 数据标识id部分
* </p>
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
public static void main(String[] args) {
IdWorker idWorker = new IdWorker(0, 0);
for (int i = 0; i < 10000; i++) {
long nextId = idWorker.nextId();
System.out.println(nextId);
}
}
}
配置分布式ID生成器
application.ym添加配置
workerId: 0
datacenterId: 0
IdWorker添加到容器
@Value("${workerId}")
private Integer workerId;
@Value("${datacenterId}")
private Integer datacenterId;
@Bean
public IdWorker idWorker(){
return new IdWorker(workerId,datacenterId);
}
分布式ID方案之开源组件
uid- generator(百度)
UidGenerator是百度开源的一款基于 Snowflake的唯一 ID 生成器,是对 Snowflake进行了改进
GitHub:https://github.com/baidu/uid-generator

Tinyid(滴滴)
Tinyid是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
GitHub: https://github.com/didi/tinyid

Leaf(美团)
Leaf是美团开源的一个分布式 ID 解决方案。提供了号段模式 和 Snowflake这两种模式来生成分布式 ID。
目前Leaf覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM基础上,通过公司RPC方式调用,QPS压测结果近5w/s,TP999 1ms。
Leaf 设计文档: https://tech.meituan.com/2017/04/21/mt-leaf.html
GitHub:https://github.com/meituan-diaNPing/leaf
三者比较
百度:只支持雪花算法
滴滴:只支持数据库号段,多DB,高可用,java- client,适合对id有高可用需求
美团:号段模式和 snowflake模,适合多种场景分布式id
Leaf组件的使用
源码打包
git clone git@github.com:Meituan-Dianping/Leaf.git
cd Leaf
git checkout feature/spring-boot-starter
mvn clean install -Dmaven.test.skip=true
引入依赖
目前Leaf最新使用2.0.1.RELEASE的starter版本
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.1.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--引入源码编译打包安装到本地的Leaf-->
<dependency>
<artifactId>leaf-boot-starter</artifactId>
<groupId>com.sankuai.inf.leaf</groupId>
<version>1.0.1-RELEASE</version>
</dependency>
<!--zk-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.6.0</version>
<exclusions>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
Leaf配置参数
Leaf 提供两种生成的ID的方式(号段模式和snowflake模式),可以同时开启两种方式,也可以指定开启某种方式(默认两种方式为关闭状态)。
| 配置项 | 含义 | 默认值 |
|---|---|---|
| leaf.name | leaf | 服务名 |
| leaf.segment.enable | 是否开启号段模式 | false |
| leaf.jdbc.url | mysql 库地址 | |
| leaf.jdbc.username | mysql 用户名 | |
| leaf.jdbc.password | mysql 密码 | |
| leaf.snowflake.enable | 是否开启snowflake模式 | false |
| leaf.snowflake.zk.address | snowflake模式下的zk地址 | |
| leaf.snowflake.port | snowflake模式下的服务注册端口 |
号段模式配置
如果使用号段模式,需要建立DB表,并配置leaf.jdbc.url, leaf.jdbc.username, leaf.jdbc.password
如果不想使用该模式配置leaf.segment.enable=false即可。
CREATE DATABASE leaf
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
在classpath下配置leaf.properties
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=true
leaf.segment.url=jdbc:mysql://127.0.0.1:3306/leaf
leaf.segment.username=root
leaf.segment.password=123456
Snowflake模式配置
算法取自twitter开源的snowflake算法。如果不想使用该模式配置leaf.snowflake.enable=false即可。
在classpath下配置leaf.properties
在leaf.properties中配置leaf.snowflake.zk.address,配置leaf 服务监听的端口leaf.snowflake.port。
leaf.snowflake.enable=true
leaf.snowflake.address=127.0.0.1
leaf.snowflake.port=2181
注解启动leaf
使用@EnableLeafServer注解启动leaf
@SpringBootApplication
@EnableLeafServer
public class DistributedIdApplication {
public static void main(String[] args) {
SpringApplication.run(DistributedIdApplication.class, args);
}
}
API的使用
@RestController
public class IdContoller {
@Autowired
private SegmentService segmentService;
@Autowired
private SnowflakeService snowflakeService;
@GetMapping("/segment")
public Result segment() {
// segmentService.getId("leaf-segment-test").getId();
return segmentService.getId("leaf-segment-test");
}
@GetMapping("/snowflake")
public Result snowflake() {
// 参数key无实际意义,受迫于统一接口的实现
return snowflakeService.getId("snowflake");
}
}
参数key无实际意义,受迫于统一接口的实现
public interface IDGen {
Result get(String var1);
boolean init();
}
public Result getId(String key) {
return this.idGen.get(key);
}
号段模式中该参数key有着重要意义

号段模式测试
数据库表初始时

访问地址:http://localhost:8080/segment

请求获取id值后,号段模式提前加载

重启服务后再次访问,使用新的号段

号段模式再一次提前加载

雪花算法测试
访问地址:http://localhost:8080/snowflake