目录
chunker
header
index_col
names
Series与DataFrame的区别
df.columns
del和drop的区别
reset_index
loc与iloc的区别
不同的排序方式
sort_values
sort_index
DataFrame相加
describe函数查看数据基本信息
查看多个列的数据时使用列表
处理缺失值的几种思路
dropna
fillna
去重手段
分箱-连续数值离散化
value_counts
unique
nunique
类别文本转换为数值
方法一
方法二
方法三-使用使用sklearn.preprocessing的LabelEncoder
编辑
replace
map
LabelEncoder
将类别文本转换为one-hot编码
get_dummies
concat
从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
chunker
"chunker"是一个可迭代的对象,每次迭代返回文件中的下一个数据块。这种方法可以让你逐块地处理大型文件,而不必一次将其全部加载到内存中。
for chunk in chunker:
print(chunk)
header
在pandas中使用read_csv函数时,header参数用于指定文件中哪一行作为列名。如果设置header=0,则表示文件的第一行(索引为0的行)应被用作列名。这是read_csv的默认行为。
index_col
index_col参数在pandas的read_csv函数中用于指定用作行索引的列。这允许你将CSV文件的一列或多列设置为DataFrame的索引。
- 如果设置为整数,例如
index_col=0,则CSV文件的第一列(索引为0的列)将用作索引。 - 如果设置为字符串,例如
index_col='乘客ID',则CSV文件中名为'乘客ID'的列将用作索引。 - 如果不设置
index_col或设置为None,则DataFrame将使用默认的整数索引。
names
使用names参数在读取CSV文件时定义列名要注意以下几点:
-
长度匹配:
names列表的长度应与CSV文件中的列数相匹配。如果不匹配,可能会导致错误或不可预期的结果。 -
与
header参数的配合:- 如果CSV文件的第一行包含列名,并且你想用
names替换它们,则应将header设置为0,以便跳过文件中的第一行。 - 如果CSV文件没有列名行,则应设置
header=None。
- 如果CSV文件的第一行包含列名,并且你想用
-
重复列名:确保
names列表中没有重复的列名,否则可能会导致混淆和错误。 -
与
index_col的配合:如果你还使用了index_col参数,确保index_col中指定的索引列在names列表中存在。 -
字符编码:如果列名包括非ASCII字符(例如中文字符),请确保CSV文件的编码与读取文件时使用的编码相匹配。
-
数据类型:
names参数接受的是字符串列表。尽量不要在其中混合不同的数据类型。 -
特殊字符:避免在列名中使用可能与CSV格式冲突的特殊字符,例如逗号或引号。
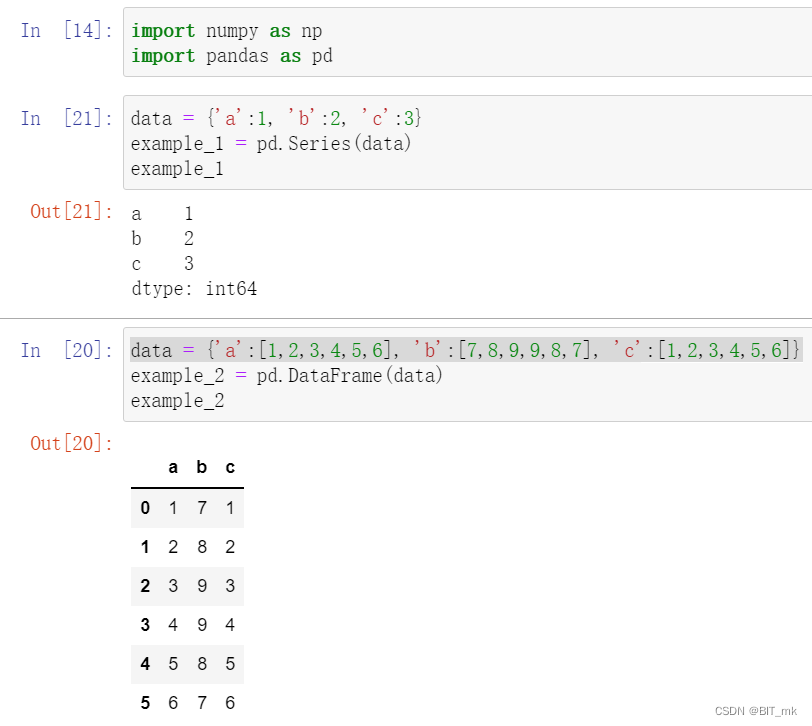
data = {'a':1, 'b':2, 'c':3}
data = {'a':[1,2,3,4,5,6], 'b':[7,8,9,9,8,7], 'c':[1,2,3,4,5,6]}都是创建了字典,只不过第二个里面的值为列表。
Series与DataFrame的区别
df.columns
在编程和数据分析上下文中,columns一词通常与数据框架(如pandas DataFrame)有关。columns可以用于多种目的:
获取列名:在pandas DataFrame中,columns属性用于获取DataFrame的列名
import pandas as pd
df = pd.DataFrame({'a': [1, 2], 'b': [3, 4]})
print(df.columns) # 输出:Index(['a', 'b'], dtype='object')
重命名列:你可以通过赋值来更改列名
df.columns = ['new_a', 'new_b']
选择特定列:在一些函数中,columns参数允许你选择要操作的特定列。例如,你可以在pd.read_csv中使用usecols参数来选择要读取的列。
创建DataFrame:在创建新的pandas DataFrame时,你可以使用columns参数来指定列的顺序和名称。
df = pd.DataFrame(data=[[1, 2], [3, 4]], columns=['a', 'b'])
del和drop的区别
drop和del在Python的pandas库中用于从DataFrame中删除列,但它们的使用方式和一些行为有所不同:
-
drop方法:drop是pandas DataFrame的一个方法,可以用于删除指定的行或列。- 通过设置
axis参数,可以控制是删除行还是列(axis=0表示删除行,axis=1表示删除列)。 drop默认返回一个新的DataFrame,不会更改原始DataFrame,除非设置inplace=True。- 可以同时删除多个列或行。
df = df.drop(['col1', 'col2'], axis=1) # 删除列并返回新的DataFrame -
del语句:del是Python的内置语句,用于删除对象或对象的部分(例如列表或字典中的元素)。- 在pandas中,可以使用
del直接删除DataFrame的某一列。 del直接更改原始DataFrame,不返回新的DataFrame。- 一次只能删除一列。
del df['col1'] # 直接从df中删除列
- 如果你想要直接更改原始DataFrame并删除单个列,可以使用
del。 - 如果你想要更灵活地删除多个列或行,并有可能保留原始DataFrame不变,则可以使用
drop方法。

reset_index
pandas库中的reset_index方法用来重置DataFrame midage的索引。
具体来说:
- 调用
reset_index()会重新设置索引为默认的整数索引(0, 1, 2, ...),并将原来的索引列添加为一个新的列。 - 通过设置参数
drop=True,原来的索引列不会被添加为新列,而是会被完全丢弃。
loc与iloc的区别

loc:
- 基于标签的索引:使用
loc时,你必须传入行或列的实际标签名称。 - 可以使用标签名称切片,切片的结束点是包含的。
- 支持布尔索引。
iloc:
- 基于整数位置的索引:与
loc不同,iloc使用整数索引来选择行和列,这些整数代表行和列的位置。 - 使用整数进行切片时,切片的结束点是不包含的。
- 不支持布尔索引。
不同的排序方式
sort_values
sort_values是pandas库中DataFrame的一个方法,用于根据一个或多个列的值对DataFrame进行排序。以下是一些常见的用法:
-
按单列排序:
sorted_df = df.sort_values(by='column_name') -
按多列排序:
sorted_df = df.sort_values(by=['column1', 'column2']) -
选择升序或降序排序:
sorted_df = df.sort_values(by='column_name', ascending=False) # 降序 -
在排序后重置索引:
sorted_df = df.sort_values(by='column_name').reset_index(drop=True) -
按列中的特定位置排序(例如,如果列包含列表或其他可迭代对象):
sorted_df = df.sort_values(by='column_name', key=lambda x: x.str[0])
sort_values方法返回一个新的DataFrame,其中的行按指定列的值排序。如果想在原地修改DataFrame,可以使用inplace=True参数。
sort_index
sort_index是pandas库中DataFrame和Series的一个方法,用于根据索引标签对数据结构进行排序。以下是一些常见的用法:
-
按索引排序:
sorted_df = df.sort_index() -
选择升序或降序排序:
sorted_df = df.sort_index(ascending=False) # 降序 -
对多级索引进行排序:
sorted_df = df.sort_index(level='index_level_name') # 在具有多级索引的情况下,通过级别进行排序 -
对特定轴进行排序:
sorted_df = df.sort_index(axis=1) # 对列进行排序
sort_index方法返回一个新的DataFrame或Series,其中的行或列按索引标签排序。如果想在原地修改DataFrame或Series,可以使用inplace=True参数。
注意sort_index不能按照多列进行排序
DataFrame相加

两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN。
describe函数查看数据基本信息
count : 样本数据大小
mean : 样本数据的平均值
std : 样本数据的标准差
min : 样本数据的最小值
25% : 样本数据25%的时候的值
50% : 样本数据50%的时候的值
75% : 样本数据75%的时候的值
max : 样本数据的最大值

查看多个列的数据时使用列表

处理缺失值的几种思路
df[df['Age']==None]=0
df[df['Age']==np.nan]=0
df[df['Age'].isnull()]=0数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到,比较的时候最好用np.nan
dropna
dropna是pandas库中的一个方法,用于从DataFrame或Series中删除缺失值(NA或NaN)。以下是一些常见的用法:
-
删除任何包含缺失值的行:
df.dropna() -
删除任何包含缺失值的列:
df.dropna(axis=1) -
删除特定列中有缺失值的行:
df.dropna(subset=['column_name']) -
保留至少有N个非NA值的行:
df.dropna(thresh=N) -
原地删除缺失值(不返回新的DataFrame,而是修改原始DataFrame):
df.dropna(inplace=True)
dropna方法返回一个新的DataFrame或Series,在其中删除了包含缺失值的行或列。如果你想在原地修改数据结构,可以使用inplace=True参数。
fillna
fillna是pandas中的一个方法,用于填充DataFrame或Series中的缺失值(NA或NaN)。以下是一些常见的用法:
-
用特定值填充所有缺失值:
df.fillna(value=5) -
用前一个值填充缺失值(向前填充):
df.fillna(method='ffill') -
用后一个值填充缺失值(向后填充):
df.fillna(method='bfill') -
对不同的列使用不同的填充值:
df.fillna({'column1': value1, 'column2': value2}) -
用特定列或行的平均值填充缺失值:
df.fillna(df.mean()) -
原地填充缺失值(不返回新的DataFrame,而是修改原始DataFrame):
df.fillna(value=5, inplace=True) -
限制连续填充的数量:
df.fillna(value=5, limit=2)
fillna方法返回一个新的DataFrame或Series,在其中用指定的值或方法填充了缺失值。如果想在原地修改数据结构,可以使用inplace=True参数。
去重手段
在pandas中,与重复相关的主要方法是duplicated()和drop_duplicates()。
-
duplicated()方法:这个方法返回一个布尔系列,表示每一行是否是重复行。可以根据所有列或指定的列来判断。示例:查找所有重复的行
duplicates = df.duplicated()示例:根据特定列查找重复的行
duplicates = df.duplicated(subset=['column1', 'column2']) -
drop_duplicates()方法:这个方法返回一个新的DataFrame,在其中删除了重复的行。与duplicated()一样,可以根据所有列或指定的列来判断。示例:删除所有重复的行
df_no_duplicates = df.drop_duplicates()示例:根据特定列删除重复的行
df_no_duplicates = df.drop_duplicates(subset=['column1', 'column2']) -
原地删除重复的行:
df.drop_duplicates(inplace=True)
通过这些方法,你可以检测和处理DataFrame中的重复行。
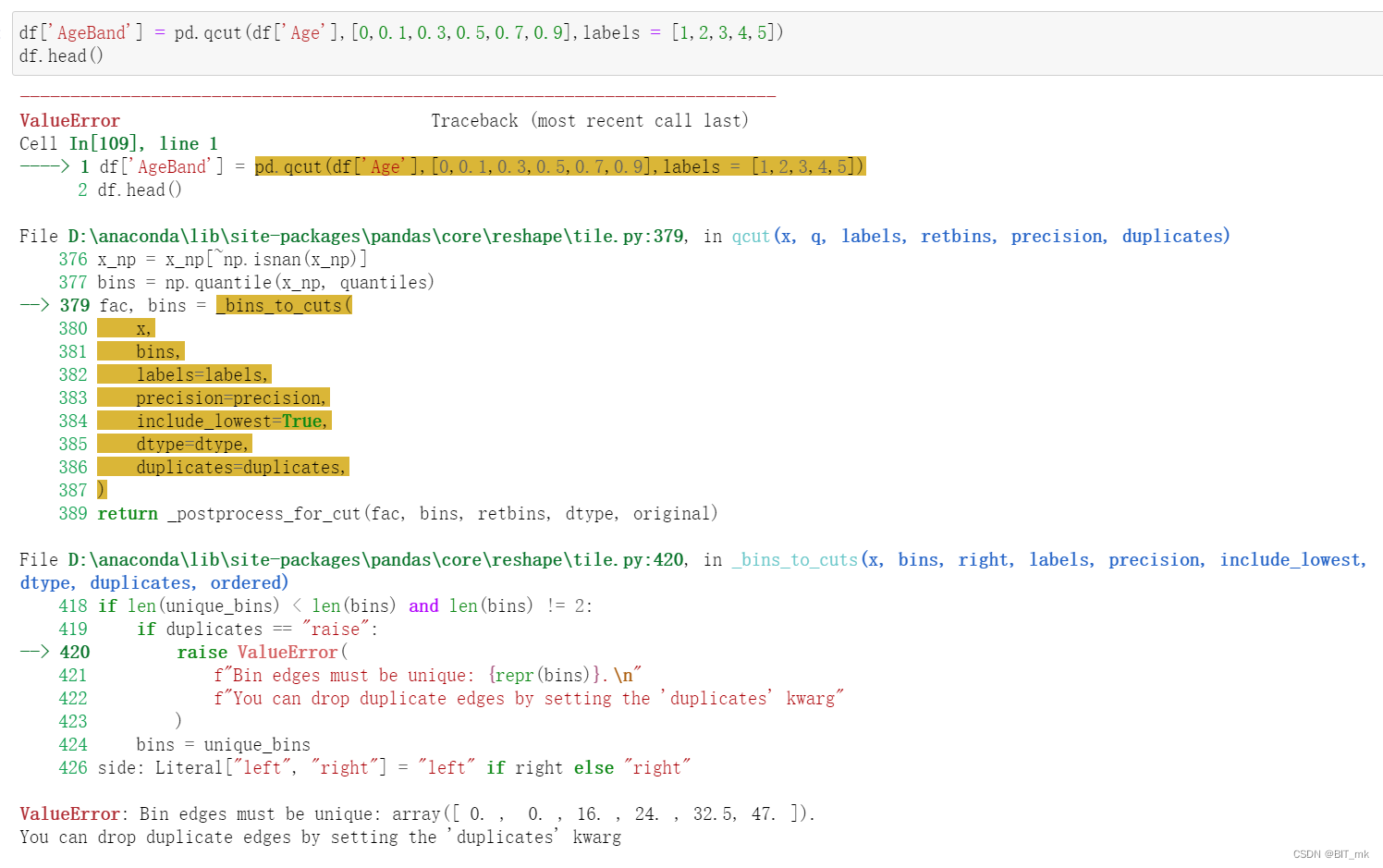
分箱-连续数值离散化
分箱(Binning)是一种数据预处理技术,用于将连续的数值数据转换为离散的区间或“箱”。这在数据分析中是有用的,因为它可以简化数据,并帮助识别模式和趋势。在pandas中,你可以使用pd.cut()或pd.qcut()方法进行分箱。
-
pd.cut()方法:使用指定的边界值将数据分割成不同的箱。示例:将年龄分成三个箱
bins = [0, 18, 35, 100] labels = ['Youth', 'Adult', 'Senior'] df['age_bin'] = pd.cut(df['age'], bins=bins, labels=labels) -
pd.qcut()方法:根据数据的分位数将数据分割成不同的箱,以便每个箱中的数据数量大致相同。示例:将年龄分成四个等量的箱
df['age_bin'] = pd.qcut(df['age'], q=4)
这些方法都会返回一个分类对象,可以作为新的DataFrame列添加,从而允许你根据分箱结果进行进一步的分析或可视化。

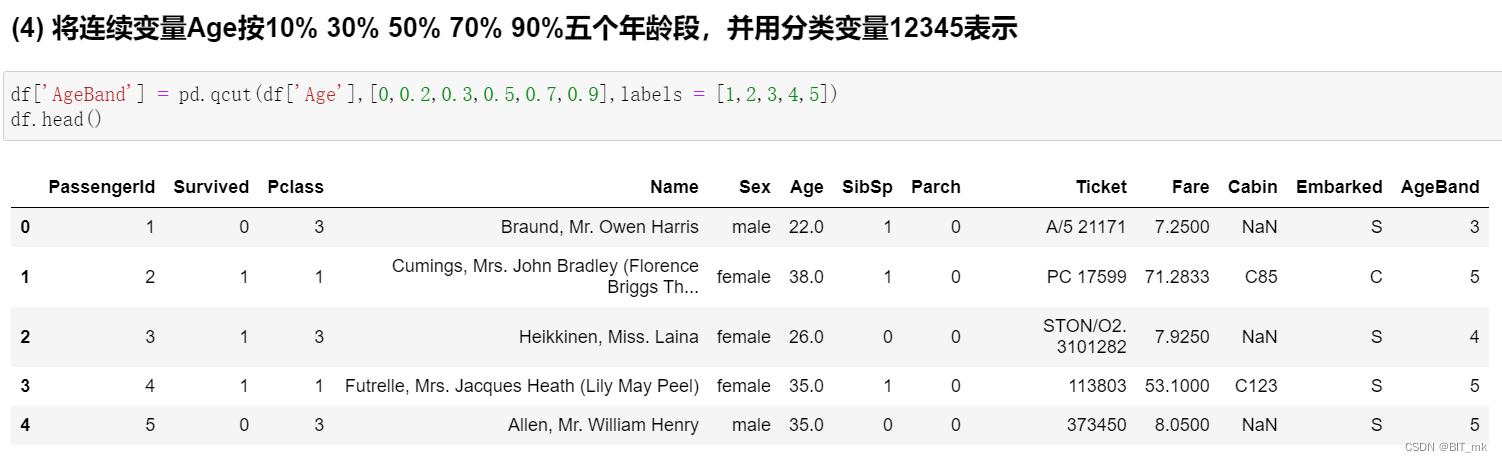 注意有可能不同的分位数计算出的边界由于精度的问题可能会相同进而产生报错!
注意有可能不同的分位数计算出的边界由于精度的问题可能会相同进而产生报错!
value_counts
value_counts是Pandas库中的一个方法,用于计算一个序列中各个唯一值的出现次数。这在统计分类数据的频率时非常有用。
以下是一个例子,说明如何使用value_counts来计算DataFrame中某一列的值的频率:
import pandas as pd
# 创建一个示例
DataFrame df = pd.DataFrame({ 'fruits': ['apple', 'banana', 'apple', 'orange', 'banana', 'apple'] })
# 使用value_counts计算'fruits'列中各个水果的出现次数
fruit_counts = df['fruits'].value_counts()
# 输出结果
print(fruit_counts)输出将是:
apple 3
banana 2
orange 1value_counts方法会按频率降序排列结果,所以最常见的值会排在最前面。如果你想要得到升序结果,可以使用sort和ascending参数,例如:
fruit_counts = df['fruits'].value_counts(sort=True, ascending=True)unique
unique() 是 pandas 库中的一个方法,用于查找 Series 或 DataFrame 中的唯一值。对于一个特定的列或序列,你可以使用 unique() 来获得所有不重复的值。

nunique
nunique() 方法在 pandas 中用于返回 DataFrame 或 Series 中的唯一值数量。这是计算有多少不同的值存在于特定列或整个 DataFrame 中的一种便捷方法。

注意,nunique() 默认会排除 NaN 值。如果你也想计算 NaN 值,可以使用参数 dropna=False,例如:
number_of_unique_fruits_including_nan = df['fruits'].nunique(dropna=False)
类别文本转换为数值
方法一
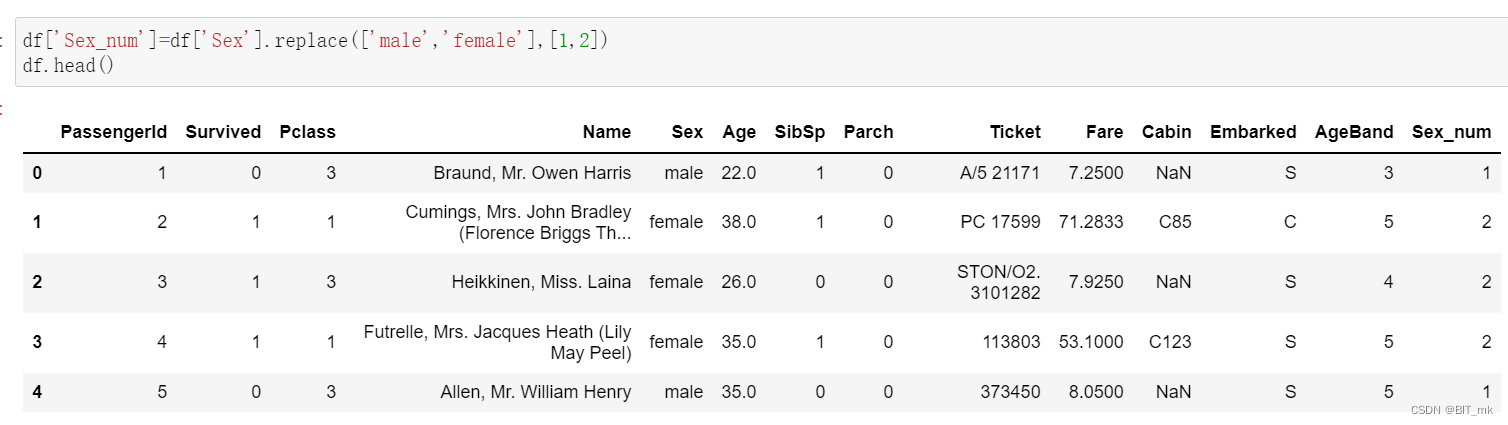
方法二

方法三-使用使用sklearn.preprocessing的LabelEncoder
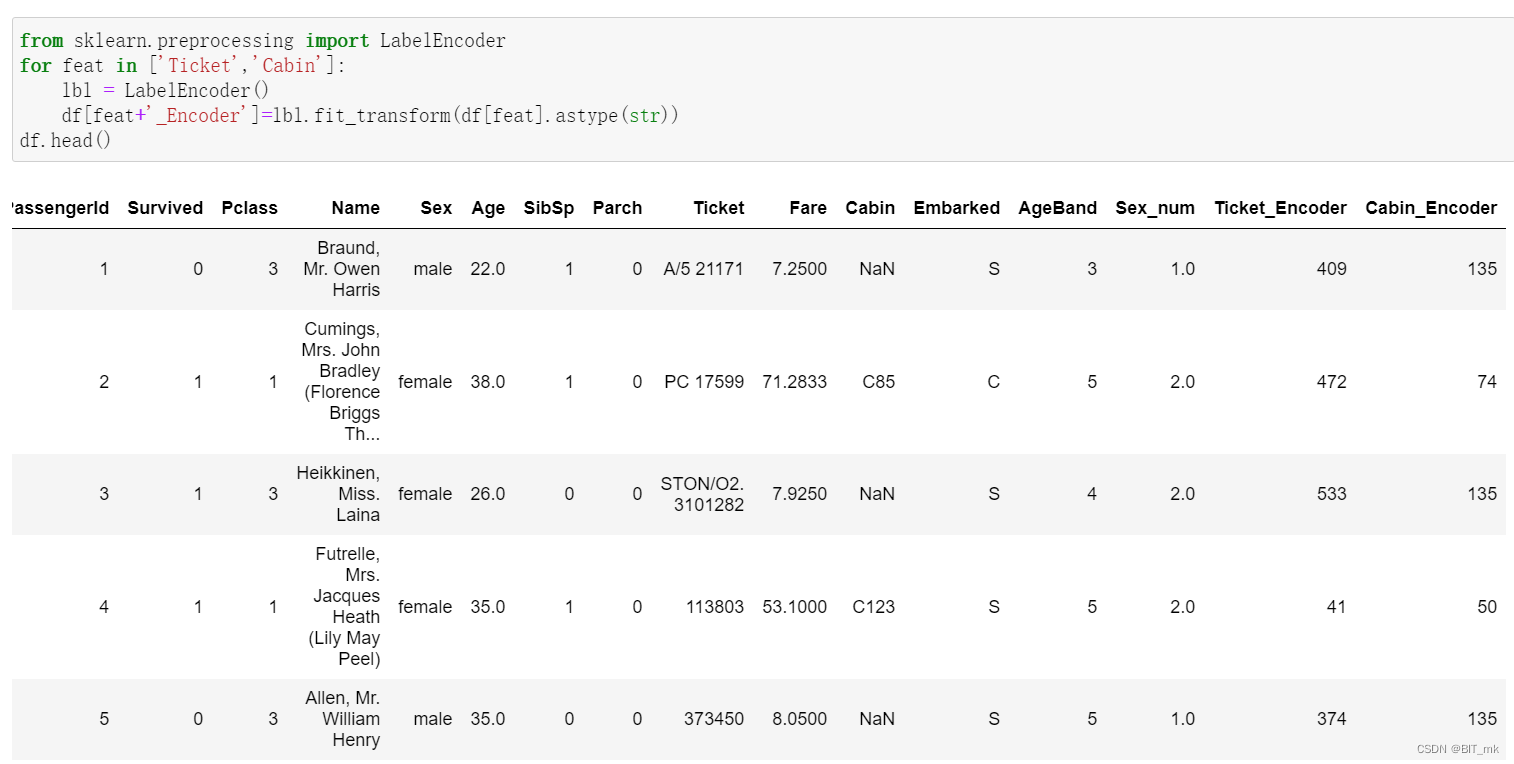
from sklearn.preprocessing import LabelEncoder
for feat in ['Ticket','Cabin']:
lbl = LabelEncoder()
df[feat+'_Encoder']=lbl.fit_transform(df[feat].astype(str))
df.head()代码中使用astype(str)的原因:
-
处理非字符串数据:
feat列可能包含不同的数据类型(例如数字、NaN 或其他对象)。将其转换为字符串类型可以确保LabelEncoder能够正确处理。 -
处理缺失值:如果
feat列中存在 NaN 或其他缺失值,直接将其传递给LabelEncoder可能会导致错误。通过使用.astype(str),可以将缺失值转换为字符串表示,例如"nan",从而可以进行编码。 -
一致的编码:确保所有的输入值都是字符串类型,可以确保
LabelEncoder对整个列执行一致的编码。
replace
replace() 方法在 pandas 中用于替换 DataFrame 或 Series 中的值。你可以使用它来替换一个或多个特定的值,或者基于某些逻辑来替换值。
以下是一些使用 replace() 的例子:
-
替换特定值:
df['column_name'] = df['column_name'].replace(5, 'five')这将在
'column_name'列中将所有值为 5 的项替换为 'five'。 -
替换多个特定值:
df['column_name'] = df['column_name'].replace([1, 2, 3], ['one', 'two', 'three'])这将在
'column_name'列中分别将 1、2 和 3 替换为 'one'、'two' 和 'three'。 -
使用字典替换值:
replacements = {1: 'one', 2: 'two', 3: 'three'} df['column_name'] = df['column_name'].replace(replacements)这将在
'column_name'列中使用字典中的映射替换值。 -
在整个 DataFrame 中替换值:
df = df.replace(0, 'zero')这将在整个 DataFrame 中将所有值为 0 的项替换为 'zero'。
map
map() 是 pandas 的一个 Series 方法,用于将指定的函数或字典应用于整个 Series。这个方法对于元素级的转换非常有用,可以基于某个映射关系更改值。
以下是一些使用 map() 方法的例子:
-
使用函数进行映射:
def square(x): return x**2 df['squared_values'] = df['original_values'].map(square)这将计算
'original_values'列中每个值的平方,并将结果存储在新的'squared_values'列中。 -
使用 lambda 函数:
df['squared_values'] = df['original_values'].map(lambda x: x**2) -
使用字典进行映射:
mappings = {1: 'one', 2: 'two', 3: 'three'} df['text_values'] = df['numeric_values'].map(mappings)这将在
'numeric_values'列中使用字典的映射关系替换值,将其存储在新的'text_values'列中。 -
用于替换缺失值:
df['values'] = df['values'].map({np.nan: 0})这将替换
'values'列中的所有 NaN 值为 0。
请注意,当使用字典进行映射时,不在字典中的值将被转换为 NaN。如果你希望保留原始值,可以考虑使用 replace() 方法。
LabelEncoder
LabelEncoder 是一个来自 Scikit-learn 库的工具,用于将类别标签转换为整数。这种转换通常用于处理分类问题,将文本或其他非数字标签转换为可以用于机器学习模型的数字形式。
以下是如何使用 LabelEncoder 的一个例子:
from sklearn.preprocessing import LabelEncoder
# 创建 LabelEncoder 对象
labelencoder = LabelEncoder()
# 模拟一些类别标签
labels = ['cat', 'dog', 'fish', 'cat', 'dog']
# 使用 LabelEncoder 对象拟合并转换标签
encoded_labels = labelencoder.fit_transform(labels)
# 结果是一个整数数组,每个元素对应于原始标签数组中的一个元素
print(encoded_labels)
# 输出可能是:[0 1 2 0 1]
# 可以使用 inverse_transform 方法将整数标签转换回原始标签
original_labels = labelencoder.inverse_transform(encoded_labels)
print(original_labels)
# 输出:['cat' 'dog' 'fish' 'cat' 'dog']请注意,LabelEncoder 的输出依赖于输入标签的字母顺序,所以同一组标签在不同的输入数组中可能会得到不同的编码。
将类别文本转换为one-hot编码
One-hot编码是一种表示分类变量的方法。通过将每个类别值转换为一个二进制向量来实现。向量中的每个元素对应于一个可能的类别,如果某个元素的值是该类别,则该元素为1,否则为0。
get_dummies
get_dummies是Pandas库中的一个函数,用于将分类变量转换为虚拟/指示变量,也称为One-hot编码。
该函数通过为每个唯一的分类值创建一个新的二进制列来工作。例如,如果你有一个包含“红色”、“蓝色”和“绿色”的颜色列,get_dummies会创建三列,对应于这三个颜色,如果颜色存在,则列中的值为1,否则为0。
如果你希望在原始DataFrame中保留转换后的列,可以如下所示:
df_with_dummies = pd.concat([df, dummies], axis=1)或者直接将整个DataFrame传递给get_dummies,指定要转换的列:
df_with_dummies = pd.get_dummies(df, columns=['color'])使用get_dummies可以方便地将分类特征转换为数值形式,从而使它们可以在许多机器学习算法中使用。
concat
concat是Pandas库中的函数,用于连接两个或多个pandas对象。你可以沿特定轴连接它们,通过逻辑连接它们的索引/轴来设置逻辑。
以下是一些使用concat的基本示例:
- 垂直连接(沿轴0):
import pandas as pd
df1 = pd.DataFrame({'A': ['A0', 'A1'], 'B': ['B0', 'B1']})
df2 = pd.DataFrame({'A': ['A2', 'A3'], 'B': ['B2', 'B3']})
result = pd.concat([df1, df2])结果将是:
A B
0 A0 B0
1 A1 B1
0 A2 B2
1 A3 B3注意索引没有重置。你可以通过添加参数ignore_index=True来重置索引。
- 水平连接(沿轴1):
result = pd.concat([df1, df2], axis=1)结果将是:
A B A B
0 A0 B0 A2 B2
1 A1 B1 A3 B3从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
df.Name.str.extract('([A-Za-z]+)\.',expand=False)-
df.Name:从DataFramedf中选择"Name"列。 -
str:使字符串方法可用于该列。 -
extract('([A-Za-z]+)\.',expand=False):使用正则表达式'([A-Za-z]+)\.'来提取每个元素中的匹配项。- 正则表达式
[A-Za-z]+匹配一个或多个字母。 \.匹配一个点字符。- 括号
()定义了一个捕获组,即我们想要提取的部分。
- 正则表达式
-
expand=False:这个参数指定返回一个Series,而不是DataFrame。
所以,如果"Name"列包含类似"Dr."、"Mr."、"Mrs."这样的称呼,这个代码将从每个名字中提取出这些称呼,不包括后面的点,返回一个包含这些称呼的Series。