目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- TensorFlow环境
- 方法一
- 方法二
- 模块实现
- 1. 数据预处理
- 1)导入数据
- 2)数据清洗
- 3)统计词频
- 2. 词云构建
- 3. 关键词提取
- 4. 语音播报
- 5. LDA主题模型
- 6. 模型构建
- 系统测试
- 工程源代码下载
- 其它资料下载

前言
本项目运用了TF-IDF关键词提取技术,结合词云数据可视化、LDA (Latent Dirichlet Allocation)模型训练以及语音转换系统,来实现一个基于TensorFlow的文本摘要程序。
首先,我们利用TF-IDF(Term Frequency-Inverse Document Frequency)技术来提取文本中的关键词。这有助于找出文本中最具代表性的词汇,为后续的摘要提取提供了重要的信息。
其次,我们运用词云数据可视化技术,将关键词以视觉化的方式展示出来。这能够帮助用户直观地理解文本的重点和关注点。
接下来,我们使用LDA模型进行训练,这是一种用于主题建模的技术。通过LDA模型,我们能够发现文本中隐藏的主题结构,从而更好地理解文本内容的分布和关联。
最后,我们将这些技术结合在一起,创建了一个基于TensorFlow的文本摘要程序。这个程序可以自动提取文本的关键信息、主题结构,并生成简明扼要的文本摘要。
另外,我们还融合了语音转换系统,使得生成的文本摘要能够通过语音方式呈现,提升了用户的体验和使用便捷性。
通过这个项目,我们能够将多种技术融合在一起,实现一个功能强大的文本摘要程序,为用户提供更便捷、直观的文本理解和获取体验。
总体设计
本部分包括系统整体结构图和系统流程图。
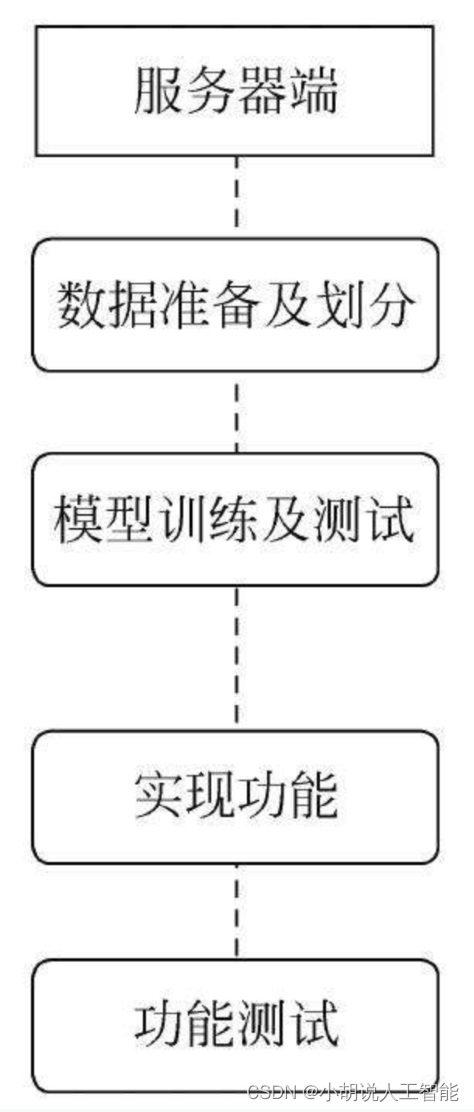
系统整体结构图
系统整体结构如图所示。
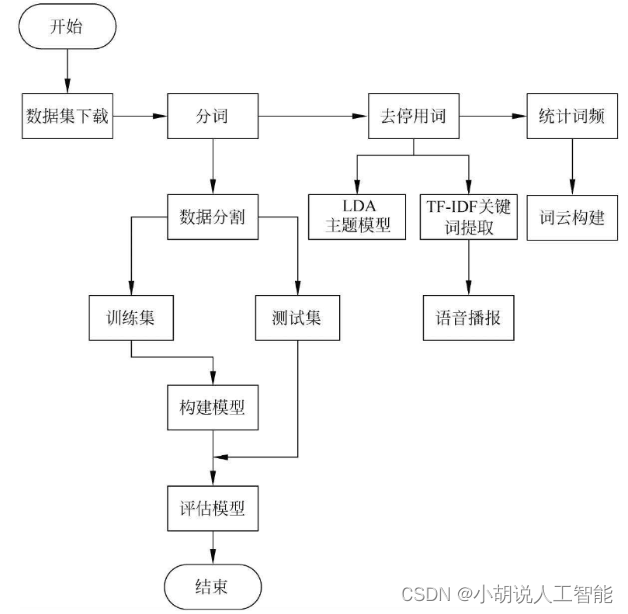
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境和TensorFlow环境。
Python 环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成对Python环境的配置,下载地址为https://www.anaconda.com/。也可下载虚拟机在Linux环境下运行代码。
TensorFlow环境
安装方法如下:
方法一
打开Anaconda Prompt,输入清华仓库镜像。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config -set show_channel_urls yes
创建Python 3.6的环境,名称为TensorFlow,此时Python版本和后面TensorFlow的版本有匹配问题,此步选择Python 3.x。
conda create -n tensorflow python=3.6
有需要确认的地方,都输入y。在Anaconda Prompt中激活TensorFlow环境:
conda activate tensorflow
安装CPU版本的TensorFlow:
pip install -upgrade --ignore -installed tensorflow
测试代码如下:
import tensorflow as tf
hello = tf.constant( 'Hello, TensorFlow! ')
sess = tf.Session()
print sess.run(hello)
# 输出 b'Hello! TensorFlow'
安装完毕。
方法二
打开Anaconda Navigator,进入Environments 单击Create,在弹出的对话框中输入TensorFlow,选择合适的Python版本,创建好TensorFlow环境,然后进入TensorFlow环境,单击Not installed在搜索框内寻找需要用到的包。例如,TensorFlow,在右下方选择apply,测试是否安装成功。在Jupyter Notebook编辑器中输入以下代码:
import tensorflow as tf
hello = tf.constant( 'Hello, TensorFlow! ')
sess = tf.Session()
print sess.run(hello)
# 输出 b'Hello! TensorFlow'
能够输出hello TensorFlow,说明安装成功。
模块实现
本项目包括6个模块:数据预处理、词云构建、关键词提取、语音播报、LDA主题模型、模型构建,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
在清华大学NLP实验室推出的中文文本数据集THUCNews中下载,下载地址为https://github.com/gaussic/text-classification-cnn-rnn。共包含5000条新闻文本,整合划分出10个候选分类类别:财经、房产、家居、教育、科技、时尚、时政、体育、游戏、娱乐。
1)导入数据
通过jupyter notebook来实现,相关代码如下:
#导入相应数据包
import pandas as pd
import numpy as np
#数据的读入及读出
df_news=pd.read_table("./cnews.val.txt",names=["category","content"])
df_news.head()
从文件夹读出相应的数据,分别表示新闻数据的类别及内容,如图所示。
#数据的类别及总量
df_news.category.unique()
df_news.content.shape
#为方便后续对数据的处理,将原始表格型据结构转换成列表格式
content_list=df_news.content.values.tolist()

数据类别处理代码编译成功,如图所示。

2)数据清洗
新闻文本数据中不仅包括了中文字符,还包括了数字、英文字符、标点等,分词是中文文本分析的重要内容,正确的分词可以更好地构建模型。中文语料中词与词之间是紧密相连的,这一点不同于英文或者其他语种的语料,因此,不能像英文使用空格分词,而是使用jieba库中的分割方法。
#jieba分词
content_fenci = [] #建立一个空的
for line in content_list:
text = jieba.lcut(line) #给每一条都分词
if len(text) > 1 and text != '\r': #换行
content_fenci.append(text) #将分词后的结果放入
#content_fenci[0] #分词后的一个样本
df_content=pd.DataFrame({'content':content_fenci})
df_content.head()
分词后结果如图所示。

#导入停用词
def drop_stopwords(contents,stopwords):
content_clean = [] #放清理后的分词
all_words = []
for line in contents:
line_clean=[]
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
content_clean.append(line_clean)
return content_clean,all_words
content_clean,all_words = drop_stopwords(content_fenci,stopwords_list,)
df_clean= pd.DataFrame({'contents_clean':content_clean})
df_clean.head()
清洗后结果如图所示。

3)统计词频
统计文本中每个单词出现的次数,对该统计按单词频次进行排序。如图所示。

相关代码如下:
tf= Counter(all_words)
2. 词云构建
词云是对文本中出现频率较高的关键词予以视觉化的展现,词云过滤掉大量低频低质的文本信息,使浏览者快速阅读文本就可领略文本的主旨。
#导入背景图片后的词云
mask = imread('4.png')#读入图片
wc=wordcloud.WordCloud(font_path=font,mask=mask,background_color='white',scale=2)
#scale:按照比例进行放大画布,如设置为2,则长和宽都是原来画布的2倍
wc.generate_from_frequencies(tf)
plt.imshow(wc) #显示词云
plt.axis('off') #关闭坐标轴
plt.show()
wc.to_file('ciyun.jpg') #保存词云
3. 关键词提取
TF-IDF是一种统计方法,字词的重要性随着它在文件中出现的次数成正比增加,但同时也会在语料库中出现的频率成反比下降,接下来通过TF-IDF算法的运用实现关键词提取。
import jieba.analyse
index = 2
#print(df_clean['contents_clean'][index])
#词之间相连
content_S_str = "".join(content_clean[index])
print(content_list[index])
print('关键词:')
print(" ".join(jieba.analyse.extract_tags(content_S_str, topK=10, withWeight=False)))
4. 语音播报
将上述提取成功的关键词通过pyttsx3转换成语音进行播报。
import pyttsx3
voice=pyttsx3.init()
voice.say(" ".join(jieba.analyse.extract_tags(content_S_str, topK=10, withWeight=False)))
print("准备语音播报.....")
voice.runAndWait()
5. LDA主题模型
LDA是一种文档主题生成模型,也称为三层贝叶斯概率模型,模型中包含词语(W)、主题(Z)和文档(theta)三层结构。文档到主题、主题到词服从多项式分布,得出每个主题都有哪些关键词组成。在实际运行中,因为单词数量多,而一篇文档的单词数是有限的,如果采用密集矩阵表示,会造成内存浪费,所以gensim内部是用稀疏矩阵的形式来表示。首先,将分词清洗后的文档,使用dictionary = corpora.Dictionary (texts) 生成词典;其次,将生成的词典转化成稀疏向量。
def create_LDA(content_clean):
#基于文本集建立(词典),并获得特征数
dictionary = corpora.Dictionary(content_clean)
#基于词典,将分词列表集转换成稀疏向量集,称作语料库
dic = len(dictionary.token2id)
print('词典特征数:%d' % dic)
corpus = [dictionary.doc2bow(sentence) for sentence in content_clean]
#模型训练
lda = gensim.models.LdaModel(corpus=corpus, id2word = dictionary,num_topics = 10,passes=10)
#passes 训练几轮
print(lda.print_topic(1,topn=5))
print('-----------')
for topic in lda.print_topics(num_topics=10, num_words = 5):
print(topic[1])
create_LDA(content_clean)
6. 模型构建
贝叶斯分类器的原理是通过某对象的先验概率,利用贝叶斯公式计算出后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为所属类。一个mapping对象将可哈希的值映射为任意对象,映射是可变对象。目前Python中只有一种标准映射类型一字典, 用花括号表示,但是花括号中的每个元素都是一个键值对(key: value),字典中的键值对也是无序的。
df_train=pd.DataFrame({"content":content_clean,"label":df_news['category']})
#为了方便计算,把对应的标签字符类型转换为数字
#映射类型(mapping)
#非空字典
label_mapping = {"体育": 0, "娱乐": 1, "家居": 2, "房产": 3, "教育":4, "时尚": 5,"时政": 6,"游戏": 7,"科技": 8,"财经": 9}
df_train['label'] = df_train['label'].map(label_mapping)
#df_train.head()
#将每个新闻信息转换成字符串形式,CountVectorizer和TfidfVectorizer的输入为字符串
def create_words(data):
words = []
for index in range(len(data)):
try:
words.append( ' '.join(data[index]))
except Exception:
print(index)
return words
#把数据分成测试集和训练集
x_train,x_test,y_train,y_test =train_test_split(df_train['content'].values,df_train['label'].values,random_state=0)
train_words = create_words(x_train)
test_words = create_words(x_test)
#模型训练
#第一种
#CountVectorizer属于常见的特征数值计算类,是一个文本特征提取方法
#对于每个训练文本,只考虑每种词汇在该训练文本中出现的频率
vec = CountVectorizer(analyzer = 'word',max_features=4000,lowercase=False)
vec.fit(train_words)
classifier = MultinomialNB()
classifier.fit(vec.transform(train_words),y_train)
print("模型准确率:",classifier.score(vec.transform(test_words), y_test))
#第二种,TfidfVectorizer除了考量某一词汇在当前训练文本中出现的频率之外
#关注包含这个词汇的其它训练文本数目的倒数,训练文本的数量越多特征化的方法就越有优势
vectorizer = TfidfVectorizer(analyzer='word',max_features = 40000,
lowercase=False)
vectorizer.fit(train_words)
classifier.fit(vectorizer.transform(train_words),y_train)
print("模型准确率为:",classifier.score(vectorizer.transform(test_words),
y_test))
系统测试
词云如图1所示,关键词提取如图2所示,LDA测试结果如图3所示,贝叶斯结果如图4所示。




工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
![P4381 [IOI2008] Island (求基环树直径)](https://img-blog.csdnimg.cn/9bad0e782a124e44921beff6fbc798b8.jpeg#pic_center)









![【LeetCode】数据结构题解(12)[用栈实现队列]](https://img-blog.csdnimg.cn/cd5db38a49474116b0b4f2c9246e5ada.png)