目录
- 前言
- 1. 简述
- 2. 环境配置
- 3. ggml核心概念
- 3.1 gguf
- 3.2 ggml_tensor
- 3.3 ggml_backend_buffer
- 3.4 ggml_context
- 3.5 backend
- 3.6 ggml_cgraph
- 3.7 ggml_gallocr
- 4. 推理流程整体梳理
- 4.1 时间初始化与参数设置
- 4.2 模型加载与词汇表构建
- 4.3 计算图与内存分配
- 4.4 文本预处理与推理过程
- 4.5 性能统计与资源释放
- 4.6 完整推理流程
- 结语
- 下载链接
- 参考
前言
学习 UP 主 比飞鸟贵重的多_HKL 的 GGML源码逐行调试 视频,记录下个人学习笔记,仅供自己参考😄
refer1:【大模型部署】GGML源码逐行调试
refer2:llama.cpp源码解读–ggml框架学习
refer3:https://github.com/ggml-org/ggml
refer4:https://chatgpt.com/
1. 简述
本来想直接上手学习 llama.cpp 的,但是在读源码时发现很多概念都没接触过,所以这里还是花一些时间从简单的 ggml 框架开始学习
ggml 是一个用 c/c++ 编写、专注于 transformer 架构模型推理的机器学习库,它和 pytorch、tensorflow 等机器学习库比较类似。github 地址是:https://github.com/ggml-org/ggml
关于 ggml 更多的介绍大家可以参考 Georgi Gerganov 在 hugging face 上发布的一篇文章:Introduction to ggml
2. 环境配置
ggml 本身没有什么依赖,并且它的 README 文档对其环境配置已经描述得很清楚了,需要注意的是 ggml 提供了很多案例,例如 sgemm、mnist、yolo、sam、gpt-2 等等,这里我们主要分析的案例是 gpt-2 的推理
下面我们来简单过下如何利用 ggml 推理 gpt-2
1. 代码克隆,指令如下:
git clone https://github.com/ggml-org/ggml
Note:大家也可以点击 here 下载博主准备好的源码(注意该代码下载于 2025/4/12 日,若后续有改动请参考最新)
2. 模型下载,指令如下:
cd ggml
bash examples/gpt-2/download-ggml-model.sh 117M
等待一段时间后,在 models/gpt-2-117M 文件夹下会保存 ggml-model.bin 的模型文件
Note:模型下载需要访问外网,大家也可以点击 here 下载博主准备好的模型
3. 代码编译,指令如下:
cd ggml
mkdir build && cd build
cmake ..
cmake --build . --config Release -j 8
4. 执行推理,指令如下:
cd ggml
./build/bin/gpt-2-backend -m models/gpt-2-117M/ggml-model.bin -p "This is an example"
这里我们指定了模型的路径,并且给出了我们的 prompt 提示词 "This is an example"
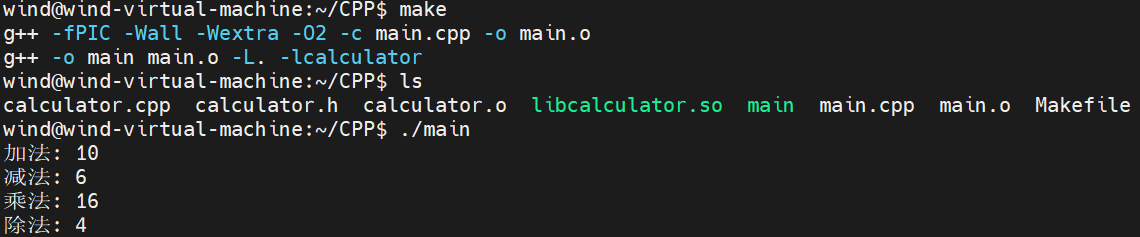
输出如下图所示:

从上图中可以看到,我们成功执行了推理,此外终端输出的并不只有模型推理的结果,还包括很多其他的东西,例如模型加载时的一些信息打印、推理的耗时打印等等
值得注意的是推理时默认使用的后端是 CPU 后端,如果大家有 GPU 可以选择 CUDA 后端,我们调试时也是以 CUDA 后端来分析的
下面我们就来看看如何使用 CUDA 后端推理,指令如下:
cd ggml
mkdir build && cd build
cmake -DGGML_CUDA=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda-11.8/bin/nvcc ..
cmake --build . --config Release -j 8
cd ..
./build/bin/gpt-2-backend -m models/gpt-2-117M/ggml-model.bin -p "This is an example" -ngl 12
Note:其中 -DCMAKE_CUDA_COMPILER 参数指定的 nvcc 路径需要替换为你自己电脑上的路径
如果需要支持 CUDA 后端也很容易,只需要在编译时将 -DGGML_CUDA 开启,同时指定下 nvcc 的路径即可。另外在推理时需要新增一个 -ngl 的参数,它代表的含义是 number of layers to offload to GPU on supported models,也就是将模型的多少个 layer 放到 GPU 上去推理,默认 0
值得注意的是如果不指定 -ngl 参数,即便你在编译时开启了 CUDA 后端支持,在执行时也是不会在 GPU 上推理,因为模型加载函数中有如下的代码:
#ifdef GGML_USE_CUDA
if (n_gpu_layers > 0) {
fprintf(stderr, "%s: using CUDA backend\n", __func__);
model.backend = ggml_backend_cuda_init(0);
if (!model.backend) {
fprintf(stderr, "%s: ggml_backend_cuda_init() failed\n", __func__);
}
}
#endif
我们可以从上述代码中发现,它通过宏定义 GGML_USE_CUDA 来判断是否使用 CUDA 后端来推理模型,此外只有当 n_gpu_layes 参数大于 0 时才会做 CUDA 后端的初始化,这里的 n_gpu_layes 变量就是我们上面提到的 -ngl 参数
CUDA 后端输出如下图所示:

CUDA 后端推理时在终端可以看到 GPU 设备的一些信息,另外可以看到每个 token 预测所使用的时间明显减少了
OK,以上就是利用 ggml 推理 gpt-2 时环境配置的整体流程了
既然要学习 ggml 的源码,肯定是需要 debug 逐行调试的,因此下面我们来配置下 debug 时的环境
Note:博主使用的是 vscode 编辑器,如果大家使用的是其它工具,可能需要自行配置
1. Debug 模式编译,指令如下:
cd ggml
mkdir build && cd build
cmake -DGGML_CUDA=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda-11.8/bin/nvcc -DCMAKE_BUILD_TYPE=Debug ..
cmake --build . -j 8
2. vscode 配置 c++ 的调试功能
主要是在 .vscode 文件夹下新建 tasks.json、launch.json 以及 c_cpp_properties.json 来进行调试,其中 c_cpp_properties.json 非必需,下面是它们的一些说明:
.vscode:它是一个隐藏文件夹,其主要作用是以 .json 的方式保存相关配置信息,如编译任务的配置、调试任务的配置、工作环境的配置等等tasks.json:用来配置编译文件的信息,用于生成可执行文件launch.json:用来配置调试文件的信息,比如指定调试语言环境、指定调试类型等等c_cpp_properties.json:配置 c/c++ 代码的智能提示,方便代码的书写
tasks.json 内容如下:
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks": [
{
"label": "build",
"type": "shell",
// for cmake
"command": "cd build && cmake --build . -j 8"
}
]
}
launch.json 内容如下:
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "(gdb) 启动",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/build/bin/gpt-2-backend",
"args": [
"-m", "models/gpt-2-117M/ggml-model.bin",
"-p", "This is an example",
"-ngl", "12"
],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "为 gdb 启用整齐打印",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
"preLaunchTask": "build"
}
]
}
c_cpp_properties.json 内容如下:
{
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/include/**",
"${workspaceFolder}/examples/**",
"${workspaceFolder}/src/**",
"/usr/local/cuda-11.8/include/**"
],
"defines": ["__CUDACC__", "HAS_PYTHON"],
"compilerPath": "/usr/bin/gcc",
"cStandard": "gnu11",
"cppStandard": "gnu++14",
"intelliSenseMode": "linux-gcc-x64",
"configurationProvider": "ms-vscode.makefile-tools",
"browse": {
"path": [
"${workspaceFolder}/include/**",
"${workspaceFolder}/examples/**",
"${workspaceFolder}/src/**",
"/usr/local/cuda-11.8/include/**"
],
"limitSymbolsToIncludedHeaders": false,
"databaseFilename": ""
}
}
],
"version": 4
}
Note:注意将 CUDA 头文件目录修改为你自己的路径
3. 打断点,进入调试
我们需要调试的文件是 main-backend.cpp,位于 examples/gpt-2 文件夹下,找到这个文件后在 main 函数中打一个断点,将上面的环境配置好后,按住 F5 即可进入调试,如下图所示:

接下来我们就可以愉快的调试代码了🤗
3. ggml核心概念
在分析调试代码之前,我们先来简单的梳理下 ggml 中的一些核心概念,博主本来是想放在代码中一边讲解一边梳理的,但是发现如果不事先了解下这些概念的话,在调试阅读源码时会比较困难
3.1 gguf
gguf 是一种文件格式,由 Georgi Gerganov 定义发布,用于存储使用 ggml 框架进行推理的模型文件。gguf 是一种二进制格式,旨在快速加载和保存模型。大部分模型是通过 pytorch 或者其他框架开发的,我们可以将它们转换成 gguf 格式并通过 ggml 框架推理
博主对于 ggml 框架中 LLM 的存储方式有些困惑,为什么不使用像 ONNX 这种能够直接查看计算图的存储格式,而是使用单独定义的 GGUF 格式呢?🤔
可能的原因有以下几点:(from ChatGPT)
1. 精细化的量化与推理优化
ggml 的设计初衷就是通过高效的量化和特殊的内存布局来实现本地 CPU/GPU 上的快速推理
- 常见的 ONNX 推理引擎也支持 FP16/INT8 等常用量化格式,但 ggml/llama.cpp 社区针对大模型场景做了许多的优化,例如 Q4_0、Q4_K、Q5_0、Q8_0 等更细粒度的专用量化方案
- ggml 在推理或加载时的某些操作不一定能直接在 ONNX 解析器中被高效地识别和执行。也就是说,如果使用 ONNX,仍然需要再去做针对性 “二次开发” 或适配,才能在内存带宽受限的环境中跑得足够快
2. 最小化对外部依赖和格式解析的需求
ONNX 文件的结构本身是基于 Protocol Buffers(protobuf),里面包含了大量描述算子的元数据、模型结构等,一个完整的 ONNX 模型包含算子定义(opset)、计算图、以及用于图推理的各种配置信息
- ggml/llama.cpp 这种使用场景往往是想把一切都打包到非常简洁的推理实现里,不依赖过多外部库,也不需要通用推理引擎去解析或执行复杂算子
- 只需要保留 “大语言模型的参数和最小必要的结构信息”,就可以完成推理,避免处理通用 ONNX 解析框架的开销和复杂度
3. 灵活的模型结构与定制的推理过程
大语言模型的推理过程是一个相对固定的 Transformer 堆叠(如解码器结构),而 ONNX 这种通用格式会把所有网络层、激活函数等一股脑儿封装在计算图中
- ggml/llama.cpp 以及衍生项目中,推理的具体步骤、batch 处理、KV Cache 等,往往都放在手写或者定制的 C/C++/Go/Python 逻辑里实现
- 由于模型结构和推理过程已经非常固定且可预测,所以常常不需要一个通用的 “模型结构描述 + 解析器” 来动态构建推理图。这时,存储权重时只要能快速映射到内存,按照适合的张量布局进行运算就足够了
4. 文件体积与加载速度
对大语言模型而言,模型文件本身动辄几十 GB。如果我们使用的是经过高度量化(如 Q4、Q5 等)的权重,加载时只需要非常小且固定的 “额外数据” 即可开始推理,减少了对复杂解析的依赖
- 在 ONNX 中,权重依旧要打包到同一个 protobuf 中,但如何高效地组织这些量化后的张量(并尽量减少不必要的结构信息)就相对繁琐
- GGUF 则是专为量化权重在本地高效加载而生,为此精心做了格式上的取舍、适配与优化
5. 更适合「社区量化版本」与开源生态
ggml/llama.cpp 以及对应的 GGUF 文件,能非常快速地衍生出社区版本:
- 比如将原始模型转换成多种量化精度版本,只需要在转换脚本中调用相关函数,就能快速把原始 FP32/FP16 权重转成 Q4、Q5、Q8 等多种量化精度
- 再加上 GGUF 文件通常很轻量,格式相对简单,社区可以无需 ONNXRuntime、TensorRT 等推理引擎,也能低门槛地进行本地推理
总体来说,ONNX 适合更通用、更跨平台的模型交换,尤其在多框架支持和通用推理场景下非常有用。但是像 ggml/llama.cpp 这类专注于 “在 CPU 或 GPU 上高效推理大语言模型” 并且大量使用细粒度量化策略的场景,就会选择与自身开发思路契合的专用格式(如 GGUF),省去对通用计算图进行解析和适配的麻烦,也能高度控制在加载、推理时的内存布局和性能表现
gguf 文件结构如下图所示:

gguf 文件中各字节代表的含义如上图所示,它们使用在 general.alignment 元数据字段中指定的全局对齐方式,在需要时,gguf 文件会以 0x00 字节填充到 general.alignment 的下一个倍数。除非另有说明,否则字段(包括数组)都是按顺序写入的,不会对齐
关于 gguf 更详细的说明,大家感兴趣的可以看看官方说明文档:https://github.com/ggml-org/ggml/blob/master/docs/gguf.md
3.2 ggml_tensor
ggml_tensor 是 ggml 框架中用于表示 n 维张量(tensor)的结构体,可以类比于 pytorch 中 tensor 的概念
其定义如下:
/* include/ggml.h */
// n-dimensional tensor
struct ggml_tensor {
enum ggml_type type;
struct ggml_backend_buffer * buffer;
int64_t ne[GGML_MAX_DIMS]; // number of elements
size_t nb[GGML_MAX_DIMS]; // stride in bytes:
// nb[0] = ggml_type_size(type)
// nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding
// nb[i] = nb[i-1] * ne[i-1]
// compute data
enum ggml_op op;
// op params - allocated as int32_t for alignment
int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)];
int32_t flags;
struct ggml_tensor * src[GGML_MAX_SRC];
// source tensor and offset for views
struct ggml_tensor * view_src;
size_t view_offs;
void * data;
char name[GGML_MAX_NAME];
void * extra; // extra things e.g. for ggml-cuda.cu
char padding[8];
};
其中:(from ChatGPT)
type字段表示张量的数据类型,它是一个枚举类(ggml_type)。ggml 支持多种数据类型,例如GGML_TYPE_F32、GGML_TYPE_F16、GGML_TYPE_Q4_0等等buffer字段是一个指向ggml_backend_buffer结构的指针,指向的是能够操作该张量对应的数据块的接口,而实际 tensor 对应的数据存储地址为data指针指向的位置。该结构体我们后续会做详细分析ne是一个整数数组,表示张量每一维的大小。例如,对于 3 维张量,ne数组将包含三个数值分别表示每一维的大小nb数组表示每一维度的字节步长(stride)。步长用于描述内存中不同维度元素的存储距离,例如,nb[0]是类型元素的大小,nb[1]是跨越第一维度所需的字节数,依此类推。它用于高效地访问多维数组中的元素,对于一个 4x3x2 的 tensor 来说,其步长nb计算如下:

op字段表示张量的操作类型,它也是一个枚举类(ggml_op),将其设置为GGML_OP_NONE时表示该 tensor 持有数据。而其它值表示不同的操作,例如GGML_OP_MUL_MAT表示该 tensor 不保存数据,只表示其它两个 tensor 之间的矩阵乘法结果op_params是一个整数数组,存储与张量操作相关的一些参数flags字段存储张量的一些状态标志,可能用于标识张量的特性,如是否需要梯度计算等src是一个指针数组,指向要在其间进行运算的 tensor。例如,如果op == GGML_OP_MUL_MAT,那么src将包含指向两个要相乘的 tensor 的指针,如果op == GGML_OP_NONE,那么src将是空的view_src字段表示另一个张量的指针,若该 tensor 是其它 tensor 的引用时,引用的目标 tensor 指针为 view_srcview_offs字段表示偏移量,即从view_src中的哪个位置开始获取数据data指向实际的 tensor 数据,如果该 tensor 是一个操作(例如op == GGML_OP_MUL_MAT),则指向NULL。它也可以指向另一个 tensor 的数据,即视图(view)name是一个字符数组,用于存储张量的名词extra是一个通用的指针,允许为张量存储额外的信息。在 CUDA 或其它后端中,它可能用于存储特定于设备的额外数据padding是用来填充的空间,可能是为了确保结构体对齐,以便更高效地访问内存- 关于结构体对齐是怎么计算的,大家感兴趣的可以看看:结构体对齐怎么计算的,一个视频带你理解清楚
ggml_tensor 结构体定义了一个 n 维张量的各种属性,包括张量的维度信息、数据类型、内存存储、计算操作、源张量等。它主要涉及数据存储、计算图操作和后端支持(如 CUDA)的交互
在 理解llama.cpp如何进行LLM推理 文章中我们也有详细解释过 ggml 中的张量,大家感兴趣的可以看看
3.3 ggml_backend_buffer
在 ggml 框架中,一切数据(context、dataset、weight、output…)都应该被存放在 buffer 中,而之所以要用 buffer 进行集成承载不同的数据,主要是为了便于实现多种后端(CPU、GPU)设备内存的统一管理。也就是说 buffer 是实现不同类型数据在多种后端上进行统一的接口对象,其结构如下图所示:

在 ggml 框架中,buffer 结构体 ggml_backend_buffer 的设计涉及了较多的层次,使用了面向对象的编程模式来封装不同的功能。这种设计模式的核心目的是为每种设备(例如 CPU、GPU)提供一个通用的接口,同时又能根据设备的特性执行优化
其定义如下:
/* src/ggml-backend-impl.h */
struct ggml_backend_buffer {
struct ggml_backend_buffer_i iface;
ggml_backend_buffer_type_t buft;
void * context;
size_t size;
enum ggml_backend_buffer_usage usage;
};
我们可以按照以下几个关键组件来分析整个 buffer 的设计:
1. ggml_backend_buffer_i
ggml_backend_buffer_i 是一个结构体,其定义如下:
struct ggml_backend_buffer_i {
// (optional) free the buffer
void (*free_buffer) (ggml_backend_buffer_t buffer);
// base address of the buffer
void * (*get_base) (ggml_backend_buffer_t buffer);
// (optional) initialize a tensor in the buffer (eg. add tensor extras)
void (*init_tensor) (ggml_backend_buffer_t buffer, struct ggml_tensor * tensor);
// tensor data access
void (*memset_tensor)(ggml_backend_buffer_t buffer, struct ggml_tensor * tensor, uint8_t value, size_t offset, size_t size);
void (*set_tensor) (ggml_backend_buffer_t buffer, struct ggml_tensor * tensor, const void * data, size_t offset, size_t size);
void (*get_tensor) (ggml_backend_buffer_t buffer, const struct ggml_tensor * tensor, void * data, size_t offset, size_t size);
// (optional) tensor copy: dst is in the buffer, src may be in any buffer, including buffers from a different backend (return false if not supported)
bool (*cpy_tensor) (ggml_backend_buffer_t buffer, const struct ggml_tensor * src, struct ggml_tensor * dst);
// clear the entire buffer
void (*clear) (ggml_backend_buffer_t buffer, uint8_t value);
// (optional) reset any internal state due to tensor initialization, such as tensor extras
void (*reset) (ggml_backend_buffer_t buffer);
};
它定义了一组指针函数(即接口),这些函数是针对缓冲区(buffer)操作的一些基本功能。_i 后缀通常表示 “interface”(接口),它是一种编程约定,用于区分结构体与它所提供的接口函数
这个结构体中的函数指针如下:
free_buffer:释放缓冲区get_base:获取缓冲区的首地址init_tensor:在缓冲区中初始化张量memset_tensor、set_tensor、get_tensor:用于张量数据的读写cpy_tensor:在不同的缓冲区间进行张量数据的复制clear:清空整个缓冲区reset:重置缓冲区的内部状态
这些操作都是通过不同后端设备实现的具体细节来执行的
Note:结构体中的 ggml_backend_buffer_t 是 ggml_backend_buffer 结构体的指针类型,_t 后缀通常表示它是一个类型别名
2. ggml_backend_buffer_type_t
ggml_backend_buffer_type_t 是指向 ggml_backend_buffer_type 的指针类型,而 ggml_backend_buffer_type 结构体定义如下:
struct ggml_backend_buffer_type {
struct ggml_backend_buffer_type_i iface;
ggml_backend_dev_t device;
void * context;
};
该结构体用于表示缓冲区的类型,每种缓冲区类型都会实现一组接口(通过结构体 ggml_backend_buffer_type_i 来定义),允许在不同的后端(如 CPU 和 GPU)上创建和管理缓冲区
Note:ggml_backend_dev_t 是指向 ggml_backend_device 的指针类型,它封装了后端设备的各种具体信息
ggml_backend_buffer_type_i 定义如下:
struct ggml_backend_buffer_type_i {
const char * (*get_name) (ggml_backend_buffer_type_t buft);
// allocate a buffer of this type
ggml_backend_buffer_t (*alloc_buffer) (ggml_backend_buffer_type_t buft, size_t size);
// tensor alignment
size_t (*get_alignment) (ggml_backend_buffer_type_t buft);
// (optional) max buffer size that can be allocated (defaults to SIZE_MAX)
size_t (*get_max_size) (ggml_backend_buffer_type_t buft);
// (optional) data size needed to allocate the tensor, including padding (defaults to ggml_nbytes)
size_t (*get_alloc_size)(ggml_backend_buffer_type_t buft, const struct ggml_tensor * tensor);
// (optional) check if tensor data is in host memory and uses standard ggml tensor layout (defaults to false)
bool (*is_host) (ggml_backend_buffer_type_t buft);
};
其接口函数包括:
get_name:获取缓冲区类型名alloc_buffer:为指定类型分配缓冲区get_alignment:获取缓冲区的对齐要求get_max_size、get_alloc_size:查询缓冲区的最大大小和分配大小is_host:检查缓冲区是否位于主机内存 host 中
3. context 和 size
context 字段是一个指向 void 的指针,通常用于存储与特定后端或设备相关的额外信息,可能是设备上下文、内存管理上下文或者其他一些元数据
size 字段则表示缓冲区的大小
4. ggml_backend_buffer_usage
ggml_backend_buffer_usage 是一个枚举类型,用于描述缓冲区的用途,其定义如下:
enum ggml_backend_buffer_usage {
GGML_BACKEND_BUFFER_USAGE_ANY = 0,
GGML_BACKEND_BUFFER_USAGE_WEIGHTS = 1,
GGML_BACKEND_BUFFER_USAGE_COMPUTE = 2,
};
其中:
GGML_BACKEND_BUFFER_USAGE_ANY:通用缓冲区,可以用于任何用途GGML_BACKEND_BUFFER_USAGE_WEIGHTS:用于存储权重数据的缓冲区GGML_BACKEND_BUFFER_USAGE_COMPUTE:用于计算的缓冲区
buffer 的整个设计的核心思想是将不同的缓冲区操作抽象成接口,通过 ggml_backend_buffer、ggml_backend_buffer_type 和 ggml_backend_device 等结构体实现对不同硬件(如 CPU 或 GPU)的支持。这样,通过统一的接口和抽象层,框架能够灵活地支持多种设备和后端,同时优化内存管理和数据传输
3.4 ggml_context
context 直译为 “上下文”,在 ggml 框架中会出现各种以 context 为名称的变量,在此框架中我们可以把它翻译为 “环境信息”,类似于操作系统的 “环境变量”(针对不同的程序需要设置不同的环境变量)
对于 ggml 框架来说,无论你要做什么(例如构建 model、建立计算图等)都需要先创建一个 context 作为容器,而你所创建的任何信息结构体(tensor、graph、…)实际都存储在 context 容器包含的地址空间内
下面我们以 ggml_context 为例来讲解,ggml_context 主要用于管理和存储与计算图或张量操作相关的上下文信息,可以承载三种数据类型:Tensor、Graph、Work_buffer。它可以被看作是一个 内存管理 和 资源组织 的中心,负责管理计算中使用的所有对象和内存,内部结构如下图所示:

Note:图片来自于:llama.cpp源码解读–ggml框架学习
其定义如下:
/* src/ggml.c */
struct ggml_context {
size_t mem_size;
void * mem_buffer;
bool mem_buffer_owned;
bool no_alloc;
int n_objects;
struct ggml_object * objects_begin;
struct ggml_object * objects_end;
};
其中:
mem_size字段表示ggml_context所管理的内存总大小(以字节为单位)mem_buffer是一个指向内存缓冲区的指针,之前说过 ggml 中一切数据都要放在 buffer 中,这里的ggml_context也不例外mem_buffer_owned字段标识ggml_context是否拥有mem_buffer。- 如果为
true,意味着ggml_context自己负责管理和释放这个内存缓冲区 - 如果为
false,表示内存由其他部分管理,ggml_context仅用于访问
- 如果为
no_alloc字段表示ggml_context是否允许内存分配保存实际数据n_objects字段表示ggml_context管理的对象数量objects_begin指向第一个ggml_object的指针,标记了管理对象链表的起始位置objects_end指向最后一个ggml_object的指针,它表示当前上下文中对象链表的结束位置。通过这两个指针(objects_begin和objects_end),可以遍历所有的ggml_object,从而管理所有的计算对象
ggml_object 结构体的定义如下:
enum ggml_object_type {
GGML_OBJECT_TYPE_TENSOR,
GGML_OBJECT_TYPE_GRAPH,
GGML_OBJECT_TYPE_WORK_BUFFER
};
struct ggml_object {
size_t offs;
size_t size;
struct ggml_object * next;
enum ggml_object_type type;
char padding[4];
};
ggml_object 代表了 ggml 框架中的一个对象,在 ggml_context 中,每个对象都有以下字段:
offs字段表示对象在mem_buffer中的偏移量,也就是说,offs是指向该对象数据在内存中的位置size字段表示对象的大小,即该对象所占用的内存大小next是一个指向下一个ggml_object的指针。这种链表结构允许将多个ggml_object组织成一个有序的集合,并且可以依次遍历它们type字段表示对象的类型。它是一个枚举类,定义了几种不同的对象类型,主要有:GGML_OBJECT_TYPE_TENSOR:表示一个张量对象GGML_OBJECT_TYPE_GRAPH:表示一个计算图对象GGML_OBJECT_TYPE_WORK_BUFFER:表示一个工作缓冲区对象
padding数组用于填充,确保结构体的内存对齐
总的来说,ggml_context 类似于一个 “容器” 或 “管理器”,负责保存和组织计算图中的所有对象,它让你可以灵活地处理张量、计算图等对象的内存分配、释放和管理。
3.5 backend
ggml 的后端 backend 有如下几个比较重要的概念:(from here)
ggml_backend:执行计算图的接口,有多种类型,包括:CPU(默认)、CUDA、Metal(Apple Silicon)、Vulkan 等等ggml_backend_buffer:表示后端 backend 分配的内存空间ggml_backend_sched:一个调度器,使得多种后端可以并发使用。在处理大模型或多 GPU 推理时,实现跨硬件平台地分配计算任务(如 CPU+GPU 混合计算)。该调度器还能自动将 GPU 不支持的算子转移到 CPU 上,来确保最优的资源利用和兼容性
具体的后端细节与后端调度器内容过多,博主能力有限这边就不分析了,大家感兴趣的可以自己看看相关源码
3.6 ggml_cgraph
计算图(computation graph,cgraph)是 Deep Learning 框架中常见的一个重要概念,用一句话通俗地说:计算图是一种有向图,用来描述计算的依赖关系和执行顺序
它的核心目的是:把复杂的数学表达式拆分成一系列的基本运算节点,然后用图的形式表示这些节点之间的依赖关系
举个例子,假设我们要计算 C = A × B + C C = A \times B + C C=A×B+C,根据 tensor 之间关系构建的计算图如下:

Note:图片来自于 llama.cpp源码解读–ggml框架学习
在上图中,分两种类型的元素:node 中间节点(白色)和 leaf 叶节点(粉红色)。一切既不是参数(weight)也不是操作数(即 ggml_tensor 结构体中的 op 为 None)的元素称之为 leaf,其余都作为 node(如 op 为 GGML_OP_MUL_MAT)
图中 leaf_0、leaf_1 和 leaf_2 都是 leaf 类型张量,是输入或常量张量,在计算中不会被修改,其中:
leaf_0 (f32) / CONST 0 [4, 3]leaf_0是view的源张量CONST 0表示它是个常量张量,数据类型为 float32,shape 为 4x3
leaf_1等于 A A A,shape 为 2x4,leaf_2等于 B B B,shape 为 2x3- 注意,ggml 内部会做隐式转换,将
leaf_1的 shape 做转置变为 4x3
图中 node_0 是 node 类型张量,对应 ggml_tensor 中 op == GGML_OP_MUL_MAT 操作,也就是:
node_0 = ggml_mul_mat(leaf1, leaf2)
最后一个节点 node 有 (view) 标识,结合之前我们对 ggml_tensor 的讲解可知,这个节点是一个对原节点(leaf_0)的引用,即将
A
×
B
+
C
A \times B +C
A×B+C 的计算结果直接存储在
C
C
C 矩阵的 tensor 中(leaf_0),而不是重新建立一个新的 tensor 来进行存储
ggml 中的计算图结构体 ggml_cgraph 定义如下:
struct ggml_cgraph {
int size; // maximum number of nodes/leafs/grads/grad_accs
int n_nodes; // number of nodes currently in use
int n_leafs; // number of leafs currently in use
struct ggml_tensor ** nodes; // tensors with data that can change if the graph is evaluated
struct ggml_tensor ** grads; // the outputs of these tensors are the gradients of the nodes
struct ggml_tensor ** grad_accs; // accumulators for node gradients
struct ggml_tensor ** leafs; // tensors with constant data
struct ggml_hash_set visited_hash_set;
enum ggml_cgraph_eval_order order;
};
其中:
size表示计算图中可容纳的最大节点数,包含中间节点、叶节点、梯度和梯度累加器n_nodes表示当前图中用于计算的 中间节点 数量,比如加法、乘法这些操作形成的节点n_leafs表示当前图中所有 叶节点 数量nodes用来存放图中所有中间节点grads用来存放图中每个计算节点对应的梯度张量grad_accs用来存放梯度的累加器leafs用来存放图中的叶子张量visited_hash_set结构体利用哈希集合来记录哪些节点已经被访问过,用来避免重复处理节点(类似于图遍历中的 “标记是否访问过”)order字段指定了计算图中节点的评估顺序
总的来说,ggml_cgraph 就是 ggml 中用来组织张量运算顺序、执行依赖、自动微分的计算图引擎核心结构
3.7 ggml_gallocr
我们需要知道,图 graph 是根据 ctx 中 tensor 之间的关系进行建立的,而 graph 中可能包含着输入数据、权重、新建的 node 节点,这些在 graph 中都只是数据的描述信息,而不是数据本身。因此我们还需要有一个专门的内存分配器来对我们计算图 graph 中所需要使用的全部数据进行内存分配,这就是 ggml_gallocr 所要做的事情
ggml_gallocr 定义如下:
/* src/ggml-alloc.c */
struct ggml_gallocr {
ggml_backend_buffer_type_t * bufts; // [n_buffers]
ggml_backend_buffer_t * buffers; // [n_buffers]
struct ggml_dyn_tallocr ** buf_tallocs; // [n_buffers]
int n_buffers;
struct ggml_hash_set hash_set;
struct hash_node * hash_values; // [hash_set.size]
struct node_alloc * node_allocs; // [n_nodes]
int n_nodes;
struct leaf_alloc * leaf_allocs; // [n_leafs]
int n_leafs;
};
整个结构体分为以下几个部分:(from ChatGPT)
1. 缓冲区管理
bufts与buffersbufts:存储了多个后端缓冲区类型(ggml_backend_buffer_type_t),用于描述每个缓冲区的类型信息buffers:存储实际的后端缓冲区(ggml_backend_buffer_t),每个缓冲区代表一块内存区域,供计算图中张量数据存放n_buffers:表示当前管理的缓冲区数量
buf_tallocs- 每个缓冲区都有对应的动态张量分配器
ggml_dyn_tallocr,用于管理该缓冲区内的内存分配 buf_tallocs是一个指针数组,每个元素对应一个缓冲区内的动态分配器,它负责追踪该缓冲区的空闲内存块、对齐要求以及最大可分配内存量
- 每个缓冲区都有对应的动态张量分配器
2. 哈希集合管理
hash_set与hash_values- 在内存分配过程中,可能会遇到重复的分配请求或需要对已有分配做快速查找
hash_set用来记录已经处理过的张量的信息,防止重复分配hash_values是一个数组,存储每个键对应的hash_node,其中每个hash_node包含了分配状态、所在缓冲区、偏移量以及引用计数信息
3. 节点和叶子分配
node_allocs与n_nodes- 用于记录图中 计算节点(即中间计算结果张量)的内存分配情况
- 每个
node_alloc结构体记录了一个节点的输出(dst)内存分配信息以及输入(src)的分配信息
leaf_allocs与n_leafs- 用于记录图中 叶子节点(通常为输入、常量或权重张量)的内存分配情况
- 每个
leaf_alloc仅包装了一个tensor_alloc结构体,记录了该叶子张量所在的缓冲区、内存偏移和分配的大小
整个 ggml_gallocr(图内存分配器)的设计目的是为了高效管理计算图中各类张量的内存分配,它通过以下几个层面实现这一目标:
- 缓冲区与动态分配器管理
- 使用
buffers、bufts以及buf_tallocs数组管理底层内存缓冲区,确保内存对齐和空闲块的合理利用
- 使用
- 哈希集合辅助配合
- 通过
hash_set和hash_values快速查找和管理重复分配、共享内存块,防止重复分配及内存浪费
- 通过
- 节点与叶子分配
- 分别使用
node_allocs和leaf_allocs记录计算节点和输入/常量张量的内存分配信息,保证计算图在执行前向传播和反向传播时内存访问正确、布局合理
- 分别使用
4. 推理流程整体梳理
在简单了解了 ggml 中的一些核心概念之后,我们先来把 ggml 推理 gpt-2 的总体流程过一遍,也就是先来把 main-backend.cpp 中的 main 函数梳理下,不跳进具体的函数,先把握下推理的整体过程
4.1 时间初始化与参数设置

在 main 函数中首先我们做了时间初始化与相关参数的一些设置
对于时间初始化,一开始调用了 ggml_time_init() 函数,并记录了程序开始时间,主要是方便后续统计模型加载、模型预测等各阶段的耗时
接着创建了一个 gpt_params 结构体,其定义如下,并将传入的命令参数进行解析并覆盖默认参数,在这里主要传入的是模型的路径、提示词文本等
struct gpt_params {
int32_t seed = -1; // RNG seed
int32_t n_threads = std::min(4, (int32_t) std::thread::hardware_concurrency());
int32_t n_predict = 200; // new tokens to predict
int32_t n_parallel = 1; // number of parallel streams
int32_t n_batch = 32; // batch size for prompt processing
int32_t n_ctx = 2048; // context size (this is the KV cache max size)
int32_t n_gpu_layers = 0; // number of layers to offlload to the GPU
bool ignore_eos = false; // ignore EOS token when generating text
// sampling parameters
int32_t top_k = 40;
float top_p = 0.9f;
float temp = 0.9f;
int32_t repeat_last_n = 64;
float repeat_penalty = 1.00f;
std::string model = "models/gpt-2-117M/ggml-model.bin"; // model path
std::string prompt = "";
std::string token_test = "";
bool interactive = false;
int32_t interactive_port = -1;
};
gpt_params 结构体主要用于存储 GPT 模型推理相关的参数,包括批处理大小(n_batch)、上下文窗口大小(n_ctx)、采样参数、提示词文本(prompt)等等
4.2 模型加载与词汇表构建

参数设置完之后,我们开始利用这些参数来加载我们的模型,并构建词汇表
首先我们定义了 gpt_vocab 和 gpt2_model 两个结构体对象,分别用于存储词汇表和 GPT-2 模型相关的数据,它们的定义如下:
gpt_vocab 结构体定义:
struct gpt_vocab {
using id = int32_t;
using token = std::string;
std::map<token, id> token_to_id;
std::map<id, token> id_to_token;
std::vector<std::string> special_tokens;
void add_special_token(const std::string & token);
};
gpt_vocab 结构体中 token_to_id 成员变量用于从 token 到 ID 的映射,允许根据 token 查找对应的 ID,例如给定一个 token 如 "hello" 查找它在词汇表中的 ID,而 id_to_token 成员变量则刚好相反,用于从 ID 到 token 的反向映射,special_tokens 则存储着模型中一些特殊的 token 如 eos 等
gpt2_model 结构体定义:
struct gpt2_model {
gpt2_hparams hparams;
// normalization
struct ggml_tensor * ln_f_g;
struct ggml_tensor * ln_f_b;
struct ggml_tensor * wte; // position embedding
struct ggml_tensor * wpe; // token embedding
struct ggml_tensor * lm_head; // language model head
std::vector<gpt2_layer> layers;
// key + value memory
struct ggml_tensor * memory_k;
struct ggml_tensor * memory_v;
//
struct ggml_context * ctx_w;
struct ggml_context * ctx_kv;
ggml_backend_t backend = NULL;
ggml_backend_buffer_t buffer_w;
ggml_backend_buffer_t buffer_kv;
std::map<std::string, struct ggml_tensor *> tensors;
};
gpt2_model 结构体是 GPT-2 模型的核心部分,包含模型的各种参数:
hparams是一个结构体,存储 GPT-2 的超参数,如隐藏层大小、词汇表大小等ln_f_g和ln_f_b是 LayerNorm 层的参数,分别表示缩放因子 scale 和偏置项 biaswte和wpe是两个 embedding 向量,分别表示 token 的 embedding 和 position 的 embedding,它们都是 ggml_tensor 结构体lm_head是语言模型的头,用于计算最终的 logitslayers存储了模型的多个层(通常是 Transformer 层)memory_k和memory_v是我们常说的 kv cachectx_w和ctx_kv是模型的上下文指针,其中ctx_w可能与权重相关,ctx_kv可能与 kv cache 相关backend表示模型计算的后端,例如 CPU 或 GPUbuffer_w和buffer_kv用于存储模型计算过程中需要的缓存区tensors用于存储模型中的各种张量,其中张量名字为键,张量对象为值
接着调用 gpt2_model_load 加载模型文件,同时将定义的 model 和 vocab 传入,这个函数是我们后续需要重点分析的,该函数包含模型权重加载、ggml 上下文的创建、后端初始化等等工作
4.3 计算图与内存分配

首先通过 ggml_gallocr_new 创建了一个图形分配器,该分配器基于模型后端默认的 buffer 类型
接着根据当前模型的上下文大小和批处理大小,构建了一个 “最坏情况” 下的计算图(cgraph),它通过 gpt2_graph 函数来构建。然后调用 ggml_gallocr_reserve 根据计算图预留内存,并在终端打印所需的计算缓冲区大小
这个步骤涉及到 ggml 框架的核心数据结构之一:ggml_cgraph(计算图),它用于组织计算步骤和内存管理。还有 ggml_gallocr 作为内存分配器,帮助估算和分配整个推理过程中需要的内存。计算图的构建和内存的分配也是我们后面需要重点分析的
Note:ggml 为了在运行阶段避免动态内存的申请,在计算开始之前会预分配一个 “足够大” 的内存空间。这种做法虽然可以提高运行效率,但也会带来一定的内存浪费,特别是在处理 kv cache 时。相比之下,其他一些推理框架如 vLLM,通过采用 PagedAttention 作为高速缓存管理层,在推理过程中能够更灵活地分配和释放内存。大家如果对 PagedAttention 感兴趣的话,可以看看 vLLM 的 Blog:vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
4.4 文本预处理与推理过程
模型加载、计算图构建、context 创建、内存分配这些都做完之后就可以正式进入我们的推理环节了

推理第一步要做的就是 tokenization 分词,对输入的 prompt 使用 gpt_tokenize 函数进行分词,将输入的文本序列转化为对应 token 的 ID 序列。在我们的例子中,输入的 prompt 是 "This is an example",经过分词后得到了四个 token("This"、"is"、"an"、"example") 的 ID
接着调整预测步数,确保整个输入加上预测的 token 数不超过模型上下文的最大长度

整个推理过程是以 token 为单位逐渐进行的(token-by-token),因此这里我们进入了一个 for 循环。当有 token(embd 不为空)时,调用 gpt2_eval 函数进行前向推理,更新 logits(概率分布)。
我们知道 gpt-2 的 vocabulary 词汇表的大小是 50257,因此这里我们得到了也刚好是 50257 个 logit,它们存储在一个 vector 容器中,每个 logit 是 float 类型的变量

推理完之后,更新累积已处理的 token 数(n_past),并清空当前的 token 缓冲(embd)
根据当前状态,若还处于处理初始 prompt,则按批处理一次性添加后续 token(else 分支,这里未执行)
若已经超过 prompt,则调用 gpt_sample_top_k_top_p 根据 logist 采样(温度采样),得到下一个 token,并将其加入上下文中(embd),在我们的例子中,预测得到的第一个 token 的 id 是 286

每个生成的 token 都会被立即打印出来,并检查是否遇到结束符以终止生成,在我们的例子中生成的第一个 token 是 "of"
接着模型会根据 "of" 这个 token 预测下一个 token,如此反复循环,直至达到结束生成条件
这个过程是绝大部分 LLM 推理的通用过程,大家如果对 LLM 的推理流程不熟悉,可以看看 理解llama.cpp如何进行LLM推理 这篇文章,这里博主把 LLM 推理过程的流程图贴在下面了:

4.5 性能统计与资源释放
整个推理完成之后就是一些资源的释放工作了

在所有生成过程完成后,统计并打印模型加载时间、采样时间、预测时间(以及平均每 token 的预测时间)和总执行时间
最后,依次释放模型使用的资源,包括:
- 释放模型上下文(
ggml_free) - 释放计算图内存分配器(
ggml_gallocr_free) - 释放后端分配的缓冲区和后端资源(
ggml_backend_buffer_free和ggml_backend_free)
4.6 完整推理流程
OK,以上就是 ggml 推理 gpt-2 的整理流程梳理了
博主绘制了一个简单的流程图来描述这整个过程:

下面我们就来具体分析其中的每个步骤
Note:由于逐行代码调试展示篇幅占用太大,因此博主下面就只展示一些重点核心部分的函数,例如时间记录、命令行参数解析这类的函数就跳过了,大家如果想要了解更多的细节可以跟随 UP 主的视频一步步调试。另外想要说的是博主这边选取的案例是 gpt-2,UP 主选择的案例是 mnist,其实都大差不差,重点是学习 ggml 中的一些核心概念如 ctx、ggml_tensor、gguf、cgraph 等等,以便更好的学习 llama.cpp
由于篇幅原因,我们将核心部分的函数分析放在下篇文章来讲解😄
结语
这篇文章我们主要学习了利用 ggml 来推理模型(以 gpt-2 为例),同时梳理了 ggml 中的一些核心概念,包括 ggml_tensor、ggml_backend_buffer、ggml_context、ggml_cgraph 等等,大部分的概念解释都来自于 ChatGPT,这里博主对这些概念只是有个简单的印象,具体的设计以及实现博主其实也并不了解,大家可以自己多看看源码实现
OK,以上就是 ggml 推理 gpt-2 总体流程梳理的全部内容了,下篇文章我们就来进入到具体的函数中分析每个步骤都是如何实现的,敬请期待🤗
下载链接
- ggml源码下载链接【提取码:1234】
- gpt-2-117M模型下载【提取码:1234】
参考
- 【大模型部署】GGML源码逐行调试
- llama.cpp源码解读–ggml框架学习
- https://github.com/ggml-org/ggml
- https://chatgpt.com/
- 理解llama.cpp如何进行LLM推理