集成学习
参考机器学习——集成算法。
集成算法是指构建多个学习器,然后通过一定策略结合它们来完成学习任务,常常可以表现得比单一学习更显著优越。
集成算法一般分为三类:
- bagging。并行训练多个模型,预测结果取所有模型的投票结果,或平均和。
- boosting。串行训练多个模型,每次从多个候选模型中,选取对预测提升最大的那个,加入集群。
- stacking。分两层训练,第一层训练多个模型,它们的输出作为第二层的输入。第二层训练一个分类器,对上一层的模型作综合,并输出最终结果。
bagging
直接阅读Bagging与随机森林算法原理小结即可。
用笔者的语言总结,就是训练多个弱分类器,再由它们投票预测结果。
每个分类器在训练时,对大小为m的数据集作m次可放回采样,得到训练集,并将剩余的从未被选中的数据作为验证集,可用于后剪枝操作
。
在切分训练/验证测试集时,由于每个样本都来自可放回采样,约36.8%的数据一直不会被选中。(具体计算见原文)
stacking
基本思想
参考 stacking算法基本思想
stacking的意思是将模型堆叠成多层,上一层模型的输出作为下一层模型的输入,并将最后一层输出的结果作为最终结果。通常可以只堆叠两层,第一层训练若干个基模型,第二层训练1个分类模型。训练时,先训练第一层,取它们的输出构建第二层的数据集,再训练第二层。
stacking 的思想也很好理解,接下来我们首先看两个简单的举例:
- 以论文审稿为例,首先是三个审稿人分别对论文进行审稿,然后分别返回审稿意见给总编辑,总编辑会结合审稿人的意见给出最终的判断,即是否录用。对应于stacking,这里的三个审稿人就是第一层的基模型,其输出(审稿人意见)会作为第二层模型(总编辑)的输入,然后第二层模型会给出最终的结果。
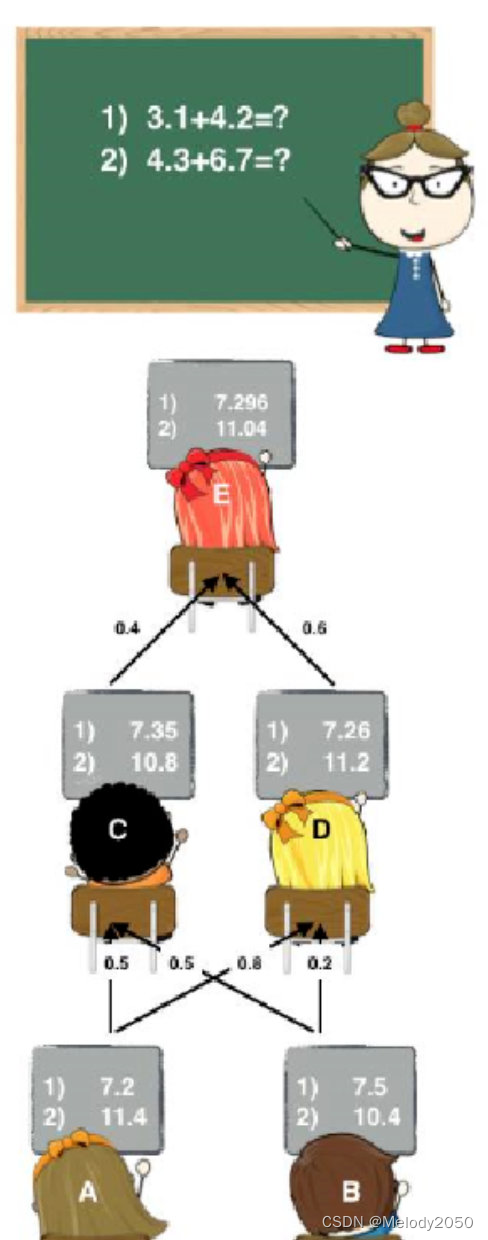
- 下图以讲课为例。图中相当于三层stacking,A、B是第一层的基学习器,C、D是第二层的学习器,E是处于第三层的学习器。
算法过程
参考7. 集成学习(Ensemble Learning)Stacking中的文字说明和集成学习之stacking详解的图片。
原文图片如下。
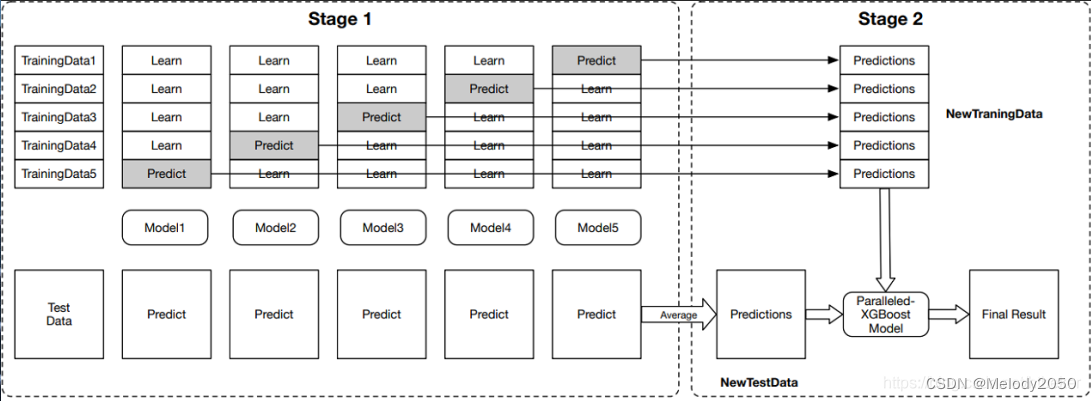
有一个样本数量为m的数据集D,其分为训练集
D
t
r
a
i
n
D_{train}
Dtrain和
D
t
e
s
t
D_{test}
Dtest。之后将要使用k-fold交叉验证,将训练集均分为5份。
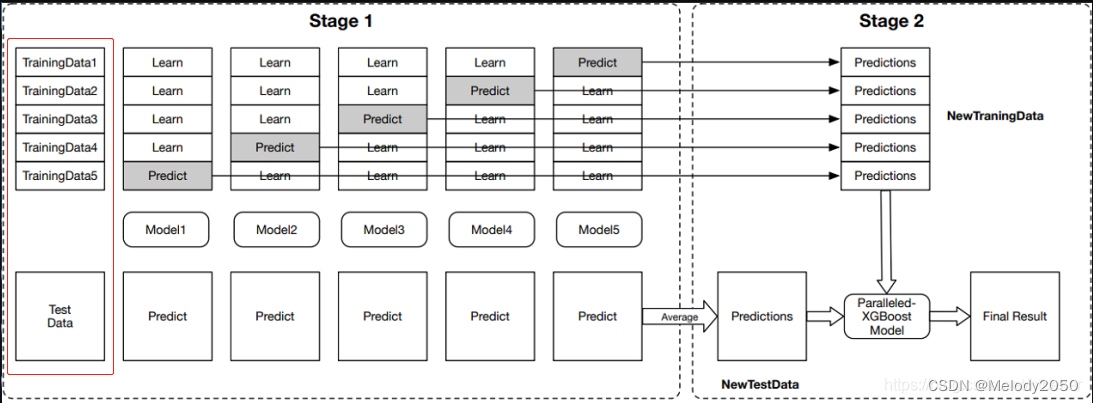
Stacking的初级学习器有n种。本例中n=5,是图中红框待训练的Model1到Model5。
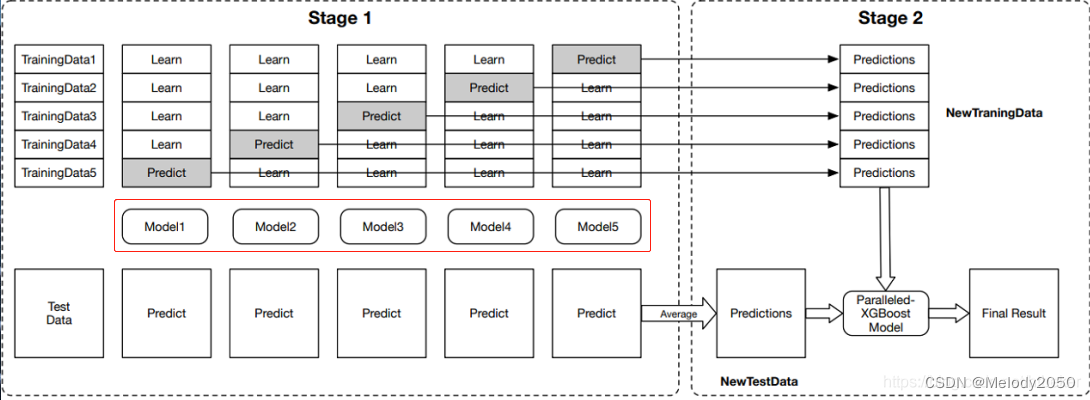
训练 m o d e l i model_i modeli
接下来训练
m
o
d
e
l
i
model_i
modeli。对
D
t
r
a
i
n
D_{train}
Dtrain进行5-fold处理,得到5种训练-验证集划分。每种划分里训练集和验证集大小为4:1。
第i个划分的训练集可用于训练模型
m
o
d
e
l
i
model_i
modeli,验证集可用于作验证
m
o
d
e
l
i
model_i
modeli的效果。
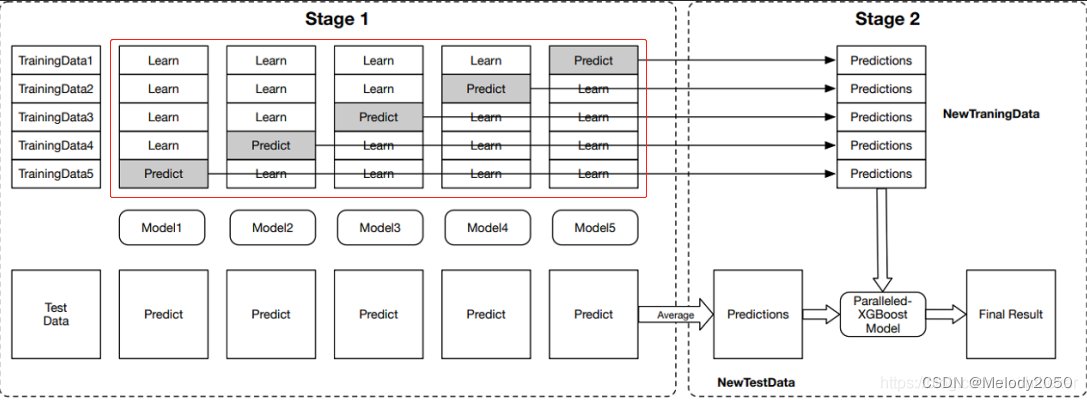
在每一折,会用4份的训练集训练模型,再用1份的验证集去预测,得到
D
v
a
l
i
j
D^{ij}_{val}
Dvalij,
5个折的
D
v
a
l
i
j
D^{ij}_{val}
Dvalij得到
D
v
a
l
i
D^{i}_{val}
Dvali,它将被用于下一层的输入。
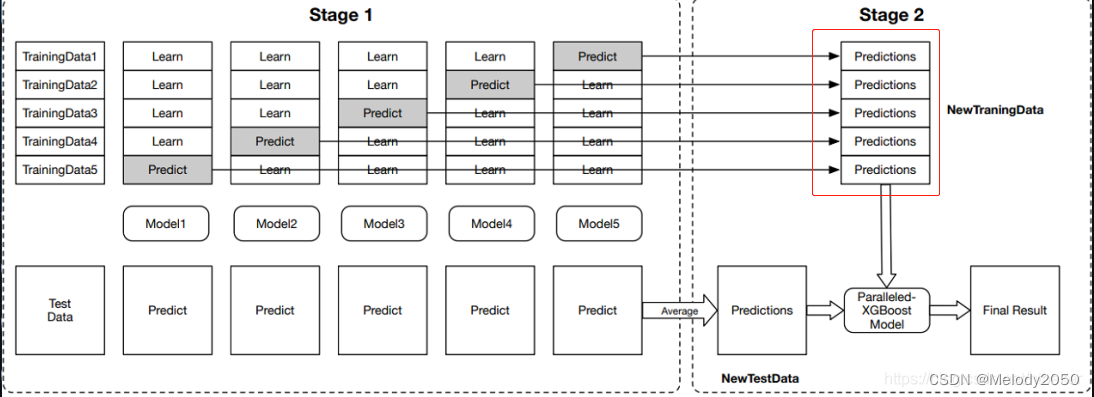
每个模型
m
o
d
e
l
i
model_i
modeli对预测集进行预测,
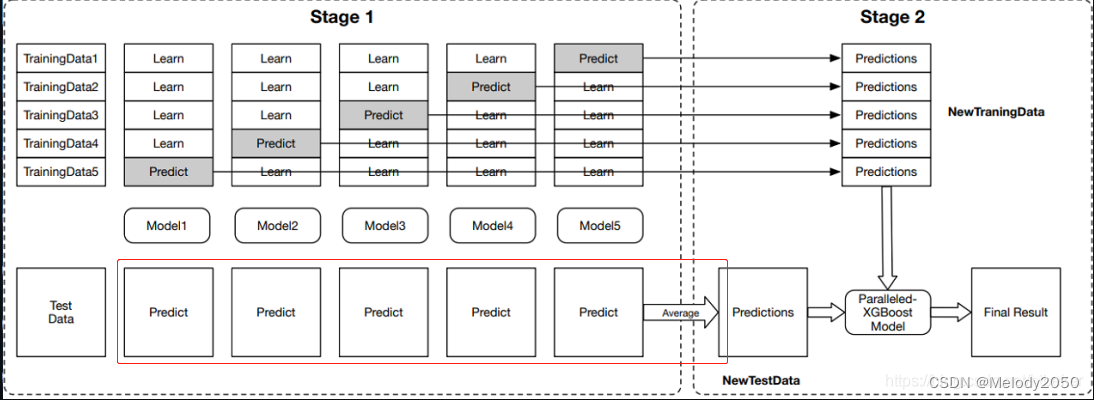


![[附源码]Python计算机毕业设计SSM基于web动物园网站(程序+LW)](https://img-blog.csdnimg.cn/289ea437fe7341798cee0d6015a274c3.png)