
论文:https://arxiv.org/pdf/2210.09461.pdf
代码: https://github.com/facebookresearch/ToMe
这篇论文写的很棒呀,以摘要为例,第一句话指明ToMe的作用(提高ViT-based模型的训练和推理速度)和特色(不需要训练哦);第二句话概括ToMe的方法(通过匹配算法,将相似token聚合在一起);后面几句话分别给出ToMe的量化指标(在处理图片、视频或音频时,提高两倍吞吐量,对准确率影响小),表明ToMe的优越性。还有引言的第一段,第一句话说明Transformer从NLP迁移到视觉任务上的历史;第二句话说明Vision Transformer的特点(这句话写得好棒);第三句话将特点归因于归纳偏置对视觉任务的重要性。
摘要
提出Token Merging (ToMe),无需额外训练即可提高ViT-based模型的训练和推理速度;
ToMe通过匹配算法,将transformer中的相似token聚合在一起;
在推理时加入ToMe:对图片数据,ToMe可以提高ViT-L@512和ViT-H@518两倍的吞吐量;对视频数据,ToMe可以提高ViT-L 2.2倍的吞吐量,仅降低0.2-0.3%准确率;
在训练时加入ToMe,对视频数据,ToMe可以缩短MAE fine-tuning两倍时间;同时,可以进一步减少准确率损耗,对音频数据,ToMe可以提高ViT-B两倍的吞吐量,仅降低0.4% mAP。
引言
Swin提出针对视觉任务的attention,MViT提出针对视觉任务的pooling,LeViT提出针对是觉任务的卷积模块。这些改进可以归因于归纳偏置对视觉任务的重要性,向transformer结构引入归纳偏置可以减少计算量的同时,提高准确性;
虽然vanilla ViTs结构具有一些不错的性质,但使用或复现他们是较为困难的。现有方法提出通过在推理阶段对token剪枝,加快模型速度。但是token剪枝有多个缺点:1)剪枝中的信息损失(information loss)限制了可以合理减少的token数量(?);2)部分方法需要对模型重新训练;3)大多数不能加速训练;4)部分方法的剪枝数量不固定,导致无法batched inference;
本文提出的Token Merging (ToMe) 可以加速ViT-based模型的训练和推理过程,无需修改即可用于图片、视频、音频数据的处理。
本文贡献:
ToMe可以加速ViT-based模型的训练和推理过程;
在图片、视频和音频数据上,在不同ViT模型上证明ToMe的有效性;
可视化发现融合后的token,在图片数据中可以表征物体的某个语义部分,在视频数据中可以表征某个物体;
近期工作
Efficient Transformer:1)更快的注意力计算;2)heads或特征剪枝;3)针对任务设计特定模块。
Token Reduction:token剪枝,存在两个问题:1)部分方法需要重新训练;2)部分方法产生的token数量是不固定的,导致这类方法无法batched inference,一些方法引入mask,而不是去除token,但这会影响模型速度。
Combining Tokens:token融合。1)GroupViT,使用跨注意力机制将token分组;2)TokenLearner,使用MLP减少token数量;3)Token Pooling:使用kmeans-based方法融合特征,但该方法需要重新训练模型。
Token Merging

Strategy. 1)数量:每层减少r个token,对于一个L层的transformer,则会逐步减少rL个token;2)位置:在attention和MLP之间,这有两个好处,首先被融合的token特征仍然可以传播,其次可以借助attention决定哪些token应该被融合;
Token Similarity.
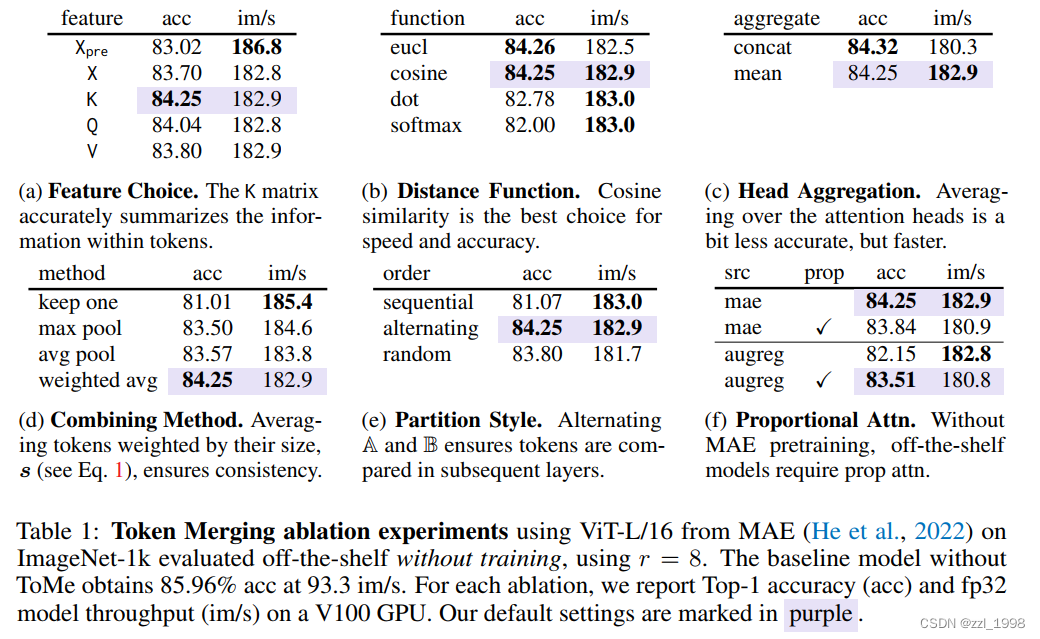
Bipartite Soft Matching
Tracking Token Size.










![[附源码]Python计算机毕业设计Django的家政服务平台](https://img-blog.csdnimg.cn/252e74743749479cab4b794614a555a2.png)