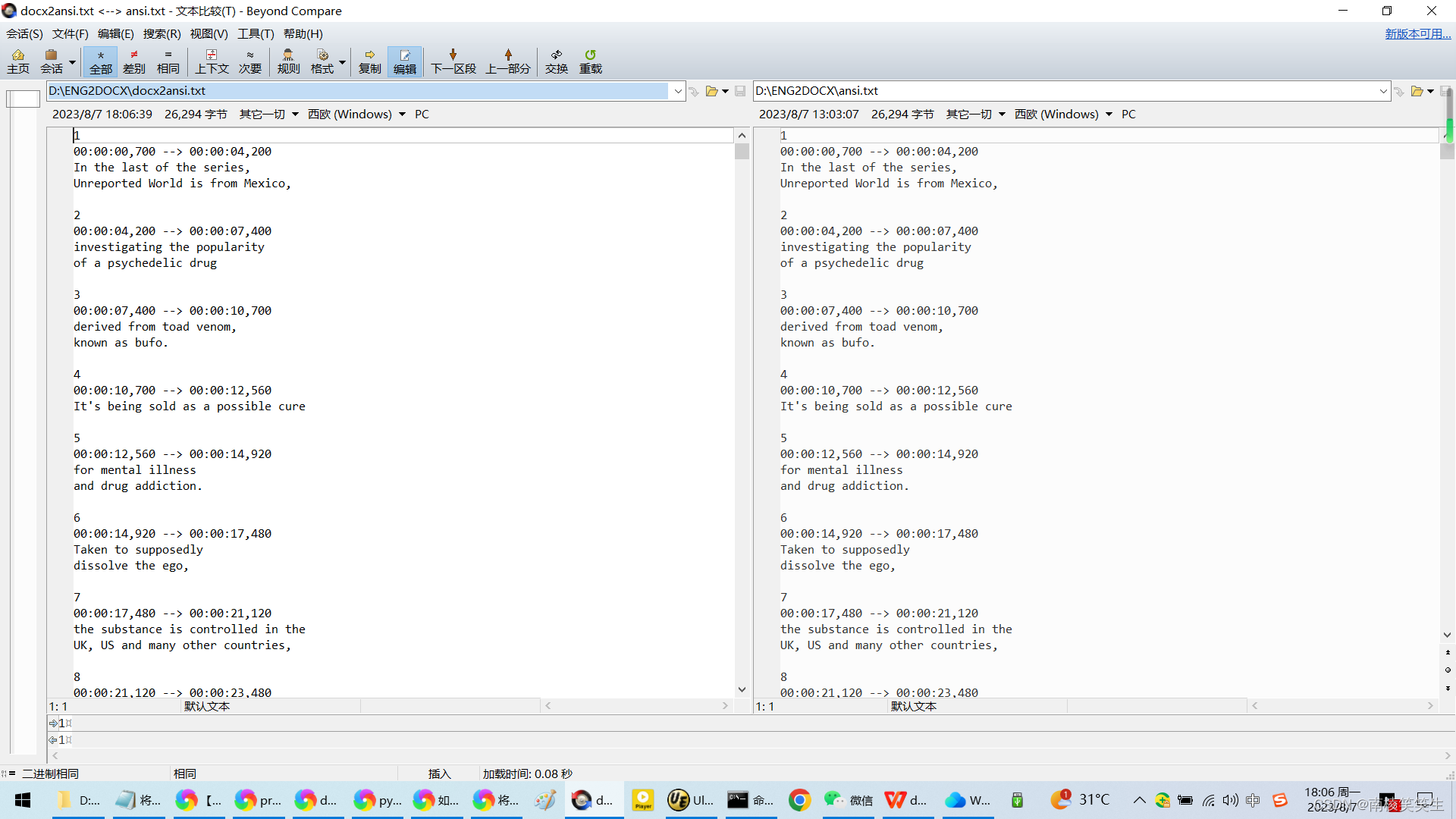
20230807在WIN10下使用python3将TXT文件转换为DOCX(在UTF8编码下转换为DOCX有多一行的瑕疵)
2023/8/7 12:58
https://translate.google.com/?sl=en&tl=zh-CN&op=docs
缘起,由于google的文档翻译不支持SRT/TXT格式的字幕,因此需要将SRT格式的字幕转为DOCX。
Ch4.Unreported.World.2022.Mexicos.Psychedelic.Toads.1080p.HDTV.x265.AAC.MVGroup.org.mkv
1、ANSI编码的TXT文件转DOCX:
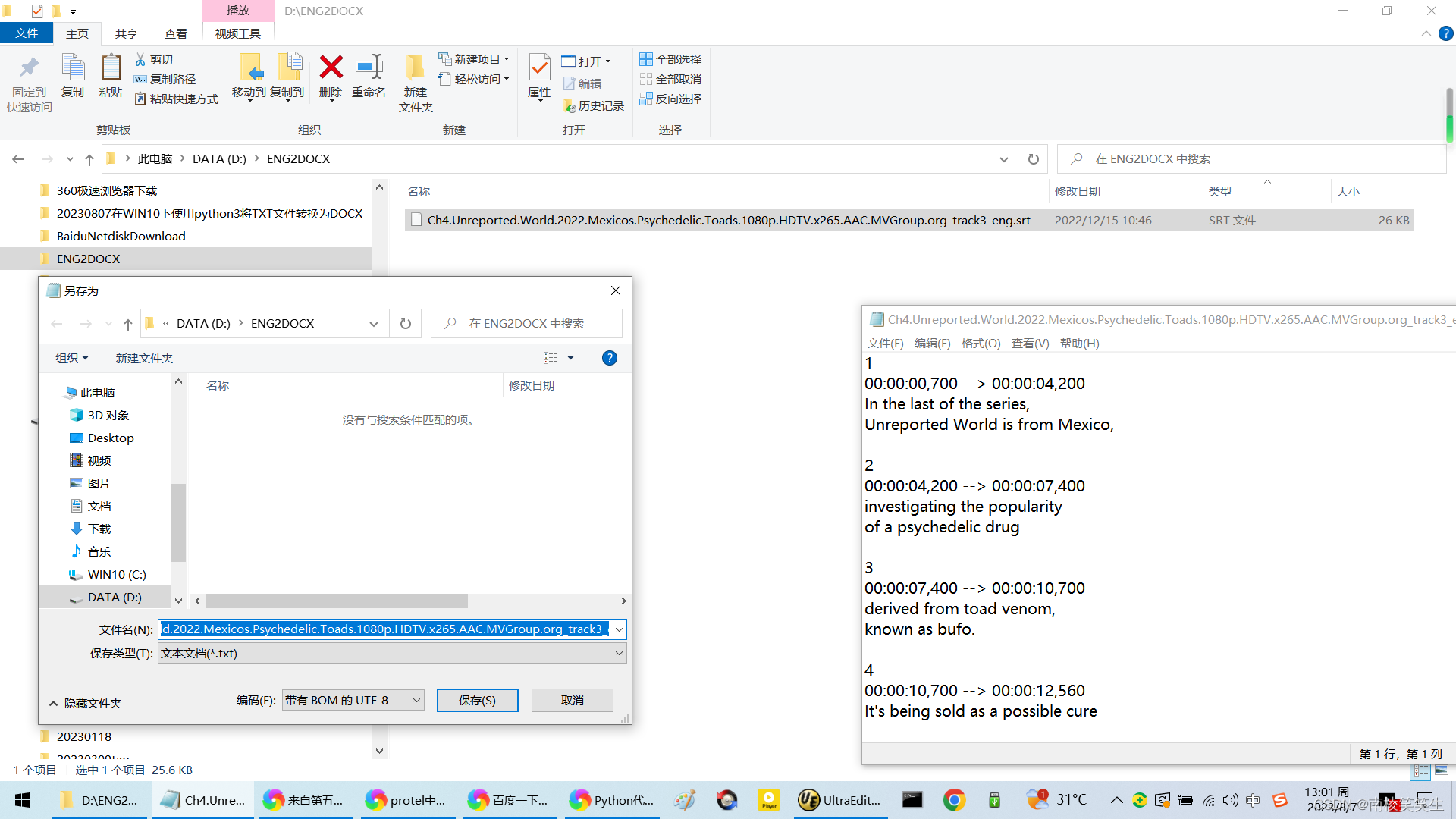
Ch4.Unreported.World.2022.Mexicos.Psychedelic.Toads.1080p.HDTV.x265.AAC.MVGroup.org_track3_eng.srt
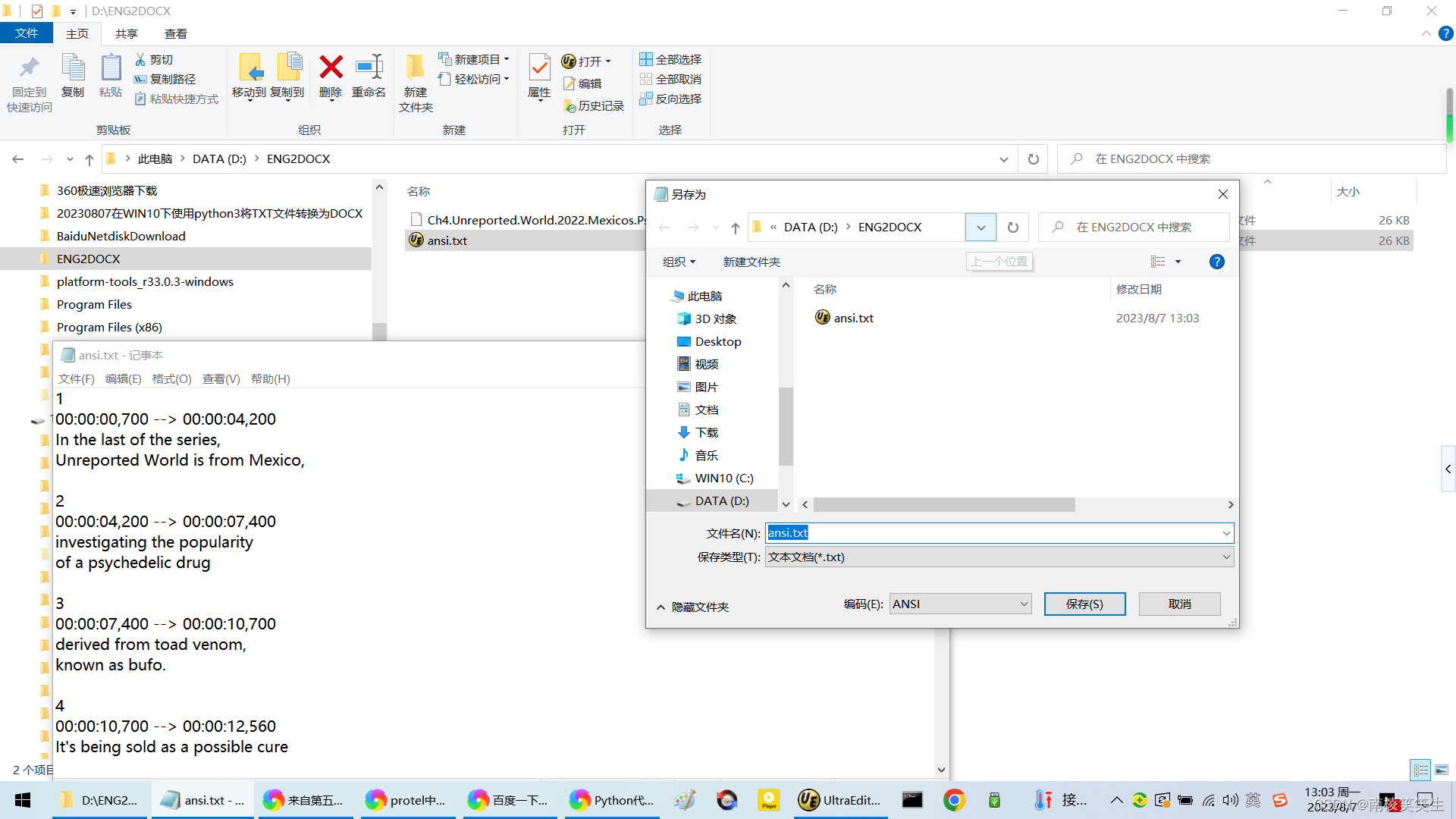
直接使用记事本另存为ANSI编码的:ansi.txt
完成之后可以确认的!

!!!!
https://wenku.csdn.net/answer/2cd4b739868911ed9a8700163e34985e
将txt文本转换成doc格式文件,直接写python代码
可以使用 python-docx 库来将 txt 文件转换为 docx 格式文件。
首先,需要安装 python-docx 库:
pip install python-docx
然后,可以使用以下代码将 txt 文件转换为 docx 格式文件:
import docx
# 读取 txt 文件with open('input.txt', 'r') as f:
text = f.read()
# 创建一个新的 docx 文档
document = docx.Document()
# 将 txt 文本写入文档
document.add_paragraph(text)
# 保存文档
document.save('output.docx')
上面的代码将会读取名为 input.txt 的 txt 文件,并将其内容写入一个新的 docx 文档中,最后保存为 output.docx 文件。
import docx
with open('ansi.txt', 'r') as f:
text = f.read()
#docment = docx.Docment()
docment = docx.Document()
docment.add_paragraph(text)
docment.save('ansi.docx')
Microsoft Windows [版本 10.0.19044.2728]
(c) Microsoft Corporation。保留所有权利。
C:\Users\QQ>cd D:\ENG2DOCX
C:\Users\QQ>d:
D:\ENG2DOCX>dir
驱动器 D 中的卷是 DATA
卷的序列号是 547F-1046
D:\ENG2DOCX 的目录
2023/08/07 18:00 <DIR> .
2023/08/07 18:00 <DIR> ..
2023/08/07 18:02 186 ansi.py
2023/08/07 13:03 26,294 ansi.txt
2022/12/15 10:46 26,297 Ch4.Unreported.World.2022.Mexicos.Psychedelic.Toads.1080p.HDTV.x265.AAC.MVGroup.org_track3_eng.srt
2023/08/07 10:18 278 utf8.py
2023/08/07 10:17 26,294 utf8.txt
5 个文件 79,349 字节
2 个目录 272,317,231,104 可用字节
D:\ENG2DOCX>
D:\ENG2DOCX>python ansi.py
D:\ENG2DOCX>dir
驱动器 D 中的卷是 DATA
卷的序列号是 547F-1046
D:\ENG2DOCX 的目录
2023/08/07 18:03 <DIR> .
2023/08/07 18:03 <DIR> ..
2023/08/07 18:03 47,533 ansi.docx
2023/08/07 18:02 186 ansi.py
2023/08/07 13:03 26,294 ansi.txt
2022/12/15 10:46 26,297 Ch4.Unreported.World.2022.Mexicos.Psychedelic.Toads.1080p.HDTV.x265.AAC.MVGroup.org_track3_eng.srt
2023/08/07 10:18 278 utf8.py
2023/08/07 10:17 26,294 utf8.txt
6 个文件 126,882 字节
2 个目录 272,317,181,952 可用字节
D:\ENG2DOCX>
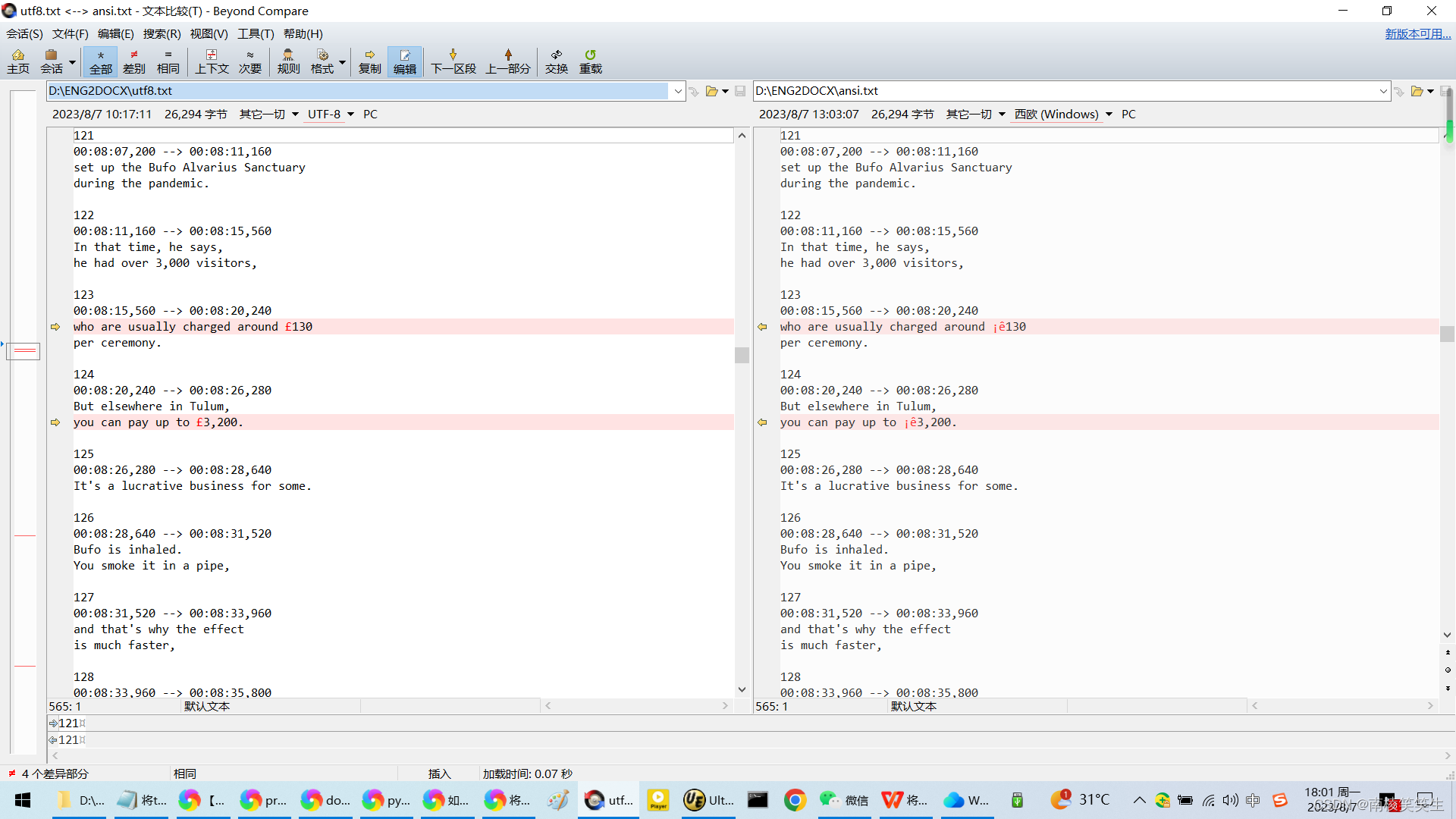
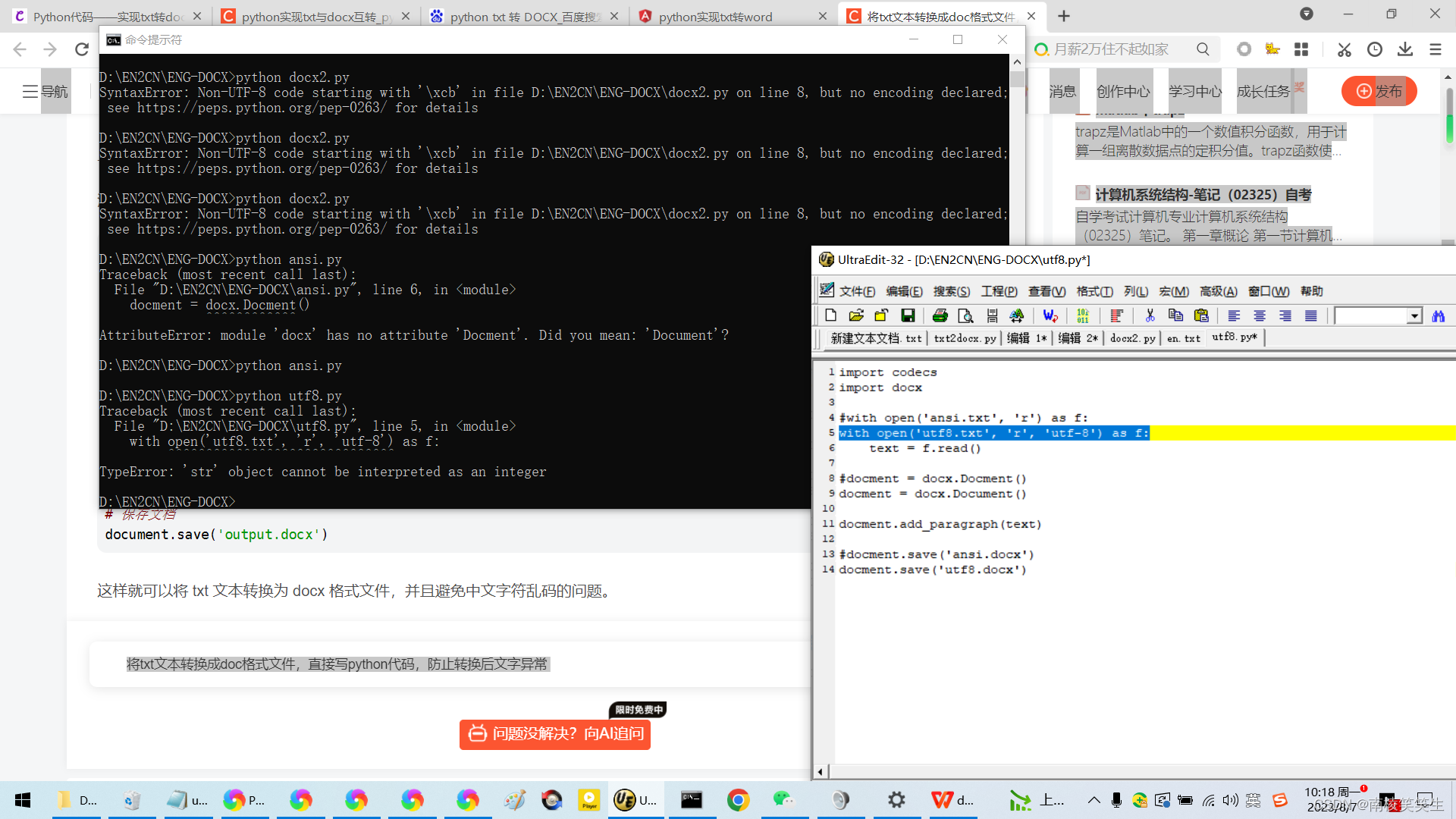



注意,如果 txt 文件中包含中文字符,可能会出现乱码问题。这时可以使用 codecs 库来解决这个问题:
import codecs
import docx
# 读取 txt 文件,使用 codecs 库的 open 方法,指定编码为 utf-8with codecs.open('input.txt', 'r', 'utf-8') as f:
text = f.read()
# 创建一个新的 docx 文档
document = docx.Document()
# 将 txt 文本写入文档
document.add_paragraph(text)
# 保存文档
document.save('output.docx')复制代码
这样就可以将 txt 文本转换为 docx 格式文件,并且避免中文字符乱码的问题。
#docment.save('ansi.docx')
import codecs
import docx
with codecs.open('utf8.txt', 'r', 'utf-8') as f:
text = f.read()
#docment = docx.Docment()
docment = docx.Document()
docment.add_paragraph(text)
docment.save('utf8.docx')
D:\ENG2DOCX>
D:\ENG2DOCX>
D:\ENG2DOCX>dir
驱动器 D 中的卷是 DATA
卷的序列号是 547F-1046
D:\ENG2DOCX 的目录
2023/08/07 18:06 <DIR> .
2023/08/07 18:06 <DIR> ..
2023/08/07 18:03 47,533 ansi.docx
2023/08/07 18:02 186 ansi.py
2023/08/07 13:03 26,294 ansi.txt
2022/12/15 10:46 26,297 Ch4.Unreported.World.2022.Mexicos.Psychedelic.Toads.1080p.HDTV.x265.AAC.MVGroup.org_track3_eng.srt
2023/08/07 18:06 26,294 docx2ansi.txt
2023/08/07 18:09 217 utf8.py
2023/08/07 10:17 26,294 utf8.txt
7 个文件 153,115 字节
2 个目录 272,315,310,080 可用字节
D:\ENG2DOCX>
D:\ENG2DOCX>
D:\ENG2DOCX>python utf8.py
D:\ENG2DOCX>dir
驱动器 D 中的卷是 DATA
卷的序列号是 547F-1046
D:\ENG2DOCX 的目录
2023/08/07 18:12 <DIR> .
2023/08/07 18:12 <DIR> ..
2023/08/07 18:03 47,533 ansi.docx
2023/08/07 18:02 186 ansi.py
2023/08/07 13:03 26,294 ansi.txt
2022/12/15 10:46 26,297 Ch4.Unreported.World.2022.Mexicos.Psychedelic.Toads.1080p.HDTV.x265.AAC.MVGroup.org_track3_eng.srt
2023/08/07 18:06 26,294 docx2ansi.txt
2023/08/07 18:12 47,746 utf8.docx
2023/08/07 18:09 217 utf8.py
2023/08/07 10:17 26,294 utf8.txt
8 个文件 200,861 字节
2 个目录 272,315,260,928 可用字节
D:\ENG2DOCX>


http://huijobs.cn/article/article-detail/11600/
python实现txt转word
2022年11月17日 23:06
def TXTRead_Writeline():
ms=open("./file/test.txt") #读取文件
for line in ms.readlines(): #逐行写入
with open("./file/test.doc","a") as mon:
mon.write(line)
TXTRead_Writeline()
LOG:
Type "help", "copyright", "credits" or "license" for more information.
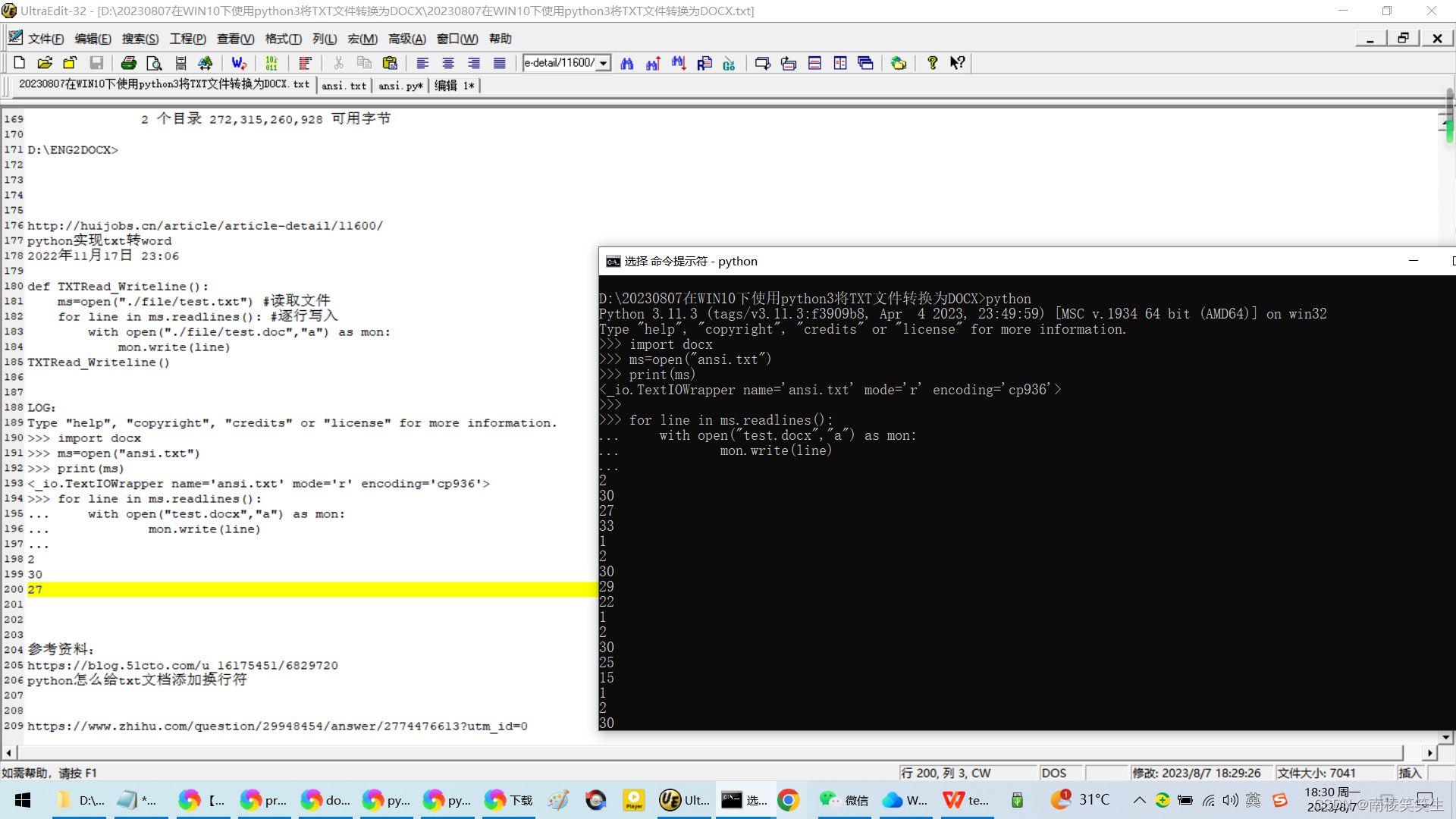
>>> import docx
>>> ms=open("ansi.txt")
>>> print(ms)
<_io.TextIOWrapper name='ansi.txt' mode='r' encoding='cp936'>
>>> for line in ms.readlines():
... with open("test.docx","a") as mon:
... mon.write(line)
...
2
30
27
test.py【将ANSI编码的TXT可以转换为DOC或者DOCX】
import docx
ms=open("ansi.txt")
#print(ms)
for line in ms.readlines():
#with open("test.doc","a") as mon:
with open("test.docx","a") as mon:
mon.write(line)
参考资料:
https://blog.51cto.com/u_16175451/6829720
python怎么给txt文档添加换行符
https://www.zhihu.com/question/29948454/answer/2774476613?utm_id=0
请问python怎么做到在写入的TXT中换行?
line = line.strip('\n')
https://blog.csdn.net/u010565244/article/details/19193635
关于python 的line.strip()方法
python utf-8 txt 转 DOCX 多一个换行
【貌似有道理,但是没有实现】
https://www.jianshu.com/p/7307262a6197
使用python批量转换编码时多余换行的问题
最近使用python批量将项目中的GBK编码文件转换为UTF8时遇到了会自动给每一行结尾多添加一个换行符的问题这样会导致多行宏命令失效
原因是使用文本读写模式 ‘w’ ‘r’
修改为使用 ‘wb’ ‘rb’ 使用二进制接收在使用utf8编码为str然后以二进制方式写入就可以了
python write 换行
python txt 转 DOCX
Python TXT 转 DOCX 多换行
python utf8转gbk
https://blog.csdn.net/qq_40845077/article/details/124872708
Python代码——实现txt转docx
https://blog.csdn.net/qq_40837206/article/details/130323856
python实现txt与docx互转
https://codeleading.com/article/62046304563/
Python代码——实现txt转docx
https://blog.csdn.net/qq_33005553/article/details/124755791
python 去除 txt文本换行
python 递归读取
https://blog.51cto.com/love51/6389966
python递归获取文件 python 递归文件夹
https://www.bilibili.com/read/cv13745103/
Python代码——实现txt转docx
https://zhuanlan.zhihu.com/p/564678085
Python txt文件转word 格式