大家可能都用过APM监控,包括开源的Skywalking、商用的卓豪(ZOHO)ManageEngine APM应用性能监控、以及云监控产品如听云(Server监控),这些APM监控产品大大方便了我们实时监控应用性能,并实现性能深度透视监控。
但是这些监控手段离真正能够定位性能问题还是有一段距离,有时候可能就差这最后1米的距离,只能找资深开发人员介入定位分析,有些开发人员还真没这水平。但其实我们用好了工具,任何人都可以参与定位分析,甚至不用依赖开发人员就能找到问题所在,换句话说,测试人员不需要去深度定位分析问题,但至少要找到和开发人员沟通的桥梁吧,你把APM监控的结果发给开发人员,直接做个甩手掌柜,你信不信,开发人员可能看都不看,直接说那不是他的代码问题,可能是环境或配置问题,因为确实可能真不是他的问题,再说了,你会用APM监控工具,开发人员不一样会用,用的比你还溜,靠工具不是真本事,会用好工具才是真本事(同时你还能结合业务去思考和应用,这是开发人员不具备的)。
一、APM监控可以告诉你慢的方法名
说到web响应慢,有很多方法能够监控,比如我们用浏览器自带的开发者工具就行,像谷歌浏览器通过F12,查看network就能看响应时间,就拿我最近测试的一个系统当中的导出功能来实验:

可以看到导出的请求,响应时间12.4秒,大部分时间花在等待服务器响应,这时候我们会说这个接口请求很慢,但我们无法知道慢的方法名,因为我们最多就捕获到了请求接口:

通过性能测试工具如JMeter,也一样的道理,我们只知道哪个请求哪个接口慢,不知道哪个方法调用慢,但通过APM监控就可以知道这个慢请求的方法,包括方法名和入口参数名:

通过APM监控的慢事务分解,我们能看到方法名是com.nfschina.controller.ExportController,其入口参数是exportLoophole
二、APM监控无法看到多层次的调用逻辑
看到了入口方法,我们肯定想知道下一层的方法是什么,想进一步深度探索,这在大部分的APM监控是做不到了,比如我们就看事务的慢组件分解,如下所示:
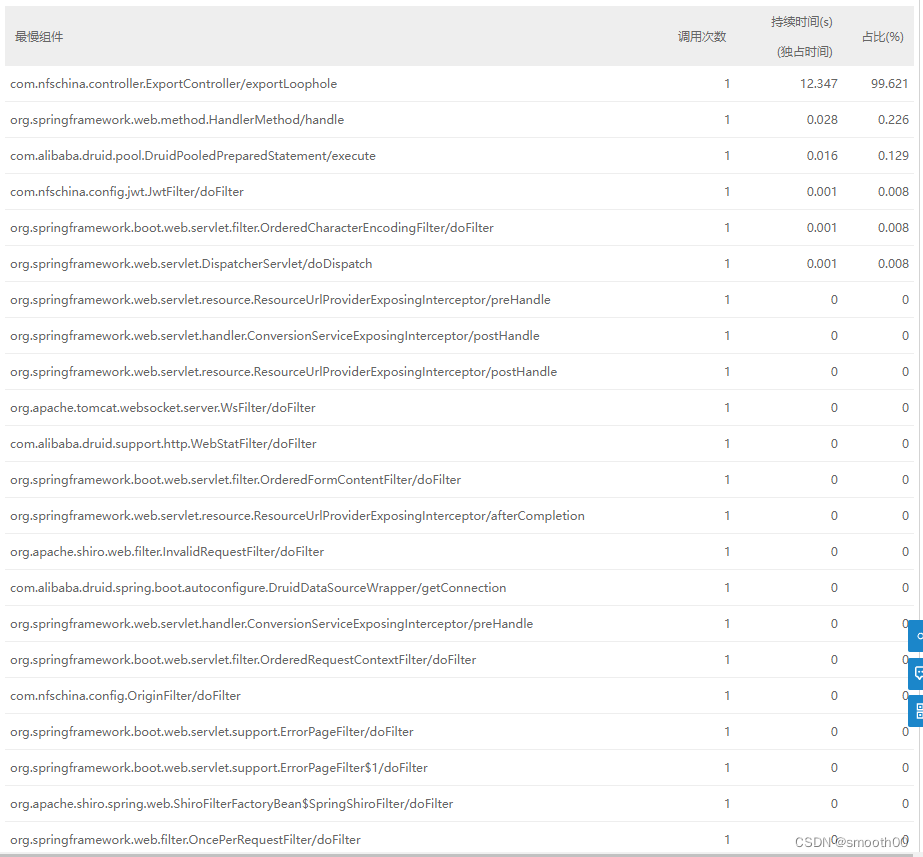
这个表能看出com.nfschina.controller.ExportController的方法多层调用吗?什么也看不出来,只是列出了方法调用的第一层方法链,ExportController为什么慢,还是根本不知道,不过这里还是能排除慢SQL问题(通过PreparedStatement/execute执行时间),至于代码为什么慢的问题是看不出来的,因为这只是第一层代码调用关系。
三、利用Arthas进行深度追踪
虽然我们作测试时,不能直接定位到性能慢的原因,但至少可以给开发人员提供慢事务的方法名,以及平均响应时间数据,本身也是价值很大。开发得到这些数据,就可以进一步定位分析。同样我们测试人员也可以尝试用开发的工具去进一步定位分析,比如Arthas:
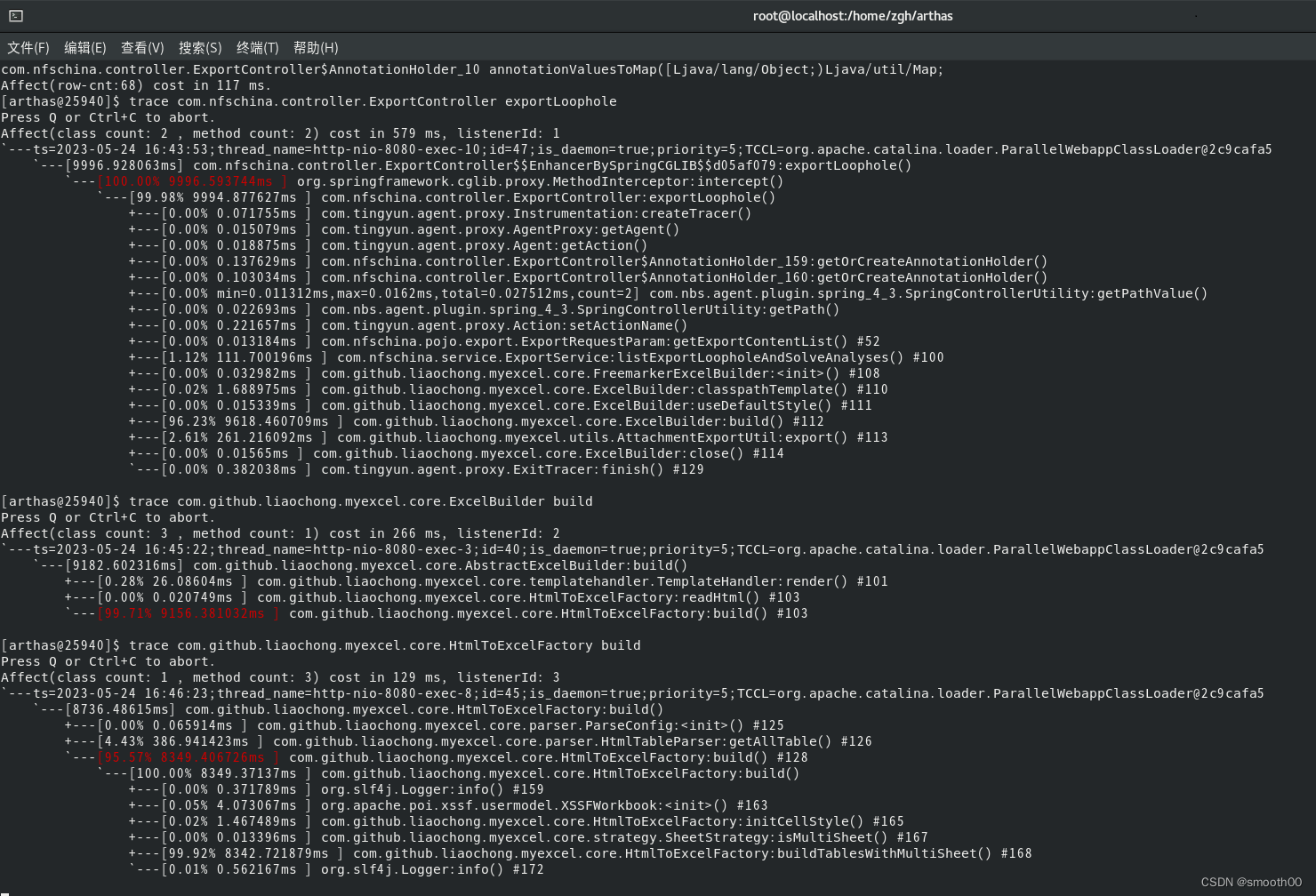
如上图,我们第一步,通过 trace com.nfschina.controller.ExportController exportLoophole追踪到了慢的方法com.github.liaochong.myexecl.core.ExcelBuilder,到这里就可以判断出慢的组件是myexcel,我们再一步步深入追踪:
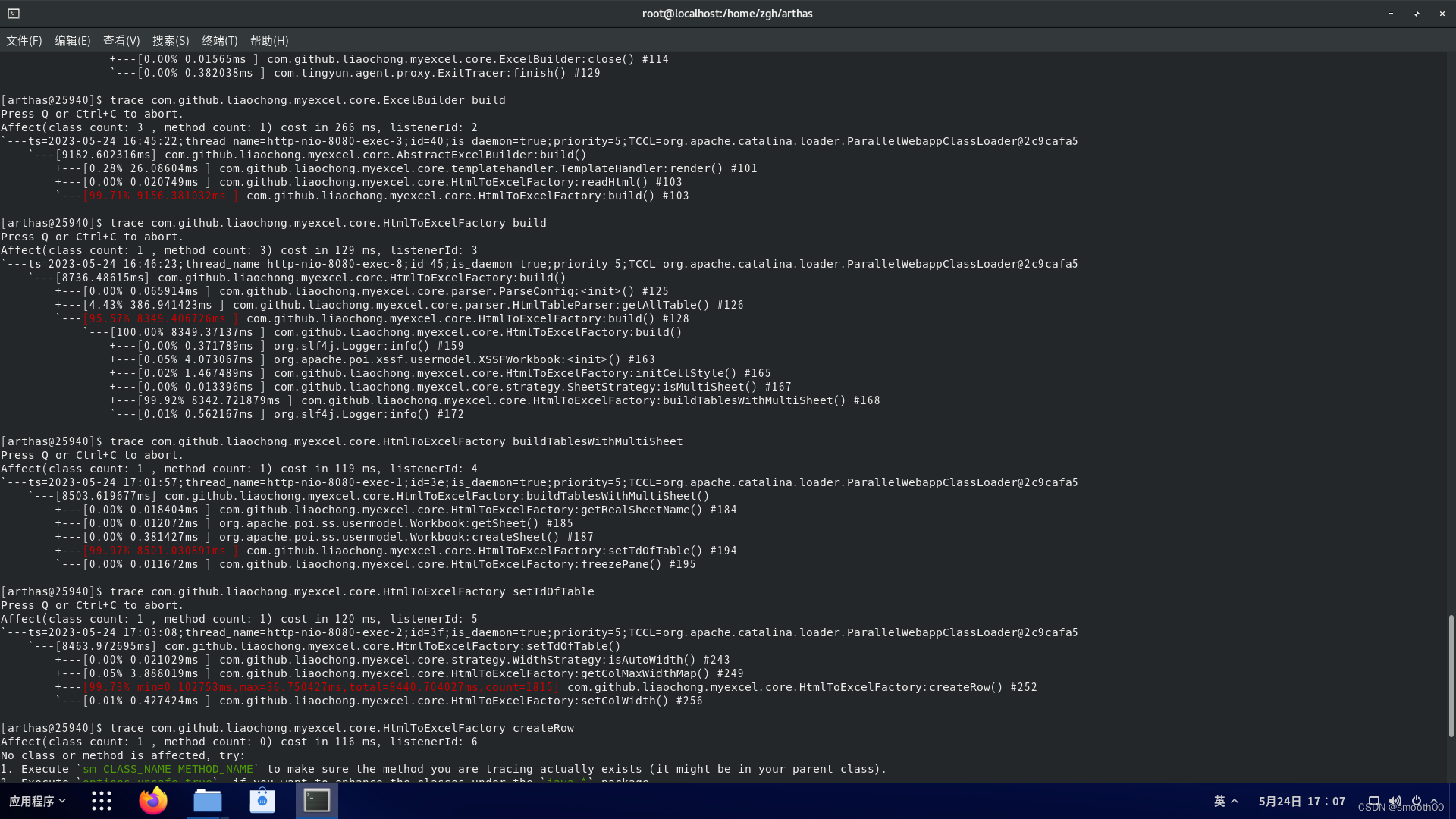
最后我们追踪到是myexcel组件的createRow方法慢(响应时间占99.73%),其实就是mysql的数据导成excel创建table行数据很慢。
四、利用Arthas进一步获取异常信息
APM监控除了能捕获慢事务方法,还可以捕获异常信息的方法,如下所示:

通过监控,我们可以看出错误方法的名称及传参,并且抛出的异常信息是CustomException,如果我们觉得不够清晰,其实我们还可以用Arthas进一步查看和追踪异常信息,如下:

其实这只是个思路,因为Java的异常信息可能也是一层层上抛的,所以通过Arthas的命令是可以一层层的去追踪报错信息。
五、Arthas并不是万能的
通过上面的例子,你可能会觉得用Arthas定位Java性能问题简直无所不能,其实不是,引起Java性能问题的因素千种万种,可能就不是你说的那一种,有些问题不是Java代码的问题,但也可能会映射成是Java的代码问题,因为软件架构各式各样,代码之间互相调来调去,再加上环境千差万别,各种因素互相干扰,所以你还要有足够的敏锐度和经验去排查,以下我拿上面报异常的方法做个例子,这个方法之所以报异常,其实是和性能不稳定也有关,有时候响应很快,不到300ms,有时候很慢,高于15s,甚至直接报异常了。我们通过arthas反复一层层trace,去找到慢的原因:
1、首先我通过APM监控获取它的慢方法名

2、然后开始arthas追踪获取下一层慢方法
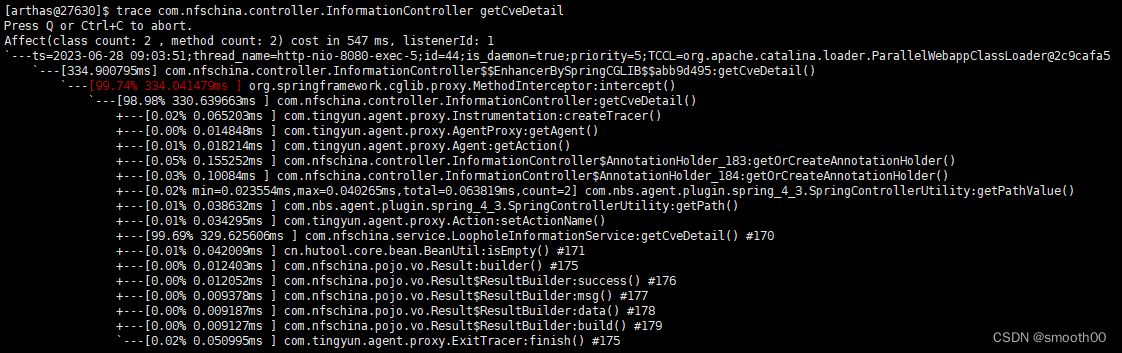
3、继续一层层往下追踪


4、不要一味的穷尽trace
当我们trace到这一步是,发现好像跟IO读取有关了,如下所示:

这时候我们就要思考了,这个业务是属于IO占用高的事务吗?显然不是呀,这只是个通过漏洞CVE编码去官网获取漏洞详情事务的请求,请求和获取的数据量都很小,也不需要去查询SQL。这时候我们就要排除是否Java代码的问题,因为不排除的话,这样一直trace下去就会越来越迷茫,因为都超出正常业务代码的范围了。另外就算是IO问题或网络问题,这也要涉及到和其他监控工具结合监控,比如通过查看服务器找找哪个进程线程占用IO高,总之,思路也得转变了。
基于我对这个业务的了解,我判断不太可能是简单的IO问题,我们首先思考这个方法除了Java代码本身,还有没有调用第三方的东西。通过从开发那了解到,这个业务其实是调用一个工具去第三方的网站爬取数据,这个工具是用go语言写的,和Java没关。所以我们花大把时间在这用arthas去追踪Java的性能问题,根本是在浪费时间。以上只是举个例子,就是告诉我们无论什么时候,都要有独立的判断能力,不能沉浸于工具带给我们的方便,而放弃了思考。
既然,找到了是这个go语言写的小工具的性能问题,那我们就直接调用和测试这个小工具,抛开Java的干扰,同时优化性能也可以从Java语言转移到这个golang小工具了,以下是通过JMeter对这个小工具的测试报告(单用户测试),发现确实是性能不稳定:
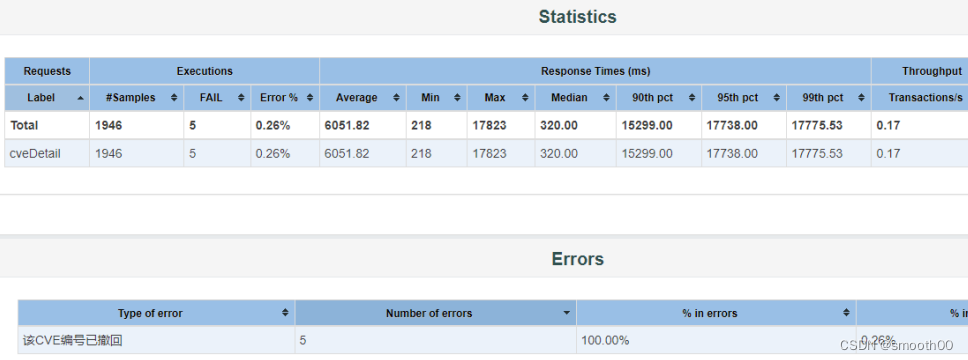
响应时间波动非常大:

在单用户下,性能就如此不稳定,由于这个golang小工具,还会到漏洞官网去爬取数据,所有我们直接用JMeter按同样的逻辑去官网爬取数据(绕开这个工具),看看网站性能如何:

性能很高,两个接口加起来平均也不到200ms,再看响应时间波动和网络流量,都不大(响应时间有较大抖动,但最大响应时间都不高),如下所示:
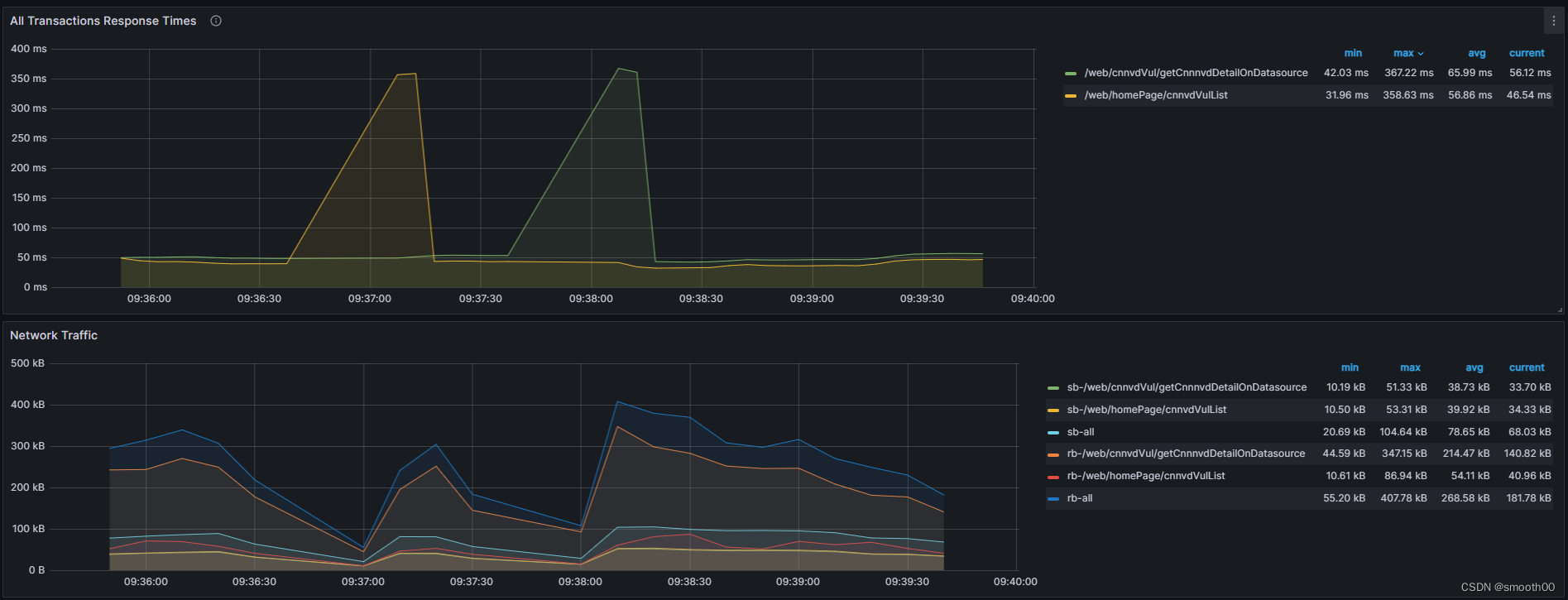
说明,golang小工具爬取数据的性能很不稳定,不是和网站页面请求及网络性能有关,是它自身的性能问题(当然是否触发防爬取也需要考虑),通过排除法也可以告知开发人员,应该好好对这个golang写的小工具进行性能定位分析,由于本篇讲的是APM监控+Arthas定位分析问题,至于定位分析golang就需要用到别的工具,如pprof,本篇就不继续展开说明了。