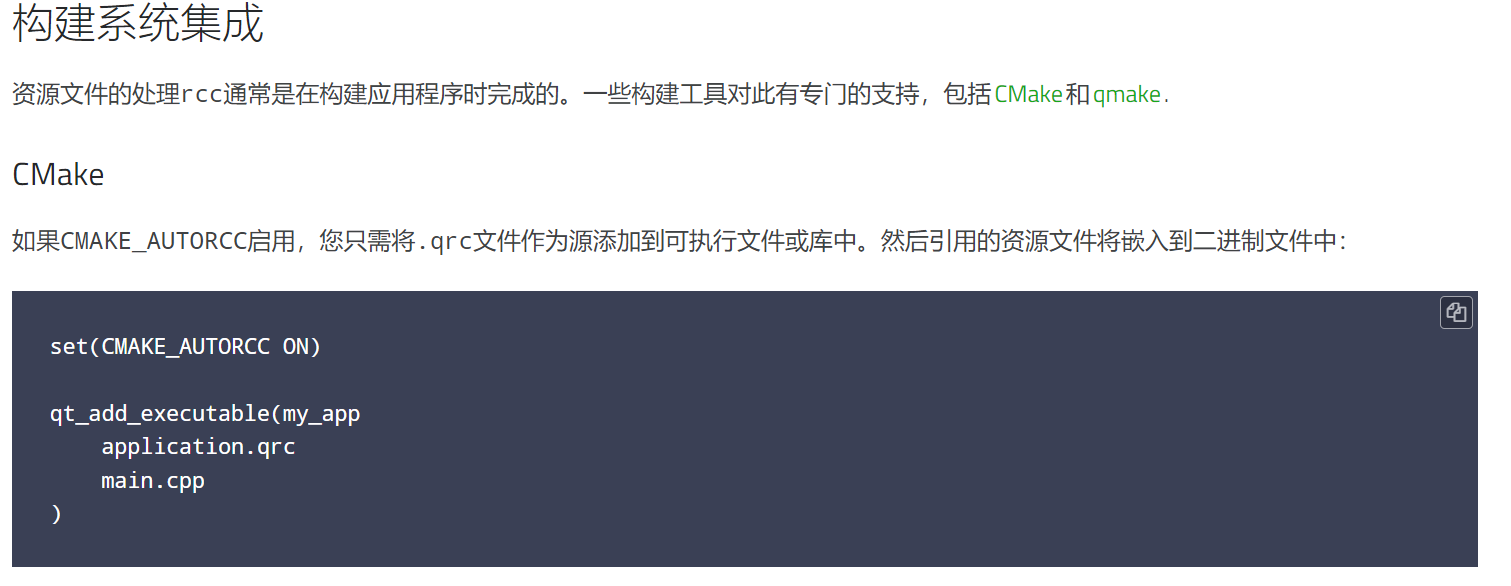
实验记录
注意,我为了让线性注意力在 fp16-mix 中稳定训练,作为以下修改。
输入线性注意力前,q 和 k 均做了以下操作
q = q / torch.norm(q, dim=-1, keepdim=True)
k = k / torch.norm(k, dim=-1, keepdim=True)
把 SRmsNorm 替换为普通的 RmsNorm(中幅度增加Loss下降速度)
图取自TransnormerLLM论文
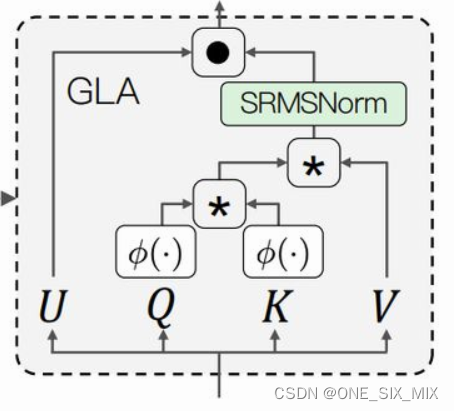
记录
试验模型为 PF7b,hidden_dim=1024,head=12,head_dim=64,ffn_dim=2048,ffn=SwiGLU,layer=24
epoch=40,每轮有8000次迭代
余弦退火学习率调整,max_lr=1e-4,min_lr=1e-6
最大训练序列长度 512
思考
联合以下的情况1和情况2,这个情况有点像 StyleGAN v1 遇到的那种图里有水滴样畸变的问题。
注意力层中产生了一个很大异常值,然后在RmsNorm时,使对应维度 weight 偏向 0 来消除异常值
情况1
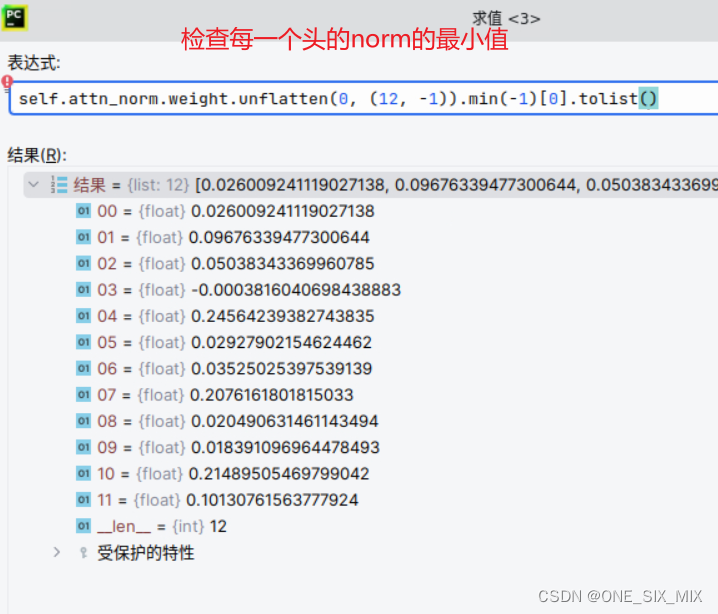
RmsNorm 中 weight 的情况,前几层有这样的情况,每个头都有一个偏小的值。
这可能是 SRmsNorm 收敛慢的原因?
但是越往后面, weight 反而趋向正常。
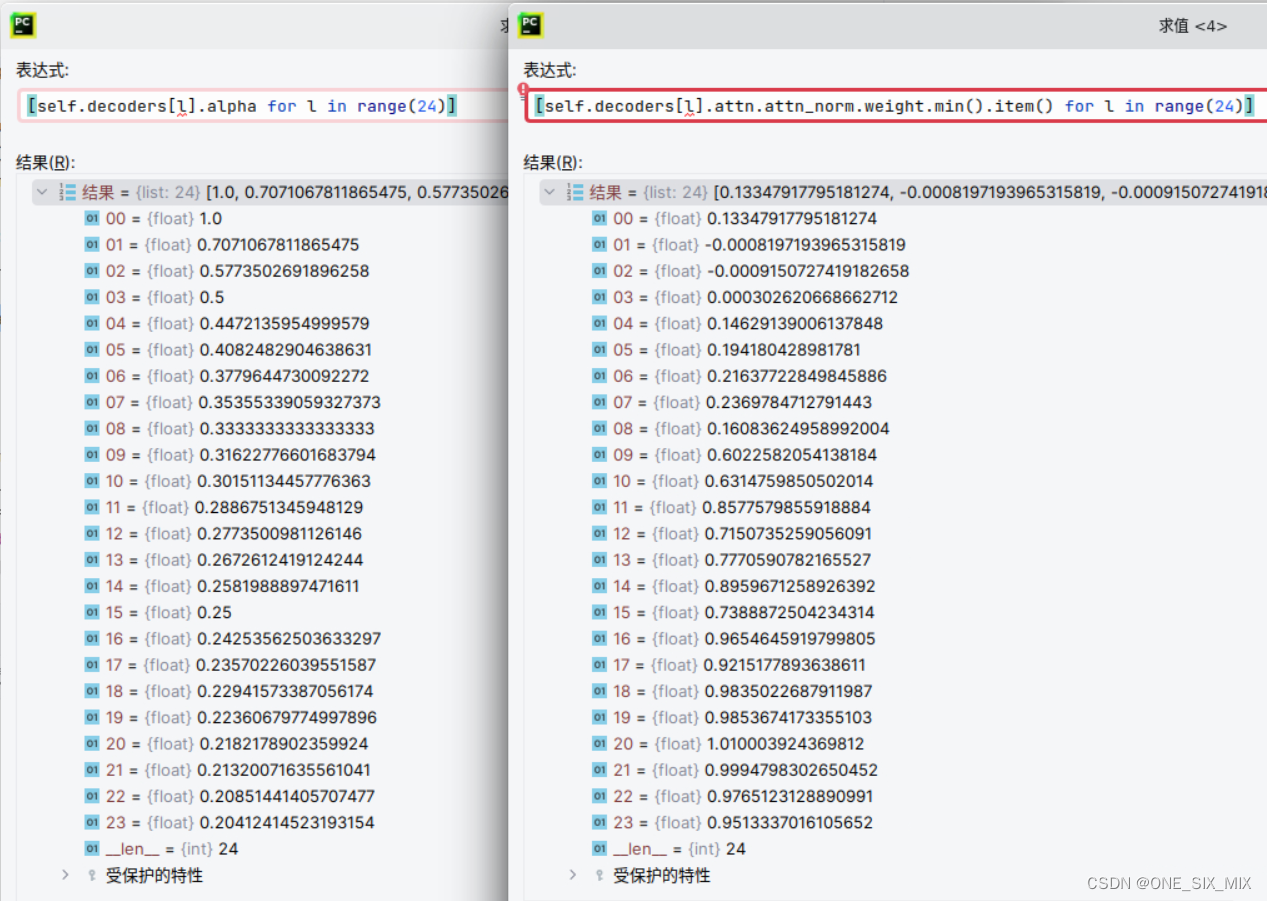
alpha 为每层的残差缩放值,y = y + alpha * F(x)
图中为两个不同层的 注意力正则化层的 weight,可以看到有12个明显偏小的值
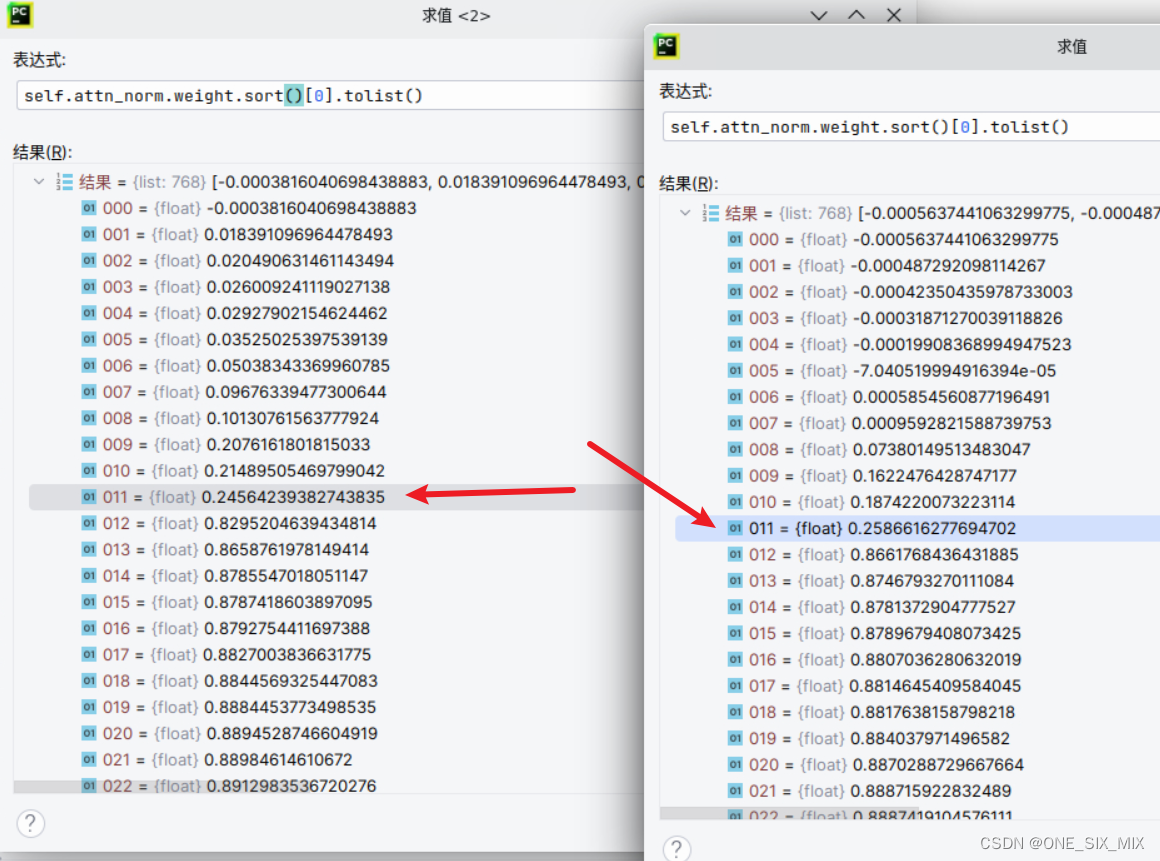
这是第二层的 注意力正则化层,reshape 为12个头,检查每个头weight 的最小值
左边为每层的残差缩放,右边为每层的注意力正则化层的最小值变化情况。
情况2
(这个似乎在原始注意力里面也有类似的情况,但是因为softmax算子,A矩阵大部分地方为趋向0,没有这么严重)
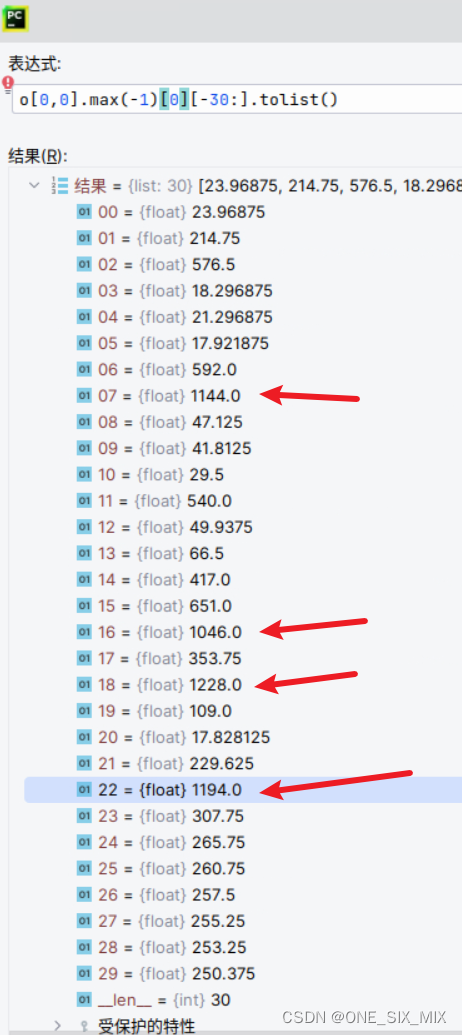
序列越长,出现的概率越大,O = A @ V 的 O 里面会出现个别的很大的值,大于1000,如果序列再长2-4倍(例如1024-2048),可能会有值过大,让精度过低,导致太长的地方收敛困难,和LongEval评分很差。
这好像也没啥好办法。矩阵连加堆起来的大值



![[SWPUCTF 2022 新生赛]numgame](https://img-blog.csdnimg.cn/a8bce61e72ad4002ab5967e0bf9352a3.png)