pre 前言
这里使用聚合模型,可以在导入数据的时候,就将部分数据做预处理,提高查询效率。
同样,因为是预处理,因此,数据细节会丢失。
1, 建表语句
create table if not exists user_landing_record_new
(
`company_id` LARGEINT NOT NULL COMMENT '公司id',
`user_id` LARGEINT NOT NULL COMMENT '用户id',
`user_name` VARCHAR(255) COMMENT '用户名',
`statistical_time` DATE NOT NULL COMMENT '统计时间',
`day_succ_login_count` LARGEINT SUM DEFAULT "0" COMMENT '按天统计登录成功次数',
`last_login_date` DATETIME REPLACE COMMENT '最后一次登录时间'
)
AGGREGATE KEY(`company_id`,`user_id`,`user_name`,`statistical_time`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES(
"replication_allocation" = "tag.location.default: 1"
)1.1关键点解释
表中的列按照是否设置了
AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置AggregationType的,如company_id、user_id、user_name... 等称为 Key,而设置了AggregationType的称为 Value。
常见的 AggreagationType 有
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
1.2 sql 说明
结合上述描述,文章开始的建表表示,需要统计按公司、人员统计每天的登录次数以及该人员最后一次登录次数。
2,数据导入
源数据在 mysql 中,因此采用 datax 进行数据导入。但由于之前表中,主键是字符串,所以,暂时无法用 datax 的splitPk属性,进而无法使用多通道技术。
datax 中转换 json 如下
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"xxxxx"
],
"querySql": [
"select company_id, user_id, user_name, date_format(login_date,'%Y-%m-%d') as statistical_time, sussess_or_fail as day_success_login_count, login_date as last_login_date from r where company_id is not null and user_id is not null order by company_id,user_id,login_date asc"
]
}
],
"username": "",
"password": "",
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"loadUrl": [""],
"loadProps": {
},
"column": [
"company_id","user_id","user_name","statistical_time","day_success_login_count","last_login_date"
],
"username": "",
"password": "",
"flushInterval":30000,
"connection": [
{
"jdbcUrl": "",
"selectedDatabase": "",
"table": ["f"]
}
],
"loadProps": {
"format": "json",
"strip_outer_array": true
}
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
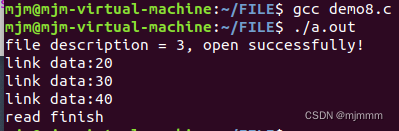
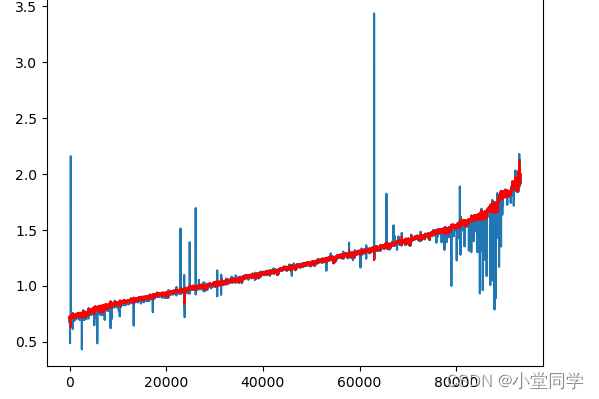
3,结果展示
导入速率

最终结果
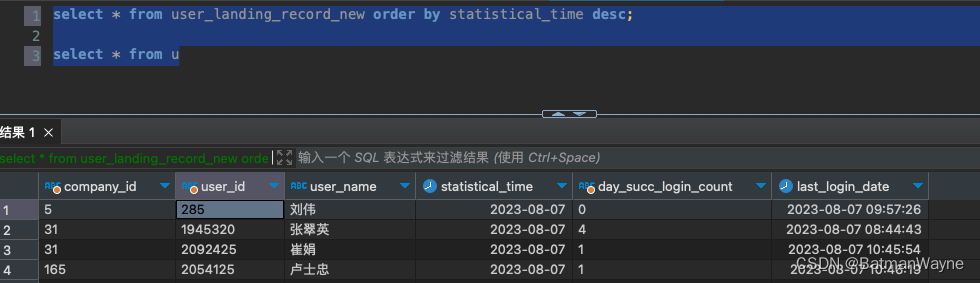
因为是按天聚合,因此,最后登录时间也是统计那天的最后一次登录时间。