简介
locust 是 Python 的一个开源的负载测试工具,用于测试网络应用程序的性能和可伸缩性。它使用Python编写,并提供了一个简单易用的语法来定义和执行负载测试。locust模块允许用户模拟大量并发用户并观察系统在高负载下的响应情况。
目录
1. 基本用法
1.1. 基础代码
1.2. 执行方法
1.2.1. web 界面执行
1.2.2. 命令执行
2. 多用例调度
2.1. 数据关联
2.1.1. 自定义辅助方法
2.1.2. 自定义初始操作
2.1.3. 任务依赖方法
2.2. 执行顺序
2.3. 线程分配
3. 分布式压测
1. 基本用法
1.1. 基础代码
from locust import HttpUser, task, between
class MyUser(HttpUser):
# 设置用户在执行任务时等待 1~3 秒
wait_time = between(1, 3)
@task #标记为测试任务
def test1(self):
# 发送 get 请求
response = self.client.get('xxx')
# 通过状态码来断言
assert response.status_code == 200
post 请求方法
data = {"username": "yt", "password": "123456"}
self.client.post("xxx", json=data) # 发送POST请求到指定URL,并附带JSON数据get 带头部信息
headers = {"Authorization": "yt token123"}
self.client.get("xxx", headers=headers) # 发送带头部的GET请求
1.2. 执行方法
1.2.1. web 界面执行
1、执行命令
locust -f 文件
2、通过提示的地址打开浏览器
提示地址:http://0.0.0.0:8089

把 0.0.0.0 改成 localhost
http://localhost:8089/

3、查看结果
大项选择

统计数据(Statistics)
- Requests:总请求数
- Fails:总失败数
- Median (ms):中位数响应时间(将所有观察值按从小到大排序后,正好处于中间位置的值)
- 90%ile (ms):90% 的响应时间(有 90% 的请求的响应时间小于或等于该值)
- 99%ile (ms):99% 的响应时间(有 99% 的请求的响应时间小于或等于该值)
- Average (ms):平均响应时间
- Min(ms):最小响应时间
- Max(ms):最大响应时间
- Average size (bytes):请求返回的平均响应内容大小
- Current RPS:当前的每秒请求数
- Current Failures/s: 当前每秒失败请求数

图表信息(Charts)
每秒总请求数(Total Requests per Second)
- RPS:当前请求数
- Failures/s:当前失败数
响应时间(Response Times (ms))
- Median Response Time:中位数响应时间
- 95% percentile:95% 的响应时间
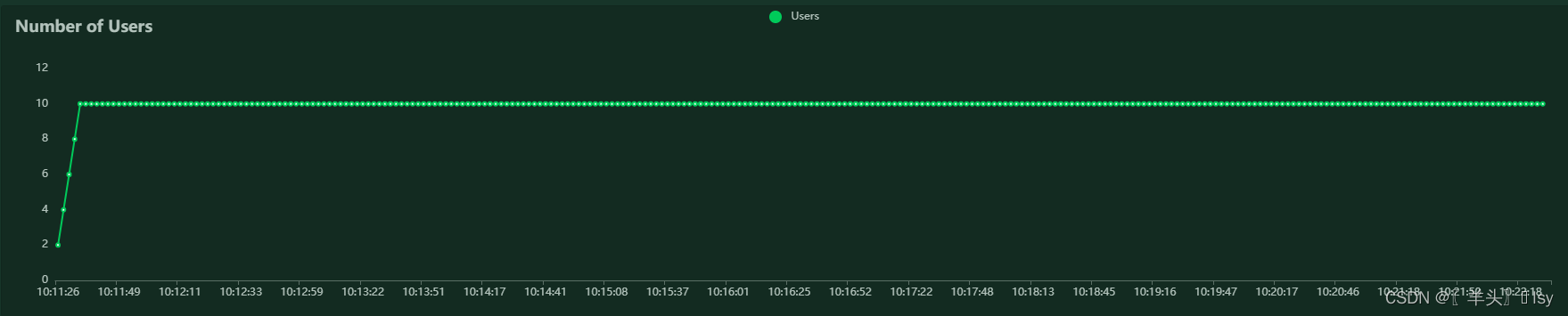
用户数(Number of Users)


1.2.2. 命令执行
常用参数选项
-f:指定Python测试文件
-H:设置主机地址
-u:设置用户数
-r:每秒生成n个用户
-t:指定测试时长(例如:300s, 20m, 3h, 1h30m)
-P:指定web界面端口
-l:显示可能的User类列表并退出web UI 参数选项
--web-host:要绑定web接口的主机。默认为'*'(所有接口)
--web-port:指定web界面端口
--headless:不使用web界面测试,直接启动测试
--autostart:直接启动测试,不禁用web
--autoquit:执行运行结束后n秒完全退出。只能与——autostart一起使用。默认情况下,在使用CTRL+C关闭Locustl之前,它将一直运行
--web-auth:打开web界面的基本验证。基本格式为 username:password
--tls-cert:用于通过HTTPS提供服务的TLS证书的可选路径
--tls-key:用于通过HTTPS提供服务的TLS私钥的可选路径分布式压测选项
--master:将locust设置为以分布式模式运行,并将此进程设置为主进程
--master-bind-host:master绑定的接口(主机名、ip)(默认:*(所有可用接口))
--master-bind-port:locust绑定的端口(默认:5557)
--expect-workers:在开始测试之前(仅当使用——headless/autostart时),master应该连接多少worker
--expect-workers-max-wait:主节点等待备节点的时间(默认:永远等待)
--worker:将locust设置为以分布式模式运行,并将此进程作为辅助进程
--master-host:指定主机或IP地址(默认:127.0.0.1)
--master-port:指定要连接的端口。默认为5557。输出信息选项
--html:将HTML报告存储到指定的文件路径
--csv:以CSV格式将当前请求状态存储到文件中
--csv-full-history:将每个统计条目以CSV格式存储到统计历史记录中。必须指定'--csv'
--print-stats:在控制台中打印统计信息
--only-summary:仅打印摘要统计信息
--reset-stats:开始之前重置所有的统计数据(包括请求数、响应时间等),分布式需要同时设置主备。
该参数主要用于在连续运行多个测试场景时,确保每个测试都从零开始计算统计信息,以避免之前的数据对当前测试的影响。输出日志选项
--skip-log-setup:禁用locust的日志设置,由Locust测试或Python默认值提供。
--loglevel:设置日志级别(默认:INFO),可选 DEBUG、INFO、WARNING、ERROR、CRITICAL
--logfile:指定日志文件的路径。如果没有设置,日志将转到stderr
直接使用命令执行
locust -f tmp1.py --host=abc --headless -u 10 -r 1 -t 10s- -f:指定测试文件 tmp1.py
- --host:指定访问地址(代码中已写死地址,这里随便写都行)
- --headless:禁用web,直接测试
- -u:设置10个总用户数
- -r:每秒增加1个用户
- -t:总共执行10秒
将命令放入 Python 文件
import os
if __name__ == '__main__':
file_path = os.path.abspath(__file__)
os.system(f'locust -f {file_path} --host=abc --headless -u 1 -t 1s')
2. 多用例调度
2.1. 数据关联
2.1.1. 自定义辅助方法
方法结构

代码如下
from locust import HttpUser, task
class MyUser(HttpUser):
# 定义一个空的token
token = ""
'''定义测试用例'''
@task
def test1(self):
# 先调用登录方法
self.login()
# 再调用查询信息的方法
self.query_information()
'''定义登录方法'''
def login(self):
# 使用post请求登录界面
response = self.client.post("/login", json={"username": "yt", "password": 123456})
# 获取登录的token值
self.token = response.json()["token"]
'''定义登录之后的查询信息'''
def query_information(self):
# 通过登录方法获取的token值,组成headers
headers = {"Authorization": f"yt {self.token}"}
# 查询个人信息
self.client.post("xxx", headers=headers, json={"data": "data"})
2.1.2. 自定义初始操作
方法结构
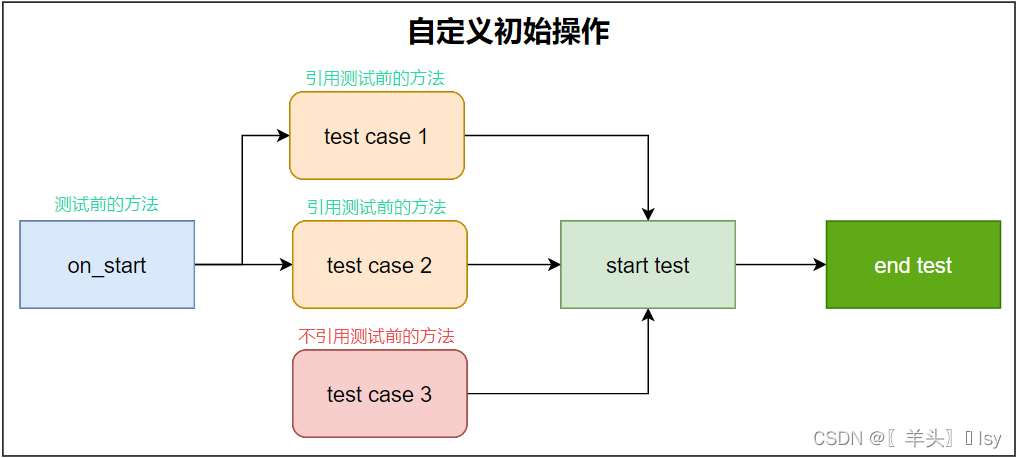
代码如下
from locust import HttpUser, task
class MyUser(HttpUser):
# 定义一个空的token
token = ""
"""定义一个开始方法,on_start是固定名称"""
def on_start(self):
# 在测试前进行登录,并获取token值
response = self.client.post("/login", json={"username": "yt", "password": 123456})
self.token = response.json()["token"]
"""封装测试用例"""
@task
def test1(self):
# 通过测试前获取的token代入headers
headers = {"Authorization": f"yt {self.token}"}
# 执行post请求测试
self.client.post("xxx", headers=headers, json={"data": "data"})
2.1.3. 任务依赖方法
方法结构

代码如下
from locust import HttpUser, task
class MyUser(HttpUser):
# 定义一个空的token
token = ""
"""定义一个登录测试方法"""
@task
def login(self):
# 使用post请求登录界面
response = self.client.post("/login", json={"username": "yt", "password": 123456})
# 获取登录token值
self.token = response.json()["token"]
"""定义一个登录后查询信息的方法"""
@task
def query_information(self):
# 通过登录方法获取的token值,组成headers
headers = {"Authorization": f"yt {self.token}"}
# 查询个人信息
self.client.post("xxx", headers=headers, json={"data": "data"})
2.2. 执行顺序
使用 tasks = [ ] 来指定任务函数的执行顺序。任务函数会循环执行,按照列表中的顺序进行调度。
【错误示例】直接使用 HttpUser 方法不能保证顺序
from locust import HttpUser, task
class MyUser(HttpUser):
@task
def test1(self):
print('test1 --登录')
@task
def test2(self):
print('test2 --查询商品信息')
@task
def test3(self):
print('test3 --查看评价')
tasks = [test1, test3, test2]
使用 SequentialTaskSet 方法(从上往下顺序执行)
from locust import HttpUser, task, SequentialTaskSet
class MyUser(HttpUser):
"""定义一个顺序执行的类,方法从上往下的执行"""
@task
class MySequentialTaskSet(SequentialTaskSet):
@task
def test1(self):
print('test1 --登录')
@task
def test2(self):
print('test2 --查询商品信息')
@task
def test3(self):
print('test3 --查看评价')
# 在user类中,指定类的顺序
tasks = [MySequentialTaskSet]
2.3. 线程分配
- 使用 @task 装饰器设置权重(权重为1,执行1次;权重为2,执行2次...)。设置权重后 tasks 指定的顺序将会受到影响。
示例(测试前登录,登录后多次调用其他方法)
from locust import HttpUser, task
class MyUser(HttpUser):
"""测试前调用登录方法"""
def on_start(self):
self.test1()
"""封装一个登录方法"""
def test1(self):
print('test1 --登录')
"""封装一个查询商品信息的方法"""
@task(3) # 设置权重为3,执行3次
def test2(self):
print('test2 --查询商品信息')
"""封装一个查看评价的方法"""
@task(5) # 设置权重为5,执行5次
def test3(self):
print('test3 --查看评价')
"""指定执行顺序,基本无效"""
tasks = [test2, test3]
使用 SequentialTaskSet 方法指定顺序,并设置权重
from locust import HttpUser, task, SequentialTaskSet, TaskSet
class MyUser(HttpUser):
"""定义一个顺序执行的类"""
@task
class MySequentialTaskSet(SequentialTaskSet):
@task(1) # 执行1次
def test1(self):
print('test1 --登录')
@task(5) # 执行5次
def test2(self):
print('test2 --查询商品信息')
@task(3) # 执行3次
def test3(self):
print('test3 --查看评价')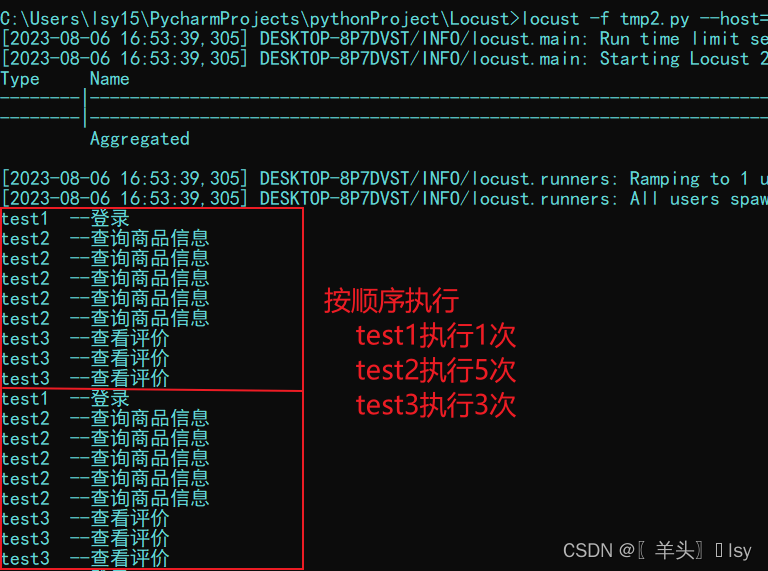
3. 分布式压测
方法简单,步骤如下
- 编写 locust 脚本 → 主节点执行 → 从节点执行 → web 端启动
1、编写 locust 脚本(根据实际情况写,方法同上示例)
2、主节点启动 locust 100个线程
locust -f <Python文件> --master --users 1003、从节点启动 locust 50个线程
locust -f <Python文件> --slave --master-host=<主节点的IP> --clients 504、登录 web 界面执行即可(见目录 1.2.1)