本期分享一个Kaggle上playground系列多变量回归问题的第一名解决方案。试着分析、复现、学习一下金牌选手的数据分析思路。
赛题链接:
Prediction of Wild Blueberry Yield | Kaggle![]() https://www.kaggle.com/competitions/playground-series-s3e14第一名解决方案链接:
https://www.kaggle.com/competitions/playground-series-s3e14第一名解决方案链接:
[PS S3E14, 2023] First place winning solution | Kaggle![]() https://www.kaggle.com/code/sergiosaharovskiy/ps-s3e14-2023-first-place-winning-solution
https://www.kaggle.com/code/sergiosaharovskiy/ps-s3e14-2023-first-place-winning-solution
目录
1、数据查看
2、准备工作
3、数据预处理
第二部分是 mattop_post_process 函数的定义
第三部分是 DataProcessor 类的定义
第四部分是 xy_split 函数的定义
4、模型定义
——fit函数——
5、训练
6、第一次后处理:组合
7、第二次后处理
1、数据查看
在得到数据的时候,首先简单的查看一下数据的分布情况,明确一下手里有什么数据以及最后需要得到什么数据。
读取数据查看数据信息及分布:
path_train = 'data/train.csv'
path_test = 'data/test.csv'
train_data_set = pd.read_csv(path_train)
print(train_data_set.describe())
print(train_data_set.info())结果如下:
id clonesize ... seeds yield
count 15289.000000 15289.000000 ... 15289.000000 15289.000000
mean 7644.000000 19.704690 ... 36.164950 6025.193999
std 4413.698468 6.595211 ... 4.031087 1337.056850
min 0.000000 10.000000 ... 22.079199 1945.530610
25% 3822.000000 12.500000 ... 33.232449 5128.163510
50% 7644.000000 25.000000 ... 36.040675 6117.475900
75% 11466.000000 25.000000 ... 39.158238 7019.694380
max 15288.000000 40.000000 ... 46.585105 8969.401840# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 15289 non-null int64
1 clonesize 15289 non-null float64
2 honeybee 15289 non-null float64
3 bumbles 15289 non-null float64
......
15 fruitmass 15289 non-null float64
16 seeds 15289 non-null float64
17 yield 15289 non-null float64
由上可知,我们的 train.csv 中共有18列数据,出去id数据之外,共有17列有用数据,且数据中均为浮点数类型,无空值数据,数据总个数为15289个。依据题意,我们需要基于前16中特征数据来预测第17个‘yiedl'字段的数据,也就是建立一个 16->1 的一个预测模型。
测试样本中test.csv中数据结构与之相同,只是缺少了’yield‘字段数据,其数据个数有10194个。
接下来就来学习一下得分最高的solution。
2、准备工作
该solution使用的编辑器环境为notebook,导入需要的第三方库。
!pip install sklego -q
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm.auto import tqdm
import os
import lightgbm as lgbm
from lightgbm import log_evaluation, early_stopping, record_evaluation
from sklearn import metrics
from sklearn import model_selection, utils
from sklego.linear_model import LADRegression
import warnings
warnings.filterwarnings('ignore')
tqdm.pandas()
rc = {
"axes.facecolor": "#F8F8F8",
"figure.facecolor": "#F8F8F8",
"axes.edgecolor": "#000000",
"grid.color": "#EBEBE7" + "30",
"font.family": "serif",
"axes.labelcolor": "#000000",
"xtick.color": "#000000",
"ytick.color": "#000000",
"grid.alpha": 0.4
}
sns.set(rc=rc)
palette = ['#302c36', '#037d97', '#E4591E', '#C09741',
'#EC5B6D', '#90A6B1', '#6ca957', '#D8E3E2']
from colorama import Style, Fore
blk = Style.BRIGHT + Fore.BLACK
red = Style.BRIGHT + Fore.RED
gld = Style.BRIGHT + Fore.YELLOW
blu = Style.BRIGHT + Fore.BLUE
res = Style.RESET_ALL上述代码中:pandas、numpy、matplotlib为常用的数据分析及可视化第三方库,不多做介绍。seaborn是在matplotlib的基础上开发的数据可视化库。tqdm主要是用于在屏幕打印循环进度。lightgbm是一个组合模型的实现第三方库。sklearn中封装了常用的机器学习的算法、模型、预处理、评价标准等等。sklego也是一个机器学习第三方库,其中封装着很多机器学习模型和方法。
其余部分主要是对可视化的一些颜色进行提前定义。
3、数据预处理
PATH_ORIGIN = '/kaggle/input/wild-blueberry-yield-prediction-dataset/WildBlueberryPollinationSimulationData.csv'
PATH_TRAIN = '/kaggle/input/playground-series-s3e14/train.csv'
PATH_TEST = '/kaggle/input/playground-series-s3e14/test.csv'
PATH_OOFS = '/kaggle/input/s3e14-oofs/pubs'
PATH_SUB = '/kaggle/input/playground-series-s3e14/sample_submission.csv'
def mattop_post_process(preds):
return np.array([min(unique_targets, key = lambda x: abs(x - pred)) for pred in preds])
class DataProcessor:
def __init__(self,
train_data=None,
test_data=None,
combined: bool = False,
verbose: bool = False):
self.origin_data = None
self.train_data = train_data
self.test_data = test_data
self.combined = combined
self.verbose = verbose
def load_data(self):
if self.combined:
#
self.origin_data = pd.read_csv(PATH_ORIGIN).drop(columns='Row#').drop([766])
self.train_data = pd.read_csv(PATH_TRAIN).drop(columns='id')
self.test_data = pd.read_csv(PATH_TEST).drop(columns='id')
if self.verbose:
print(f'{gld}[INFO] Shapes before feature engineering:'
f'{gld}\n[+] train -> {red}{self.train_data.shape}'
f'{gld}\n[+] test -> {red}{self.test_data.shape}\n')
@staticmethod
def fe(df):
return df
def process_data(self):
self.load_data()
self.train_data = self.fe(self.train_data)
self.test_data = self.fe(self.test_data)
if self.combined:
cols = self.train_data.columns
self.origin_data = self.fe(self.origin_data)
self.train_data = pd.concat([self.train_data, self.origin_data])
self.train_data = self.train_data.reset_index(drop=True)
if self.verbose:
print(f'{gld}[INFO] Shapes after feature engineering:'
f'{gld}\n[+] train -> {red}{self.train_data.shape}'
f'{gld}\n[+] test -> {red}{self.test_data.shape}\n')
return self.train_data, self.test_data
def xy_split(tr_df, te_df, target, cols_to_drop=[]):
"""Preprocess the train and test data by dropping the
eliminated columns and separating the target column.
Args:
tr_df: Train dataframe.
te_df: Test dataframe.
target: list of str (target name).
cols_to_drop: list of str (columns to be eliminated).
Returns:
X_tr: X_train dataframe.
y_tr: y_train pd.Series.
te_df: test dataframe.
"""
if cols_to_drop:
X_tr = tr_df.drop(columns=target + cols_to_drop)
y_tr = tr_df[target[0]]
te_df = te_df.drop(columns=cols_to_drop)
else:
X_tr = tr_df.drop(columns=target)
y_tr = tr_df[target[0]]
return X_tr, y_tr, te_df对上述代码进行分析理解,
第一部分是定义文件路径,略过。
第二部分是 mattop_post_process 函数的定义。如下:
def mattop_post_process(preds):
return np.array([min(unique_targets,
key = lambda x: abs(x - pred))
for pred in preds])关于对min函数中key参数的解释,key通常表示一个函数,如下算例可以辅助了解:
print(min([2,3,4,5,6],key = lambda x:(x-1)*2.5))
# 表达对[2,3,4,5,6]这组数据中每个元素的lambda结果后的最小值
# 也即 min[lambda(2),lambda(3),lambda(4),lambda(5),lambda(6)]
# 最小为 lambda(2) 所以使得这个匿名函数最小的元素是2
# 输出 2在理解完min函数中key值的用法之后,式中的unique_targets在后续的代码中会被定义为一个数组,是一个全局已知变量,该函数可以简化为
def mattop_post_process(preds):
return np.array([min(...) for pred in preds])所以,该函数的作用是返回preds每一个元素与unique_target中所有元素距离(差值绝对值)的那个元素,也即寻找对某一个preds相差最小的那个unique_target.。
第三部分是 DataProcessor 类的定义:
整体代码类定义如下:
class DataProcessor:
def __init__(self,
train_data=None,
test_data=None,
combined: bool = False,
verbose: bool = False):
self.origin_data = None
self.train_data = train_data
self.test_data = test_data
self.combined = combined
self.verbose = verbose
def load_data(self):
if self.combined:
#
self.origin_data = pd.read_csv(PATH_ORIGIN).drop(columns='Row#').drop([766])
self.train_data = pd.read_csv(PATH_TRAIN).drop(columns='id')
self.test_data = pd.read_csv(PATH_TEST).drop(columns='id')
if self.verbose:
print(f'{gld}[INFO] Shapes before feature engineering:'
f'{gld}\n[+] train -> {red}{self.train_data.shape}'
f'{gld}\n[+] test -> {red}{self.test_data.shape}\n')
@staticmethod
def fe(df):
return df
def process_data(self):
self.load_data()
self.train_data = self.fe(self.train_data)
self.test_data = self.fe(self.test_data)
if self.combined:
cols = self.train_data.columns
self.origin_data = self.fe(self.origin_data)
self.train_data = pd.concat([self.train_data, self.origin_data])
self.train_data = self.train_data.reset_index(drop=True)
if self.verbose:
print(f'{gld}[INFO] Shapes after feature engineering:'
f'{gld}\n[+] train -> {red}{self.train_data.shape}'
f'{gld}\n[+] test -> {red}{self.test_data.shape}\n')
return self.train_data, self.test_data该类主要分为以下模块:
1、 def __init__(self,train_data=None,test_data=None,combined: bool = False,verbose: bool = False):
类自带的初始化函数,即当这个类实例化一个对象时会执行的函数操作。
本类别中一共定义了五个变量用来创建数据。
self.origin_data 表示原始数据(Kaggle上的原始数据来源,WildBlueberryPollinationSimulationData)
self.train_data 表示训练数据集(主要是从train.csv数据中读取)
self.test_data 表示测试数据即(从test.csv数据中提取)
self.combined bool类型数据,表示是否将原始数据和train.csv数据融合
self.verbose bool类型数据,表示是否将数据集信息输出到屏幕
2、def load_data(self):
此函数的作用即是读取数据文件,将读取的数据保存到类的变量中。如果给的读入原始数据的为真,则将原始数据也读入保存到其中。
3、def fe(df):
类的静态方法(所谓静态方法即不需要对该类进行实例化就能调用的的方法)
该函数返回本身
4、def process_data(self):
处理数据。如果要读入原始数据,则最后将原始数据融入到训练数据中。如果不融入原始数据则就读取train.csv即可。
函数最后返回 训练数据 和 测试数据。(此处的训练数据和测试数据不是训练模型的训练集和测试集)
该类的使用也很简单:
A = DataProcessor(*param) # 设置参数实例化类
train_data,test_data = A.process_data() # 调用方法第四部分是 xy_split 函数的定义:
函数定义如下:
def xy_split(tr_df, te_df, target, cols_to_drop=[]):
"""Preprocess the train and test data by dropping the
eliminated columns and separating the target column.
Args:
tr_df: Train dataframe.
te_df: Test dataframe.
target: list of str (target name).
cols_to_drop: list of str (columns to be eliminated).
Returns:
X_tr: X_train dataframe.
y_tr: y_train pd.Series.
te_df: test dataframe.
"""
if cols_to_drop:
X_tr = tr_df.drop(columns=target + cols_to_drop)
y_tr = tr_df[target[0]]
te_df = te_df.drop(columns=cols_to_drop)
else:
X_tr = tr_df.drop(columns=target)
y_tr = tr_df[target[0]]
return X_tr, y_tr, te_df对于该函数来说,需让传入四个参数:训练数据集、测试数据集、目标列、需要删除的列。
其完成的功能即:对于传入的数据(训练数据集、测试数据集),在删除不需要的数据之后(需要删除的列作为函数的参数传入)。将训练数据集划分为X数据集(也即代码中的X_tr)和y数据集(代码中的y_tr)。
4、模型定义
首先是对LightGBM模型的定义
class LGBMCVModel:
def __init__(self, cv, **kwargs):
self.cv = cv
self.model_params = kwargs
self.models_ = list()
self.feature_importances_ = None
self.eval_results_ = dict()
self.oof = None
self.metric = mae
self.tuning_step = False
self.mean_cv_score = None
self.general_config = None
self.predictions = None
self.target_name = None
def fit(self, X, y=None, **kwargs):
feature_names = X.columns if isinstance(X, pd.DataFrame) else list(range(X.shape[1]))
self.feature_importances_ = pd.DataFrame(index=feature_names)
self.oof = np.zeros(len(X))
for fold, (fit_idx, val_idx) in enumerate(self.cv.split(X, y), start=1):
# Split the dataset according to the fold indexes.
X_fit = X.iloc[fit_idx]
X_val = X.iloc[val_idx]
y_fit = y.iloc[fit_idx]
y_val = y.iloc[val_idx]
# LGBM .train() requires lightgbm.Dataset.
# https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.Dataset
fit_set = lgbm.Dataset(X_fit, y_fit)
val_set = lgbm.Dataset(X_val, y_val)
# Training.
# https://lightgbm.readthedocs.io/en/latest/Python-API.html#lightgbm.train
self.eval_results_[fold] = {}
model = lgbm.train(
params=self.model_params,
train_set=fit_set,
valid_sets=[fit_set, val_set],
valid_names=['fit', 'val'],
callbacks=[
log_evaluation(0),
record_evaluation(self.eval_results_[fold]),
early_stopping(self.model_params['early_stopping_rounds'],
verbose=False, first_metric_only=True)
],
**kwargs
)
val_preds = model.predict(X_val)
self.oof[val_idx] += val_preds / self.general_config['N_REPEATS']
if not self.tuning_step:
val_score = self.metric(y_val, val_preds)
best_iter = model.best_iteration
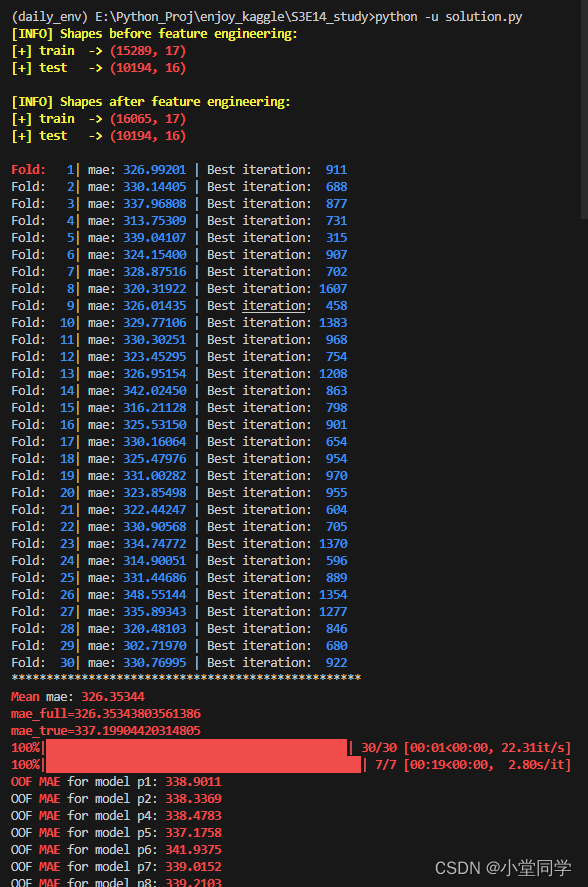
print(f'Fold: {blu}{fold:>3}{res}| {self.metric.__name__}: {blu}{val_score:.5f}{res}'
f' | Best iteration: {blu}{best_iter:>4}{res}')
# Stores the model
self.models_.append(model)
self.mean_cv_score = self.metric(y, self.oof)
print(f'{"*" * 50}\n{red}Mean{res} {self.metric.__name__}: {red}{self.mean_cv_score:.5f}')
return self
def predict(self, X):
utils.validation.check_is_fitted(self, ['models_'])
y = np.zeros(len(X))
for model in tqdm(self.models_):
y += model.predict(X)
return y / len(self.models_)这个类主要由三个函数组成,__init__(),fit(),predict(),其分别代表实例化对象时初始化方法、拟合模型方法、预测方法。
__init__():实例化对象时的初始化方法,该方法主要是提前定义一些模型的参数及变量。
其定义的参数和变量如下:
self.cv = cv # sklearn中的交叉验证
self.model_params = kwargs # 模型参数
self.models_ = list() # 来保存每次的模型
self.feature_importances_ = None #
self.eval_results_ = dict() #
self.oof = None # 折外交叉验证的预测,即对剩下那一折进行预测
self.metric = mae # 定义预测评价标准为MAE准则
self.tuning_step = False #
self.mean_cv_score = None # 平均的交叉验证分数
self.general_config = None # 一些
self.predictions = None #
self.target_name = None # 目标列名字
——fit函数——
fit函数是整个类的主题,着重分析和介绍。
首先分析前三行:
feature_names = X.columns if isinstance(X, pd.DataFrame) else list(range(X.shape[1]))
# isinstance(X,classinfo) 函数,判断对象X是不是某个类别,本语句即分析X是否为pd.DataFrame。是的话feature_names是X的列名。否的话基于列的维度产生对应数组。
self.feature_importances_ = pd.DataFrame(index=feature_names)
# 按上行语句的列名创建一个对应行数的空DataFrame。即假设上个语句的结果(X的列名)为['a','b','c'],则这个语句就创建一个行索引为 'a' 'b' 'c' 的三行零列的空DataFrame
self.oof = np.zeros(len(X))# 创建一个和X的行维度一致的一维0数组。即假设X为1000行50列,则该语句创建一个1000长度的1维(0初始化)数组
其次是根据交叉验证分割的数据集进行训练,
for fold, (fit_idx, val_idx) in enumerate(self.cv.split(X, y), start=1):
# Split the dataset according to the fold indexes.
X_fit = X.iloc[fit_idx]
X_val = X.iloc[val_idx]
y_fit = y.iloc[fit_idx]
y_val = y.iloc[val_idx]
fit_set = lgbm.Dataset(X_fit, y_fit)
val_set = lgbm.Dataset(X_val, y_val)对于其交叉验证而言,其最终返回的是对应数据集的索引,根据索引得到本次的训练集和交叉验证集。随后调用lgbm.Dataset方法来组件lgbm模型的数据集。
本文使用的是N次重复的KFOLD交叉验证方法。具体源码可见:
sklearn.model_selection.RepeatedKFold-scikit-learn中文社区![]() https://scikit-learn.org.cn/view/642.html 由上文可知设置参数为3次重复的10择交叉验证,由此可知循环共会进行30次。后续代码即设置参数对lgbm模型进行训练。
https://scikit-learn.org.cn/view/642.html 由上文可知设置参数为3次重复的10择交叉验证,由此可知循环共会进行30次。后续代码即设置参数对lgbm模型进行训练。
self.eval_results_[fold] = {}
model = lgbm.train(
params=self.model_params,
train_set=fit_set,
valid_sets=[fit_set, val_set],
valid_names=['fit', 'val'],
callbacks=[
log_evaluation(0),
record_evaluation(self.eval_results_[fold]),
early_stopping(self.model_params['early_stopping_rounds'],
verbose=False, first_metric_only=True)
],
**kwargs
)
val_preds = model.predict(X_val)
self.oof[val_idx] += val_preds / self.general_config['N_REPEATS']
if not self.tuning_step:
val_score = self.metric(y_val, val_preds)
best_iter = model.best_iteration
print(f'Fold: {blu}{fold:>3}{res}| {self.metric.__name__}: {blu}{val_score:.5f}{res}'
f' | Best iteration: {blu}{best_iter:>4}{res}')
# Stores the model
self.models_.append(model)如上文所述,后续对每择都进行了模型训练和评价,最后将30(重复3次的10择交叉验证)个训练好的模型都保存到了self.models_列表中。
在进行模型预测时,使用30个模型逐一进行预测,最后预测值除以30记得到最终预测值,代码如下。
def predict(self, X):
utils.validation.check_is_fitted(self, ['models_'])
y = np.zeros(len(X))
for model in tqdm(self.models_):
y += model.predict(X)
return y / len(self.models_)本次所用的参数设置如下:
config = {"SEED": 42,
"FOLDS": 10,
"N_ESTIMATORS": 2000,
"EXP_NUM": "2",
"COMBINE": True,
"KFOLD": True,
'N_REPEATS': 3,
"COL_DROP": ["RainingDays"]}
params = {"learning_rate": 0.04,
"max_bin": 1000,
"colsample_bytree": 0.8,
"subsample": 0.7,
"bagging_freq": 1,
"objective": "regression_l1",
"metric": "mae",
"early_stopping_rounds": 200,
"n_jobs": -1,
"verbosity": -1}
def mae(y_true, y_pred):
return metrics.mean_absolute_error(y_true, y_pred)5、训练
target = ['yield']
# 获得数据集
f_e = DataProcessor(verbose=True, combined=config['COMBINE'])
train, test = f_e.process_data()
# 将数据集分割为x和y(输入和对应的输出)
X_train, y_train, test = xy_split(train, test, target, cols_to_drop=config['COL_DROP'])
# 定义N次重复的K择交叉验证
cv = model_selection.RepeatedKFold(n_repeats=config['N_REPEATS'],
n_splits=config['FOLDS'],
random_state=config['SEED'])
# 实例化类及模型
lgbm_model = LGBMCVModel(cv=cv, **params)
# 参数设置
lgbm_model.tuning_step = False
lgbm_model.general_config = config
lgbm_model.target_name = target[0]
# 拟合
lgbm_model.fit(X_train, y_train, num_boost_round=config['N_ESTIMATORS'])
# 评估
mae_full = lgbm_model.mean_cv_score
mae_true = mae(y_train.iloc[:15289], lgbm_model.oof[:15289])
print(f'{mae_full=}\n{mae_true=}')将该模型的训练结果保存到本地
path_submissions = ''
# 定义实验名字
exp_num = '2'
# 保存训练集的模型输出 即在train.csv数据中模型的预测输出
oof = pd.DataFrame(lgbm_model.oof[:15289], columns=['oof_preds'])
oof.to_csv(os.path.join(path_submissions, f'oof_{exp_num}.csv'), index=False)
# 将模型测试结果保存到本地 (即对test.csv的模型预测输出)
# Saves the submission file.
submission = pd.read_csv(PATH_SUB)
if lgbm_model.predictions is None:
predictions = lgbm_model.predict(test)
else:
predictions = lgbm_model.predictions
submission[lgbm_model.target_name] = predictions
submission.to_csv(os.path.join(path_submissions, f'sub_{exp_num}.csv'), index=False)6、第一次后处理:组合
本节组合的主要思路是结合之前K择交叉的预测输出来矫正目前的模型预测值。
之前10择交叉验证,那么就会有10个模型oof和10个sub数据。(oof是指:模型训练好后,对训练集的模型输出。sub是指:训练好后的模型在其他数据集上的预测结果)
所以,目前我们拥有:11(10个择内,1个总和)个模型的oof,11(10个择内,1个总和)个模型的sub。
本次只选择了其中8个来进行分析:
for i in tqdm([1, 2, 4, 5, 6, 7, 8]):
pub_oof = pd.read_csv(f'{PATH_OOFS}/p{i}_oof.csv').iloc[:15289, :]
sub_oof = pd.read_csv(f'{PATH_OOFS}/p{i}_sub.csv')
if MATT:
oofs_df[f'p{i}'] = mattop_post_process(pub_oof.oof_preds)
subs_df[f'p{i}'] = mattop_post_process(sub_oof[target_name[0]])
else:
oofs_df[f'p{i}'] = pub_oof.oof_preds
subs_df[f'p{i}'] = sub_oof[target_name[0]]
if MATT:
oofs_df[f's{exp_num}'] = mattop_post_process(oof.oof_preds)
subs_df[f's{exp_num}'] = mattop_post_process(submission[target_name[0]])
else:
oofs_df[f's{exp_num}'] = oof.oof_preds
subs_df[f's{exp_num}'] = submission[target_name[0]]
for i, col in enumerate(oofs_df.columns):
score = mae(train[target_name[0]], oofs_df[col])
print(f'OOF {red}{mae.__name__.upper()}{res} for model {col}: {red}{score:.4f}{res}')
我试着解释一下此举的含义:现在选择了8个择内oof,那么现在就共有9列数据(8个择内oof和一个总和oof),一个oof的维度是15289行(不加入原始的数据)1列,那么现在创建一个oofs_df的表单数据,维度为15289行9列,列名分别为p1~p8(代表8个择内)、s2(代表总和)。然后每列对应值是其对应列名的oof值经过mattop_post_process函数的结果。sub数据也是同理。
经过上述之后,就会得到一个15289行9列的oofs_df的表单数据和10194行9列的subs_df的表单数据。
然后将这15289行9列作为输入的特征数据,真值数据作为标签数据,建立回归模型。
LADRegression_blend = LADRegression(positive=True)
LADRegression_blend.fit(oofs_df, train[target_name[0]])
lad_score = mae(train[target_name[0]], LADRegression_blend.predict(oofs_df))
print(f"{blk}MAE with LAD Regression of OOFS predictions : {red}{lad_score}{blk}\n\nCoefficients :{res}")
display(pd.Series(LADRegression_blend.coef_.round(2), oofs_df.columns, name='weight'))(LADRegression:Least absolute deviation Regression)
得到模型的各个特征的回归方程系数:
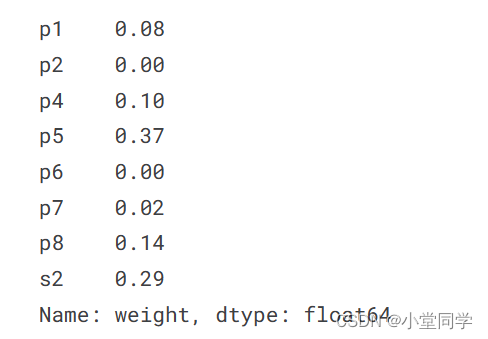
基于上述回归方程及其拟合系数,同样可以基于10194行9列的subs_df来得到拟合后的结果。
以上为第一次结果的后处理
7、第二次后处理
第二次后处理是将数据中的train.csv和test.csv中的两列数据做了精细的分析。随后对预测结果进行第二次后处理改正。
其使用了fft.csv数据,其获得方式如下:
ffs = ['fruitset', 'fruitmass', 'id']
# merges train and test and finds final common samples.
ids = train[ffs].merge(test[ffs], on=ffs[:-1], how='inner')['id_y'].unique()
final_samples = test[test.id.isin(ids)].drop_duplicates(subset=ffs[:-1])[ffs[:-1]]
train['pred'] = cop # already blended and corrected oofs up to mae 335.9858.
d = dict()
VERBOSE = False
# runs for loop to check what re-assigned value gives the bigger improvement
# for out-of-fold predictions, in the end of the loop it sets values to default.
for i in tqdm(final_samples.values):
best_mae = 335.9858
for yl in sorted(train['yield'].unique()):
train.loc[train['fruitset'].eq(i[0]) & train['fruitmass'].eq(i[1]), 'pred'] = yl
sc = mae(train[target_name[0]], train['pred'])
if sc < best_mae:
best_mae = sc
d['_'.join(i.astype(str))] = [sc, yl]
if VERBOSE and sc < 335.95:
print(sc, yl)
train['pred'] = cop第二次后处理代码:
def second_postprocessing(indx: str):
"""Walks thru grouped ffs.csv file fetching `fruitmass_fruitset`
as indx (0.334593591_0.379871916) and splits it.
The idea was to assign the best performing value (last in `grp`) from ffs.csv
but original value performed better and was robust.
Args:
indx: str of 'fruitmass_fruitset' (example: 0.334593591_0.379871916)
Returns:
tr_idx, te_idx, orig_value - the respective indexes of train/test `yeild` to be corrected.
None if dangerous zone condition is not satisfied.
"""
txt = indx
txt = list(map(float, txt.split('_')))
dsp_origin = origin.query('fruitset == @txt[0] and fruitmass == @txt[1]')
dsp_train = train.query('fruitset == @txt[0] and fruitmass == @txt[1]').iloc[:, 7:]
dsp_test = test.query('fruitset == @txt[0] and fruitmass == @txt[1]').iloc[:, 6:]
# Dangerous zone params:
if len(dsp_train) > 2 and len(dsp_test) > 1:
if not dsp_origin.empty:
orig_value = dsp_origin['yield'].values[0]
tr_idx = train.loc[train.fruitset.eq(txt[0]) & train.fruitmass.eq(txt[1]), 'pred'].index.tolist()
te_idx = test.loc[test.fruitset.eq(txt[0]) & test.fruitmass.eq(txt[1]), 'pred'].index.tolist()
return tr_idx, te_idx, orig_value
else:
return None
tridx_teidx_value_to_assign = Parallel(n_jobs=-1)(delayed(second_postprocessing)(indx) for indx in tqdm(grp.index))
# Removes Nones from the list.
tridx_teidx_value_to_assign = [i for i in tridx_teidx_value_to_assign if i is not None]
# Corrects the yield values based on the found original values
num_of_tr_rows_affected = 0
num_of_te_rows_affected = 0
for i in tridx_teidx_value_to_assign:
tr_idx, te_idx, orig_value = i
train.loc[tr_idx, 'pred'] = orig_value
test.loc[te_idx, 'pred'] = orig_value
num_of_tr_rows_affected += len(tr_idx)
num_of_te_rows_affected += len(te_idx)
new_score = mae(train[target_name[0]], train['pred'])
print(f'{red}MAE {blk}dangerous zone: {red}{new_score:.4f}{res}')
print(f'{blk}Number of rows affected train: {red}{num_of_tr_rows_affected}{res}')
print(f'{blk}Number of rows affected test: {red}{num_of_te_rows_affected}{res}')
余下部分均是模型结果验证及结果可视化部分。可自行学习。
才疏学浅,敬请指正!
共勉。
需要完整可运行代码可邮件联系(邮箱:rton.xu@qq.com,QQ:2264787072)
有任何疑问和建议欢迎交流,静候。