更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
由于流量红利逐渐消退,越来越多的广告企业和从业者开始探索精细化营销的新路径,取代以往的全流量、粗放式的广告轰炸。精细化营销意味着要在数以亿计的人群中优选出那些最具潜力的目标受众,这无疑对提供基础引擎支持的数据仓库能力,提出了极大的技术挑战。
本篇内容将聚焦字节跳动OLAP引擎技术和落地经验,从广告营销场景出发,上篇讲解利用ByteHouse 加速实时人群包分析查询的技术原理;下篇以字节跳动内部场景为例,具体拆解广告业务的实现逻辑和业务效果。(文本为上篇)
背景
人群圈选分析是客户画像平台(CDP)中的核心功能。 分析师利用各种标签组合,挑选出最合适的人群,进而进行广告推送,达到精准投放的效果。同时由于人群查询在不同标签组合下的结果集大小不同,在一次广告投放中,分析师需要经过多次的逻辑调整,以获得"最好"的人群包。在这种高频的操作下,画像平台通常会遇到两方面的问题:
-
第一,由于此类查询分析是临时性的,各种标签组合数巨大,离线预计算无法满足此类灵活性。
-
第二,由于此类查询是实时场景,查询性能变得非常关键, 通常一次查询在分钟级,耗时较长,无法满足分析师需求。
这篇文章中,我们将会分享人群圈选查询在实时分析OLAP场景下的解决思路,同时介绍如何利用ByteHouse来加速此类查询。从数据表现上看,在10亿级用户测试数据下,ByteHouse的人群查询P99小于10s,展现了优异的性能。
场景模型
一个支持人群圈选的数据架构大致如下:

用户的注册信息通过用户流进入数据湖,同时用户的行为信息通过事件流进入数据湖。 之后通过标签生产任务,我们为每个用户打上标签。
由于即时查询的实时性和灵活性,转化好的数据通常会写入OLAP引擎,例如ByteHouse,以提供灵活且实时的SQL查询。用户在分析时,一般会从画像平台应用界面去可视化构建标签逻辑,再由平台应用将这些逻辑转化成SQL,发给ByteHouse进行处理。
从数据模型上看, 数据仓库或者数据湖里存储的格式多数以id-tag为主,例如:
| user_id | sex | age | tags |
| 10001 | F | 20 | [] |
| 10002 | M | 22 | [tag_1,tag_2] |
| 10003 | F | 23 | [tag_1] |
| 10004 | M | 24 | [tag_2] |
| 10005 | F | 25 | [tag_1,tag_2] |
在人群分析中,以下以tag为主的模式会更合适,例如:
| tags | active_users |
| tag_1 | [10002,10003,10005] |
| tag_2 | [10002,10005] |
数据是通常是基于用户作为主体存储,这种情况导致用户数量非常多,同时存在很多不必要字段。 那么当用户通过组合标签(tag) 过滤人群时,几乎所有的行都需要被扫描, 使得性能开销随着标签和用户的增长越来越大。
当数据以标签作为主体时,有两个比较大的改动:
-
其一,只有跟人群相关的维度会被保留,其他信息例如sex,age等会被移除。
-
其二,active_users以数组(array)的形式存放所有的用户id, 这种操作带来的一个重要的收益是减少了行数,同时减少了数据大小。
在这种模型下, 根据tag组合选取用户就会变成集合的交并补操作,性能对比第一种模型会有显著提升。
ByteHouse Bitmap类型
第二种存储模型可以用如下ByteHouse SQL建表:
CREATE TABLE id_tags ( tags String, active_users Array<UInt64> ) Engine = CnchMergeTree() order by tags人群圈选查询,例如找到同时满足tag_1和tag_2的人群的数量,可以用如下SQL完成:
WITH (SELECT active_users as tag_1 FROM id_tags WHERE tags = 'tag_1') as tag_1_user, WITH(SELECT active_users as tag_2 FROM id_tags WHERE tags = 'tag_2') as tag_2_user, SELECT length(arrayIntersect(tag_1_user, tag_2_user))虽然该模型可以简化部分操作,但是每个tag的选取需要有一个子查询(with 部分)。这种方式对于表的扫描有大量浪费,而且跟标签的数量线性相关。
为了解决这个问题,ByteHouse内置BitMap类型,可以直接用位(bit)来表示一个tag是否能存在。
沿用以上例子, 在利用BitMap后,建表语句改为:
CREATE TABLE id_tags ( tags String, active_users BitMap64 ) Engine = CnchMergeTree() order by tags此处注意,我们只是将active_users的类型由Array<UInt64> 改成 BitMap64,其余的部分没有变动。
对于同样的“找到同时满足tag_1和tag_2的人群的数量”的查询,用以下查询:
SELECT bitmapCount('tag_1&tag_2') FROM tag_uids_map我们用bit代替了原始的数组,使得该查询可以被优化到在一次表扫描中完成。
基于字节跳动内部线上场景,我们观测到上述的查询优化在多标签场景下,能有10~50倍的性能提升。
数据导入
写入数据进入bitmap表跟普通表没有显著差异。 例如,小批量insert的方式可以用如下方式:
INSERT INTO TABLE id_tags values ('tag_1', [2,4,6]),('tag_2', [1,3,5])因为id_tags中active_users定义为BitMap64的类型, 数组值[1,3,5], [2,4,6]会被自动转化为BitMap64。之后的计算和存储都会是BitMap64类型。
大批量文件导入时,我们可以利用ByteHouse提供的导入服务,目前离线(TOS, LASFS)以及实时(Kafka)等导入模式均已支持BitMap数据导入。流式写入(如Flink直写)可以通过JDBC接口用insert的方式写入。
相关函数
ByteHouse除了支持BitMap类型的数据进行交并补操作,也内置了大量的列函数,例如bitmapColumnAnd用来接收一个bitmap列,对该列所有bitmap做and运算; 以及bitmapColumnCardinality用来返回一个列中所有bitmap的元素个数。 详情可以参考官方文档。
BitEngine原理介绍
BitMap结构解析
假设一个用户ID用32位unsigned integer表示, 那么使用常规bit存储的方式需要2^32 bits ~ 512MB 的空间。如果需要为每个标签对应512MB空间,在标签量增长时,存储量会变得巨大。实际上,很少有业务会遇到2^32 大约40亿用户,因此实际场景中用户ID的分布是很稀疏的。
我们可以基于这个特性,利用Roaring bitmap来进一步压缩这个空间。如下图所示:
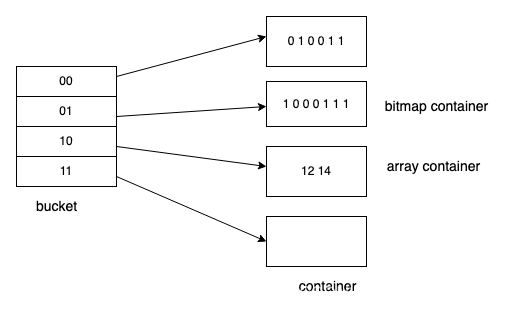
在32位的Roaring bitmap中,前16位用于分桶,该取值范围内没有数据则bucket不会被创建,后16位存在对应的container中。Container有两种类型:
-
Array container: 数据量较少的时候(一般少于8K容量),更省空间
-
Bitmap container 适合存储稠密数据、占用空间小
在计算的时候只要对某些bucket中的值进行计算即可。扩展到64位的roaringbitmap的时候,我们可以通过一个map<uint32_t, Roaring>来支持,前32位作为map的key,后32位用roaringbitmap存储。
字典优化
在大部分场景中,以上的roaring bitmap已经有很好的性能。 但是在字节的实际场景中,我们发现由于user_id 不是连续生成的,array container的数量占比会很高。 对两个稀疏人群的交并补操作就变成了对两个有序数组的计算,这种计算对比单纯的位计算,在性能上还是有明显的差异。
因此在ByteHouse中,我们通过字典方式,对数据进行编码,让数据更加集中。
开启字典优化的方式如下:
CREATE TABLE id_tags ( tags String, active_users BitMap64 BitEngineEncode ) Engine = CnchMergeTree() order by tags本质上字典服务是个onto映射, 可以通过key 查找value, 也可以通过value反查key, 其中key原始值,value时编码值。开启编码之后,ByteHouse会依赖一个字典文件。在默认情况下,ByteHouse会在内部维护一个字典文件。
当底表更新时,内部字典文件也会随之异步更新。ByteHouse同时也支持用户维护外部字典,这里不做展开。
总结
人群分析是画像平台的基础功能,本文介绍了如何利用ByteHouse内置的BitMap类型来支持实时的画像查询分析。目前ByteHouse云数仓以及企业版均已登陆火山引擎。未来,火山引擎将通过 ByteHouse 来为客户持续提供字节跳动和外部最佳实践,构建交互式大数据分析平台,以应对复杂多变的业务需求和高速增长的数据场景。
点击跳转【云原生数据仓库ByteHouse】了解更多