文章目录
- CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
- 摘要
- 本文方法
- 实验结果
- Boundary Difference Over Union Loss For Medical Image Segmentation(损失函数)
- 摘要
- 本文方法
- 实验结果
CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
摘要
u型结构已成为医学图像分割网络设计的一个重要范例。然而,由于卷积固有的局部局限性,具有u型结构的全卷积分割网络难以有效地提取全局上下文信息,而这对于病灶的精确定位至关重要。虽然结合cnn和transformer的混合架构可以解决这些问题,但由于环境和边缘设备施加的计算资源限制,它们在真实医疗场景中的应用受到限制。此外,轻量级网络中的卷积感应偏置能很好地拟合稀缺的医疗数据,这是基于Transformer的网络所缺乏的。为了在利用归纳偏置的同时提取全局上下文信息,我们提出了一种高效的全卷积轻量级医学图像分割网络CMUNeXt,该网络能够在真实场景场景中实现快速准确的辅助诊断。
CMUNeXt利用大内核和倒瓶颈设计,将远距离空间和位置信息彻底混合,高效提取全局上下文信息。我们还介绍了Skip-Fusion模块,旨在实现平滑的跳过连接,并确保充分的特征融合。在多个医学图像数据集上的实验结果表明,CMUNeXt在分割性能上优于现有的重量级和轻量级医学图像分割网络,同时具有更快的推理速度、更轻的权重和更低的计算成本。
代码地址
本文方法
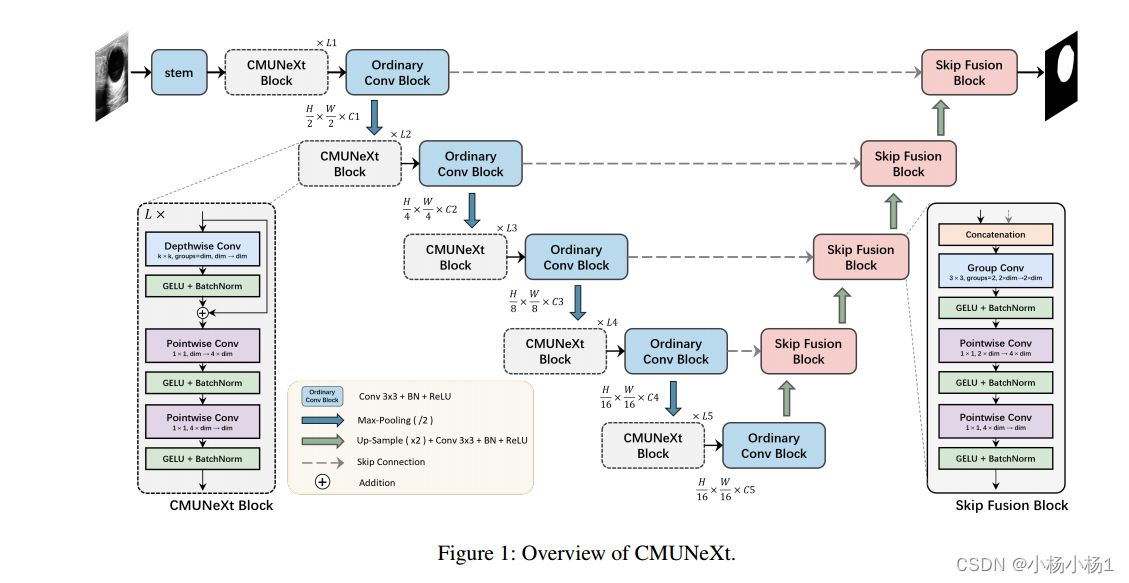
CMUNEXT模块比较简单,总的来说不是很复杂
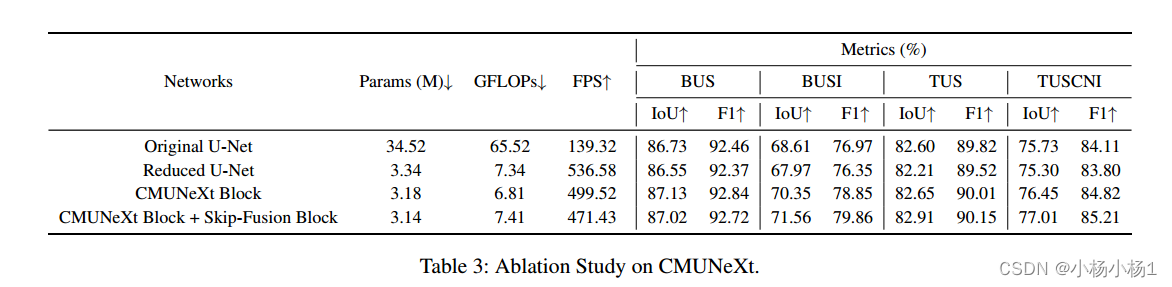
实验结果
Boundary Difference Over Union Loss For Medical Image Segmentation(损失函数)
摘要
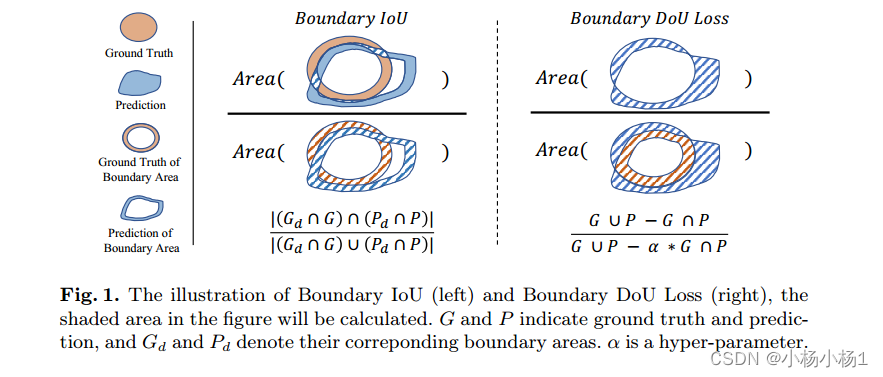
医学图像分割对临床诊断至关重要。然而,目前医学图像分割的损失主要集中在整体分割结果上,较少提出用于指导边界分割的损失。那些确实存在的损失往往需要与其他损失结合使用,并且产生无效效果。为了解决这个问题,我们开发了一种简单有效的损失,称为边界差分联合损失(边界DoU损失)来指导边界区域分割。它是通过计算预测与真值的差集与差集与部分交集集并集的比值得到的。我们的损失只依赖于区域计算,使得它易于实现并且训练稳定,不需要任何额外的损失。此外,我们使用目标大小来自适应调整应用于边界区域的注意力。
代码地址
本文方法

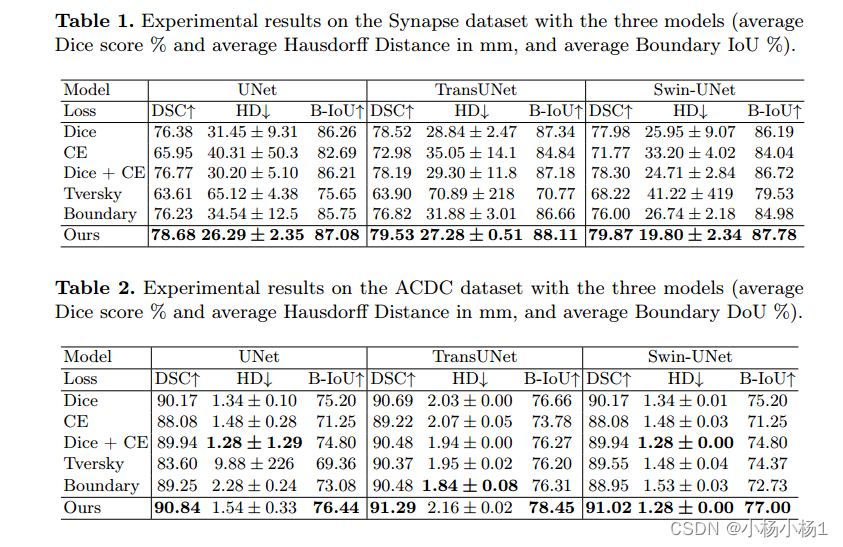
实验结果
class BoundaryDoULoss(nn.Module):
def __init__(self, n_classes):
super(BoundaryDoULoss, self).__init__()
self.n_classes = n_classes
def _one_hot_encoder(self, input_tensor):
tensor_list = []
for i in range(self.n_classes):
temp_prob = input_tensor == i
tensor_list.append(temp_prob.unsqueeze(1))
output_tensor = torch.cat(tensor_list, dim=1)
return output_tensor.float()
def _adaptive_size(self, score, target):
kernel = torch.Tensor([[0,1,0], [1,1,1], [0,1,0]])
padding_out = torch.zeros((target.shape[0], target.shape[-2]+2, target.shape[-1]+2))
padding_out[:, 1:-1, 1:-1] = target
h, w = 3, 3
Y = torch.zeros((padding_out.shape[0], padding_out.shape[1] - h + 1, padding_out.shape[2] - w + 1)).cuda()
for i in range(Y.shape[0]):
Y[i, :, :] = torch.conv2d(target[i].unsqueeze(0).unsqueeze(0), kernel.unsqueeze(0).unsqueeze(0).cuda(), padding=1)
Y = Y * target
Y[Y == 5] = 0
C = torch.count_nonzero(Y)
S = torch.count_nonzero(target)
smooth = 1e-5
alpha = 1 - (C + smooth) / (S + smooth)
alpha = 2 * alpha - 1
intersect = torch.sum(score * target)
y_sum = torch.sum(target * target)
z_sum = torch.sum(score * score)
alpha = min(alpha, 0.8) ## We recommend using a truncated alpha of 0.8, as using truncation gives better results on some datasets and has rarely effect on others.
loss = (z_sum + y_sum - 2 * intersect + smooth) / (z_sum + y_sum - (1 + alpha) * intersect + smooth)
return loss
def forward(self, inputs, target):
inputs = torch.softmax(inputs, dim=1)
target = self._one_hot_encoder(target)
assert inputs.size() == target.size(), 'predict {} & target {} shape do not match'.format(inputs.size(), target.size())
loss = 0.0
for i in range(0, self.n_classes):
loss += self._adaptive_size(inputs[:, i], target[:, i])
return loss / self.n_classes