一、说明
二、pca降维和自编码
2.1 pca和自编码的共同点
自动编码器通过组合数据最重要的特征,将馈送的数据映射到低维空间。他们将原始数据编码为更紧凑的表示形式,并决定如何组合数据,因此自动编码器中的自动。这些编码特征通常称为潜在变量。
这样做可能有用的有几个原因:
1. 降维可以减少训练时间
2. 使用潜在特征表示可以增强模型性能
像机器学习中的许多概念一样,自动编码器似乎很深奥。如果您不熟悉潜在变量,则潜在变量本质上是某些数据的隐式特征。这是一个不直接观察或测量的变量。例如,幸福是一个潜在的变量。我们必须使用像问卷这样的方法来推断个人幸福的程度。
与自动编码器模型一样,主成分分析(PCA)也被广泛用作降维技术。但是,PCA 算法映射输入数据的方式与自动编码器不同。
2.2 直觉
假设您有一个很棒的跑车乐高套装,您想在朋友生日时送给他们,但您拥有的盒子不够大,无法容纳所有乐高积木。与其根本不发送,不如决定打包最重要的乐高积木——对制造汽车贡献最大的积木。所以,你扔掉一些琐碎的部件,如门把手和挡风玻璃刮水器,并打包一些像车轮和框架这样的部件。然后,您将盒子运送给您的朋友。收到包裹后,您的朋友对没有说明的杂七杂八的乐高积木感到困惑。尽管如此,他们还是组装了这套设备,并能够识别出它是一辆可驾驶的车辆。它可能是沙丘越野车,赛车或轿车 - 他们不知道。
上面的类比是有损数据压缩算法的一个例子。数据的质量没有得到完全保留。这是一种有损算法,因为一些原始数据(即乐高积木)已经丢失。虽然使用PCA和Autoencoders进行降维是有损的,但这个例子并没有完全描述这些算法——它描述了一种特征选择算法。特征选择算法会丢弃数据的某些特征并保留显著特征。选择它们保留的要素通常是出于统计原因,例如属性与目标标签之间的相关性。
三、主成分分析
假设一年过去了,你朋友的生日又快到了。你决定给他们买另一套乐高汽车,因为他们去年告诉你他们有多喜欢他们的礼物。你也因为购买了一个太小的盒子而再次犯了错误。这一次,您认为可以通过系统地将它们切成更小的碎片来更好地利用乐高积木。乐高积木的粒度更精细,让您比上次更多地填充盒子。以前,无线电天线太高,无法放入盒子,但现在您将其切成三份,包括三部分中的两部分。当您的朋友收到邮件中的礼物时,他们会通过将某些部件粘合在一起来组装汽车。他们能够将扰流板和一些轮毂盖粘在一起,因此汽车更容易识别。接下来,我们将探讨这个类比背后的数学概念。

阐述
PCA 的工作原理是将输入数据投影到数据协方差矩阵的特征向量上。协方差矩阵量化数据的方差以及每个变量彼此之间的差异程度。特征向量只是通过线性变换保持其跨度的向量;也就是说,它们在转换之前和之后指向相同的方向。协方差矩阵将原始基向量变换为朝向每个变量之间的协方差方向。简单来说,特征向量允许我们重新构建原始数据的方向,以不同的角度查看它,而无需实际转换数据。我们本质上是在提取每个变量的分量,当我们将数据投影到这些向量上时,这些分量会导致最大的方差。然后,我们可以使用协方差矩阵的特征值选择主轴,因为它们反映了相应特征向量方向上的方差大小。
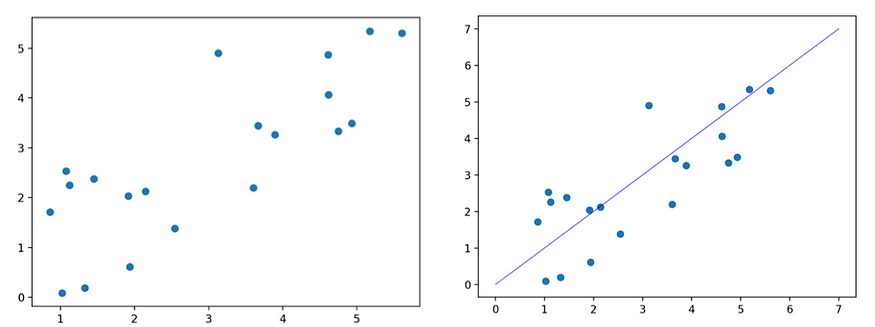
原始数据(左)第一主成分和数据(右)
这些投影产生了一个新的空间,其中每个基向量封装了最大的方差(即,具有最大特征值的特征向量的投影具有最大的方差,第二个特征向量上的投影具有第二大方差,依此类推)。这些新的基向量被称为主分量。我们希望主成分朝最大方差方向定向,因为属性值的方差越大,预测能力越好。例如,假设您正在尝试预测给定两个属性的汽车价格:颜色和品牌。假设所有的汽车都有相同的颜色,但其中有很多品牌。在这个例子中,根据汽车的颜色(一个零方差的特征)猜测汽车的价格是不可能的。但是,如果我们考虑一个差异更大的功能——品牌——我们将能够提出更好的价格估计,因为奥迪和法拉利的价格往往高于本田和丰田。由 PCA 产生的主成分是输入变量的线性组合——就像粘合的乐高积木是原始积木的线性组合一样。这些主成分的线性性质也使我们能够解释转换后的数据。

PCA 优点:
- 降低维度
- 解释
- 快速运行时间
PCA 缺点:
- 无法学习非线性特征表示
四、自动编码器
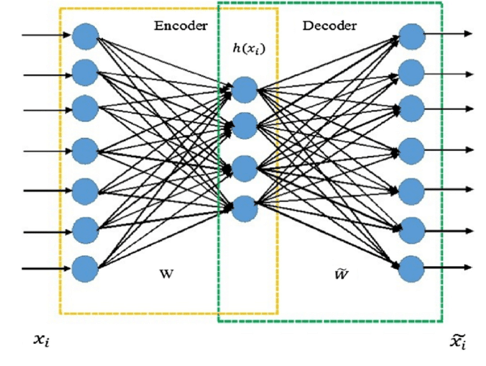
自动编码器的事情变得有点奇怪。您不只是切割零件,而是开始完全融化、拉长和弯曲乐高积木,以便最终的零件代表汽车最重要的特征,但又符合盒子的限制。这样做不仅可以让您在盒子中放入更多乐高积木,还可以创建自定义积木。这很好,但是您的好友不知道包裹到达时如何处理。对他们来说,它看起来像一堆随机操纵的乐高积木。事实上,这些部件是如此不同,以至于您需要在几辆车上重复这个过程无数次,以系统的方式将原始部件转化为可以由您的朋友组装到汽车中的部件。
阐述
希望上面的类比有助于理解自动编码器与PCA的相似之处。在自动编码器的上下文中,您是编码器,您的朋友是解码器。您的工作是以解码器可以解释和重建的方式转换数据,并且误差最小。
自动编码器只是一个重新利用的前馈神经网络。我不打算在这里深入研究细节,但请随时查看 Piotr Skalski 的精彩文章或深度学习书籍,以更全面地了解神经网络。
虽然它们能够学习复杂的特征表示,但自动编码器的最大缺陷在于它们的可解释性。就像您的朋友在收到扭曲的乐高积木时毫无头绪一样,我们不可能可视化和理解非视觉数据的潜在特征。接下来,我们将研究稀疏自动编码器。
自动编码器优点
- 能够学习非线性特征表示
- 降低维度
自动编码器缺点
- 训练计算成本高
- 无法解释
- 更复杂
- 容易过度拟合,尽管这可以通过正则化来缓解
稀疏自动编码器
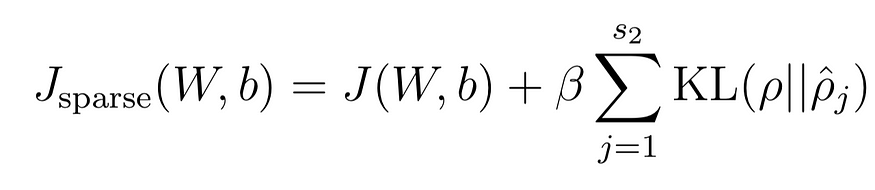
人类未充分利用大脑力量的观点是基于神经科学研究的误解,该研究表明最多有1-4%的神经元在大脑中同时放电。人脑中神经元的稀疏放电可能有几个很好的进化原因。如果所有神经元同时放电,我们能够“释放大脑的真正潜力”,它可能看起来像这样。我希望你喜欢题外话。回到神经网络。大脑中突触的稀疏性可能是稀疏自动编码器的灵感来源。神经网络中的隐藏神经元学习输入数据的分层特征表示。当神经元看到它正在寻找的输入数据的特征时,我们可以认为它“放电”。原版自动编码器通过其不完整的架构(不完整意味着隐藏层包含的单元少于输入层)强制学习潜在特征。稀疏自动编码器背后的想法是,我们可以强制模型通过与架构无关的约束(稀疏性约束)来学习潜在特征表示。
稀疏性约束是我们希望的平均隐藏层激活,通常是接近零的浮点值。稀疏性约束超高计在上面的函数中用希腊字母 rho 表示。Rho hat j 表示隐藏单元 j 的平均激活。
我们使用KL散度将此约束强加于模型,并通过β加权。简而言之,KL 散度衡量两个分布的相异性。将此项添加到我们的损失函数中可激励模型优化参数,从而使激活值分布与稀疏性参数均匀分布之间的KL分歧最小化。
限制接近零的激活意味着神经元只会在优化准确性最关键的时候触发。KL发散项意味着神经元也将因过于频繁地放电而受到惩罚。如果您有兴趣了解有关稀疏自动编码器的更多信息,我强烈建议您阅读本文。吴恩达的这些讲座(讲座1,讲座2)也是一个很好的资源,帮助我更好地理解了支撑自动编码器的理论。
五、结论
在本文中,我们深入研究了PCA和自动编码器背后的概念。不幸的是,没有灵药。PCA和自动编码器模型之间的决定是间接的。在许多情况下,PCA 是优越的 - 它更快,更易于解释,并且可以像自动编码器一样降低数据的维度。如果你可以使用PCA,你应该这样做。但是,如果您处理的数据需要高度非线性的特征表示才能获得足够的性能或可视化效果,则 PCA 可能达不到要求。在这种情况下,训练自动编码器可能是值得的。再说一次,即使自动编码器产生的潜在特征提高了模型性能,这些特征的模糊性也会对知识发现构成障碍。