目录
前言
一:负载均衡概述
二:为啥负载均衡服务器这么快呢?
编辑
2.1 七层应用程序慢的原因
2.2 四层负载均衡器LVS快的原因
三:LVS负载均衡器的三种模式
3.1 NAT模式
3.1.1 什么是NAT模式
3.1.2 NAT模式实现LVS的缺点
3.1.3 NAT模式的注意事项
3.2 DR模式
3.2.1 什么是MAC欺骗?
3.2.2 为什么Real Server需要处于同一个局域网内?
3.2.3 如何实现VIP的对内可见,对外隐藏
3.2.4 为什么DR模式要快
3.3 TUN隧道模式
3.3.1 实现原理
3.3.2 优缺点
四:Real Server调度算法
4.1 如何监控每台Real Server的负载情况?
4.2 客户端长连接
前言
在互联网发展早期,由于用户量较少,业务需求也比较简单。对于软件应用,我们只需要一台高配置的服务器,把业务所有模块全单机部署,这样的软件架构模式称为单体架构模式。
随着用户量的增加,客户端请求的并发量越来越大,在这个过程中单体架构会产生两个问题。
1)单机的硬件资源是有限的,哪怕使用高配置服务器,其硬件资源仍然会称为瓶颈,随着客户端请求并发量越来越大,但单机性能的上涨受限,进而使得软件的性能逐渐下降,访问延迟越来越高。
2)容易出现单点故障

为了解决上述的问题,我们引入了将应用进行分布式集群化部署的架构,分为两种水平架构部署和垂直架构部署。
1)水平架构部署:应用程序分片集群化部署,例如Redis的分片集群。实现高性能和高拓展。
2)垂直架构部署:为了解决单点故障问题,一般会对应用程序进行主备/主从架构,例如Redis的主从。
但是新的架构设计有两个问题亟待解决:
1)客户端的请求如何均匀的分发到多台目标服务器上呢?
2)如何检测每台目标服务器的健康状态,避免客户端向已经宕机的服务器发起请求导致请求失败呢?如何支持目标服务器进行动态的上下线呢?
一:负载均衡概述
为了解决前言中提到的两个问题,于是引入了负载均衡技术的设计。简单来说负载均衡的核心目的就是做分治,将客户端的请求均匀的分发到多台目标服务器上,并支持目标服务器动态上下线的功能。
由于进行了分治处理,目标服务器多台的性能得到了释放,因此能够接受更大的客户端请求并发,实现了高并发负载均衡的目标。
那负载均衡的具体实现是什么呢?
首先实现负载均衡的可能方式有两种:
1)客户端层面做负载均衡。
2)把负载均衡功能解耦出来单独部署成一个单独的负载均衡服务器。
首先第一种方案,在客户端层面做负载均衡显然是不可取的,因为每一台Real Server服务器都有一个提供服务的RIP,如果让客户端记录所有的Real Server对应的RIP显然是非常荒谬的。
比如想象这样一件事,百度的网页放在了多台Tomact目标服务器上部署,比如今天突然百度新上线了一台Tomcat服务器,难道要打电话给所有使用百度的用户,告诉他们新的Tomact服务器的IP地址,让后让他们去访问新的Tomcat服务器?这显然是不对的。
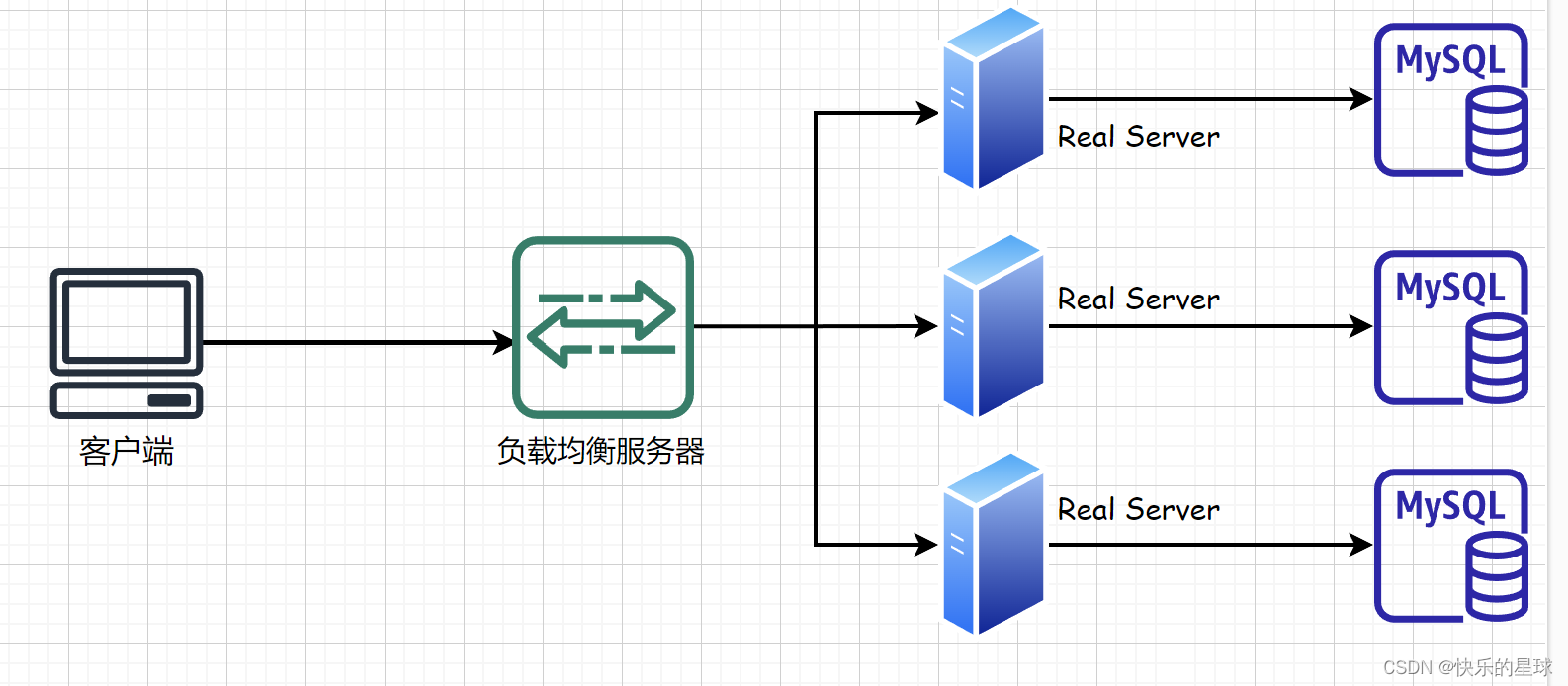
第二种方案显然是可行的,其基础设计图如下:

注意:在这种设计模型下,客户端其实根本就不知道后端服务器集群是否使用了负载均衡,这对客户端都是透明的,客户端只要向后端服务器集群暴露的统一流量入口VIP发起请求就行了,其内部是如何进行请求分发的,对客户端来根本就不重要。
此时我们再想一个问题,Real Server为啥要集群化部署呢?还不是因为单台Real Server扛不住很高的并发因此需要集群化部署。那么疑问就来了,为啥单台Real Server抗不住的并发,需要多台Real Server才能抗住的并发,单台负载均衡服务器就能抗住?
问题:为啥负载均衡服务器这么快呢?
二:为啥负载均衡服务器这么快呢?
负载均衡服务器的功能是将客户端的请求均匀的分发给目标服务器,其是否快的根本原因就是在于计算机接受请求数据包->处理请求数据包->发出响应数据包的这个过程是否是足够快。

2.1 七层应用程序慢的原因
如上图所示应用程序服务器例如Tomcat等,是属于应用层的服务器,属于OSI七层的服务器。
在应用层的应用程序进程在跨主机跨进程进行通信的时候,首先需要在传输控制层通过三次握手建立长连接,且请求数据包需要通过网络IO到用户空间的应用程序进程当中,在进行处理。这个过程涉及到以下几个耗时的步骤:
1)内核网络协议栈接受数据包时涉及到的中断,CPU拷贝。
2)用户态的应用程序进程通过网络IO去读取Sockt缓冲区的数据时,涉及到 中断,用户态内核态的切换,CPU拷贝
3)用户态的应用程序进程处理数据包,进行业务逻辑处理的耗时
4)用户态的应用程序进程发出响应数据包的时候,涉及到的一系列的中断,上下文切换,CPU拷贝的代价。
上述原因就是应用程序服务器慢的原因。
2.2 四层负载均衡器LVS快的原因
首先LVS在逻辑上到了四层但又没有到四层,逻辑上到了四层是LVS只是看了一下请求报文中的目标地址和端口。如果是LVS负载均衡服务器的IP地址和端口号就进行负载,否则就不进行处理。
之所以需要看请求报文中的目标地址和端口号的本质目的就是,一台计算机上有很多端口号,但只有负载均衡器监听的端口号才需要进行处理。
之所以说LVS又没到四层的原因是,LVS在传输控制层不需要进行三次握手,只是看了一下端口号。
LVS的性能快在是基于四层的且不需要建立连接。相较于七层应用程序进程来说快太多了,可以看成LVS就是只做了数据包的转发,不需要对数据包进行修改,所以很快。
但是一定要注意的是使用LVS负载均衡服务器的时候,Real Server必须是镜像,也就是提供完全一样的服务。
因为LVS仅仅只是四层负载均衡服务器,其没有涉及到应用层,甚至都不知道应用层使用的是HTTP还是FTP等。因此自然也不能根据HTTP请求的报文信息来决定把请求分发到哪个目标服务器上。所以Real Server必须是镜像的。
但基于七层负载的Nginx,因为其是基于应用层的负载均衡,可以根据HTTP请求的报文信息来决定把请求分发到哪个目标服务器上,比如Cookie,消息体,RequestHeader等。因此Nginx的目标服务器可以是提供不一样的服务的,Nginx可以根据HTTP请求报文的信息来进行负载。
三:LVS负载均衡器的三种模式
我们已经讲了为什么要有负载均衡,也讲了负载均衡的作用以及四层负载均衡LVS为什么快,现在开始思考LVS如何实现呢?
3.1 NAT模式
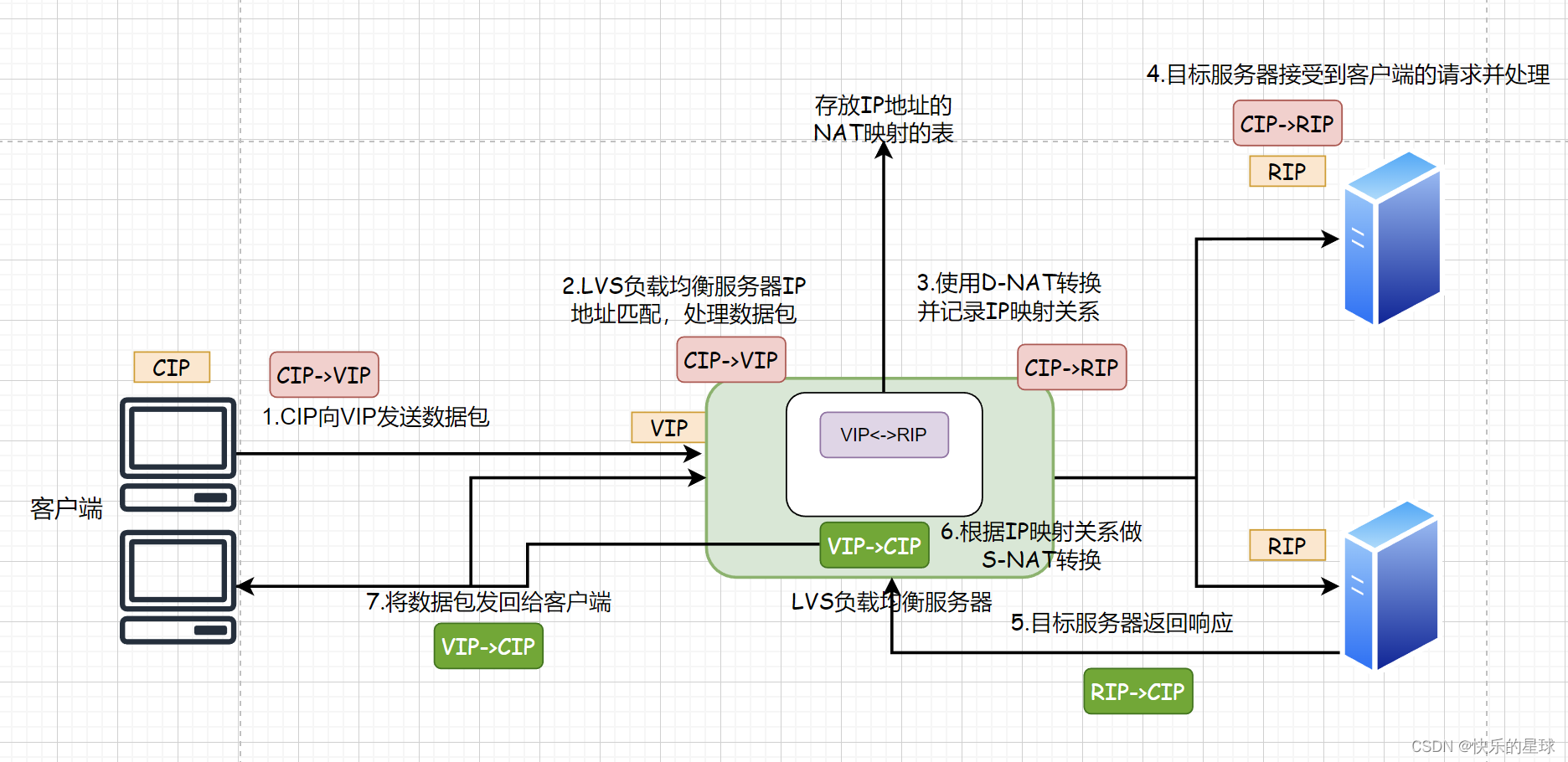
NAT模式实现LVS图示
3.1.1 什么是NAT模式
所谓NAT模式,其实是(Network Adress Transfer) 网络地址转换协议的缩写。其原理用一句话说就是在数据报文即将发出去之前对数据报文的IP地址和端口号进行修改。
3.1.2 NAT模式实现LVS的缺点
1. NAT网络地址转换协议是网络层处理的,性能比数据链路层MAC欺骗要慢。
2. LVS负载均衡服务器是后端服务器高并发流量的入口,频繁的进行NAT网络地址转换会消耗CPU的性能,并且还需要消耗内存空间存放地址映射关系。
3. 无论是客户端发给服务器的请求,还是服务器给客户端的响应都需要经过LVS,会对LVS造成过大的压力,大大消耗LVS的网络带宽;而且请求的数据包和响应的数据包的大小是不对称的,因此会使得LVS的吞吐量进一步下降。
这里着重讲一下上述第三点的原理
首先负载均衡机制的核心目的是让客户端的请求合理均分地分发给多台目标服务器上。其本质地目的是用多台目标服务器均摊客户端请求流量,以便能够承载更大地并发。那么目标服务器地响应应该由目标服务器直接返回给对应的客户端即可。这样LVS只需要承担客户端请求的网络带宽,而目标服务器响应的网络带宽由多台目标服务器共同承担,自然LVS的吞吐量就上升了。
请求和响应数据包大小不对称很常见,比如我们打开网页请求百度的主页。在这个情景下,请求数据包很小,但是响应数据包确实整个页面的文字和图片,响应数据包比请求数据包大很多,而请求和响应数据包都经过LVS,这种不对称,会进一步降低LVS的吞吐量。
3.1.3 NAT模式的注意事项
在使用NAT的模式的时候要注意,Real Server的默认网关要设置为LVS负载均衡服务器。否则NAT模式会失效。
看看3.1的图例Real Server处理完客户端的数据包后,会封装(RIP->CIP)的响应数据包,如果默认网关不配置成LVS负载均衡服务器,这个响应数据包很可能不经过LVS负载均衡器将数据包转换为(VIP->CIP),就直接返回给客户端。但客户端发出的请求数据包确是(CIP->VIP),因此(RIP->CIP)的数据包会被直接丢弃。
Real Server响应数据包在NAT模式下必须要经过LVS服务器做S-NAT之后,由LVS负载均衡器将数据包返回给客户端,
3.2 DR模式
DR模式的提出本质上是为了解决NAT模式存在的问题,其思想是既然NAT的模式目标服务器的响应需要经过LVS负载均衡服务器导致其吞吐量下降,那DR模式下目标服务器的响应就直接返回给客户端达到减轻LVS压力的目的,从而提高LVS的吞吐量。
为了实现DR模式,涉及到的重要技术就是 MAC欺骗 和 VIP对内可见对外隐藏。
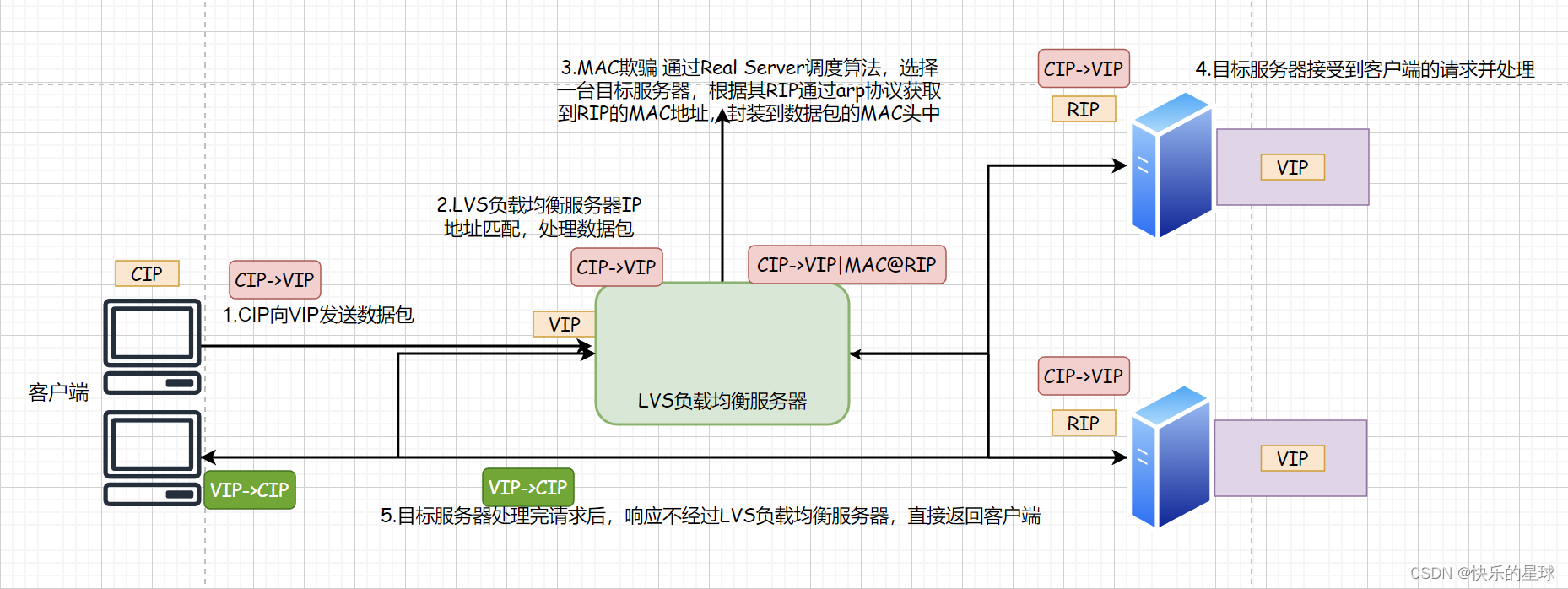
DR模式重要的几个特点:
1. LVS负载均衡服务器做基于数据链路层的MAC欺骗。
2. 每台Real Server都具有VIP,但是对内可见,对外隐藏。
3. 同一台LVS负载均衡服务器所负载的多台Real Server需处于和LVS负载均衡服务器在同一个局域网内。
4. Real Server的响应不经过LVS负载均衡服务器,会直接返回给客户端。
3.2.1 什么是MAC欺骗?
如上图所示LVS服务器接收到(CIP->VIP)的数据包之后,其并没有做D-NAT转换,修改其IP到某一台RIP。而是通过Real Server调度算法,选择一台目标服务器,根据其RIP通过arp协议获取到RIP对应的MAC地址,封装到当前数据包的MAC头上。
客户端请求的目标地址就是VIP,就是LVS负载均衡服务器本身,本应当接收包,但是却通过修改MAC地址到另一台Real Server的MAC地址而将数据包转发出去的过程称为MAC欺骗。
重点:MAC欺骗是基于二层数据链路层的技术,其速度要比基于四层的NAT技术要快。
3.2.2 为什么Real Server需要处于同一个局域网内?
在进行LVS部署的时候,需要注意同一台LVS负载均衡服务器所负载的多台Real Server需处于同一个局域网内。
其原因是LVS负载均衡服务器在进行MAC欺骗时,会通过Real Server调度策略选择一台Real Server的RIP,然后通过arp协议获取此RIP对应的MAC地址。
这里要注意arp协议是局域网内部的基于交换机的广播协议,所以自然要求多台Real Server和LVS负载均衡服务器在同一个局域网内部。
3.2.3 如何实现VIP的对内可见,对外隐藏
因为需要达到目标服务器直接向客户端返回响应的目的,所以目标服务器返回的数据包应该是 (VIP->CIP),也就是说目标服务器Real Server 需要具备VIP的网络接口。
但是互联网中自然不能出现多个相同的VIP地址,所以只有负载均衡器LVS,能够将VIP暴露到公网中,而每一个Real Server都应该知道自己有VIP,但不能将VIP暴露出去。
那么如何实现VIP的对内可见,对外隐藏呢?
修改Linux内核参数
目录 /proc/sys/net/ipv4/conf/*interface*/
arp_ignore:定义网卡接收到ARP请求时的响应级别:
0: 只要本地的所有网络接口配置了相应的地址,就给予响应,返回相应地址所对应的网卡的MAC地址。
1:仅在请求的目标网络接口上查找ARP请求相应的地址,如果有就返回此网卡的MAC地址。
arp_announce: 定义网络接口连接互联网时向外通告时的通告级别
0:将本地所有网络接口上的任何地址向外通告;
1:试图仅向目标网络通告与其网络匹配的地址;
2:仅将连接互联网的网卡上配置的所有地址进行通告
需要进行配置 arp_ignore=1 arp_announce=2
arp_ignore=1 的含义是 网络接口接收ARP请求后,不将其它网络接口的地址暴露出去。
arp_annouce=2 的含义是 当前网络接口连接互联网后,不会将其它网络接口的地址通告出去。
注意一台计算机可能有多个interface,只需配置 RIP所在的interface即可。
同时还要注意需要在Real Server里创建Loopback网卡的网络接口做为VIP,也就是VIP要配置到Loopback网卡上。
其根本原因是Looback网卡是内核应用程序模拟的网卡,不是物理网卡,不会连接互联网主动通告,也不会接收ARP请求。
3.2.4 为什么DR模式要快
上面讲过NAT模式,这里讨论DR模式为什么要比NAT模式快,其原因主要有以下几点:
1. DR模式是基于二层数据链路层的MAC欺骗,而NAT模式是基于四层的网络地址转换协议,因此DR模式比NAT模式更快,更节省CPU资源。
2. DR模式下目标服务器的响应不会经过LVS负载均衡服务器,大大减轻了LVS负载均衡服务器的网络带宽压力,节约了网卡资源,提升了吞吐量。、
3.3 TUN隧道模式
每一种新技术的诞生,很多时候都是为了解决旧技术存在的痛点。学习新技术时,先了解技术的发展历史,理解旧技术的痛点在哪,学习新技术就能游刃有余。
DR模式的痛点:
DR模式虽然相较于NAT模式性能有较大的提升,但是其限制LVS服务器需要和所有的Real Server在同一个局域网中。无法突破地域的限制。
TUN隧道模式目的就是突破地域的限制,使得LVS服务器和所有的Real Server可以部署在不同的局域网中。
设计图:

3.3.1 实现原理
如上图可以知道在TUN隧道模式下,LVS负载均衡服务器在转发数据包前通告Real Server调度算法选择一台Real Server,且在目标数据包外层再封装一个(VIP->RIP)的数据包。这种情况可以理解为"数据包背着数据包"。
在这种情况下外层数据包是由(VIP->RIP),因此不需要做基于二层数据链路层的MAC欺骗,直接将数据包转发给Real Server,因此LVS服务器和Real Server自然不需要在同一个局域网内部署。
3.3.2 优缺点
优点:
相较于DR模式,突破了地域的限制,LVS服务器可以和Real Server部署在不同的局域网中,提高了部署的灵活性。
缺点:
TUN隧道模式的性能肯定是比NAT模式要高的,但其性能比DR模式要慢。因为这种"数据包背着数据包",使得数据包更大,在高并发的场景下其会消耗更多的网络带宽,网卡资源会成为其性能瓶颈。
四:Real Server调度算法
LVS(Linux Virtual Server)主要有以下几种实现调度算法:
静态调度算法:只基于算法本身进行调度
轮询调度算法(Round Robin)
加权轮询调度算法(Weighted Round Robin)
源地址哈希算法 sh
目标地址哈希算法 dh
动态调度算法:根据各个Real Server的负载情况和算法来进行调度。优先调度负载程度最轻的Real Server
最少连接数调度算法(Least Connection)
加权最少连接数调度算法(Weighted Least Connection)
最短期望延迟算法(Shortest Expected Delay Scheduling) sed
最少队列算法(Never Queue Scheduling) nq
基于局部的最少连接算法:
带复制的基于局部的最少连接算法(Locality-Based Least Connections with Replication) lblcr
FO算法(Weighted Fail Over) fo
OVF算法(Overflow-connection) ovf
每种调度算法的详情可见:LVS的12种Real Server调度算法
4.1 如何监控每台Real Server的负载情况?
在使用动态调度算法的时候,需要监控各个Real Server的负载情况,比如连接数指标,那么LVS负载均衡器是如何知道每台Real Server上建立了多少长连接呢?
其实很简单,客户端的握手报文会发送给LVS负载均衡器,因此LVS负载均衡器自然知道哪个客户端想要与哪台Real Server握手,LVS服务器监听到客户端发来的ACK包,就知道连接建立成功,于是连接数+1统计就可以。
注意:在DR模式和TUN隧道模式下,Real Server的响应数据包会直接发回给客户端,不会经过LVS服务器,因此三次握手的全过程并不能完全监控到,四次握手也是如此。
4.2 客户端长连接
首先一定要明白的一点是LVS负载均衡服务器不会与客户端建立连接,也不会与Real Server建立连接,真正建立连接的是客户端与目标服务器。
思考一个问题:客户端每发送的数据包都会经过Real Server调度算法进行负载均衡均分到多台Real Server吗?
回答:在使用长连接时,LVS负载均衡服务器只会把客户端的长连接通过Real Server调度算法均摊到Real Server,让每台Real Server都分摊到一定量的客户端长连接。但连接建立后,客户端所有数据报文虽然也会发送给LVS服务器,但是此时LVS服务器如果判断当前客户端与Real Server已经建立过长连接,就会直接转发请求到目标Real Server,不会再进行Real Server负载均衡调度。