前言
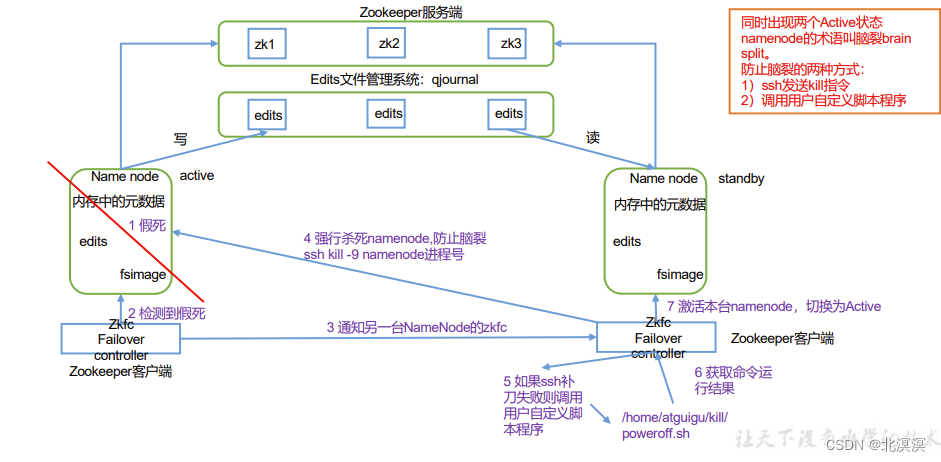
本节内容主要介绍一下hadoop集群下实现HDFS高可用的自动故障转移,HDFS高可用的自动故障转移主要通过zookeeper实现故障的监控和主节点的切换。自动故障转移为 HDFS 部署增加了两个新组件:ZooKeeper 和 ZKFailoverController (ZKFC)进程。ZooKeeper 是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。在开始本节内容之前,我们需要提前安装好zookeeper集群,可参考作者往期博客内容。
正文
- 集群规划
hadoop集群高可用hdfs hadoop101 hadoop102 hadoop103 NameNode NameNode NameNode JournalNode JournalNode JournalNode DataNode DataNode DataNode Zookeeper Zookeeper Zookeeper ZKFC ZKFC ZKF
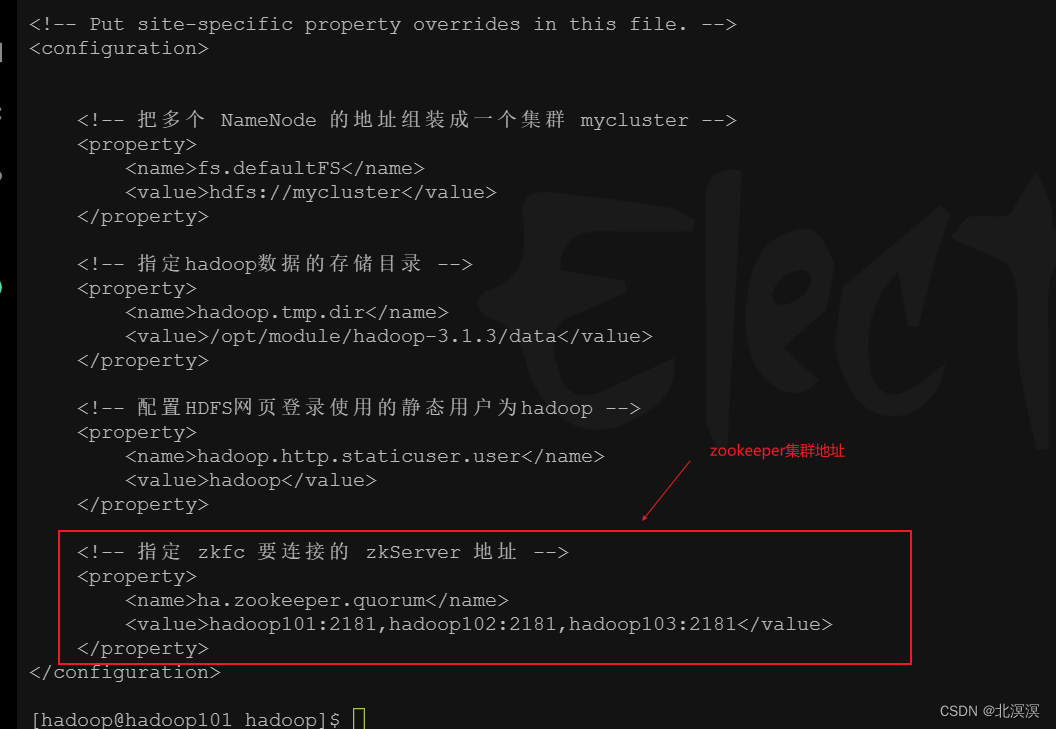
- 在core-site.xml文件中增加zkfc要连接的zkServer地址
- core-site.xml配置
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 把多个 NameNode 的地址组装成一个集群 mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为hadoop --> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property> <!-- 指定 zkfc 要连接的 zkServer 地址 --> <property> <name>ha.zookeeper.quorum</name> <value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value> </property> </configuration>
- 在hdfs-site.xml中增加故障转移的配置
- hdfs-site.xml配置
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- NameNode 数据存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/nn</value> </property> <!-- DataNode 数据存储目录 --> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dn</value> </property> <!-- JournalNode 数据存储目录 --> <property> <name>dfs.journalnode.edits.dir</name> <value>${hadoop.tmp.dir}/jn</value> </property> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 集群中 NameNode 节点都有哪些 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2,nn3</value> </property> <!-- NameNode 的 RPC 通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop101:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop102:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn3</name> <value>hadoop103:8020</value> </property> <!-- NameNode 的 http 通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop101:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop102:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>hadoop103:9870</value> </property> <!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/mycluster</value> </property> <!-- 访问代理类:client 用于确定哪个 NameNode 为 Active --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要 ssh 秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 启用 nn 故障自动转移 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
- 使用hsync分发修改的配置文件
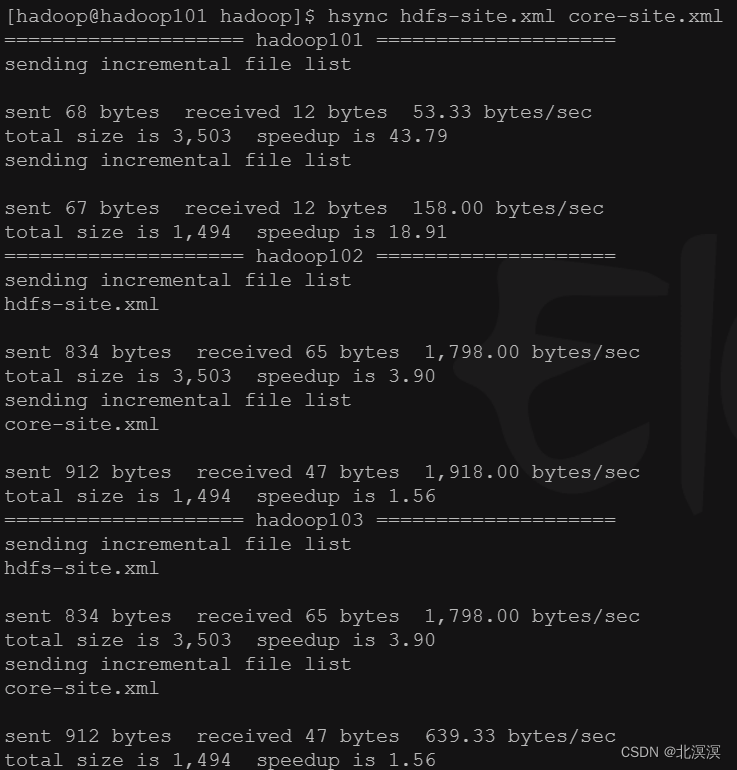
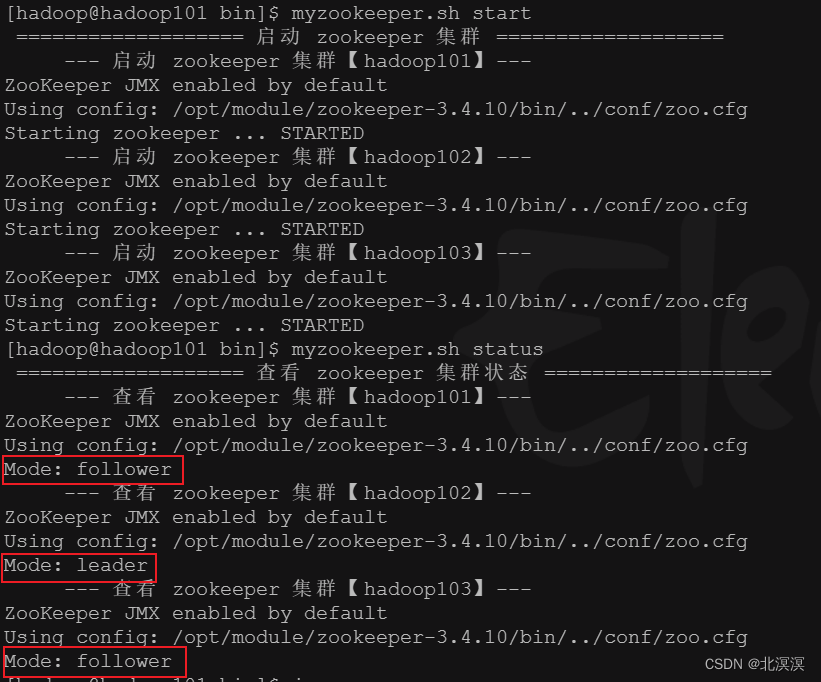
- 启动zookeeper集群
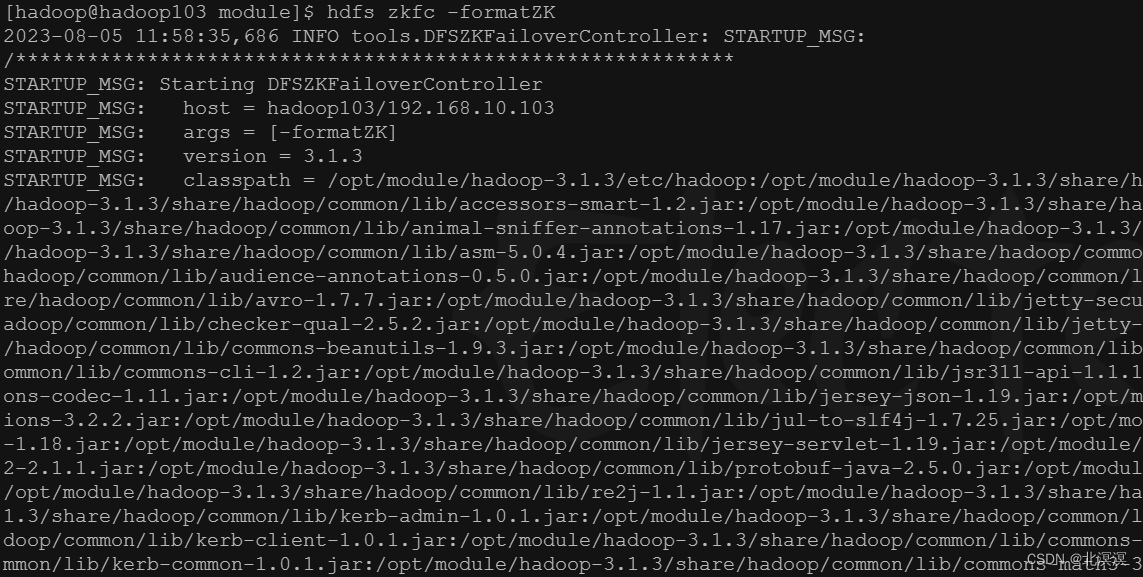
- 启动 Zookeeper集群后,然后再初始化HA在Zookeeper集群中状态
命令:hdfs zkfc -formatZK
- 启动HDFS服务
- 命令:start-dfs.sh
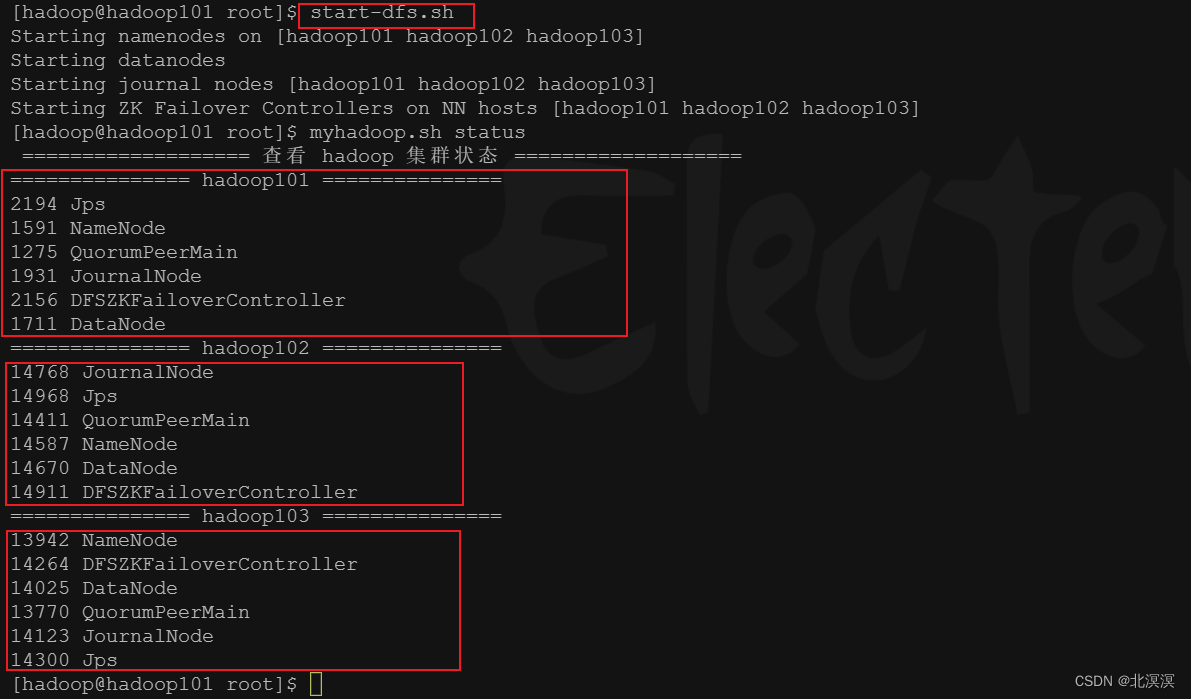
- 关闭hadoop102的active的节点,查看故障是否会转移
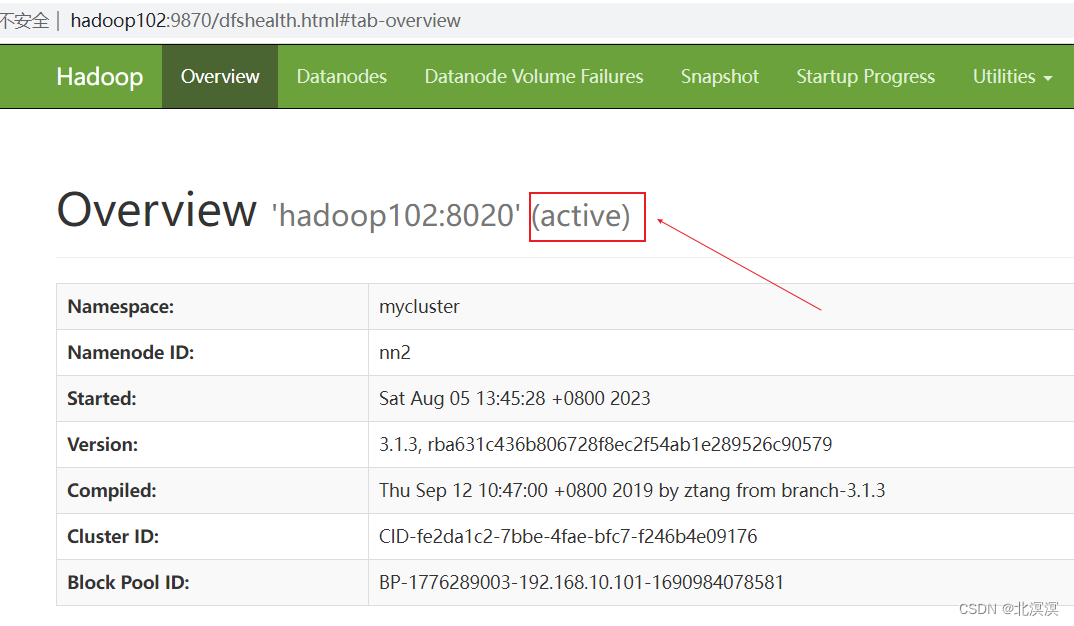
- 当前激活的节点是hadoop102
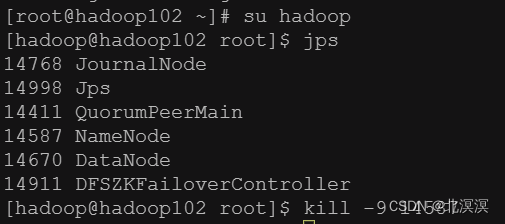
- 关闭hadoop102的namenode节点
- 发现故障并未转移,每个服务需要独立安装psmisc,实现服务通信,命令:yum install psmisc -y
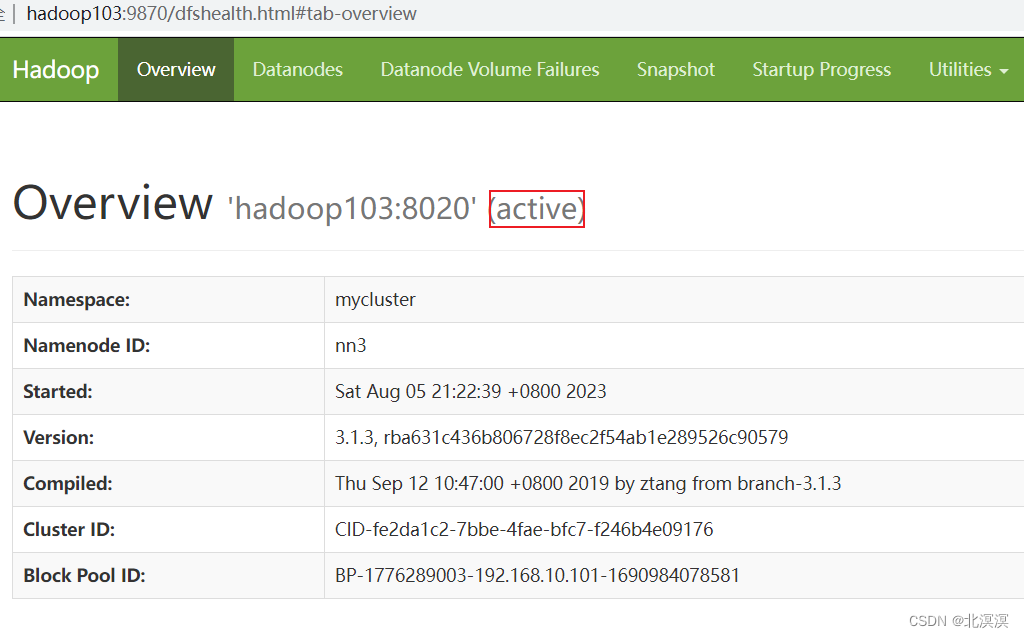
- 当前激活节点变为hadoop103,hadoop101为备用节点,hadoop102无法访问,实现了故障转移
结语
关于hadoop集群之HDFS高可用自动故障转移的内容到这里就结束了,我们下期见。。。。。。